基于可编程GPU的遥感影像快速处理研究
2013-12-11刘旭春李德龙滕长胜靖常峰
刘旭春,李德龙,,刘 津,,刘 杨,,滕长胜,靖常峰
(1.北京建筑工程学院,北京100044;2.现代城市测绘国家测绘地理信息局重点实验室,北京100044;3.中测新图(北京)遥感技术有限责任公司,北京100039)
一 、引 言
低空航摄能够获取大比例尺高精度的影像,且具有响应时间短和灵活多变的优势,因此常用于应急灾害测绘。同时,救灾的紧迫性要求遥感影像能够被快速处理。在快速处理领域,一般采用分布式集群计算机和多核CPU来获得大数据量和复杂计算的加速效果,但其局限性比较大,大集群占用太大空间,多核CPU性能难以达到要求,而可编程图形处理器(graphic process unit,GPU)同时解决了分布式集群和多核CPU的局限性。尤其是近年来,可编程图形处理器的并行处理在其他领域得到了很好的应用和发展,因此研究其在遥感影像快速处理领域的应用非常有实际意义。
可编程图形处理器利用其可并行运算的CUDA(compute unified device architecture)统一计算设备软硬件架构体系,可在硬件加速和软件并行设计方面提高图像处理的计算速度。本文通过对3种常见影像处理算法的CUDA编程设计实现,得到了在精度不变的情况下,GPU并行比CPU串行算法执行速度有显著提高的结论,大幅度提高了现阶段低空遥感影像处理的速度。
二、可编程图形处理器及编程模型
可编程图形处理器是由NVIDIA公司开发的具有高性能数据处理特性的集成到显卡上的专用硬件,它的型号有 TESLA、QUADRO、GTX等。其中,TESLA专用于数值计算;QUADRO专用于图像处理和显示。FREMI 2.0及以上的GPU已经基本支持C++和数值double类型,可以提供更加便利的开发环境和更高的精度。GPU硬件正逐渐走向成熟,在硬件架构上主要是采用了统一处理架构和引入了片内共享存储器,支持随机写入和线程间通信,因此它可以轻松实现Tflops级计算精度。
CUDA是基于CPU和GPU的异构编程模型,它把CPU作为主机端(host),GPU作为协处理器或者设备端(device),因此在一个系统中可以有一个主机端和若干个设备端,它们协同合作。在CUDA异构模型中,CPU主要负责逻辑性强的事务处理及与硬盘的数据交换,GPU则专注于执行高度密集线程化的数据并行处理,它们之间的数据交换通过内存和显存的数据拷贝来完成。PCI-E3.0接口的上下行速率已经达到了16 GB/s,GPU的显存带宽已经达到了140 GB/s。
CUDA编程模型的计算步骤基本分为3步:①待处理数据从内存拷贝到显存;②GPU并行数据处理;③处理后的数据从显存拷贝回内存。GPU多线程处理是通过__global__函数来驱动的,称为内核函数。内核函数的参数规定了 Grid、Block与Thread间的层次并行模型。
CUDA编程模型并不一定适用于所有的编程算法,但适合的算法必须满足它的统一编程模型架构。CUDA编程模型对算法的要求主要有以下几点:
1)数据量很大,计算复杂度高。因为内存和显存的拷贝同样占用时间,如果数据量不大,计算复杂度小,有可能出现CPU比GPU运算速度快的情况。
2)数据可分块。数据块之间具有相互独立性且计算步骤十分相近。
3)算法本身应尽可能地少用逻辑判断。因为GPU有很多计算单元,但逻辑单元非常少。
4)GPU编程时一定要注意其数据访存模式。必须实现对全局存储器的合并访存,以及对常数存储器、纹理存储器和共享存储器的合理应用。
三、影像处理算法分析CUDA设计
1.正射纠正算法分析设计
影像正射纠正算法用于改正航摄过程中由航摄轴倾斜、中心投影、大气折光、地球曲率等因素的影响而产生的影像几何变形。它的主要流程依次包括建立纠正后影像框架、共线方程计算像点坐标、灰度内插赋值。正射纠正算法在CPU端主要的费时操作是共线方程计算像点坐标和灰度插值,这两个过程有大量的循环和计算。
1)共线方程可以解算出正射后影像每个点的地面坐标所对应源影像上的每个点像元坐标的映射关系。其公式为

