面向农业物联网多环境信息融合的监测判别
2013-12-07张向飞丁永生郝矿荣
刘 倩,张向飞,丁永生,2,郝矿荣,2
(1.东华大学信息科学与技术学院,上海 201620;2.数字化纺织服装技术教育部工程研究中心,上海 201620)
物联网是通过射频识别、全球定位系统、激光扫描器等信息传感设备,按约定协议,把任何物品与互联网连接起来,进行信息交换和通信,以实现智能化识别、定位、跟踪、监控和管理的一种网络[1-3]。物联网为农田信息获取提供了崭新的思路,将传感器节点布设于农田等目标区域,网络节点大量实时、精确地采集温度、湿度、光照、气体浓度等环境信息,这些信息在数据汇聚节点汇集,网络对汇集的数据进行分析,帮助生产者有针对性地投放农业生产资料等,从而更好地实现耕地资源的合理高效利用和农业现代化精准管理,推进农业生产的高效管理,提升农业生产效能[4-5]。面向农业物联网的多环境信息融合的监测判别就是在此基础上的一次实践。
信息融合是利用已有的知识经验来处理从未知世界得到的来自不同领域的数据,强调通过分析来自多个传感器或多个数据源的信息对目标进行识别估计或做出某种综合判断。数据挖掘主要是通过统计或人工智能的方法从大量原始数据集合中推测寻找数据间复杂的潜在关系或蕴涵的模型。本文采用模糊推理方法对采集的环境信息进行决策级的融合分类,并引入由关联规则挖掘所得的知识库,定量地分析多种环境信息的协调关系,从而进行多环境信息融合的监测判别,这不仅是监测农业环境的有效手段,而且可为动态地控制环境的各项指标提供依据。
1 面向农业物联网的环境指标判别模型
基于多环境信息融合的监测判别关键是采用合适的分类融合算法,将采集来的多种环境信息与知识库中的典型关联规则相结合,进行决策级融合分类以反映农田环境的状态,同时建立和谐的人机交互环境,从而对农田的环境状况进行监测控制。
图1为面向农业物联网的多环境信息融合的监测判别模型框架,通过分布在农田的环境信息传感器采集各种环境信息,将之与从数据库等媒介中挖掘出的典型关联规则传输到中央处理模块进行信息融合,最后将监测结果送到用户交互界面。
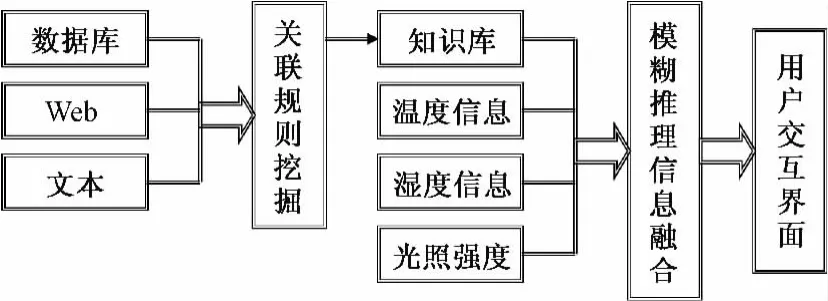
图1 多环境信息融合监测判别模型框架
2 基于关联规则和模糊推理的信息融合算法
2.1 关联规则理论
关联规则的挖掘问题可形式化地描述如下:设I= {i1,i2,…,im}是项集合,T= {t1,t2,…,tm}是事务集合,其中Ati∈I(1≤i≤n)。A⇒B称为T中的关联规则,其中A⊂I,B⊂I,A∩B=C。在事务集合T中,包含A∪B的事务占全部事务的百分比称为T中关联规则A⇒B的支持度记为support(A⇒B)=P(A∪B);包含A∪B事务占包含A事务的百分比称为T中关联规则A⇒B的置信度,记为 confidence(A⇒B)=P(A|B)。设min_sup是最小支持度阈值,min_conf是最小置信度阈值。若事务集合T中的关联规则A⇒B同时满足support=(A⇒B)≥min_sup和confidence=(A⇒B)≥min_conf,则A⇒B称为T中的强关联规则。包含k个项的集合称为k-项集,如果项集满足最小支持度,则称其为频繁项集,频繁k-项集的集合通常记作Lk。
目前有多种产生频繁项集的算法,最著名的是Agrawal等[6-8]提出的 Apriori算法。Apriori算法使用逐层搜索的迭代方法,k-项集用于搜索 (k+1)-项集,利用“任意频繁项集的子集都是频繁项集,任意弱项集的超集都是弱项集”这一性质扫描事务集合。
Apriori算法由两部分组成。首先使用候选项集找出频繁项集,基于频繁k-项集Lk,采用自连接方法产生所有可能频繁的 (k+1)-项集,即候选 (k+1)-项集Ck+1,再扫描1次事务集合,统计Ck+1中每个候选的支持度,并与最小支持度阈值相比,形成频繁 (k+1)-项集Lk+1;接着由频繁项集产生关联规则,对于每个频繁项集L,产生L的所有非空子集,对于L的每个非空真子集Lu,如果L的支持度除以Lu的支持度大于等于最小置信度阈值,则输出规则Lu⇒ (L-Lu)。
2.2 模糊推理理论
模糊推理是采用模糊逻辑并实现由给定的输入到输出的映射过程,具体表现为运用模糊语言规则,对已知的模糊判断或模糊命题进行推导而得出新的近似模糊判断结论的过程。模糊推理步骤主要包括:输入变量模糊化;在模糊规则前件中应用模糊算子;根据模糊蕴含运算由前提推断结论;模糊合成;输出变量反模糊化[9]。
利用模糊推理可针对复杂系统建立拥有输入输出数据的模糊推理系统,同时还可与其他人工智能技术相结合形成智能融合型模糊推理系统。模糊推理信息融合过程为模拟人脑处理不确定性信息的过程,其基本思想可描述为:采用模糊集和隶属函数描述多传感器所获信息;根据不同领域专家知识建立不同的模糊规则;利用各种模糊逻辑算子在进行模糊推理过程中实现多传感器信息的融合处理;推导出模糊推理信息融合的最终结果。
3 结果与分析
3.1 数据预处理
从农业数据库中获取10组环境信息与专家监测判别指标的分析数据 (表1)。由于所有的分析数据均为非离散的数值属性,故应先进行离散化处理 (表2)。预处理后的数据如表3所示。

