决策树方法在药物选择模型中的应用
2013-12-06汪卫霞
张 燕 汪卫霞
(安徽财经大学管理科学与工程学院,安徽 蚌埠 233030)
信息技术的发展推动着数据的不断增加,如何从海量的数据中提取所需的信息成为人们关注的焦点,通过人类的长期试验数据挖掘应运而生。数据挖掘是指从大量的数据中提取出有价值的信息的过程。数据挖掘工具通过对未来的预测影响人们的决策。其常用方法有人工神经网络、贝叶斯网络、遗传算法、QUEST、决策树方法等。决策树以树的形式显示数据挖掘的结果,它具有结构简单,构造时间短,输出结果通俗易懂,准确度高的优点。因此,它在数据挖掘中应用较广。但决策树方法也有其固有缺点,即运用决策树方法时很难发现规律。有多种算法可以构建决策树,ID3和C5.0是决策树中的典型算法,文章以C5.0算法对药物选择过程进行挖掘分析,并给出了挖掘分析的结果。
1 决策树的概念及其构建过程
决策树是指采用由上而下的递归方式对数据进行归类,使得归类后的数据具有相同属性并以树的形式显示分类结果的过程。决策树包括分类树和回归树,分类树用于对离散变量做决策,而回归树用于对连续变量做决策。决策树的根节点是整个数据的集合,每个分节点代表某一属性的测试,该测试将数据集合分成众多子集合。每个叶节点代表了一个类或类分布。连接根节点和叶节点之间的那条线表示一种分类规则。决策树的构造步骤是:树的根部作为数据的集合首先数据由根部递归进行分类,然后对树进行修剪,去掉那些其干扰作用或者异常的数据。当树的某个分节点的数据具有相同属性,而没有其他属性再分割时就停止该分支的分割,当所有的分支都停止分割时最终的树就形成了。
2 决策树方法在药物选择中的应用实例
假设一名正在整理数据的医学研究者收集了一组患有相同疾病的病人的数据,在病人的治疗过程中,由于每个病人自身状况的不同对药物的反应也不同。现在有五种药物可供选择,每个人都对5种药物的一种有反应。病人的血压、年龄、胆固醇、血液中的钠和钾离子的含量都会影响药物的选择产生影响。本模型通过200名患者服用5种不同药物的反应结果和每个病人的血压、胆固醇、血液中的钠和钾离子的含量应用决策树方法为未来患有此类疾病的病人寻找适合自身状况的药物。
2.1 商业理解
本文以服用可供选择的5种药物的200患者为分析对象。
2.2 数据理解
从目标数据源中提取数据挖掘的目标数据集进行数据预处理评估相关因素包括:血压、年龄、胆固醇、血液中的钠和钾离子的含量。
2.3 建立模型
本节,假设一名正在整理数据的医学研究者收集了一组患有相同疾病的病人的数据,在他们的治疗过程中,每个人都对5种药物的一种有反应。研究员工作的一部分是利用数据挖掘为未来患有同样疾病的病人找出适合他们的药物。这个示例名为druglearn.str流,它引用的数据文件名drug1n。这些文件可以从任何客户端与演示目录安装。这可以从桌面Clementine程序组访问的开始菜单启动。druglearn.str文件在分类模块中。
在演示中使用的数据域如表1:
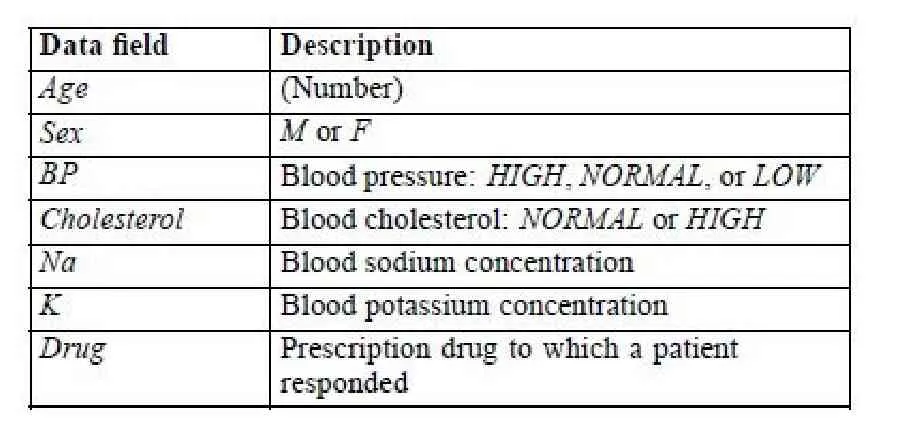