式中,Zuv为对应点的高程,由DEM内插求得。
2)灰度内插就是把对应的源影像上相关位置的灰度值赋值给正射后的影像,拟采用双线性内插方法。
根据以上算法分析,每一个像素点都要进行共线方程解算新位置并插值计算像素值。共线方程映射关系具有相对的数据独立性,利用GPU并行处理技术更适合CUDA编程模型。
根据正射纠正算法分析和CUDA编程模型,整个算法的实现流程如下:①CPU读取影像和DEM等数据,以及纠正后建立的影像,将这些数据均存放在内存中;②CPU把算法需要的数据由内存拷贝到显存,同时为纠正后影像开辟显存空间,原始影像和DEM数据访问具有不对称性,可放入纹理存储器来缩短访问时间,纠正所需的常用参数则放入共享存储器来加速访问;③在GPU端,利用CUDA编程模型的多线程并行处理技术来实现共线方程,灰度插值在各线程内部进行,全局存储器均采用合并访存的方式访问,以避免各项访问冲突;④在CPU端,把纠正后影像拷贝到内存,释放各种GPU存储器资源,并将纠正后数据写入硬盘。
2.快速傅里叶变换算法分析
快速傅里叶变换(fast Fourier transform,FFT)的基本思想是利用DFT旋转因子的周期性和对称性,使长序列的DFT分解为更小长度的DFT,然后利用这些小的DFT计算来代替大的DFT计算,从而达到提高效率的目的。FFT算法在CPU端主要的费时操作是因为像幅大、循环次数多、计算较为复杂。
设x(n)为长度为N的有限长序列,则其离散傅里叶正变换(DFT)为

式中,WN=,称为旋转因子或蝶形因子。
通过两次调用一维快速傅里叶变换即可实现二维快速傅里叶变换。二维快速傅里叶变换的输入相当于一个M行N列的复数矩阵,对其每行进行一维快速傅里叶变换,再对其每列进行一维快速傅里叶变换,这样就达到了变换的目的。
根据以上算法分析,每一个像素都要依次进行行列各一次DFT变换。此算法具有相对的数据独立性,可以利用GPU并行处理技术,适合CUDA编程模型。
本试验编程调用了CUFFT函数库。CUDA提供了封装好的CUFFT库,它提供了与CPU上的FFTW库相似的接口,能够让使用者轻易地挖掘GPU的强大浮点处理能力,不用自己去实现专门的FFT内核函数。使用者通过调用CUFFT库的API函数,即可完成FFT变换。
3.高斯差分算法分析设计
高斯差分是SIFT匹配算法的关键步骤,它包括影像空间域卷积和生成DOG影像。影像空间域卷积算法简单,即用一个窗口模板移动来平滑整幅影像;再把不同卷积模板卷积的影像对应位置相减即得到高斯差分图像。高斯差分算法在CPU端所需时间主要还是消耗在大量的循环和复杂的计算中。
本次试验算法决定使用5幅卷积图像生成1组4层高斯差分影像。为了简便算法,设计把二维卷积变换为先行卷积再列卷积,再利用卷积图像相减得到差分图像。
根据以上算法分析,每一个像素点都要先行卷积再列卷积,再对应位置相减。此过程具有天然的数据独立性,非常适合GPU并行CUDA编程模型。
根据高斯差分算法分析和CUDA编程模型,整个算法的实现流程如下:①CPU读入影像,生成卷积模板;②CPU把影像和模板数据开辟,并拷贝显存空间,影像放入全局存储器,采用合并访存的方式访问,因为模板具有重复使用性和不改变性,所以放入共享存储器来提高访问速度,另外还需在全局存储器中开辟5幅中间影像空间和5幅高斯差分结果空间;③在GPU端,为了确保列变换之前行变换已完成,采用CUDA中的流控制来依次启动行列两个卷积Kernel函数,利用CUDA编程模型的多线程并行处理技术来拆分多次循环,卷积在各线程内部进行,每个线程负责一个像素点的相减;④在CPU端把4幅高斯差分影像拷贝到内存,释放各种GPU存储器资源,并将差分影像写入硬盘。
四、CUDA试验及精度时间分析
1.试验环境
为了更有效地说明图形处理器在遥感影像快速处理领域的作用,本文所有编程试验均在统一的电脑配置环境下进行,除了添加一个GPU Quadro 4000显卡外,其余配置都和经典编程环境一致。
算法实现的主要硬件平台:CPU为Intel(R)Xeon(R)CPU W3550@3.07 GHz4核8线程;GPU为NVIDIA Quadro 4000。
算法依赖的主要软件平台:Windows XP X86、Visual Studio 2008、NVIDIA GPU Computing Toolkit(CUDA 4.1)、FFTW和 CUFFT函数库。
为了更好地体现图形处理器的性能,不仅要对多幅不同像幅的原始遥感影像进行处理,还要分析算法在CPU和GPU上运算数据精度和时间的差异。
2.CPU与GPU数据精度分析
由于CPU和GPU由不同的处理单元组成,对单浮点和双浮点类型的支持可能不同,因此有可能会造成除法保留的小数位不同,最终造成影像灰度级别的差异。同时,由于算法必须为适合CUDA统一编程模型而作适当的修改,同样可能存在差异,因此必须对比它们的数据精度。在此,仅以单波段正射纠正为例,将基于CPU和GPU获得的影像进行数据精度分析,统计两者的差异。
图1与图3分别表示CPU正射纠正后部分影像图和部分像素值图(保留小数点后3位),图2与图4则表示GPU的相同内容。图1和图2对比,影像图在视觉上无差别;图3和图4对比,相对应部分像素值内容完全相同。为了确保结论的正确性,令CPU与GPU正射纠正后的两幅影像相对应像素值相减,再对结果进行统计,发现所有对应像素位置的差值均为零。综上所述,说明GPU在数据精度上与CPU处理精度相同,达到了遥感影像快速处理对数据精度的要求。

