“大数据”背景下利用扫描数据编制中国CPI问题研究
2014-01-01乔晗
乔 晗
(河南大学 经济学院,河南 开封475004)
一、引 言
随着信息技术的不断普及,政府行政管理和企业生产经营中产生了海量的电子化数据,现在流行的叫法为“大数据”(Big Data)。在对原先专属官方统计的传统领域构成巨大挑战的同时,“大数据”也为政府统计源头数据信息化改革、宏观经济测度以及微观企业管理提供了前所未有的条件与机遇[1]。如何有效利用“大数据”已成为政府统计部门和学术界亟待研究的问题。
目前,国际上对“大数据”的应用,主要是以谷歌(Google)为代表的高科技企业,而政府统计对“大数据”的应用尚处于起步阶段。尽管它作为官方统计的源头数据,“大数据”自身存在诸如来源不稳定、持续性差等局限,但是应充分认识到“大数据”的巨大潜力,将其作为官方统计的重要数据来源,使之将来在政府统计工作中发挥巨大作用。
作为“大数据”形式之一的扫描数据(Scanner Data)①“大数据”可以是结构化、半结构化,也可以是非结构化数据,而扫描数据是一种结构化数据。在国际上政府统计中应用较广泛。
扫描数据来自市场交易,主要为企业经营服务,具有实时、细节全覆盖的特征。因其对宏观经济测度所产生的巨大正外部性,冲击了官方高成本价格统计的专属权,也因此推动政府统计源头数据信息化改革,为宏观经济测度提供了新的技术范式。
《消费者价格指数手册:理论与实践》②《消费者价格指数手册:理论与实践》由多个国际组织共同编写,对各国在编制CPI的理论及实践中起重要指导作用,下文简称《CPI手册》。指出:对于CPI的编制来说,扫描数据在迅速扩大数据来源方面有着相当大的潜力。从电子销售点获得的扫描数据,能够在非常详细的级别上显示出包括销售量、相应价值总额等信息。扫描数据都是最新的数据,而且非常全面[2]54-92。
所谓扫描数据,是指消费者在消费场所进行结算时,结算人员通过扫描设备对商品的条形码进行扫描时生成的一种电子数据。一条完整的扫描数据包括商品名称、交易价格、交易数量、销售地点、购买日期、商品品牌、型号以及对商品的简单描述等信息[3]。扫描数据不同于电子收款机数据:后者通常指直接从零售商的电子收款机取得的数据,而扫描数据则通常是指根据电子收款机数据整理的商用数据,存储在企业数据库中。
扫描数据的应用前景非常广泛,从宏观经济测度到微观企业管理,都可以发挥重要作用。在宏观经济测度方面,目前运用较为成熟的就是利用扫描数据进行地区价格水平测度,其中以CPI最为广泛。这也是本文研究的重点。
西方国家的统计部门和相关学者非常重视对这一新方法的研究和实践,如澳大利亚统计局(Australian Bureau of Statistics)、美国劳工统计局(U.S.Bureau of Labor Statistics)和新西兰统计局(Statistics New Zealand)等。挪威、瑞士和荷兰尽管在方法上不尽相同,但是已经正式开始利用扫描数据来编制本国的CPI[4]。对于扫描数据在价格水平测度方面的优势和潜力,各国政府统计部门和相关学者已达成了广泛的共识[5]。
本文立足中国现行CPI调查的实际情况,结合各国研究现状,提出一种中国利用扫描数据编制CPI的思路,并对中国在这一领域所面临的挑战进行分析,以期为后续“大数据”在经济统计中的应用研究提供参考。
二、扫描数据的优势
(一)从样本数据到总体数据
