基于隐条件随机场的人体行为识别方法
2013-12-06鹿凯宁刘安安杨兆选
鹿凯宁,孙 琪,刘安安,杨兆选
(天津大学电子信息工程学院,天津 300072)
人体行为识别是计算机视觉领域长期以来的研究热点,其目的是利用人体行为过程对应的视觉模式的动态变化特征对某一动作进行建模,从而实现对未知动作序列的自动识别.现有人体行为识别方法主要有3 类:①模板匹配法[1-3].基于模板匹配的方法是将图像序列转换成一个或者一组模板,然后将待识别的行为和已知的模板进行匹配来识别.Bobick 等[1]将图像转化为运动能量图像和运动历史图像,采用Maha-lanobis 距离作为模板相似性的度量.该方法对于时间间隔的变化较敏感,鲁棒性较低.Polana 等[2]利用二维网格特征对人体行为进行识别:首先分别在两个不同方向上分解每一个帧光流信息,然后将每一单元格的幅度叠加,从而形成一个高维特征向量用于识别匹配.该方法可以显性提取人体运动信息,但是由于光流对噪声的敏感性使得特征鲁棒性受限.②基于人体结构的方法[4-6].基于人体结构的方法需要建立2,D 或3,D 的人体模型.一般将三维人体视为由关节连接的刚体的集合,用三维的人体骨架来描述人体运动.文献[4]中通过对运动人体的轮廓进行形态学的细化处理,采用新建立连通性结构标准和肢体关节点定位算法处理骨架建立人体骨架模型.尽管该方法能够表征人体行为更多细节,但是人体行为的复杂性往往使得该类方法的建模更加困难.Chen 等[5]将一个动作的三维人体结构转化为一个二维投影图像,在结构中,采用17 个线段和14 个节点来表示人体动作模型,并且定义了很多的约束条件作为步态分析的基础.该方法计算比较复杂,因为其需要研究所有可能的三维结构并得到其相应的二维投影.③基于概率图模型的方法[7-11].概率图模型分为有向图模型和无向图模型两类,典型有向图模型为隐马尔科夫模型(hidden Markov model,HMM),典型无向图模型主要为条件随机场(conditional random field,CRF).Yamato 等[7]首先将 HMMs 引入到人体行为识别中,将人体运动区域块的视觉特征作为输入特征,并用HMMs 模型对人体行为进行建模和识别.Bregler[8]基于人体动力学在不同抽象等级的统计分解提出了层次化方法,通过最大化 HMM 后验概率来完成识别.不同于文献[7-8]中的单人行为识别,文献[9]在群体交互动作识别中采用两层HMM 模型,下层模型对群体中的个体进行动作识别,识别结果作为上层群体行为识别模型的观测.该方法通过多 HMMs 模型的组合实现了较复杂的群体行为识别.尽管 HMM 模型在时序建模应用广泛,但是由于它建立在条件独立性假设和马尔可夫假设上,导致其不能表示时间序列中的大范围上下文依赖关系以及序列间的特征多重重叠,导致该模型不能很好地模拟人体动作序列在时序上的大范围时空关联特性,限制了基于该模型的人体动作识别的准确性.为此,部分研究者开始研究基于判别模型的方法.Lafferty 等[10]提出条件随机场模型,相对于隐马尔科夫模型,它克服了条件独立性假设和马尔可夫假设,并且利用大范围上下文信息进行参数学习和预测,因此该模型具有更强的时序建模能力,已被广泛应用于自然语言处理[11]、计算机视觉[12]等.Wang 等[13]采用条件随机场模型对动作序列潜在的时空相关信息进行建模,从而实现对动作变换过程的整体表征.条件随机场模型可以实现综合利用时空上下文信息进行时序建模和推断,但是该模型的学习需要人为显性标注图像序列各帧状态,从而导致模型的学习依赖于人为的状态标注,使得模型性能受到局限.
