基于能量竞争学习算法的特定人数字语音识别
2013-12-10五邑大学信息工程学院梁兴隆张歆奕
五邑大学信息工程学院 梁兴隆 张歆奕
1.引言
现存的一些矢量量化方法一般都需要预先确定码本大小,比如LBG[1],K-means算法等,然而在现实条件很难预先确定码本大小。由中山大学赖剑煌教授和王长东提出的基于能量的竞争学习算法[2]应用在图像分割中,这种算法能自动确定数据聚类个数,能够保持类的大小(即一个类中所包含的样本个数)和稀疏度(类中样本的稀疏程度)均衡,并且具有自适应学习速率;本文尝试将基于能量的竞争学习算法应用到特定人汉语数字0-9语音识别中,在基于能量的竞争学习算法确定初始化码字中,笔者用广度优先搜索邻居的聚类算法进行了改进。
2.基于能量的竞争学习算法及其改进
给定一个样本集合X ={x1,...,xN},数据聚类算法试图找到K个类{c1,....,cK}使得目标函数J的值最小。对于经典的竞争学习算法,聚类的数目K要预先设定并且目标函数是失真的测量,即使得每个样本到被划分到的类的距离平方和最小。

在式子(1)中,wk是ck类的原型,。T为中元素的数目,k(n)将xn划分到ck(n)。目标函数JCCL是根据两个假设而提出来的,一是各个类的先验概率要相等,即:P( ck)=1/K,∀k=1,...,K,二是每个类的协方差矩阵∑k和单位矩阵成比例,即:所以这种算法只适用于大小和稀疏度相同的类。为了适应大小和稀疏度不同的类,目标函数定义如下:

2.1 样本之间的权重矩阵
为了得到式子(2)的最小值,并且能够自动估计出要聚类的数目K,我们采用基于能量的竞争学习算法。我们构建样本集合的权重矩阵
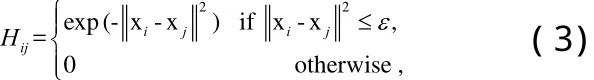
在式子(3)中,ε是一个指示xi和xj是否相似的一个参数。ε最恰当的值是点与点之间欧氏距离的均值,即:
权重矩阵反映出了样本之间距离的权重。点xi与点xj之间的距离越近,那么权重值Hij越大。
2.2 样本能量矢量
给定权重矩阵H后,我们接下来就定义样本能量矢量e=[e1,...eN]T

这个定义考虑了待聚类的所有样本之间距离的关系,所以样本的能量具有全局的意义。
2.3 主点集和边缘点集
主点集:主点集y是样本点集合x中具有较高能量的点所组成的集合,主点集中包含的点的数量是样本集合中点的数量的一半,即:

边缘点集:边缘点集是样本点集合中主点集的补集,即,
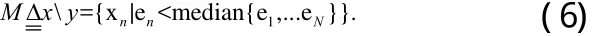
2.4 基于广度优先搜索邻居算法的聚类初始化
d( p, q)为对象p和对象q之间近似性的量化表示。估算d( p, q)的方法很多,如欧几里德距离、曼哈顿距离、名考夫斯基距离、切比雪夫距离等。相异度矩阵用来存储n个对象两两之间的近似性d( p, q)。给定对象p及距离参数ε,对于任意对象x,若d( p, x)≤ε,则称x为p的直接邻居,简称邻居;对象p的所有邻居的集合称为p的全部邻居,记为Dp。
设n个对象p1, p2,...,pn-1,pn满足pn仅是pn-1的邻居,p1仅是p2的邻居,pk是pk-1和pk+1(1<k<n)的邻居,则p3,p4,...,pn都是p1的间接邻居。对象p所有间接邻居的集合称为p的全部间接邻居,记为Ip。

既然主点集中不存在边缘点,所以主点集中的对象根据这个算法会自动分为若干类。类间的平均距离要远远大于类内点与点之间的平均距离。在这里,参数ε的最佳取值为主点集点与点之间欧氏距离的均值,即:。主点集y被划分为K个部分{ˆ,...,cK},本文将这K个部分作为初始化的聚类,各个初始化聚类的均值{w1,...,wK}作为初始化的原型。
2.5 更新原型

表2 基于EBCL和LBG算法的0-9数字识别用时比较

图1 仿真实验过程图
原型{w1,...,wK}的更新要不断重复下面三个步骤来完成:
(1)x选择获胜的原型:从样本集合X随机选取n,通过使下面的式子取得最小值来选取获胜的原型:

(2)更新获胜者:通过下面的式子来更新获胜的wk(n):
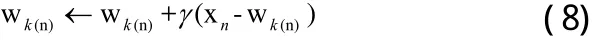
在这个式子中,γ表示基于样本能量的自适应学习速率,比如,我们可以在仿真中设置γ的取值为 γ=en/10。
(3)更新获胜原型的能量:通过下式来更新获胜原型的能量

在式子(9)中,fk(n)表示原型wk(n获胜的频率。nk表示wk赢得的次数的累加和,那么一个聚类中所包含的样本数量越多,样本与样本之间的距离越小,那么这个类所对应的原型的能量越大,反之则小。结合式子(9)和式子(2)可以看出来,获胜原型能量的更新能够保持一个类的大小和稀疏度比较均衡。
3.特定人数字语音识别仿真实验及结果
3.1 实验方案
用特定说话人进行汉语数字“0-9”的发音进行测试。实验方案:用coolpro2软件录音,设定的采样频率fs=16000HZ;每个样本点用16bit量化;声道选择为单声道;对每个数字分别进行50次录音,前15个录音用于训练,最后35个录音进行测试。试验中每个数字语音建立一个码本,提取每个数字语音(比如数字语音“1”)的15个训练样本的特征矢量,然后将这15个训练样本的特征矢量形成一个集合,将使用基于能量的竞争学习算法对这个集合进行聚类得到这个数字的码本。依次得到10个语音数字的码本作为参考模板。语音特征参数采用20维的梅尔倒谱系数(Mel-Frequency-CepstrumCoefficents,MFCC[4])。Matlab仿真实验过程如图1所示。
端点检测:端点检测[5](Endpoint-Detection)的目标时要决定语音信号开始和结束的位置。常用的方法分为时域方法和频域方法,前者计算量比较小,适合计算能力较差的微电脑平台;后者计算量比较大。本文采用时域方法,以音量为主,过零率[6]为辅来进行端点检测。端点检测方法简述如下:
(1)以高音量门槛值(τu)为标准,决定端点。
(2)将端点前后延伸到低音量门槛值(τl)处。
(3)再将端点前后延伸到过零率门槛(τzc)处,以包含语音中的气音部分。
预加重:将语音信号通过一个高通滤波器H(z)=1-a*z-1,a介于0.9和1.0之间,仿真中采用的值为0.96。
分帧:每帧包含256个采样点,相邻两帧重叠218个采样点。
加窗:采用汉明窗,窗函数为:

将每一帧乘上汉明窗,以增加左端和右端的连续性。
模板匹配方法:设待识别语音提取的特征矢量序列为 o1, o2, o3,...oT,然后用训练好的码本进行计算:
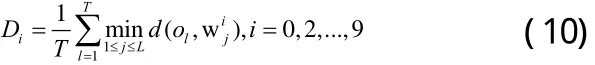
3.2 实验结果
本文的仿真结果和经典的矢量量化的LBG算法进行了对比。表1对比了两个算法的识别率,表2对比了两种算法码本大小以及仿真程序运行一次所需的时间。
4.结论
本文将EBCL学习算法运用在特定人的数字语音识别中,这个算法的优点就是能够自动初始化,自动确定码本的大小,这是此算法相对于以往的矢量量化算法所不具备的优点。从表1可以看出基于EBCL的数字语音识别可以达到较高的识别率,比经典的LBG算法的识别率还要高;LBG算法在码本提取中需要事先确定码本大小而EBCL能够自动确定码本大小,从表2中可以看出,在识别率相当的情况下,用EBCL算法获得的每个数字语音的码本大小不尽相同而LBG算法获得的码本大小是固定的;EBCL获得的码本的大小相对于LBG的更小,这样使得码本存储空间更小,EBCL算法识别时间更短。将此算法运用到非特定人数字语音识别中时我们今后工作的重点。
[1]刘刚,刘晶,王泉.使用新的码字分割方法的快速LBG算法[J].计算机工程与应用,2009,45(28):199-202.
[2]Chang-DongWang,Jiang-HuangLai.Energybasedcompeti tivelearning[J].Neurocomputing,2011,74:2265-2275.
[3]钱江波,懂逸生.一种基于广度优先搜索邻居的聚类算法[J].东南大学学报,2004,34(1):109-113.
[4]蔡莲红,黄德智,蔡锐.现代语音技术基础与应用[M].北京:清华大学出版社,2003:236-238.
[5][6]胡光锐,韦晓东.基于倒谱特征的带噪语音端点检测[J].电子学报,2000,28(10):95-98.