中国现行CPI调查的主要方法是抽样调查,抽样误差在所难免。同时,在代表规格品种类和数量的选择上,需要依靠价格调查员或采价员对消费者的消费习惯和偏好商品进行判断,因而受主观因素影响较大,使样本数量和样本结构的代表性受到影响。扫描数据是商品交易的总体数据而非抽样数据,因此,在消除抽样误差的同时,纳入CPI编制的代表规格品数量和结构也与总体趋于一致。
(二)从离散数据到连续数据
中国现行CPI调查要求在某一时点对某一代表规格品进行采价,以代表某一时段该商品的价格,这是一种离散数据。一方面,由于商家会根据供求不断调整价格使其收益最大化,另一方面,消费者也会根据价格变化调整自身的消费方式,所以某一商品在不同时间被购买,价格不一定相同。因此,中国现行CPI调查虽然讲求“定人、定点、定时”的原则,但仍可能会高估或低估消费者购买商品的平均价格①Warner和Barsky发现有些商品的价格具有周期性变化,有的商品的价格在周末会降低。Chevalier等人也发现了类似的问题,有的商品价格波动与天气和节假日有关。。而扫描数据是高频数据,它能记录消费者每次消费的真实价格,是一种连续数据,因而消除了离散数据可能带来的偏差。
(三)从人工数据到信息化数据
中国现行CPI调查采取人工采价的形式,在人工录入环节可能会出现两种测量误差:一是采价员录入价格时发生的错误;二是产品货架或包装上错误的价格信息[6]。国家统计局目前推行的“CPI手持数据采集系统”虽然做到了数据传输的信息化,但这种方式依然需要人工记录数据,因而无法避免上述两种测量误差。扫描数据从价格数据的生成到传输,都无需人工参与,可以说是真正意义上的信息化源头数据,同时可以避免人工采价产生的测量误差。
(四)关于新产品监测的改进
随着经济的快速发展,商品更新换代的速度也在加快。而中国现行CPI调查对于新产品的处理,主要依靠一线价格调查员,在实际调查中较难把握。Shapiro等的研究表明,产品变化更新缓慢是导致高估CPI代表的通胀水平的主要原因[7]。扫描数据提供的即时数据信息有利于监测新产品的增加并及时纳入编制目录,以消除新产品可能导致的偏差。
(五)获取权重成为可能
中国现行CPI调查无法获得单个代表规格品的销量信息,导致基本分类指数编制中无法使用加权指数。《CPI手册》指出:原先认为在基本分类指数中使用未加权指数造成的偏差不太显著,然而最近的证据表明其所导致的偏差可能会相当大。与传统价格采集方式相比,扫描数据可以获得每一商品的价格和对应的销量,从而提供了编制基本分类指数相应权重信息,为基本分类指数的选择提供了空间。
(六)降低企业回答负担
中国现行CPI调查需要价格调查员定期到调查点进行采价,有时还需要聘用调查点的员工作为价格采集员,协助价格调查员进行采价工作。具体工作中,采价员工作量大,报酬很少甚至是没有报酬。加上采价员往往是商场的工作人员,自身工作任务繁重,可能会出现工作积极性不高,责任感不强的问题,从而导致“延价”等现象出现。扫描数据从企业总部直接获取,无疑减少了企业员工的回答负担,这既有利于企业的生产经营,也提高了源头数据的可靠性,为企业向政府统计部门提供扫描数据创造了条件。
(七)提供判断与评价的可能
通过扫描数据,可以对消费者的消费习惯、商品的销售分布以及新旧产品的更新速度等商品特性做出判断,以评估现行CPI调查方案的可行性并做出评价。
三、扫描数据的获取
作为CPI编制的源头数据,扫描数据的获取是首要任务,主要分为两个方面:一是扫描数据的获取范围,二是扫描数据的获取途径。
(一)获取范围
