基于Web日志挖掘的网页推荐方法
2013-12-03解男男努尔布力印晓天
解男男, 胡 亮, 努尔布力, 樊 丽, 印晓天
(1. 吉林大学 计算机科学与技术学院, 长春 130012; 2. 新疆大学 信息科学与工程学院, 乌鲁木齐 830046; 3. 公安部第一研究所, 北京 100048)
随着网络的迅猛发展, 网络信息量呈几何级数增长, 用户迫切需要能从浩瀚的信息海洋中快速地搜索到自己感兴趣的网页. 然而一个大型网站通常有成千上万的网页, 用户可能只对其中某些网页中的内容感兴趣. 对每个用户, 所需的信息也各不相同, 这就需要针对不同的用户提供不同的服务, 以满足不同的需求. 因此, 互联网庞大的信息量和用户个性化的信息需求之间存在着矛盾, 而基于Web的数据挖掘技术是解决这种矛盾的基本方法.
基于Web的数据挖掘就是从与WWW相关的资源和行为中抽取用户感兴趣的、 潜在的有用模式和隐藏信息. 一般地, Web挖掘可分为Web内容挖掘、 Web结构挖掘和Web日志挖掘. 目前, 基于Web挖掘实现网页推荐的研究已有许多结果. 如: Yan等[1]将用户浏览网页时间作为权值加入到基于关联规则的网页推荐系统中; 杨正余等[2]提出了一种基于用户访问序列的实时网页推荐方法; 文献[3]通过对点击数据流进行关联规则挖掘实现了网页个性化推荐; 文献[4]提出了在网页推荐系统中使用基于分布式自动学习机和关联规则的混合算法; Jiang等[5]提出一种基于日志挖掘的个性化推荐系统, 采用基于约束的Apriori算法实现.
使用聚类实现网页推荐可有效提升推荐覆盖率, 但推荐精确度较低. 为优化精度, 本文提出一种基于Web日志挖掘的个性化网页推荐模型, 并实现了蕴含模型理念的WRCA核心算法, 算法结合聚类分析和关联规则挖掘, 使用基于传递闭包的模糊聚类算法对网页进行聚类, 同时采用序列模式算法挖掘出有效关联规则, 然后综合考虑聚类结果调整序列模式挖掘产生的推荐集, 进而对网站的当前用户在线提供网页推荐.
1 Web日志挖掘技术
Web日志挖掘的主要目标是从Web的访问记录中抽取感兴趣的模式. WWW中的每个服务器都保留了访问日志, 记录了关于用户访问和交互的信息. 分析这些数据可帮助理解用户的行为, 为用户提供个性化服务. Web日志挖掘过程一般分为3个阶段[6]: 数据预处理阶段、 模式识别阶段和模式分析阶段, 如图1所示.
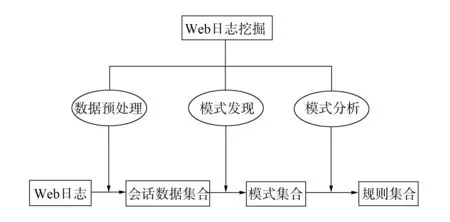
图1 典型Web日志挖掘流程Fig.1 Flow chart of a typical Web log mining
数据预处理阶段是对原始数据进行数据净化、 用户识别、 会话识别和路径补充等处理, 最后得到适合数据挖掘的结构化数据库记录形式; 模式识别阶段是对预处理后的数据运用数据挖掘的相关算法进行挖掘, 发现潜在隐藏的有用模式信息, 模式识别的方法主要有统计分析、 频繁项集和关联规则、 聚类与分类分析、 序列模式和相关性建模等; 模式分析阶段是对挖掘出的模式信息进行分析, 应用其中得到的有用规则.
1.1 聚类分析与传递闭包聚类方法
聚类分析是指将物理或抽象的对象集合分别组成由类似对象组成的多个类的分析过程[7-8].
本文通过分析用户行为对网页进行聚类, 从而重点关注用户当前所访问网页所属聚类中的其他页面, 以达到向用户推荐合适网页的目的. 在聚类前并不知道准确的分类数, 采用基于模糊等价关系的传递闭包方法. 算法描述如下[9]:
1) 计算聚类数据间的模糊相似矩阵S;
2) 通过S求出包含矩阵S的最小模糊传递矩阵, 即传递闭包C, 将模糊关系矩阵变成模糊等价矩阵;
3) 选取合适的参数γ, 当Tij>γ时,Xi,Xj在同一个等价类中.
