P2P环境下的信息搜索与信息过滤研究
2013-12-25何天云唐晓玲
何 燕,何天云,唐晓玲
(四川外语学院图书馆,重庆 400031)
一、P2P网络模型简介
P2P(Peer-to-Peer)称为对等网络或对等连接,是一种流行的网络模型。自出现之日起,P2P就已成为各个研究领域的热点课题。近年来,P2P又运用到数字图书馆领域,以分布和自组织的方式处理大量的数据。它采用的是社区组织形式,一个搜索引擎可以从大型用户社区的智能输入(书鉴、查询日志、点击流等)中获得益处[1]。这给数字图书馆的搜索能力提供了前所未有的优势,包括提高了可扩展性、有效性、容错能力和动态性等。但是,目前提出的结构化P2P模型大多数是将用户作为一个对等体,资源仅来自于数字图书馆及用户本身,资源共享也只是用户间的共享,而没有将资源共享扩大到数字图书馆之间。另外,目前的P2P技术局限于单个关键词精确匹配的查询,它不能满足包含多个关键字的文本查询[2]。并且,传统的网页搜索会得出海量的网页数据,如果需要返回与关键字相匹配的、最相近的网页列表,使用目前的P2P模型是完全行不通的[3]。
本文提出一种在数字图书馆的分布式P2P环境下而构建的、新的信息搜索和信息过滤模型。模型将每个数字图书馆(Digital Library,简称DL)看成是网络中的一个对等体。模型底层的功能和数据均是分布在不同的对等体中,但对用户提供统一的图形用户接口,以方便用户使用。模型结构如图1所示。
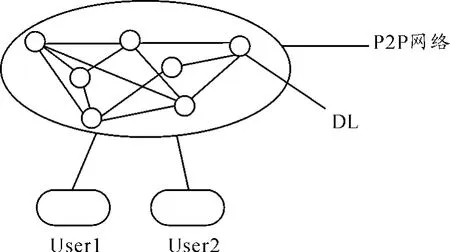
图1 P2P网络模型
模型包含两个部分:资源搜索模块和信息过滤模块。资源搜索模块采用P2P技术分配和保存对等体统计数据,并完成一次查询功能。根据相同的数据,信息过滤模块针对一个连续查询,选择最可信的数字图书馆发布最合适的文档,从而提供发布、定制服务[4]。
二、资源搜索模块
P2P资源搜索模块进行资源搜索的步骤为:
(1)系统提供一个简单的搜索界面,允许用户输入查询关键字。系统使用分布式哈希表(Distributed Hash Table,简称DHT)启动全局查询。分布式哈希表是将整个搜索空间对应到一个散列空间,当一个节点要搜索该资源时,对该资源的唯一标志使用相同的散列函数进行散列,得到散列值,再通过有效的局部路由,找到负责该资源的对等点[5]。它支持两个哈希表函数:插入关键字和对应的值 insert(key,value)和检索关键字 retrieve(key)。
(2)对于出现在查询里的每个主题,系统检索分布式目录里所有合适的候选条目,也即通过输入进行查询的路径选择。最终选择一个可靠的数字图书馆子集,这些数字图书馆能够针对指定查询返回高质量的结果。
(3)系统同样使用DHT将用户的查询发送到已选择的数字图书馆中,使用本地TOPX引擎评估搜索到的资源,对资源进行降序排列,选择排在前h位的资源(h由用户自己确定)。
网络爬行者用于模仿用户的行为,浏览那些与特定用户兴趣主题相符合的网页,并作出标注[6],从而搜集用户的兴趣。Topx是一个对XML和纯文本数据进行结果排序的搜索引擎[7]。其排序方法有两种:一种是基于概率统计的评分模型,这种方法主要是根据用户对资源的反馈来得出资源的评分,主要通过用户对搜索到的资源的态度(点击次数、浏览时间等)来决定分值的大小;另一种是根据资源的全文内容,包括文中的短语、布尔表达式以及其他的限制条件进行资源排序。
(4)综合所有数字图书馆返回的资源,进行去重、归并,最后将结果显示给用户。
三、信息过滤模块
相对于资源搜索模块,信息过滤模块的功能更加复杂。每个数字图书馆都需实现三类服务:发布、定制和目录服务。
发布服务的实现也需要一个网络爬行者,其功能为发布信息资源。爬行者获取用户提供的信息,并将信息发布到网络中。
定制服务首先由用户将连续查询发送到网络中,系统选择合适的对等体来标引用户的查询。若选择的对等体发布了与查询匹配的资源,则向使用定制服务的用户发出通知。与传统的过滤模块相比,此过滤模块在进行对等体选择时,不仅使用了传统的资源选择算法,还引入了行为预测算法来描述对等体的行为趋势。
最后,目录服务负责将对等体加入P2P网络,获取对等体的信息检索统计值。
四、P2P网络模型的运用
(一)资源的发布
一个对等体或数字图书馆希望将自己拥有的新文档共享给网络中的其他对等体,就需要发布资源。对等体在发布资源时,使用恰当的本地过滤算法将资源与本地查询索引相匹配,若匹配成功,则触发对定制该资源对等体的通知。执行过程中,要求连续查询的位置应该固定,因为对等体的查询必须能被监测到,这样发布和通知过程均不需要额外的通信费用。