中国现行CPI调查262个基本分类中,若利用扫描数据作为源头数据,需要满足两个条件:一是消费场所具备电子结算系统,二是所售商品具有条形码。在满足以上两个条件的基础上,根据国外实践经验并结合中国实际,笔者列出了中国CPI调查可以利用扫描数据的商品目录,如表1所示。
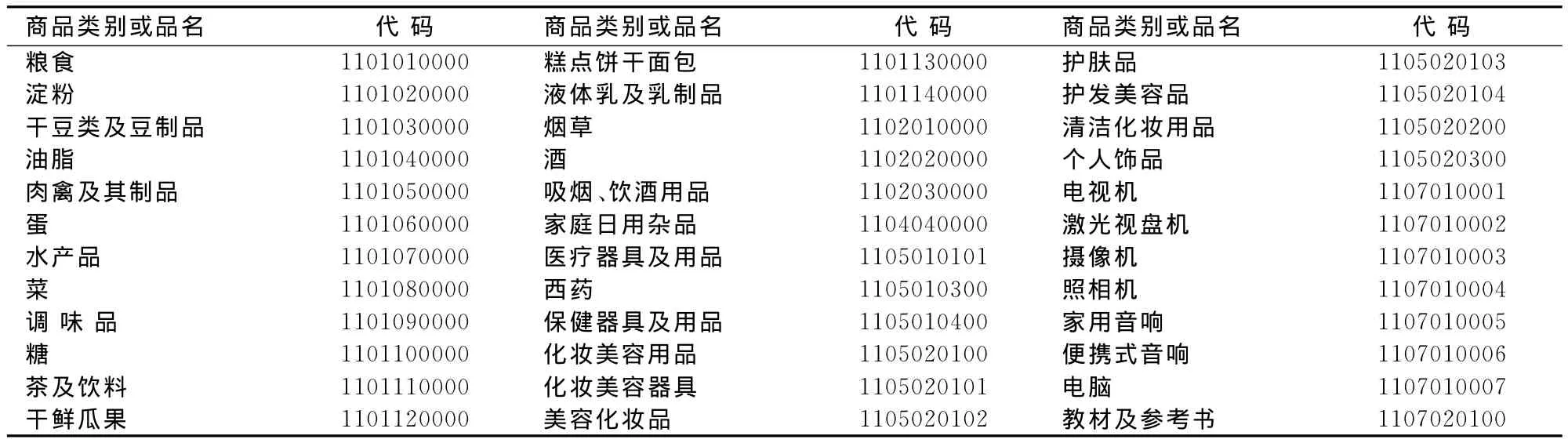
表1 中国CPI调查可以利用扫描数据的商品目录表
(二)获取途径
目前,国外统计部门主要以两种方式获取扫描数据①Fixler(2003)提出还可以利用住户扫描数据(Household Scanner Data)作为一种扫描数据的获取方式,但应用较少。。
第一种方式是政府统计部门与大型连锁超市、商场以及利用条形码进行结算商户合作,由连锁超市总部或商户定期将扫描数据发送给统计部门。如瑞典统计局从一个拥有20家分店的零售连锁企业获得扫描数据(Norberg et al.,2011)。荷兰统计局每个月前三个星期都会收到几家大型超市企业的扫描数据(Grient和 Haan,2010)。
第二种方式是政府统计部门从市场调研公司购买扫描数据。在美国,纽约统计部门从AC尼尔森(ACNielsen)和信息资源(Information Resources)两家市场调研公司获取扫描数据。这两个公司每月根据统计部门的要求收集零售商的扫描数据,并对其进行加工整理(如对扫描数据的清洗和分类),最终把数据加工为政府统计部门需要的形式。
一般情况下,统计部门以第一种方式获取扫描数据是免费的,但有一个与相关企业配合的问题。超市企业只会提供原始的扫描数据,指数编制前相关的数据整理工作需要政府统计部门独立完成。目前,挪威、瑞士②为了更方便获得和处理原始扫描数据,瑞士统计局专门开发了一套软件系统,并根据扫描数据利用情况进行实时升级。和荷兰统计局通过此种方式获取扫描数据。
统计部门若以第二种方式获取扫描数据,则可能要花费较大的费用,这笔费用甚至可能比使用人工采价方式更高。同时,这样会增加数据的采集和传输环节,形成政府统计机构对私营企业的依赖。但这样做的优势也是明显的,市场调研公司不仅根据统计部门的要求收集原始扫描数据,而且对原始扫描数据进行整理,以便统计部门能够直接使用。
对原始扫描数据的整理是利用扫描数据编制CPI的基础,它是一项复杂的工作,主要包括:扫描数据的汇总、格式的统一和分类③一方面,不同超市企业提供的原始扫描数据格式常常是不一致的,另一方面,超市企业的分类和CPI商品分类是有区别的。、数据清理④在指数编制前,要确保扫描数据的质量,数据清理这一环节非常重要,例如把在一个月内价格上下波动非常大(例如60%)的商品排除在外。等。
政府统计部门显然没有专业市场调研公司擅长处理上述内容。在英国、美国和澳大利亚等国家,扫描数据大都是从市场调研公司购买的。
综上所述,无论以哪种方式获取扫描数据,都有其明显的优势和劣势。各国都是根据自身情况选择合适的方式。例如美国这样的大国,由于超市企业众多,国土面积较大,显然第二种方式较为适合。而诸如瑞士和挪威这样的欧洲小国更合适第一种方式。
从这个角度来讲,中国政府统计部门显然适合采取第二种方式获取扫描数据,即与市场调研公司合作。但目前情况是,无论是中国政府统计部门,还是本土市场调研公司,都缺乏处理“大数据”的相关经验。而外资企业在中国的分公司虽然在利用中国扫描数据方面经验丰富,但不适宜参与中国CPI编制工作。
笔者建议,一方面,政府统计部门应主动与超市企业合作,加快开展关于扫描数据的前期研究以积累经验;另一方面,与国内“大数据”企业合作,共同应对这一挑战。