图1 CPU正射纠正后部分影像图

图2 GPU正射纠正后部分影像图

图3 CPU影像部分像素值

图4 GPU影像部分像素值
3.CPU与GPU时间分析
为了更加充分地说明GPU加速遥感影像处理的能力,采用像幅大小分别为1024像素×1024像素、2048像素×2048像素、4096像素×4096像素的遥感影像进行时间统计对比分析。测试结果见表1。
由表1计算可见,正射纠正的最高加速比为1947/377=5.16;FFT的最高加速比为2453/233=10.53;高斯差分的最高加速比为3057/330=9.26。由图5分析可得,GPU处理遥感影像的加速比随着像幅的增大而增加,这说明在不超过GPU存储单元容量的条件下,遥感影像数据量越大越能体现GPU的加速效果,也能得到更大的加速比。仅从表1处理时间上分析,利用GPU并行处理技术可以在4096像素×4096像素像幅的情况下获得比CPU串行高达一个量级的加速比,向影像快速处理迈进了重要一步。
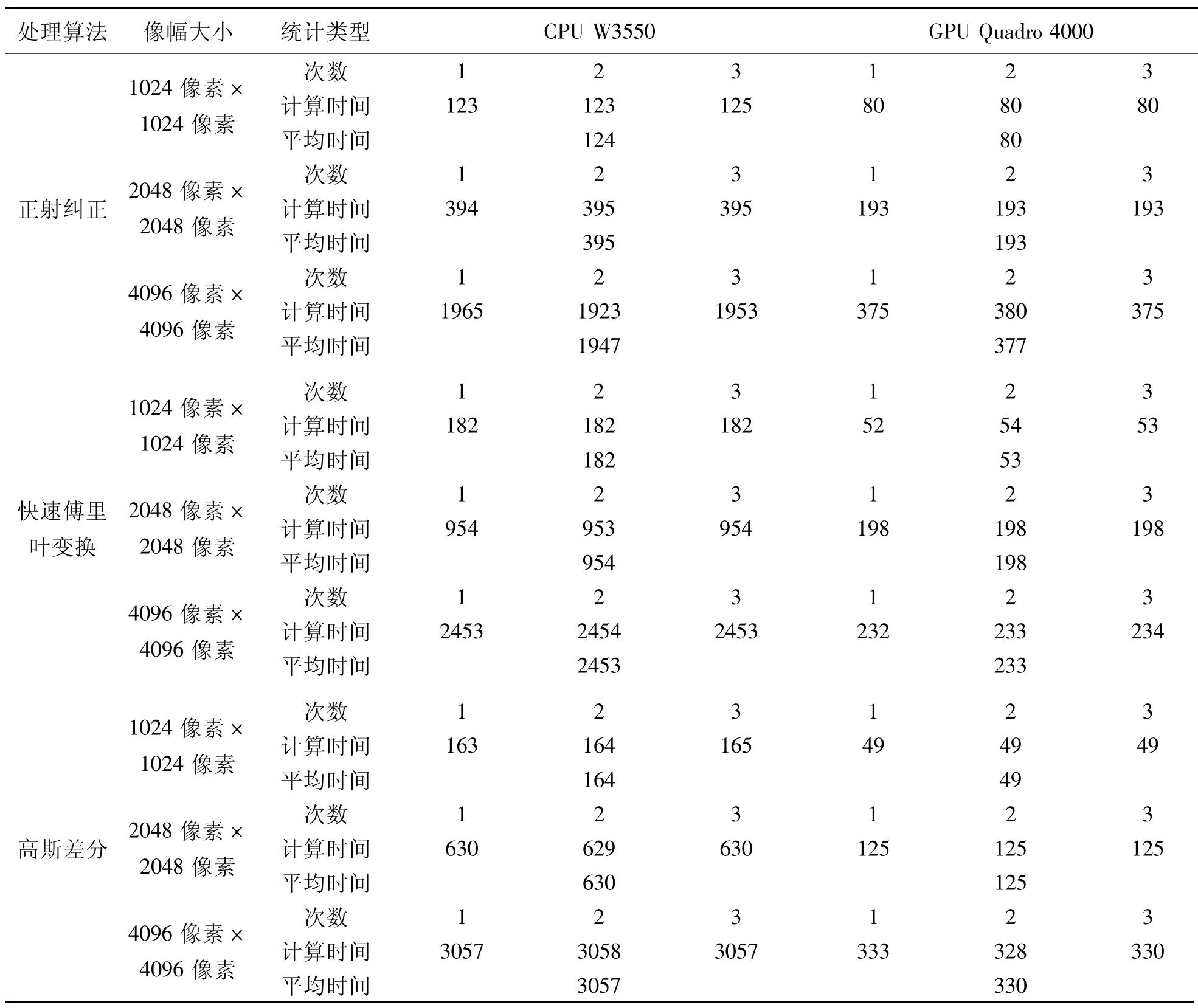
表1 测试结果ms