表1 演示中使用的数据域
2.4 执行步骤
第一步:添加一个变量节点,使用一个可变的文件节点读取带分隔符的文本数据。首先添加一个变量文件节点从从调色板中单击“源”选项卡上找到的节点或使用收藏夹选项卡,其中包括这个节点的默认。其次,双击新放置的节点打开对话框。
第二步:打开可变文件对话框。首先单击该按钮在文件中标有省略号(……)文件箱右边来浏览装在你系统中的数据挖掘目录,打开Demos文件并选择文件drug1n,然后选择读取字段名称并注意刚刚被加载到对话框的文件的字段和值。
第三步:对打开的对话框进行设置,在类型上选择值单击“数据”选项卡来重写和更改字段存储。注意存储不同于类型或使用的数据字段。通过类型的选项卡可以了解数据中更多的字段类型。对每个从数值表中选择的字段也可以通过选择读值查看每个字段的实际值。这个过程被称为实例化。
第四步:添加一个表。建立一个包括表节点的流。将一个表节点放入流中,可以双击图标调色板或拖放到画布上来看一些的值记录。
第五步:将表节点连接到数据源,并从工具栏执行流。双击节点从调色板将自动连接到在所选节点流的画布。另外,如果节点不是已连接,可以使用中鼠标按钮连接源节点到节点的表。模拟鼠标中键,按住 Alt键的同时,用鼠标。单击绿色箭头按钮工具栏执行流,或右键单击表节点并选择执行查看表。
第六步:创建一个分布图,数据挖掘过程中,通过创建可视化的总结来探索数据常常是很有用的。Clementine提出了几种不同类型的图供选择,这取决于你要总结的数据类型。例如,使用分配节点找出每种药物的患者反应比例。添加一个分布节点的流,并将其连接到源节点,然后双击编辑可显示的选项。将想要显示的药物分布选择为目标字段。然后,从对话框单击“执行”,并选择药物为目标字段。药物反应的分布图(图1),通过结果图可以看到“成形”的数据。结果表明,患者对药物Y反应最常见,对药物B和C反应最少见。同时也可以快速浏览所有字段的数据和直方图后连接和执行审核节点。

图1 药物反应分布图
第七步:创建一个散点图找出必然会影响药物的因素,并将其作为目标变量。医学研究者都知道在血液中钠和钾的浓度是重要的元素。首先创建一个用药品的类别作为颜色叠加的钠和钾的散点图,因为这些都是数字值。使用该药物的种类作为一种颜色叠加,在工作空间放置一个图节点(图选项上)并把它连接到源节点,然后双击编辑节点。在选项卡图上药物覆盖领域选择钠作为X,钾作为Y字段。单击“执行”。然后,创建一个散点图(图2),从图2可以清楚地的看出阈值以上药物Y是最好的选择,而阈值以下就不是药物Y了此阈值是一种比例即钠(Na)比钾(K)。

图2 散点图
第八步:创建一个 web图,由于许多数据域是绝对的,因此可以尝试绘制网络图反应不同类别之间的关联。首先在工作空间连接一个网络节点(图形选项上)到源节点。在Web节点对话框中,选择BP(血压)和药物。然后,单击“执行”。从图3上,似乎药物Y与三个层次的血压水平都相关。这一点也不奇怪,因为从上面的研究中已经知道 Y是最好的药物。为了专注于其他药物,可以先把它藏起来。在药物 Y点右键单击并选择隐藏并重新规划。药物对血压的网络图如图3所示:
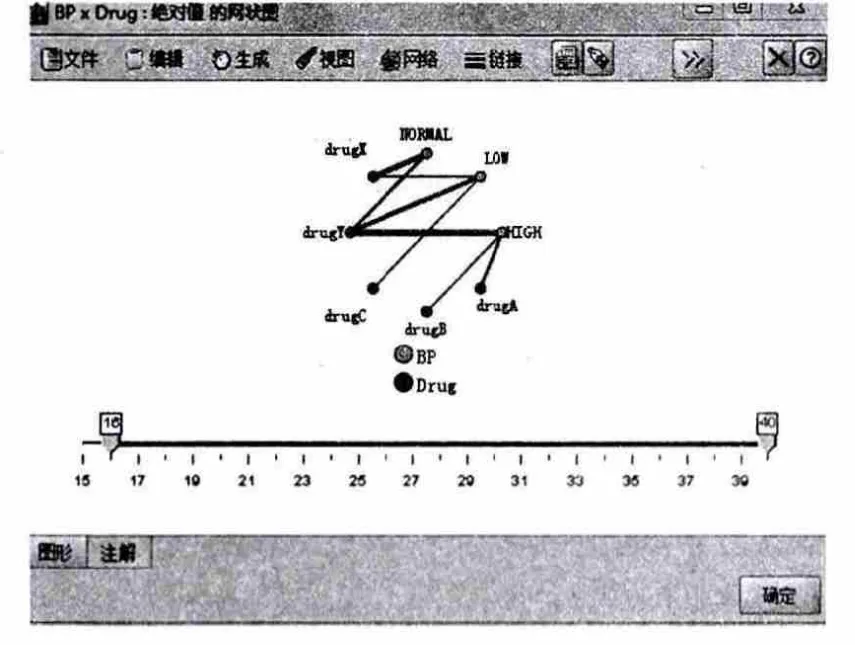
图3 药物对血压的网络图
在简化的图上,药物 Y和其所有的链接都是隐藏的。从图中可以清楚地看到,只有药物A和B与高血压有关。只有药物C和X与低血压有关。在这一点上正常血压只与药物X相关。不过,对于一个给定的病人你还不知道怎样在药物 A和B或 C和X之间进行选择,这时可以运用模拟加以确定。网络图与药物及其链接隐藏如图4所示:

图4 网络图与药物及其链接隐藏图
第九步:导出一个新的字段,由于用药物 Y时钠与钾比例似乎能预测到,因此可以为每个记录派生一个包含这一比率的字段。这个字段可能对构建一个模型来预测什么时候使用这五个药物是有用的。在流中添加一个导出节点,然后双击节点编辑。编辑导出节点,命名这个新的导出字段na_to_k。可以将钠值和钾值直接输入公式,也可以通过单击图标右边的字段创建一个公式。这将打开“表达式生成器”,一种以交互方式创建表达式使用内置列表的功能,操作数和和字段数及其值。最后,通过附加一个直方图节点派生节点检查新字段的分布。在直方图节点对话框中,指定 na_to_k作为绘制字段和药物作为覆盖领域即可得到编辑节点的直方图,当执行流时,应该得到图5所示。基于这一显示可以得出结论,当na_to_k值是15或以上,选择药物Y。
第十步: 建立一个模型,通过探索和操作数据已经能够形成一些假设。血液中钾与钠似乎会影响药物的选择,如血压。但还仍然不能解释所有的关系,如血压。这是建模可能会提供一些答案。在这种情况下,应尽量使用规则的建筑物模型拟合模型C5.0。由于使用的是导出的字段,na_to_k,可以过滤掉原来的字段,Na和 K,所以在建模算法中他们不止使用一次,可以使用一个过滤节点做这个。编辑过滤节点:在“过滤”选项卡,单击Na和K旁边的箭头,出现红叉表示字段
现在被过滤掉了。然后,将一个类型节点连接到过滤节点。允许类型节点显示已使用的该类型的字段,以及它们是如何被用来预测结果的。在“类型”选项卡上,设置了药物字段的方向,表明药物是要预测的类型。将偏离方向的其他类型设置为预测因子,再将工作区的C5.0的节点附加到流的末端显示以估计模型。然后点击绿色按钮执行流执行,当执行 C5.0节点,生成的模型节点(GEM图标)将被添加到窗口右上角的模型选项卡上。右键单击该图标并选择菜单的浏览来浏览模式。规则的浏览器显示了C5.0节点在决策树中生成的规则。通过抽象的拼图可以看到 na-to-k比率低于14.642时,高血压患者应根据年龄选择药物,对于低血压的人,应根据胆固醇水平选择药物。最初,树木是塌的,单击“所有”按钮来显示所有的层次以拓展它。点击“视图”选项卡可以在一个更复杂的图形和格式中看到同样的决策树。在这里,也可以更容易的看到每个血压层次的病例数以及病例重要性百分比。通过图6可以得出如下结论:当 na-to-k比率高于14.642时药物Y是唯一选择。当na-to-k比率低于14.642时,血压会影响药物的选择,当患者血压正常时,应选择药物X;当患者患有高血压时,年龄也会影响药物的选择,对于年龄不超过50岁的人应选择药物A,对于年龄超过50岁的人应选择药物B;而当患者患有低血压时,胆固醇会影响药物的选择,当患者体内的胆固醇含量正常时应选择药物X,而当患者体内的胆固醇含量高时应选择药物C。