笔者提出了基于隐条件随机场的人体行为识别方法.Quattoni 等[14]把隐状态变量引入到条件随机场模型中,提出隐条件随机场(hidden conditional random field,HCRF).由于隐条件随机场不需要对各时刻状态进行显性标注,因此相对于条件随机场对时序信息的利用和建模具有更高的灵活性.该方法包括 3个步骤:首先,通过目标检测和跟踪提取图像序列中人体所在时空区域;其次,提取人体区域的 Gist 特征作为人体行为视觉描述子;最后,利用隐条件随机场模型对人体行为进行建模.
1 人体时空区域提取
人体所在时空区域的检测和跟踪是人体行为分析的前提.
1.1 目标检测
目标检测的目的是判断视频序列各帧中是否出现目标,并对其进行定位.为了快速实现目标检测,首先采用基于混合高斯模型的背景差法[15]检测各帧中前景区域,然后采用 Dalal 等[16]提出的基于方向梯度直方图和支持向量机模型的人体检测分类器进行人体检测,检测结果如图1 所示.

图1 提取人体时空区域示意Fig.1 Extraction of spatiotemporal regions of human body
1.2 目标跟踪
目标跟踪的目的是建立连续帧内人体区域的对应关系,为后续的人体行为时空建模提供基础.目标跟踪通常包含两部分:首先通过目标区域的颜色、纹理和形状等特征对该区域进行表征,然后采用预测模型进行前后帧相似性的匹配.在实验中,采用高效的Meanshift 算法[17]实现了目标跟踪.由于实验数据每帧只包含一个目标,并且通过前述目标检测方法可以较准确定位到每帧中人体区域,因此在实验中将Meanshift 跟踪窗口尺寸设定为首帧图像中检测到的人体区域,为了避免 Meanshift 跟踪的漂移现象发生,将每帧图像中 Meanshift 跟踪的预测区域和目标检测方法检测到的每帧区域进行后融合,即每帧图像人体中心位置取检测和跟踪结果各自中心的中点位置,人体区域的尺度取二者长宽的均值.至此,实现了每个视频中人体所在时空区域的提取.
2 特征提取
采用 Gist 特征对人体行为视觉特征进行描述.Gist 特征的提取无需人体区域分割,并且可以表征人体区域的全局结构和形状特征,因此有利于增强特征的分辨能力.
为了优化局部边缘特征不同尺度下的检测结果,采取多尺度 Wiener 滤波器[18]对图像进行锐化预处理,再利用Gabor 变换来提取图像的Gist 特征.二维Gabor 变换的核函数可以表示为
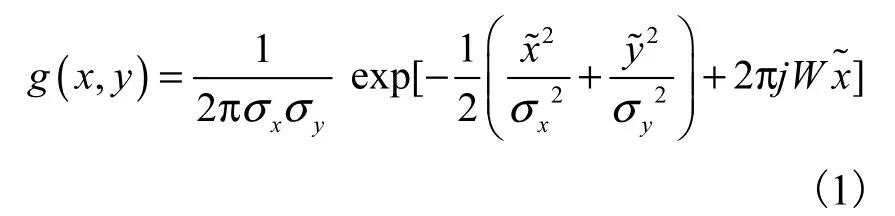
二维Gabor 变换核函数的傅里叶变换为

Gabor 滤波器组是对 Gabor 变换核进行适当尺度变换和旋转变换得到的一组自相似的滤波器,即

给定一幅图像I,对其进行Gabor 变换可表示为
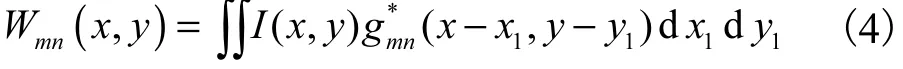
因时域卷积计算复杂度较高,因此根据卷积定理将式(4)转化为式(5)所示频域计算,从而降低计算复杂度.
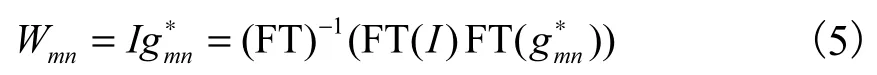
实验中,所创建Gabor 滤波器组含3 个尺度,每个尺度上方向数分别为 8、8、4,总计 20 个滤波器,然后将每幅经过锐化处理的图像与该滤波器组分别执行式(5)所示操作,最终得到图像的 Gist 特征向量(共320 维),该特征将被作为人体行为视觉描述子.