(三)获取扫描数据的建议
从数据源头的角度讲,扫描数据的获取有两方面的要求:一方面是要与相关企业保持长期、稳定的合作关系,以保证价格数据资源的一致性、连贯性和可靠性;另一方面则是全面性的要求,即获得尽可能多的企业扫描数据,并且在每个企业中贯彻全面性的原则,尽可能获取其总体数据。为了获得中国企业的扫描数据,笔者根据国外经验并结合中国国情,提出以下几点建议:
1.企业利益。这是基层统计部门获取源头数据时应特别重视的一点。从荷兰和挪威的经验来看,超市企业之所以免费给政府统计部门提供扫描数据,是因为这样可以减少企业的回答负担(response burden),即企业旗下所有分店不需再承担价格采集任务。同时,由于扫描数据涉及商业机密,为了保护合作企业利益,政府统计部门在获取数据、传输数据和发布数据等环节中,要做到严格保密。
2.法律法规。从法律角度来讲,企业有义务向政府统计部门提供相关数据,扫描数据也不应例外。挪威统计部门由企业获取扫描数据的过程中,其1989年颁布的《统计法》(The Norwegian Statistic Act)起了重要作用。欧盟理事会条例(EU Council Regulation)也规定:“相关企业有义务在规定的时间内,向统计部门真实并完整地提供所需要的数据(在足够详细的层面上),并允许统计部门利用上述提供的数据进行官方统计核算”。《中华人民共和国统计法》(2009年修订)第一章第七条规定:“国家机关、企业事业单位和其他组织以及个体工商户和个人等统计调查对象,必须依照本法和国家有关规定,真实、准确、完整、及时地提供统计调查所需的资料,不得提供不真实或者不完整的统计资料,不得迟报、拒报统计资料”。
3.调查目的。政府统计部门从企业获取的扫描数据,应仅限于CPI的编制这一目的,不能用于税收调查等其他相关目的,否则会增加企业的不信任感,导致企业不愿意配合或提供虚假数据。这是现阶段中国获取扫描数据非常关键的一点。
四、利用扫描数据编制中国CPI
(一)扫描数据的特性
利用扫描数据编制CPI的过程中,需要对其性质有一个比较清晰的把握。笔者概括了Haan等人的研究成果,提出扫描数据的三个特性:波动性、被动性和高流失率[8-9]。这三个特性对于CPI编制中代表规格品和指数公式的选择和影响较大。
1.波动性。所谓扫描数据的波动性,是指其代表的商品销售量易因促销而大幅波动。Haan和Grient①数据来源于荷兰一个大型连锁超市旗下所有分店191周(从2005年1月到2008年8月)的相关基本分类产品组的扫描数据。利用每周“品牌A洗涤剂②这些基本分类产品组并非是随机选择的,而是这些商品的销量本身就易随价格变化而产生波动。(Detergent)”的单位价格③对于同一个代表规格品,通过加总可以得到其一周的销售额和销售数量,从而推算出这一代表规格品这一周的单位产品价格(平均价格),同时也就是CPI编制中所使用的该产品的价格。及对应的销售量进行实证分析发现:打折周和非打折周的交替出现,导致该产品周销售量发生很大的波动,即产品销售量随着产品的单位价格发生了动态波动。出现这种情况的可能性是基于这样一种事实:对于一些生活用品,消费者一般会在打折周购买较大数量并储存,在非打折周使用储存量,直到下一个打折期再进行购买。这种销量随价格大幅波动的商品,对于指数公式的编制,带来了一定的困难。
