一种基于领域词典的XML非结构化信息模式识别方法
2014-01-02杜巍
杜 巍
(中国人民解放军海军舰艇学院,辽宁 大连116018)
0 引言
生产发展推动了社会分工,在效率关乎兴亡的社会条件下,许多行业都开始通过以整合资源、系统运作的方式增强竞争力。系统的日益庞大也造成了其外延的不断扩散,触及的领域之多、范围之广已经超过了人类个体的认知范围。另一方面,人类注意力的有限性使得他们在信息爆炸时代的海量“信息碎片”中难以取舍。准确快捷的提供用户所需要的信息,淡化的无关信息,就需要利用各种技术对环境和客体中各种庞杂的信息进行采集并有效进行模式识别。
模式识别是一种计算机通过对信息依次进行采集,预处理,特征或基元抽取,模式分类,以自动或者在人尽量少干预的情况下把待识别模式归入相应的模式类中去的技术传统的模式识别方法,主要有统计模式识别法和结构模式识别法。统计模式识别法是通过对待识别对象进行特征提取,然后根据某种准则所确定的决策函数进行分类,即从信息特征空间映射到决策空间;结构模式识别法,则是通过把一个模式描述成子模式的方式,形成一个树形的描述结构。
在非结构化信息面前,传统的模式识别方法往往难以满足计算量和复杂的信息描述方式。随着模糊数学及人工智能的发展,人们开始了模糊模式识别和智能模式识别的研究,尤其是人工神经网络在模式识别中产生了较大的成就。然而经验表明,在灰色领域,即信息数量庞大,结构复杂,内容零碎而情况下,运用神经网络方法,效率并不尽人意。而基于统计的方法和确定演绎方法均有各自的局限性,如样本持有量和计算量和使用范围,需要加以综合、改进。本文尝试一种分层的模式识别与信息分类系统结构,使之能够满足多范畴不完整的非结构化信息进行模式识别。
1 非结构化信息的概念与XML语言的特性
现实情况下,受到信息来源,信息范畴和保存格式的影响,许多实际问题中,信息的内部结构、参数聚合特征一般不能全部被人们了解。即使事实上这些信息存在这大量联系实际内容重合,但由于呈现出的结构各不相同,表面描述杂乱无序,内容因采集方式的局限显得残缺不齐,难以通过传统的方法进行识别和分类,这样的不完全信息都属于非结构化信息。不完全信息本身固有的语义包括:不完全信息是否有可用来取代该不完全信息的完全信息的值——实值,实值的个数,实值的限定范围[8]。根据这些语义信息,不完全信息可以分为三类:“不存在型不完全信息”,即某个关系的某一个元组在某一个属性上不该具有任何实值;“存在性不完全信息就”,即某个关系的某一个元组在某一个属性上本应必然着几个实值,但在当前是未知的,需要未来确知这个实值,这个确知的过程称之为完全化;“占位型不完全信息”,关系的某一个元组在某一属性上尚不知是否存在某种实值,它可能是不存在性不完全信息,也可能是存在性不完全信息。当作为数据源的传感器、网络端口数量庞大,种类繁多的情况下,统一的数据格式往往难以实现,更多的是以非结构化的形式出现,为了促进数据交换与操作,人们开发了各种语言标准,目前比较常用的方法是采用可扩展标记语言XML(eXtensible Markup Language),这种标记语言有这便于信息检索、数据内容与形式分离的好处,是信息载体的发展趋势,也是模式识别的主要研究对象。
2 基于分层领域词典的非结构化信息的模式识别方法
零散信息源或未知信息源所传递的信息,识别工具仅能获取表面标识和大体结构,而对其携带的信息以及实际对应的范畴难以确认,这种部分信息已知而部分信息未知的系统,称之为灰色系统。对灰色系统的认知适合采用分层次的白化方法,即从大概念上的范畴逐步划分为其下的子范畴,类似领域本体的层次划分,呈现出一种树形结构,划分的子范畴具有更具体的领域特征和对应的领域词库可以对待识别对象进行进一步匹配,这样既可以降低计算量,增强了系统在低精度要求条件下的识别正确率的鲁棒性。
假设收到一组信息,先通过少量具有明显可区别性特征的元素,如年龄信息、作者信息、具有明显的特征性,其可能所属领域范畴则显著缩小,只需要传递致含有生物信息或文化产品信息的领域识别列表处,再通过运用该领域的数据字典库对目标模式进行比对,做出更细化的划分,直到抵达叶子节点或需要达到的识别级别。
这种方式有点像本体的概念的划分,标准顶级本体概念下根据条件的细化从THING(事物)这样的宏大概念,到GraphLoop(环形图像)这样的领域概念。如图1。