1.2 序列模式挖掘方法
给定一个由不同序列组成的集合, 其中每个序列由不同的元素按顺序排列, 每个元素由不同的项目组成, 同时给定一个用户指定的最小支持度, 序列模式挖掘就是找出所有的频繁子序列, 即该子序列在序列集中出现的频率不低于用户指定的最小支持度. 本文采用经典的序列模式挖掘方法----Apriori算法, 它是一个通过挖掘频繁项目集挖掘布尔型关联规则的算法.
Apriori算法挖掘的目标是找出给定事务集合T中所有满足支持度和置信度分别高于一个用户指定的最小支持度和最小置信度的关联规则. 该挖掘关联规则过程可分解为两个子过程:
1) 产生所有频繁项目集;
2) 从频繁项目集中产生所有可信关联规则.
2 基于Web日志挖掘的网页推荐
基于个性化网页推荐的应用要求, 本文对Web日志挖掘技术采用聚类分析和关联规则两种挖掘方法, 因为在人类大脑中, 同时被激活的概念都是密切相关的, 即在一段时间内被某一用户访问的页面即可被认为是同时发生的且相互关联的. 也可认为用户在访问页面时更多是为了寻找相互关联的页面, 而不是随机访问不相关的页面. 所以, 本文根据在用户会话中网页被同时访问的频率将网页聚类, 网页被同时访问的频率越高, 表明他们之间的关联越密切, 从而越有可能是同一类资源, 即该聚类算法倾向于将多次同时被访问的页面分在同一页面聚类中, 即使这些页面表面上并不相似. 而同一网页聚类中未被访问的页面, 就是将来向用户推荐时的主要关注对象. 因此使用网页聚类技术预测用户浏览路径时覆盖率较高, 但精确度较低, 产生这种现象的原因是在同一聚类中的页面也有亲疏之分, 有些页面之间并没有直接关联, 但却经常被一起访问, 因此可同时使用关联规则挖掘出经常被同时访问的页面及其时间访问顺序, 提高网页推荐精确度. 本文提出了基于Web日志挖掘的网页推荐模型. 先使用基于传递闭包的模糊聚类算法对网页进行聚类, 然后针对每个类别中的网页进行关联规则挖掘, 进而对网站的当前用户在线提供网页推荐.
设T表示用户会话集合,I表示页面集合,S表示页面相似矩阵,C表示页面传递闭包,R表示关联规则, support(R)表示关联规则R的支持度, confidence(R)表示关联规则R的置信度, minsup表示最小支持度, mincof表示最小置信度,L表示频繁项目集, ConNum(Pi)表示访问过网页Pi的用户会话数目.
2.1 网页推荐模型设计
本文提出一种基于Web日志挖掘的网页推荐模型, 可根据用户的访问进程, 自动实现用户的个性化推荐, 不需要用户的干预, 为用户提供感兴趣的页面.
该算法主要步骤如下:
1) 使用传递闭包模糊聚类算法实现网页聚类;
2) 利用序列模式挖掘算法(Apriori算法)得到相应的关联规则;
3) 综合关联规则置信度和当前活跃会话与网页聚类的匹配度, 计算页面推荐值;
4) 将推荐值较大的n个页面推荐给用户.
基于Web日志挖掘的个性化网页推荐模型如图2所示.

图2 基于Web日志挖掘的网页推荐模型Fig.2 Model of the recommender algorithm based on Web log mining
2.2 基于Web日志挖掘的网页推荐算法
设I={i1,i2,…,im}是一个项目集合,T={t1,t2,…,tm}是一个事务集合, 其中每个事务ti是一个子集. 本文中每个页面即为一个项目, 所有的用户会话组成事务集合, 每个用户会话都由一些页面组成.
定义1Pi和Pj的相似度Rij由同时包含这两个页面的用户会话数的百分数决定, 计算公式如下:
定义2页面相似矩阵S是以页面序号为行和列构造的, 矩阵中的元素表示页面之间的相似度. 显然矩阵S满足对称性和自反性.
定义3页面传递闭包C是包含关系S最小的传递性矩阵.
在基于传递闭包的网页聚类中, 首先计算所有的相似度, 然后通过页面相似矩阵S求出对应的页面传递闭包C, 最后确定截集γ的值, 当Cij>γ时,Pi和Pj在同一页面聚类中; 否则,Pi和Pj属于不同的页面聚类, 最后输出聚类结果.
定义4[10]关联规则是具有如下形式的蕴含关系:A→B, 其中:A⊂I;B⊂I;A∩B=Ø;A和B都是项目的集合, 称为项集,A称为前项,B称为后项.