图5 GPU加速比
五、结束语
基于以上的试验结果分析,GPU能够在影像正射纠正、快速傅里叶变换和高斯差分方面得到明显的加速,并能够在数据精度上与CPU保持一致的情况下,大幅提高遥感影像的处理速度。遥感影像处理是针对像素的操作,数据处理具有以下特点:数据量大、计算复杂、处理方法固定、处理方法具有内在的并行特性等。遥感影像处理的这些特点决定了它适合于GPU的并行处理架构和CUDA编程模型。笔者认为利用GPU技术能够实现遥感图像快速处理领域的巨大飞跃。
[1]张舒,楮艳利.GPU高性能运算之CUDA[M].北京:中国水利水电出版社,2009:10.
[2]张剑清,潘励,王树根.摄影测量学[M].武汉:武汉大学出版社,2003:158-162.
[3]周海芳,遥感图像并行处理算法的研究与应用[D].长沙:国防科技大学,2003.
[4]刘勇,使用GPU加速通用科学计算-CUDA技术解析[J].科技信息,2008(24):394-395.
[5]杨靖宇,张永生,张宏兰,等.基于可编程图形硬件的遥感影像并行处理研究[J].测绘工程,2008,17(3):21-22.
[6]杨志义,朱娅婷,薄勇,基于统一计算设备架构技术的并行图像处理研究[J].计算机测量与控制,2009,17(4):734-737.
[7]SINHA SN,FRAHM JM,POLLEFEYSM,et al.Feature Tracking and Matching in Video Using Programmable Graphics Handware[J].Machine Vision and Application,2007,22(1):207-217.
[8]NVIDIA.NVIDIA CUDA Computer Unified Device Architecture Programming Guide[M].version 2.0.NVIDIA:[s.n.],2008.
[9]GARCIA V,DEBREUVE E,BARLAUD M.Fast KNearest Neighbor Search using GPU[C]∥IEEE Confidence on Computer Version and Patter Recognition Workshops.Alaska:[s.n.],2008:1-6.
[10]VASILIADIS G,ANTONATOS S,POLYCHRONAKIS M,et al.Gnort:High Performance Network Intrusion Detection Using Graphics Processors[C]∥Recent Advance in Intrusion Detection(RAID).Heidelberg:Springer-Verlay,2008:116-134.