图1 标准顶级本体概念树
识别过程:假定收到一组未知对象信息X,需要确认其所属模式ω,该模式属于一个论域Ω,通过分析对象X的信息,可以获知X包含了 n 个属性,记 为 X={x1,x2,… ,xn},其中 xi(i=1,2,… ,n)是第 i个属性,每个属性x又包括属性名和属性值;某一待模式ω内包含了m个属性,记为 ω={ωa1、ωa2…ωam},其中 ωaj(j=1,2,…,m)是模式 ω 的第 j个属性,考虑到信息的格式可能存在不规范特征,比如XML格式中属性名字可以自己定义,不同名称的属性可能表示不同的概念,这就需要为每一个属性名构造一个近义词匹配表,该表结构如表1。

表1
这里设的权值ra是衡量的是该信息来源的匹配程度,即近义词与规范名称的贴近程度,注意的是因为不同的命名方式与知识领域是相关的,不同的命名方式即使意义相同,也可能降低了属于本领域的可能性。
校正动作用于该属性名对应的属性值,如例子中因为单位的不同需要修正属性值的大小。v表示该属性的值,f(v)表示校正后的值。
以某领域距离单位名称为例:
同样,对于某个领域下该属性名的属性值有一定分布规律,对匹配对象的属性值分布可能性进行权重确定和处理。
模式ω与对象X的匹配度计算公式如下:
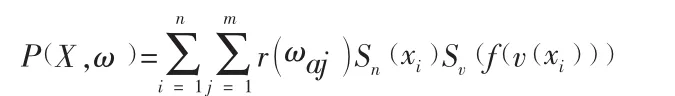
一个待识别对象X与一个模式模式ω的匹配值决定了他们的匹配程度,可以根据需要选择保留超过事先确定的阈值的若干模式,也可以取最大匹配值的模式作为结果。计算的结果可以根据需求进行下一步处理或舍弃,如信息明显不属于用户关注的领域,则可以忽视此信息,否则以该模式代表的领域,构建新的论域,进行下一级模式匹配。
3 效果验证
为了验证以上方案的有效性,构造了一组简单的不完全信息的案例作为仿真分析,假设某舰艇收到一组XML格式的信息,
<目标>
<时间>XXX</时间>
<经度>121</经度>
<纬度>41</纬度>
<高度></高度> //注:空标识,属于存在型不完全信息
<反射面积>60</反射面积>
<速度>40</速度>
<方向>135</方向>
</目标>
假设待匹配的模式有3种:模式1(飞机或导弹)、模式2(舰船)、模式3(潜艇或水雷)。
各自的模式特征属性:(括号内为该属性的权重)
模式 1:高度(0.6)、反射面积(0.2)、速度(0.3)
模式 2:高度(0.3)、反射面积(0.2)、速度(0.3)、噪声(0.2)
模式 3:深度(0.6)、速度(0.1)、噪声(0.3)
需要注明的近义词表有:

表4 模式3
各模式的属性分布(只附上待识别目标匹配的):

表7 模式3
计算结果为 P(X,ω1)=0.40

从计算结果来看,待识别对象为舰船的可能性最大,潜艇的可能性最小,基本符合人的主观认知。
4 结论
这种模式识别方法具有计算简单,对数据的结构性和完整性要求十分宽松的特点,适合知识总量可控的领域使用,如果以此进行建立较大领域的模糊识别,需要得到较完善的领域知识和丰富的认知词典内容的支持。
[1]熊超.模式识别理论以其应用综述[J].中国科技信息,2006,6:171-173.
[2]靳光俊,范学峰,郭文宏,金玉.基于灰色理论的整体模式匹配 [J].信息技术,2008,11:41-45.
[3]韩景倜,卢致杰,覃正.基于XML的复杂信息系统自动分类方法[J].系统工程理论方法应用,2005,12:487-491.
[4]王智君.粗糙集规则简约的放荡发在模式识别中的应用[J].微计算机应用,2009,5,30(5).