3 隐条件随机场
将对隐条件随机场的模型构建、学习和推断进行具体阐述.
3.1 模型构建
隐条件随机场可以解决观测序列分类问题,其图结构可以表示为 G=(ν,ε) , 其中ν表示图的顶点集合,ε表示图的边集合,如图2 所示.
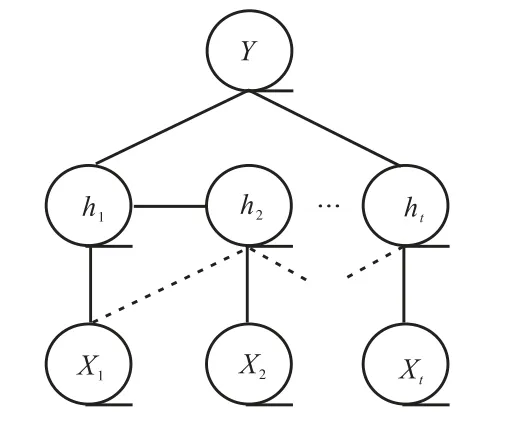
图2 隐条件随机场图模型Fig.2 Graphical model of HCRF
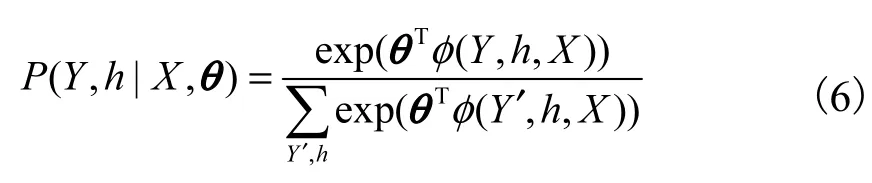
式中:θ为该模型参数;φ(Y,h,X)∈ℜ为势函数.因此,P (Y | X,θ)可以表示为
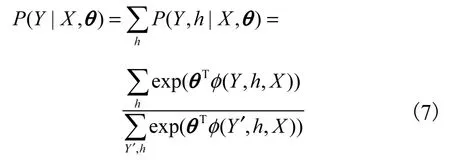
根据图 2 所示隐条件随机场图结构及人体行为过程中的变化特性,所构造隐条件随机场模型中的势函数包含 3 部分:①φ1( Xj,hj).观测节点与隐变量节点之间的关系,即各帧动作特征与该帧表征动作基元类型的关系,可以采用第 2 节中介绍的各帧 G ist 特征进行对该势函数进行表征;②φ2(Y ,hj).隐变量节点与序列标记的关系,即各帧表征的基元动作与动作类别的关系,规定当 hj对应基元动作属于Y 动作类型时,该势函数为 1,否则为 0;③φ3(Y,hj,hk).隐变量节点间形成的边与序列标记间的关系,表示基元动作转变与动作类别的关系,规定当 hj到 hk的基元动作转变符合动作Y 变化过程时,该势函数为 1,否则为0.因此,势函数可以分解为

θ也可以对应地分解,即
3.2 模型学习和推断
假设训练集合包含n 个样本(Xi,Yi),根据HCRF模型定义,通过如下目标函数的优化学习参数θ∗,即
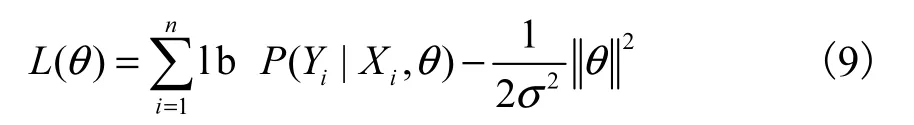
式中n表示训练样本序列的总个数.对于式(9)所示最优化问题,可以使用梯度下降法[10]计算参数最优值,即
获得参数θ后,该模型可以用于人体行为识别的预测.在行为识别过程中,对于观测行为序列X ,其所属类别的最佳估计为
4 实验结果
4.1 动作识别性能分析
采用当前动作识别研究中流行的 Weizzman 数据库(见图 3)对本文中提出的算法进行评测.该数据库共包含 9 3 个视频序列(180 ×140 像 素,25 帧/s),共有10 组动作类型,每组动作分别由9 人完成(其中跑步、慢跑、走步动作数据分别包含 1 个人的2 个视频序列)[20].通过目标检测和跟踪,能够提取所有目标所在时空区域(如图 1(c)所示),为后续动作识别提供准确的建模和识别对象.采用文献[20]提出的数据设置方式来对 HCRF 模型进行训练和测试.为了得到性能最佳的 HCRF 模型,遍历了模型的隐状态数s(2≤s≤5)和时序窗口w(0≤w≤3)两个参数的所有组合,并通过计算模型在测试集上表征分类总体性能的接收者操作特征曲线下面积来对模型参数进行选择.其中,参数 w =N (N ≠ 0)表示在训练HCRF 模型时同时使用当前帧及其相邻的前后各N帧进行状态估计,而w = 0代表训练时只用当前视频帧;参数s 表示HCRF 模型隐状态空间的大小.