表1 历史数据

表2 各因子离散化等级

表3 预处理后的数据
3.2 基于Apriori的关联规则挖掘
设min_sup=20%,min_conf=60%。根据Apriori算法编写程序,搜索原始数据表,得到满足最小支持度阈值和最小置信度阈值的关联规则(表4)。这些关联规则的左边为各种环境信息所对应的等级值,右边为监测结果所对应的等级值。

表4 关联规则挖掘结果
3.3 基于模糊推理的信息融合
根据表2的各因子离散化等级,确定各种环境信息和监测结果的隶属函数,为保证基于模糊推理的信息融合的实时性和快速性,采用三角形隶属函数。接着,将表4的关联规则挖掘结果转换成相应的模糊规则,如关联规则A1C1⇒E3可解释为当温度信息属于等级1,CO2浓度属于等级1时,监测结果属于等级3,此时模糊规则可表示为If(A is A1)and(C is C1)then(E is E3)。
最后对基于模糊推理信息融合的多环境信息融合监测判别进行仿真研究,通过MATLAB语言编程来实现这一过程。用addvar函数定义基于模糊推理信息融合的各种环境信息的输入变量和监测结果的输出变量,用addmf函数定义模糊推理系统输入、输出变量的隶属函数,用 rulelist函数和addrule函数来定义模糊规则,至此,基于多环境信息融合监测判别的模糊系统已经设计完成。此外,还可利用showrule函数查看模糊推理系统的模糊规则,利用fuzzy函数调用模糊推理系统的图形用户界面,进行信息融合的控制决策仿真,在图形用户界面下,还可以查看模糊推理的过程示意图。通过命令窗口,利用evalfis函数进行实时仿真,将实际监测结果与仿真所得信息融合结果比较 (表5),5组数据中仅1组结果有较大偏差,正确率达80%以上。
4 小结
本研究探讨了将模糊推理的方法运用到基于多环境信息融合的监测判别,并引入关联规则挖掘,将基于典型数据挖掘出的关联规则转换成相应的模糊规则后,监测识别率有明显的提高。从关联规则挖掘到信息融合分类,再到最后的监测判别,其中的Apriori算法在产生关联规则的同时,由于要多次扫描数据库并产生大量的候选集,故在算法的计算复杂度方面还有待改进;其次,测试数据量有待进一步增加,从而使得测试结果更具精确性和说服力;最后,在多环境信息融合监测判别模型框架中,关联规则挖掘之前的异构数据库数据集成和信息抽取,以及模糊推理信息融合后的人机交互界面均有待进一步设计,从而完成整个系统的集成。

表5 实际监测结果与信息融合结果的比较
[1] Teixeira L,Hachem S,Issarny V,et al.Service oriented middleware for the internet of things:A perspective[M] //Towards a Service-Based Internet.Springer Berlin Heidelberg,2011:220-229.
[2] Kulkarni R V, Forster A, Venayagamoorthy G K.Computational intelligence in wireless sensor networks:A survey[J].IEEE Communications Surveys & Tutorials,2011,13(1):68-96.
[3] Atzori L,Iera A,Morabito G.The internet of things:a survey [J].Computer Networks,2010,54:2787-2805.
[4] 张飞舟,杨东凯,陈智.物联网技术导论 [M].北京:电子工业出版社,2010:6.
[5] 彭力.物联网技术概论 [M].北京:北京航空航天大学出版社,2011:9.
[6] Agrawal R,Srikant R.Fast algorithm for mining association rules[C].Proceedings of the20th International Conference on Very Large Data Bases.Santiago Chile,1994:487-499.
[7] Srikant R,Agrawal R.Mining quantitative association rules in large relational tables[C].Proceedings of the ACM-SIGMOD Conference on Management of Data.Washington D C,1996:1-12.
[8] Agrawal R,Imielinski T,Swami A.Mining association rules between sets of items in large databases[A].Proceedings of the ACM SIGMOD International Conference on Management of Data,1993:207-216.
[9] 丁永生.计算智能:理论、技术与应用[M].北京:科学出版社,2004.
