利用CPLD提高FPGA加载速度
2013-12-30李春雨张丽霞
李春雨,张丽霞
(1.浙江机电职业技术学院电气电子工程学院,杭州310053;2.诺基亚西门子通信有限公司,杭州310053)
现场可编程门阵列FPGA常用来进行大数据量的处理,并且可以根据设计的需要灵活实现各种接口或者总线的输出,在设备端的通信产品中使用越来越广泛[1]。FPGA是基于SRAM结构的,每次上电时都需要重新加载程序,且随着FPGA规模的升级,加载程序的容量也越来越大,因此提高其加载速度是产品设计必须妥善解决的一个问题。本文介绍了通过CPLD对FPGA的加载方式的串行改进方式,满足通信系统的加载速度快,占用资源少的要求。并用Verilog HDL实现,在Modelsim中进行仿真和验证结果,在自行设计的时钟板上验证通过,而且可以扩展到所有类似系统中[2]。
1 配置方式介绍
FPGA的加载配置,大部分是将配置数据存放在FPGA组成系统的存储器件上,系统上电时由控制器读出配置数据再传送给FPGA进行配置[3]。
FPGA的配置方式最常用的有JTAG,从并,从串[4]3种,不同厂家叫法不同,但实现方式基本都是一样的。单板调试阶段常用JTAG模式,单板正式工作时通常采用从串或者从并方式。从并和从串模式各有优点,从并加载模式一个DCLK传送一个字节(8 bit),因此速度快,但是占用FPGA管脚多,以Altera公司CycloneⅢ系列为例,从并模式(FPP)占用23个FPGA专用管脚,且这些管脚在不同的逻辑Bank内,当各Bank之间接口电平不同时,即连接到控制器的23个管脚电平就要各不相同,对控制器来说通常是难以实现的,在这种情况下从串就成为唯一的选择。
以Altera公司CycloneⅢ系列FPGA为例,与从串加载相关的管脚见表1[5]。