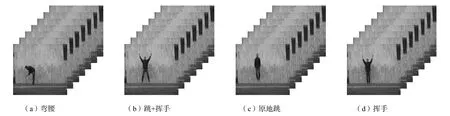
图3 Weizzman数据库中动作样例Fig.3 Example images extracted from the Weizzman dataset
采用最佳参数组合训练各动作对应的 HCRF 模型,此时各动作的查全率 P、查准率 R 及相应接收者操作特征曲线下面积(area under curve,AUC)SAUC结果如表1 所示.

表1 HCRF模型最佳性能Tab.1 Best performance of HCRF
4.2 对比实验
4.2.1 不同 Gabor 滤波器尺度参数下的 HCRF 模型性能对比
为了验证 Gabor 滤波器尺度参数对模型性能的影响,选择最优尺度参数,实验中采用不同尺度参数下提取的Gist 特征,并采用第4.1 节实验得到的最优隐状态数和时序窗口参数组合训练 HCRF 模型,并通过识别准确率进行比较.由表 2 比较可以看出,尺度参数的变化对 HCRF 模型性能的影响不显著.相对而言,当尺度参数较小时(σx=σy= 3),Gabor 滤波器组仅仅能够表征较小的局部区域特征,不能很好地描述人体行为视觉特征,因此得到的识别效果较低;尺度 参数 分别 为σx=σy= 5和σx=σy= 7时,Gabor 滤波器组能够表征较大的局部区域特征,更适于具有显著局部变化特性的图像序列表征,因此识别准确率相对σx=σy= 3有所提高,但是二者准确率十分接近.考虑到实际情况中,由于尺度参数越大,提取特征时的卷积计算复杂度越大,因此实验中采用的尺度参数为σx=σy= 5.
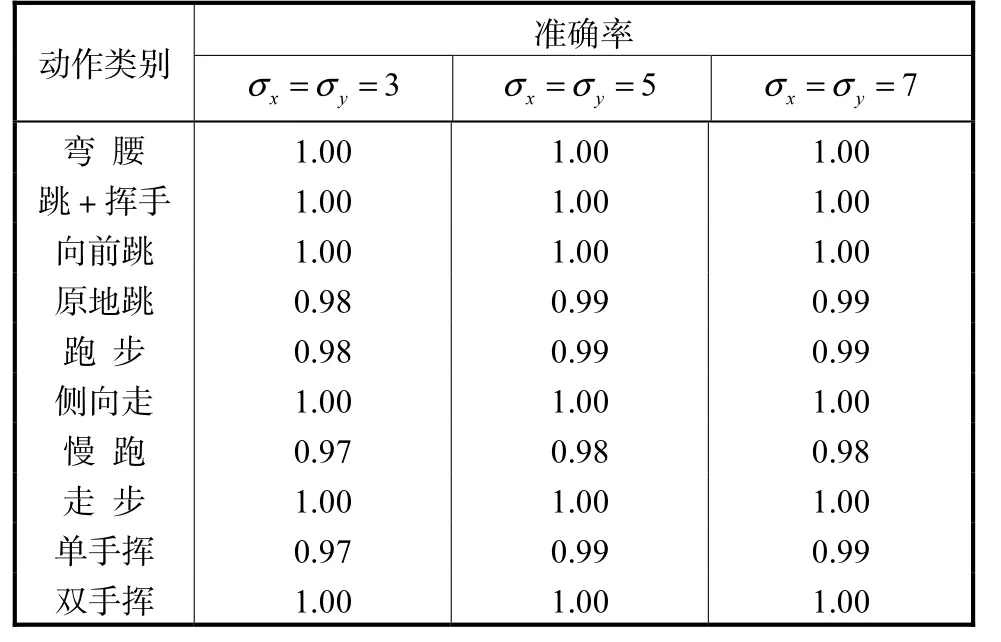
表2 不同尺度参数下HCRF模型的动作识别准确率Tab.2 Accuracy of HCRF with different scaling parameters
4.2.2 算法对比
为了证明该方法的优越性,把它的性能分别与文献[20]以及近期提出的基于条件随机场模型的动作识别方法[13]进行对比.为了公平比较 3 种方法的性能,在相同的数据库并分别采用不同文献中的相应评价准则对算法进行评测.