(二)发布者的选择
当对等体p接收到一个来自用户的连续查询q时,p首先需要决定网络中的哪些对等体为可以信任的候选对等体,并用这些对等体针对给定的连续查询来发布相似的文档。具体做法是,p针对q包含的每个主题向目录服务发出请求,获取每个对等体针对主题的统计值。综合各主题的统计值得出各对等体的综合评分,公式如下:
score(p,q)=(1 -a)*sel(p,q)+a*pred(p,q)其中,sel(p,q)表示资源选择值,pred(p,q)表示对等体行为预测值,a为调整参数。通过上述公式的计算,将对等体按分值大小进行降序排列,并将查询q发送给排在最前面的K个对等体(K是用户指定的参数)。查询q被存储在这些对等体中,一旦这些对等体每次发布一个与查询相匹配的资源,就向用户发出通知。
每个查询都包含一个生命周期值(TTL),在指定的时间后应该消失,保留查询的对等体在查询的生命周期过后应将此查询删除。对等体p在发起下一次查询过程时应该进行新的计算,选择新的对等体。
(三)资源的选择
函数sel(p,q)返回对等体p对查询q的一个分值,计算这个分值采用信息检索领域中标准的资源选择算法。sel(p,q)表示对等体p在领域q内的权威性,在我们的实验评估中,只考虑文档频率和主题频率。文档频率(df)代表数字图书馆包含某个主题的文档数量,主题频率(tf)表示在数字图书馆的所有文档中某主题出现的次数,而tfmax代表最大主题频率,表示在数字图书馆的所有文档中某主题出现的最大次数[9]。
(四)对等体的行为预测
对等体选择过程的关键组成部分就是这里引入的预测机制。预测是资源选择的补充,在过滤环境中是必要的。
假设数字图书馆dl1在足球方面相当专业,是足球资料的权威,但它不再发布新的文档。相反,数字图书馆dl2在足球方面不专业,但目前却发布了关于足球的文档。假设某个用户定制关于将在南非举行的2010年足球世界杯的文档。只使用资源选择算法的评分函数通常会选择数字图书馆dl1作为资源的发布者,实际上这是错误的。但要使数字图书馆dl2得到更高的质量评分,并被选择成为资源的发布者,它必须在足球方面专业化,这需要很长的过程,而且对于不断变化的动态过滤环境来说是不合适的。因此,单独的资源选择算法是不充分的,特别是针对一些刚被发布的新主题,因为新主题的生命周期都较短,慢速的资源选择算法是最坏的选择。所以在动态环境下,对等体预测算法比起慢速的资源选择算法适应能力更强。
在预测对等体行为的背后,主要将信息检索统计值看作是时间连续数据,并使用统计分析工具模型化对等体的行为。时间连续分析假设:发生在某时间段的数据有内在的序列,并通过观察来分析旧值,预测新值。例如,一个数字图书馆目前发布了大量的关于足球的文档,将来同样也会发布许多关于足球的文档。
有两种不同的技术预测未来值:平均值技术和指数滑动技术。平均值技术是对过去的观测值平均分布权重,不能很好地处理数据值的趋势,这个缺陷比较致命。因此,我们使用第二种技术,指数滑动技术。双指数滑动技术与单指数滑动技术相比考虑到了数据趋势,所以我们选择双指数滑动技术模型化对等体的行为,并预测未来的发布行为。另外,针对更长而持续的查询,必须考虑活动期的问题,应考虑三指数滑动技术。
(五)目录维护
综上所述,准确的对等体统计值对于对等体质量评分和对等体的选择都是必需的。过滤模块使用的是和资源搜索模块相同的目录,保存信息检索统计值。此目录是一个逻辑上统一而物理上分开的分布式目录,采用分布式哈希表来管理压缩形式的数字图书馆集成信息。在运用中,我们使用Chord分布式哈希表划分主题空间,这样每个对等体负责目录中的一个随机主题子集的统计值。为了更新统计值,对等体与全局目录保持一致。DHT决定一个对等体目前负责的主题,并且保存该主题的所有条目。
对等体实现的目录服务不一定使用Chord,可使用其他DHT。因为,这种结构允许任何种类的P2P网络(结构化的和非结构化的)使用,只要给出必须的信息,如每个对等体的信息检索统计值等。
(六)实验结果