2.被动性。所谓扫描数据的被动性,是指扫描数据生成方式是被动的,即只有规格品被出售后才会生成对应的扫描数据。如果某商品在一个调查周期都没有交易记录的话,就没有相应的扫描数据,形成数据不连续①有学者也称扫描数据的这一特性为"价格丢失"。笔者认为,大数据背景下探讨数据采集就不存在数据缺失的问题,因为大数据是针对总体而言的。如果商品的数据不连续,那不能叫缺失,因为现实的总体就是这样,不能让现实数据去适应统计方法,而应是统计方法适应现实数据,不能在"大数据"背景下还采用"小数据"思维方式。。
3.高流失率。所谓扫描数据的高流失率,是指新旧商品更替速度较快②Rodriguez的研究也得出了相似的结论:一个月之内,超过20%的商品流失了,一年后,只有42%的商品还在市场上销售。,而同一基本分类中商品种类的数量变化则相对较小。Haan等通过研究“洗涤剂”(基本分类)从2005年1月到2008年8月种类总量变化的月度数据发现:“固定篮子”中商品种类由最初的58种,到最后只剩7种在市场销售。而在同时期,洗涤剂的种类总量变化很小。上述现象说明,在某一基本分类中,产品更新速度较快而产品种类总量保持相对稳定。这一特性直接显示出了“固定篮子”的局限性。
(二)代表规格品月度平均价格
在计算基本分类指数之前,需要计算某一规格品i在报告期y年m月的平均价格。中国现行CPI调查方案的计算方法是:首先计算出某一代表规格品在某个价格调查点的月度价格的简单平均数,然后再根据各个调查点的价格计算出月度平均价,如式(1)所示:
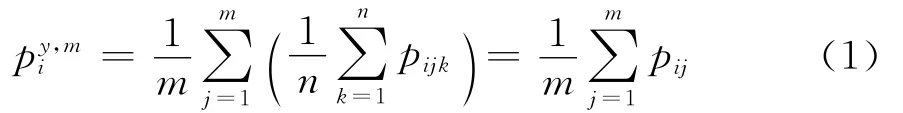
对于类似上文提及的“品牌A洗涤剂”那样在不同价格下销量分布差别较大的商品,利用上述方法计算月度平均价格,就会产生较大的偏差。中国现行CPI调查方案很难对式(1)进行改进。
扫描数据能够获得每个代表规格品当月在不同价格下的销售份额,因此可以对同一代表规格品在一个月内的不同价格水平进行加权,以消除上述情况可能产生的偏差。因此,代表规格品i在报告期y年m月的平均价格可以表示为:

(三)基本分类指数计算
基本分类指数是构建CPI的基本要素,CPI的准确性在很大程度上取决于基本分类指数的质量。在计算基本分类指数之前,首先要确定是利用链式指数(Chain Index)还是直接指数(Direct Index)。
1.链式指数与直接指数。价格指数计算方法一般分为链式指数和直接指数。若使用链式指数,需首先计算环比指数,再将环比指数“链”(以连乘积的方式)在一起推算定基指数。若使用直接指数,需首先计算出定基指数,再利用定基指数推算环比指数。
与直接指数相比,链式指数有着明显的优势:有利于即时对权数进行更新,有利于新旧产品的替代以反映市场动态③从扫描数据的高流失率可知,新旧产品更新速度很快,如果使用直接指数进行价格水平测度的话,会造成较大的偏差。以及缩小Passche指数和Laspeyres指数的差异等。目前,国际上很多政府统计部门在编制基本分类指数中使用链式指数。在扫描数据的支持下,链式指数可以发挥更大的优势。鉴于链式指数的诸多优势,中国基本分类指数在扫描数据的支持下,也可以尝试使用链式指数。
但扫描数据在链式指数的实践中,会导致链式漂移(Chain Drift),从而影响指数的准确性。从数据结构角度来讲,出现链式漂移现象的主要原因是:价格数据波动(如正常的季节性波动)较大的情况下频繁(如每月)地对环比指数进行“链接”[10]。
扫描数据本身具有波动性,因此在链式指数中使用扫描数据会出现链式漂移。这一推论得到了Haan和Rodriguez等人的验证[4,9]。正是因为这个原因,导致各国采用了不同的方法。