表 3 给出了本文所提算法与文献[20]所提算法的动作识别率的对比结果.这两种算法的区别在于:本文中用于描述人体行为的 Gist 特征是一种根据人的生理特性构造的一组图像视觉特征,它可以表示图像的自然度、开放度、粗糙度、扩张度和崎岖度等,并且它不需要人工预先进行人体区域分割就可以表征人体区域的形状和纹理特征[21],因此使得本文提出方法所构造 HCRF 模型的势函数与文献[20]中势函数不同.由表3 可知,这两种算法取得了相近的结果,其中,本文算法在走步、慢跑和跑步 3 类动作分别高于文献[20]算法 10.0%、3.1%和 9.2%,文献[20]算法在原地跳和单手挥分别高于本文算法0.1%和1.1%.
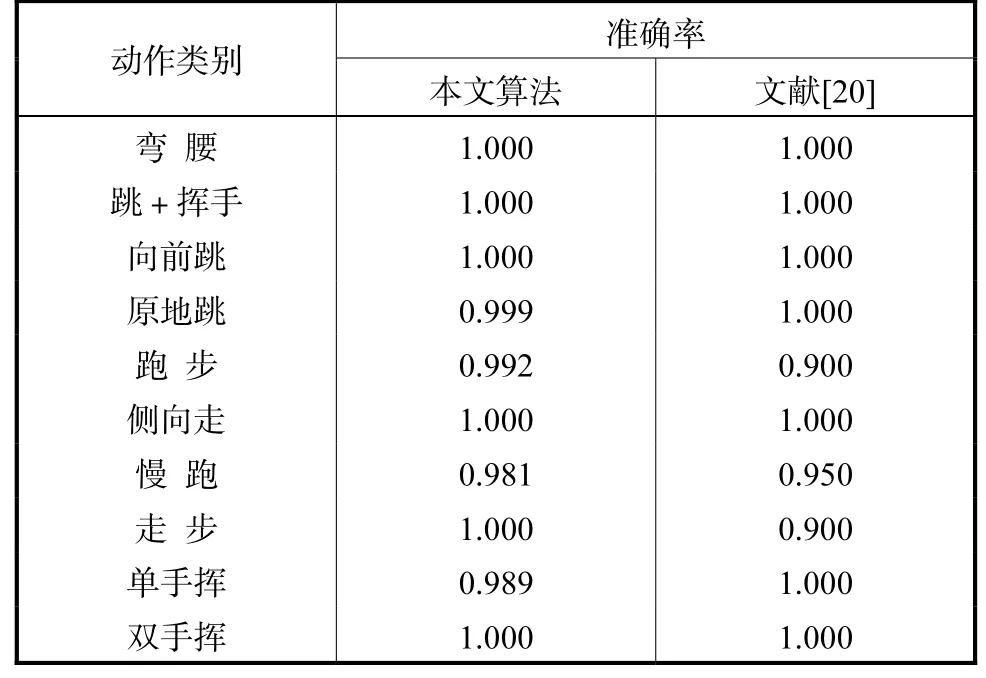
表3 本文算法与文献[20]算法比较Tab.3 Comparison between proposed method and method in Ref[20]
表 4 给出了由第 4.1 节实验得到的最佳参数条件下的HCRF 模型及CRF 模型进行行为识别的对比结果.根据文献[13]实验设置,除了对接收者操作特征曲线下面积AUC 进行比较外,还采用 F1值来对查全率和查准率两者综合性能进行比较.F1值定义为

由表 4 看出在 Weizzman 数据库中复杂人体行为识别实验中,HCRF 的性能始终优于 CRF 的.此外,CRF 模型要求对行为序列进行完全标记,因此较HCRF 模型学习工作量更大,且因人为进行帧级状态标记具有很强主观性,因此往往直接影响模型性能.