图6
3 分析模型的准确性
通过分析节点可以评估模型的准确性。首先,将C5.0模型添加到流,然后附上分析节点(从输出节点和执行节点调色板)和执行流。添加分析节点后得图7:

图7
分析节点的输出显示(图8所示),通过人工干预,该模型准确预测了数据集中几乎每一个记录的药物选择。一个真正的数据集不可能有100%的准确性,但可以使用分析节点为特定的应用程序来确定模型可接受的准确度。分析节点输出的结果如下:即准确率为99.5%,错误率为0.5%。
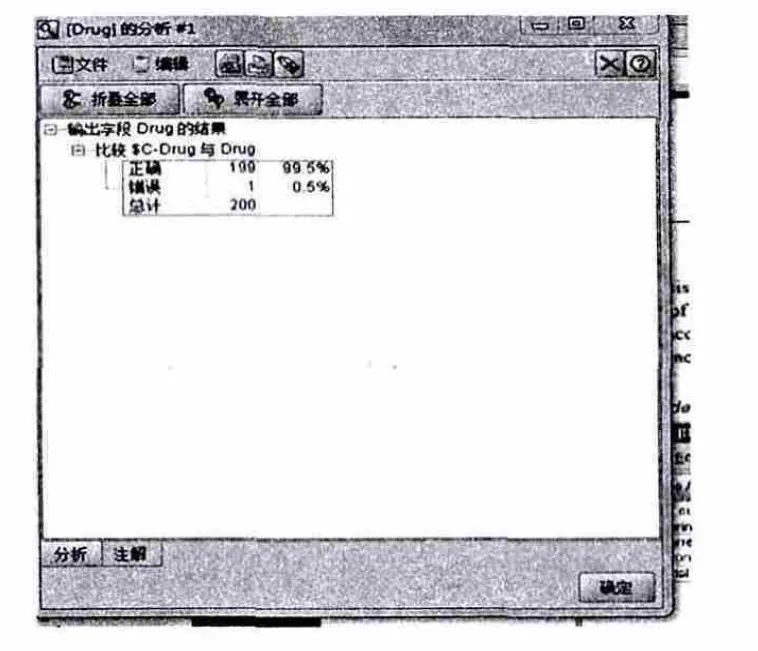
图8
4 总结
由于决策树方法可以将事例逐步分类成表示不同属性的类别,因此,在数据挖掘中应用广泛。决策树通过数据挖掘为决策者带来了巨大的经济利益。虽然决策树在不断的完善,但决策树也还有很多不足的地方需要改进。这主要是使用决策树方法时会遇到一些数据准备和数据表示方面的问题,如:虚假的数据、数据表示以外的其他数据的缺失、对数据细节理解不透等。这些都会影响到决策树的生成,因此,决策树算法在实际的应用中还需要进一步的深入研究。
[1] 韩家炜.数据挖掘:概念与技术第二版[M].北京:机械工业出版社,2001.
[2] 张剑飞.数据挖掘中决策树分类方法研究[J].长春师范学院学报,2005(3):96-98.
[3] 湛宁,徐杰.决策树算法的改进[J].电脑知识与技术,2008(5):1068-1069.
[4] 马秀红,宋建社,董晟飞.数据挖掘中决策树的探讨[J].计算机工程与应用,2004(1):185,214.
[5] 李楠,段隆振,陈萌.决策树C4.5算法在数据挖掘中的分析及其应用[J].计算机与现代化,2008(12):160-163.
[6] 唐华松,姚耀文.数据挖掘中决策树算法的探讨[J].计算机应用研究,2001(8):18-22.
[7] 施蕾,唐艳琴,张欣星.数据挖掘中决策树方法的研究[J].计算机与现代化,2009(10):29-31.
[8] 沈晨鸣.决策树分类算法研究[J].盐城工学院学报,2005(12):22-24.
[9] 江效尧,江伟.决策树在数据挖掘中的应用研究[M].安庆师范学院学报,2003(2):83-85.
[10] 王静红,李笔.基于决策树的一种改进算法[J].电讯技术,2004(10):175-177.
[11] 林向阳.数据挖掘中的决策树算法比较研究[J].中国科技信息,2010(1):94-95.
[12] 冯帆,徐俊刚.C4.5决策树改进算法研究[J].电子技术,2012(6):1-4.
[13] 林静.基于决策树的数据挖掘算法研究[J].福建电脑,2012(11):60-62.