表1
加载流程图如图1所示。
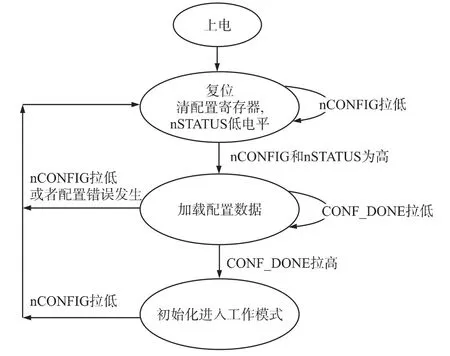
图1 CycloneⅢ从串加载流程
各种型号的FPGA从串加载英文名称虽然有些差异,但是加载流程基本如图1,每种型号的FPGA配置文件大小是固定的,和使用的逻辑资源多少无关,以CycloneⅢ系列的EP3C120为例,其大小是14.3 Mbit[5]。
2 从串加载方式的实现
2.1 以CPU作为FPGA加载控制器
CPU可以采用嵌入式微处理器[6]的GPIO口和FPGA的加载配置接口连接,框图如图2所示。
其缺点是DCLK也要由CPU GPIO口模拟,GPIO口的速度较慢,以RMI公司的XLS408为例,GPIO口模拟最大时钟2 MHz,如前面说EP3C120配置文件14.3 Mbit,加载时间为7.15 s。如果基于主频较低的ARM7处理器,对于CycloneⅡ系列中的EP2C35,配置文件大小 1.16 Mbyte,加载时间需要 1.5 min 30 s[7],对于时间比较敏感的通信产品来说,用户的体验就会很差,通常该加载时间要求小于2 s。
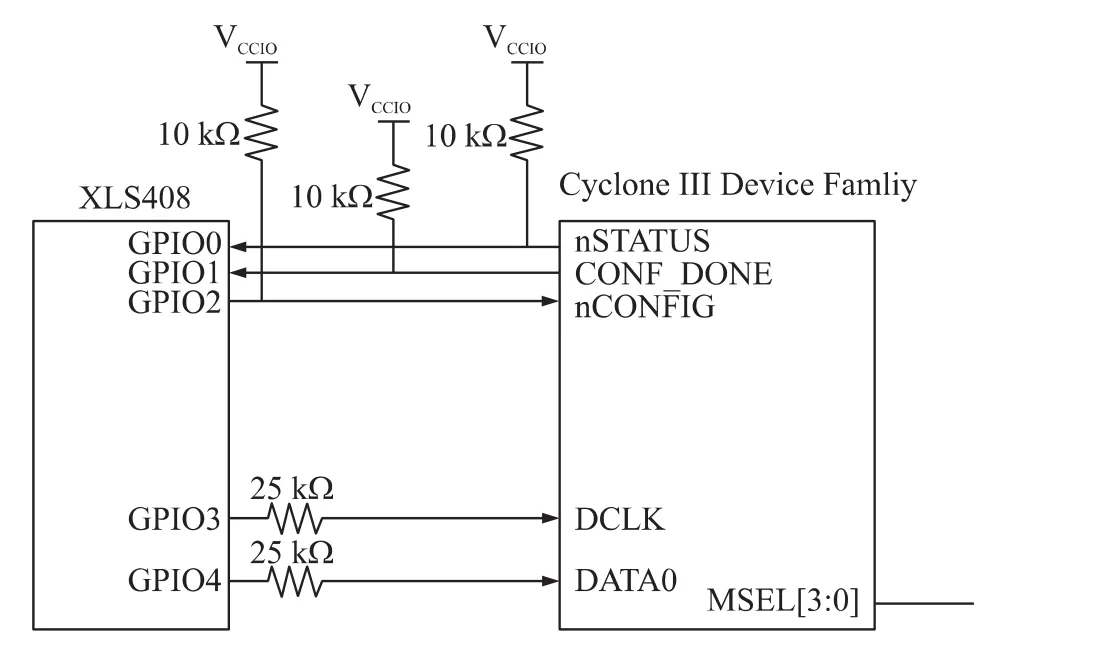
图2 XLS408从串加载流程
3 基于CPLD作为FPGA加载控制器的改进方案
3.1 改进方案介绍
采用基于DDR颗粒的CPLD作为控制器的方案,CPLD的IO管脚都可以约束到时钟信号上,只要CPLD内部的布线资源足够,输出的加载时钟可以跑到上百兆,写入CPLD的数据采用并行接口,大大提高FPGA加载速度。加载方案如下:

图3 基于CPLD加载数据流向图
本方案中CPU采用RMI公司的XLS408,CPLD采用 Lattice公司的 LCMXO1200,FPGA采用ALTERA公司的 CycloneⅢ EP3C120,DDR采用9片Hynix DDR2颗粒。
1号线表示,CPU通过16 bit localbus总线读取存储在Flash里的FPGA文件,并搬运到DDR里,这一步可以在加载前先做,不占用加载时间。
2号线表示,CPU读取DDR数据搬移到CPU内部缓存中,DDR接口速度较快,DDR2时钟266 MHz,数据位宽64 bit,几乎不占用加载时间。
3号线表示,CPU通过8 bit localbus总线写到CPLD内部寄存器,而localbus总线是异歩并行总线,以MIPS系列CPU XLS408为例,XLS408工作时钟66.7 MHz,写总线周期最快需要10个工作时钟周期,即6.67 MHz,这一步受localbus总线速度限制。
4号线表示通过CPLD和FPGA之间的串行接口,写加载配置数据到FPGA中,写FPGA的速度决定于串行接口的DCLK频率。
本方案的优点,1,2两条路径可以在加载之前处理,且运行速度快,不占用加载时间。加载时间只受3,4步限制,3步是并行总线,位宽8 bit,速度相对串行总线已经大为提高,4步受限点是CPLD输出的DCLK频率限制,CPLD输出时钟可以高达上百兆,加载时间会大为缩短。
3.2 程序实现
CPLD 程序采用 Verilog[8]语言实现,该加载模块接口定义如下:

程序实现流图如图4所示。
DCLK和FPGA加载串行数据输出部分代码如下:


在FPGA加载环节,CPU通过8 bit的Localbus总线先是写CPLD数据寄存器,一字节写完后,CPU会将标志寄存器cpu_cpld_flag翻转,CPLD检测到寄存器cpu_cpld_flag的双沿变化后,计数器cnt_fpga_prog[4:0]开始计数,其中 cnt_fpga_prog[0]是 CPLD工作时钟的二分频,该时钟送给FPGA加载接口,做为DCLK,利用cnt_fpga_prog[3:1]的变化范围实现并行数据到数据的变化,因为都是通过同一计数器实现,因此能方便的实现数据和DCLK的同步,当cnt_fpga_prog[4]计数到1 后,cnt_fpga_prog[4]上升沿有效,代表一字节数据已经成功加载到FPGA,CPU就开始通过localbus总线写下一字节数据。

图4 基于CPLD从串加载FPGA的程序流程图

图5 程序仿真波形
4 仿真及改进结果分析
基于modelsim 6.5SE仿真波形如图5所示。
由上面波形可以看出CPU每加载一字节数据需要写两次CPLD寄存器,一次写加载数据,一次写标志寄存器,读一次CPLD寄存器,读cnt_fpga_prog[4]上升沿,共3个localbus总线周期,localbus频率最快6.67 MHz。因此 CPU加载 14.3 Mbit,亦即1.787 5 Mbyte数据到CPLD共需时间:
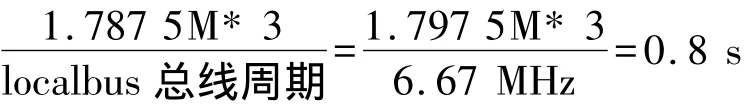
CPLD需要8个DCLK周期写一字节数据到FPGA,CPLD工作时钟33M时,DCLK 16.7 MHz,因此加载14.3 Mbit数据到FPGA,共需时间:
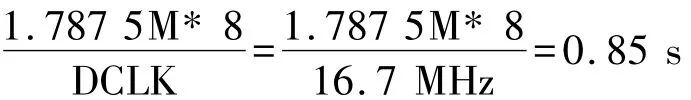
因此当FPGA使用EP3C120时,采用基于CPLD的从串加载方式,共需要加载时间1.65 s,满足通信产品FPGA加载时间小于2 s的要求。
从上述分析可以得出结论,如果提高CPLD的工作时钟,CPLD加载FPGA的时间就会进一步缩短,当CPLD工作时钟100 MHz时,DCLK达到50 MHz,CPLD加载配置数据到FPGA时间可以缩短到0.29 s,加载速度会更快。
5 结束语
使用基于 CPLD的 FPGA加载方案,相对于CPU直接加载方案,加载时间只有原先的十分之一,且有进一步提高空间,满足通信系统快速启动的要求,且该方案并不局限于本文所提到的器件,可以应用于各厂家的FPGA中,具有很高的实用价值。
[1]关珊珊,周洁敏.基于Xilinx FPGA的SPI Flash控制器设计与验证[J].电子器件,2012,35(2):216-220.
[2]王小峰,周吉鹏.一种FPGA在线配置Flash的方法[J].电子器件,2006,29(3):902-904.
[3]董宏成,魏杨.基于ARM和NAND Flash的FPGA加载配置在TD—LTE 中的实现[J].电子技术应用,2012,38(07):26-30.
[4]Xilinx,Spartan3e,Xapp502,Using a Microprocessor to Configure Xilinx FPGAs via Slave Serial or SelectMAP Mode[S].2009.
[5]Altera,cyclone Ⅲ,Configuration altera FPGAs[S].2010.
[6]葛立明,范多旺,陈光武.基于ARM的FPGA加载配置实现[J].微计算机信息,2007,1(2):244-245.
[7]胡启道,张福洪,戴绍港.基于MCU的FPGA在线配置[J].电子器件,2007,30(3):1049-1056.
[8]王静霞.FPGA/CPLD应用技术(Verilog语言版)[M].北京:电子工业出版社,2011.