2.代表规格品的选择。关于规格品的选择,可以分为两步考虑。第一,是否有必要把总体数据都纳入CPI的编制中。目前无法也没有必要把总体数据纳入到CPI的编制中。一方面,对于因季节或促销而导致价格波动较大的商品,现有方法尚无法将其纳入基本分类指数编制中,否则会出现链式漂移而影响指数准确性;另一方面,没有必要把所有规格品都纳入计算,在基本分类中各个商品的销售权重分布很不均衡①Grient和Haan利用扫描数据分析发现,在基本分类中的各个产品,支出分布是高度偏差的:40%~50%商品的支出份额还占不到总支出份额的10%。相对较少数量的商品却占了绝大多数的份额。,只需考虑较大权重的商品即可。
第二,如果没有必要将总体数据都纳入CPI的编制中,那么选取的标准是什么。关于规格品选取的标准,各国采用了不同的方法。荷兰统计局采用了一种隐性加权的方法:若某一商品在相邻两期的支出份额的均值大于某一个特定的门限值的话,该商品被视为代表规格品纳入基本分类指数的编制中,否则排除此商品②具体的计算方法可以参见《统计研究》2013年第1期《扫描数据支持下CPI编制方法研究》一文。。
挪威统计局则把因季节或促销等原因而导致价格波动较大的商品排除在基本分类指数编制之外,其目的就是为了避免在月度链式指数的计算中出现链式漂移。
3.指数公式的选择。国际上在CPI基本分类指数的编制中,一般采用Jevons指数、Dutot指数和Carli指数三种形式,其中包括中国在内多数国家选择Jevons指数,主要是因为Jevons指数是最佳价格指数(Superlative Price Index)中的一员。
各国之所以在实践中普遍使用诸如Jevons指数这样的非加权指数,是受到了权重可得性的限制。各国统计部门原以为,在基本分类指数中使用未加权指数造成的偏差不显著。但最近的证据显示,这种指数可能会造成相当大的偏差。扫描数据的出现,使得每一种商品的价格及其当月的销售份额都可以获得。因此,在很大程度上扫描数据扩大了指数公式的选择,也为统计部门缩小上述偏差提供可能。
2005年,挪威开始以扫描数据为源头数据,利用链式Fisher指数编制基本分类指数③涵盖的范围是“食品和非酒精饮料”。。挪威统计局把价格波动较大的商品排除在外。而荷兰采用了非加权的链式Jevons指数。这样做是为了避免链式加权指数可能出现的链式漂移。尽管在代表规格品的选择上考虑了权重,但在指数计算中,对商品权重忽略所造成偏差的影响,还有待检验。
为了解决链式加权指数与链式漂移的矛盾,Ivancic等对GEKS指数进行改进,以解决在使用链式最佳价格指数(如Fisher指数)时避免链式漂移,同时使得所有的价格信息都能够得到最佳的利用[11]。GEKS指数在形式上不是直接的价格指数,不容易向CPI的使用者和编制者解释。同时,因为这种方法还未受到统计界的广泛接受,所以不适合作为国家统计政策来实施。
综上所述,中国在利用扫描数据编制基本分类指数方法的选择上,应当体现以下几点:首先,每个代表规格品的权重应体现在基本分类指数编制中;其次,与直接指数相比,链式指数具有明显优势,尽管可能会造成链式漂移;最后,链式漂移在基本分类指数的编制中应引起足够的重视。
(四)基本分类指数的汇总
以扫描数据为源头数据的基本分类指数编制完成后,还需要与其他源头数据编制的基本分类指数层层汇总,形成最终的CPI。对于基本分类指数汇总中权重与公式的选择,依然可以沿用现有的方案。