我们使用不同的发布场景,根据召回率(recall)测试系统性能,召回率用收到的通知数与发布的相关文档数的比值表示。实验中,使用1000个发布者,分别用30个2、3和4主题连续查询。每个对等体都是10类信息(类别包括音乐、体育等)中的很专业的一类。并在指定时间段内发布30个文档,在10次循环后,我们得出结果。然后改变存储连续查询的发布者百分比再进行下一次实验。图2为实验结果,横坐标p为发布者对等体占总发布者数量的百分比,纵坐标表示平均召回率。实验结果显示,使用行为预测与只使用资源选择相比,召回率提高很明显。将资源选择与行为预测相结合,过滤模块更加准确地模型化了对等体的行为,可以预测对等体的行为趋势。
五、信息搜索模块与信息过滤模块的比较
信息搜索模块和信息过滤模块分别处理系统的两个不同问题,但两种方法有相似之处。它们的重要属性对比见表1。
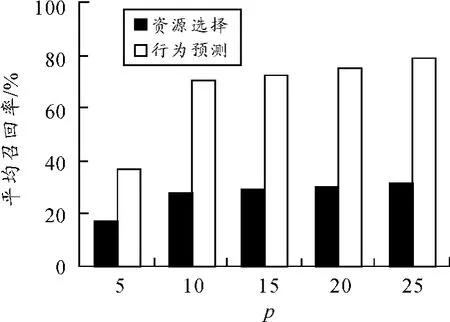
图2 资源选择与行为预测召回率比较

表1 信息搜索模块与信息过滤模块的比较
六、结论
本文给出了一个系统模型,在数字图书馆的分布式P2P环境中,能够有效地进行信息搜索和信息过滤。P2P技术被用于构建对等体统计值的分布式目录。这个目录用于对等体选择,包括信息搜索和信息过滤两种运用场景。为了构建这个目录,系统可以使用不同的底层P2P系统,比如Chord和 Pastry。
信息过滤模块与信息搜索模块具有相似的构成,都包括根据对等体统计值建立的分布式目录。只是在信息过滤模块中,对等体选择最可信的数字图书馆去发布兴趣文档,从而满足连续查询。而对等体的选择不仅使用了众所周知的资源选择算法,还使用了新的对等体行为预测算法。实验结果表明,采用这种方法进行对等体选择更加合理,提高了召回率。
[1]Matthias B,Sebastian M,Christian Z,et al.Bookmarkdriven query routing in Peer-to-Peer Web Search[C]//Proceedings of the SIGIR Workshop on Peer-to-Peer Information Retrieval,2004:1 -12.
[2]Huebsch R,Chun B,Joseph M,et al.The architecture of Pier:an internet-scale query processor[C]//Proceedings of the 2005 CIDR Conference,2005:28 -43.
[3]Matthias B,Sebastian M,Peter T,et al.Minerva:Collaborative P2P Search[C]//Proceedings of the 31st International Conference on Very Large Data Bases,2005:1263-1266.
[4]Tang C Q,Xu Z C.pFilter:Global Information Filtering and Dissemination using structured Overlay Networks[C]//The International Workshop on Future Trends of Distributed Computing Systems,2003:24 -30.
[5]Stoica I,Morris R,Karger D,et al.Chord:A scalable Peer-to-Peer Lookup Service for Internet Applications[C]//Proceedings of ACM SIGCOMM,2001:149-160.
[6]Bookmark-Induced Gathering of Information with Adaptive Classification into Personalized Ontologies[EB].[2007-03-13].http://www.mpi-inf.mpg.de/units/ag5/software/bingo/.
[7]Martin T,Ralf S,Gerhard W.An efficient and versatile query engine for topX search[C]//31st International Conference on Very Large Data Bases,2005:625 -636.
[9]Callan J.Distributed Information Retrieval[M].Holland:Kluwer Academic Publishers,2000:127 -150.