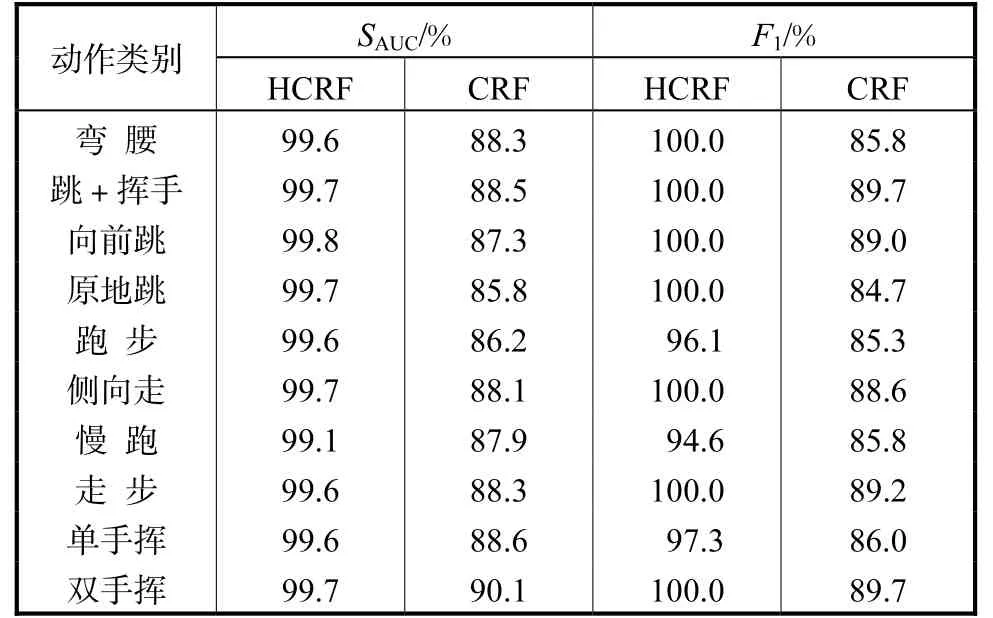
表4 HCRF与CRF性能比较Tab.4 Comparison between HCRF and CRF
5 结 语
提出了一种基于隐条件随机场的人体行为识别方法.该方法首先通过目标检测和跟踪提取图像序列中人体所在时空区域;其次提取人体区域的 Gist特征作为人体行为视觉描述子;最后,利用隐条件随机场模型对人体行为进行建模,实现对人体行为的识别.通过对比实验证明了隐条件随机场可以充分利用图像序列的时空相关信息来表征动作序列的时空变化特性,从而实现准确的人体行为识别.
[1]Bobick A F,Davis J W. The recognition of human movement using temporal templates[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2001,23(3):257-267.
[2]Polana R,Nelson R. Low level recognition of human motion[C]//Proceedings IEEE Workshop on Motion of Non-Rigid and Articulated Objects.Austin , USA ,1994:77-82.
[3]Veeraraghavan A K,Roy-Chowdhury R C. Matching shape sequences in video with applications in human movement analysis[J].IEEE Trans on Pattern Analysis and Machine Intelligence,2005,27(12):1896-1909.