五、应用中的困难与问题
扫描数据为统计源头数据信息化以及宏观经济测度提供了巨大支持。作为一种“大数据”,要想在经济统计中发挥更大的作用,还面临很多问题。就CPI的编制而言,有的困难是所有国家都需要面对和解决的,如对链式漂移的处理。然而更为复杂的是,各国法律和政府统计制度不尽相同,国土面积和市场结构也千差万别。因此,在具体研究中,各国情况又有所不同,例如荷兰这些国土面积较小的国家,在扫描数据的利用上,于中国显然不同。
(一)世界各国共同存在的一般性问题
第一,以扫描数据为代表的“大数据”,对现有的经济和指数理论提出了挑战。扫描数据反应的是个人的交易记录而非消费信息。在指数理论和相应的国民账户体系中,购买和消费是两个不同的概念。因此,在经济和指数理论方面还需要进一步研究,使得各种概念协调统一[12]224-250。
第二,海量的扫描数据虽然在数据源头上为CPI的编制提供了前所未有的机遇,但它本身并不会直接改进我们的编制技术。政府统计部门必须开发新的技术把“大数据”变成真正有用的统计工具。尤其对于直接从超市获取扫描数据的政府统计部门,需要有更为专业的技术和丰富的经验。
第三,统计部门编制价格指数是一项连续、一致的工作,需要有长期、连续、稳定的数据供给。这就需要政府统计部门与企业保持持续、良好的合作关系,以便能够及时获取所需的数据。尤其是从市场调研公司获取扫描数据的政府统计部门,在合作过程中,既要处理好与市场调查公司的关系,还要确保市场调查公司与超市企业的稳定关系。
第四,不能寄希望于扫描数据完全替代人工采价。一方面,在很多领域尤其是服务领域,由于没有扫描数据,所以无法应用;另一方面,很多传统的市场形态也无法提供扫描数据。
第五,扫描数据无法控制和监测市场参与者(例如厂商)的行为。厂商偏好通过减少商品包装袋的大小(减少了商品重量,然后再更换一个条形码),保持商品价格不变的方式暗中涨价。这种行为在扫描数据中仅仅是一种新产品的出现,但实质上是相同商品的价格上涨行为。
(二)由中国国情所引发的问题
第一,欧洲国家国土面积普遍较小,城市发展水平一致,连锁超市在全国基本实行统一的定价策略①如荷兰大多数连锁超市企业都执行统一的全国定价策略,绝大多数规格品的价格在所有的分店都是一样的。。这使得中央统计部门直接从几个大型连锁超市获得的扫描数据,具有很强的代表性。中国国土面积广阔,地区间发展水平差异明显,物价水平差距较大,消费市场中连锁超市企业众多,且地域色彩浓厚。因此,中国统计部门采集扫描数据的工作量要大得多,配合的企业也需要尽可能的多,这无疑增加了工作难度②笔者认为这也正是只有荷兰、挪威和瑞士三个国家在CPI的编制中使用了扫描数据,而诸如美国、澳大利亚等国土面积较大的国家还未使用的主要原因。。
第二,国外居民购买日常用品一般都在大型超市或是有电子结算系统的便利店。在中国,尤其是相对落后的城市,居民日常购物主要集中在农贸市场。这对中国利用扫描数据编制CPI带来一定的困难,主要表现在两个方面:一是很多交易数据无法获得;二是超市获得扫描数据的代表性会受到质疑。
六、结 论
扫描数据作为一种全新的CPI源头价格数据,无论是在数据采集方式上还是在数据结构上,都有着巨大的优势。对经济统计来说,扫描数据及其所代表的“大数据”的意义,绝不仅仅是源头数据的信息化,更为重要的是,它为准确测度宏观经济变化提供了新的条件。
正是因为它与传统数据形式的巨大差别,目前各国还未研究出一种行之有效的方法发挥其全部潜在优势,在实际应用中还有很多问题有待解决。但这并不能阻止我们利用诸如扫描数据这类“大数据”的步伐,也没有必要等到所有问题都解决了才敢将其付诸使用。例如,瑞典统计局仅仅把扫描数据作为一种替代人工数据采集的数据形式,而指数的编制方法保持原先的方法不变。这样虽然没有发挥扫描数据的全部优势,但能够以最小的成本降低指数的偏差(前提是扫描数据的获取是免费的)。
在利用扫描数据编制CPI的实践方面,国外研究机构及相关学者提供了不少宝贵经验。因此,本文认为,中国政府统计部门应该注重诸如扫描数据这类“大数据”在宏观经济测度方面的应用。
[1] 郑京平,王全众.官方统计应如何面对Big Data的挑战[J].统计研究,2012(1).
[2] ILO,IMF,OECD,Eurostat,United Nations,World Bank.Consumer Price Index Manual:Theory and Practice[M].Geneva:International Labour Organization,2004.
[3] 陈相成,乔晗.扫描数据支持下CPI编制方法研究[J].统计研究,2013(1).
[4] Haan J de,H A Van Der Grient.Eliminating Chain Drift in Price Indexes Based on Scanner Data[C].Neuchatel:the Eleventh Meeting of the Ottawa Group,2009.
[5] Berthold Feldmann.Scanner Data- Next Steps Ahead[R].Ottawa Group:Working Paper,2012.
[6] 陈相成,乔晗,温素清.扫描数据支持下的CPI调查[J].市场研究,2012(7).
[7] Matthew Shapiro,David Wilcox.Mismeasurement in the Consumer Price Index:An Evaluation[C].MIT Press:NBER Macroeconomics Annual,1996.
[8] Hann J De,Heymerik A,Van Der Grient.Eliminating Chain Drift in Price Indexes Based on Scanner Data[J].Journal of Econometrics,2011(3).
[9] Joaquin Rodriguez,Frank Haraldsen.The Use of Scanner Data in the Norwegian CPI:The New Index for Food and Non-alcoholic Beverages[J].Economic Survey,2006(4).
[10]Szulc B J.Linking Price Index Numbers[C].Ottawa:Price Level Measuerment,2007.
[11]Ivancic L,Diewert W E,Fox K J.Scanner Data,Time Aggregation and the Construction of Price Indexes[R].Working Paper,2009.
[12]高艳云.价格指数的理论与方法[M].北京:中国财政经济出版社,2008.