[4]赵晓东,李其攀,王志成. 一种快速人体骨架建模方法[J]. 计算机应用研究,2012,29(1):383-385.Zhao Xiaodong , Li Qipan , Wang Zhicheng. Fast method on building human skeleton model[J].Application Research of Computers, 2012 , 29(1) : 383-385(in Chinese).
[5]Chen Z,Lee H J. Knowledge-guided visual perception of 3D human gait from a single image sequence[J].IEEE Trans on Systems,Man and Cybernetics, 1992 ,22(2):336-342.
[6]Leung M K,Yang Y. First sight:A human body outline labeling system[J].IEEE Trans on Pattern Analysis and Machine Intelligence,1995,17(4):359-377.
[7]Yamato J,Ohya J,lshii K. Recognizing human action in time-sequential images using hidden markov model[C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Chempaign ,USA,1992:379-385.
[8]Bregler Christoph. Learning and recognizing human dynamics in video sequences[C]//Proceedings of the IEEE computer Society Conference on Computer Vision and Pattern Recognition.Puerto Rico,1997:568-574.
[9]Zhang D,Gatica-Perez D,Bengio S,et al. Modeling individual group actions in meetings:A two-layer HMM framework[C]//Proceedings of IEEE CVPR Workshop on Detection and Recognition of Events in Video. Washington,USA,2004:117-125.
[10]Lafferty J,McCallum A,Pereira F. Conditional random fields:probabilistic model for segmenting and labeling Sequence data[C]//Proceedings of the18,th International Conference on Machine Learning. San Francisco,USA,2001:282-289.
[11]Cohn T A. Scaling Conditional Random Fields for Natural Language Processing[D]. Australia:Department of Computer Science and Software Engineering,University of Melbourne,2007.
[12]Kumar S,Hebert M. Discriminitive random fields:A discriminitive framework for contextual interaction in classification[C]//IEEE International Conference on Computer Vision. Nice,France,2003:1150-1157.
[13]Wang Jin,Liu Ping,She Mary,et al. Human action categorization using conditional random field[C]//Robotic Intelligence in Informationally Structured Space(RiiSS). Paris,Frace,2011:131-135.
[14]Quattoni A,Wang S b,Morency L P,et al.Hidden conditional random fields[J].IEEE Trans Pattern Anal Mach Intell,2007,29(10):1848-1852.
[15]Stauffer C,Grimson W E L. Learning patterns of activity using real-time tracking [J].IEEE Trans on Pattern Analysis and Machine Intelligence,2000,22(8):747-757.
[16]Dalal Navneet,Triggs Bill. Histograms of oriented gradients for human detection[C]//Intermational Conference onComputer Vision and Pattern Recognition(CVPR,2005). San Diego,USA,2005:886-893.
[17]雷 云,王夏黎,孙 华. 基于视频的交通目标跟踪方法[J]. 计算机技术与发展,2010,20(7):44-47.Lei Yun,Wang Xiali,Sun Hua. The research about transport target tracking based on video[J].Computer Technology and Development,2010,20(7):44-47(in Chinese).
[18]胡 英,杨 杰,周 越. 基于多尺度Wiener 滤波器的分形噪声滤波[J]. 电子学报,2003,31(4):560-563.Hu Ying,Yang Jie,Zhou Yue. Multiscale Wiener filter for the estimation of signal embedded in noise[J].Acta Electronica Sinica,2003,31(4):560-563(in Chinese).
[19]王宇新,陆国际,郭 和,等. 同义图像融合系统设计与优化[J]. 计算机科学,2010,37(8):283-286.Wang Yuxin,Lu Guoji,Guo He,et al. Design and optimization of synonymous image cloning system[J].Computer Science, 2010 , 37(8) : 283-286(in Chinese).
[20]刘法旺,贾云得. 基于流形学习与隐条件随机场的人体动作识别[J]. 软件学报,2008,19(增):69-77.Liu Fawang,Jia Yunde. Human action recognition using manifold learning and hidden conditional random fields[J].Journal of Software,2008,19(Suppl):69-77(in Chi-nese).
[21]Oliva A,Torralba A. Modeling the shape of the scene:A holistic representation of the spatial envelope [J].International Journal of Computer Vision, 2001 ,42(3):145-175.