定义5规则A→B的支持度是指“T中包含A∪B的事务的百分数”. 因此, 规则的支持度表示规则在事务集合T中使用的频繁程度. 公式如下:

定义6规则A→B的置信度是指“T中包含A∪B事务的数量占所有包含A事务的百分数”. 因此, 规则的置信度决定了规则的可预测度. 公式如下:
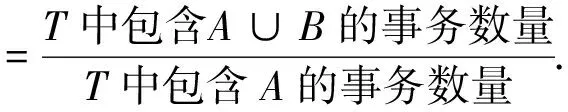
关联规则挖掘的目标即为找出给定事务集合T中所有满足支持度和置信度分别高于一个用户指定的最小支持度和最小置信度的关联规则.
定义7一个支持度大于或等于最小支持度的项集称为频繁项集, 其他项集称为非频繁项集.
定义8在频繁项目集中挑选出所有不被其他元素包含的频繁项目集称为最大频繁项目集.
定义9置信度大于或等于最小置信度的规则称为可信关联规则. 挖掘可信关联规则的过程可分解为两个子过程:
1) 产生所有频繁项目集;
2) 从频繁项目集中产生所有可信关联规则.
网页推荐算法WRCA伪代码如下:
fori←1 toN
forj←1 toN
end for
end for
call transitive_closure(C,S);
call cluster(cluster[N]C,γ);
Gen_frequent_itemset(L,T,minsup);
Gen_association_rules(R,L,minconf);
for all association rules
Rec(p)=confidence(r)×match(CS,p)
endfor
Recommdation(RecList,User).
先通过事务集T求出页面相似矩阵S, 然后由页面相似矩阵S经平方自合成法求出页面传递闭包C, 选定截集γ后可得页面聚类; 同时使用Apriori算法挖掘关联规则, 其中Gen_frequent_itemset函数采用逐级搜索思想, 每轮搜索扫描一遍事务集合, 并最终生成所有的频繁项目集. 算法伪代码如下:
L1={frequent1-itemset};
for(k=2;Lk-1≠Ø,k++)
Wk=apriori_gen(Lk-1);
for all transactionst∈T
Wt=subset(Wk,t);
for all transactionsw∈Wt
w.count++;
endfor
endfor
Lk={w∈Wk|w.count≥min sup}
endfor
L=Uk(Lk).
Gen_association_rules函数产生所有可信关联规则, 过程如下:
1) 对于L中的每个频繁项集l, 产生l的所有非空子集;
2) 对于l的每个非空子集s, 若
则输出规则s→ (l-s), 其中support为支持度.
生成关联规则后, 要同时考虑关联规则置信度和当前活跃会话与网页聚类的匹配度, 计算页面推荐值:
Rec(p)=confidence(CS,R)×match(CS,p),
其中: Confidence(CS,p)表示推荐页面p关联规则的置信度; match(CS,p)表示p所属关联规则与当前用户会话的匹配度, 计算公式如下:
match(CS,p)=PageNum(CS,Rulep)/PageNum(CS).
最后选择推荐值最大的前n个页面推荐给用户.
3 算法实验
3.1 网页推荐评估标准
推荐算法的优劣通常用精确度(precision)和覆盖率(coverage)衡量[4]. 推荐覆盖率是指系统向用户推荐的页面数占当前用户会话后访问总页面数的比例. 计算公式如下:
其中:R(p)表示用户访问页面p时系统向用户推荐的页面集;T(p)表示本次用户会话中用户在页面p后访问的所有页面集.
推荐精确度是指正确的推荐在总推荐中所占的比例, 所谓正确的推荐, 是在用户会话中被用户访问的页面. 推荐精确度Precision的计算公式如下:
3.2 实验结果
实验中采用的数据来源于糯米网的8 624条服务器端日志记录, 该数据集中包含一系列用户会话, 本文将每个用户会话视为一个事务, 每个事务都包含该用户在这个会话中访问的一系列网页. 然后将该数据集分成相互独立的两部分, 其中有6 628条日志记录作为训练集, 剩下的1 998条日志记录作为测试集.
本文选取在网页推荐研究领域应用较广泛的关联规则挖掘算法及传递闭包聚类算法分别与本文WRCA算法进行结果对比. 评估时给定不同的推荐页面数(本文选择1~7), 分别计算使用WRCA算法、 Apriori算法和传递闭包聚类算法实现网页推荐时的推荐覆盖率和推荐精确度, 实验结果列于表1和表2. 由表1和表2可见, WRCA算法在覆盖率和精确度上均优于其他算法.

表1 WRCA算法、 传递闭包算法及关联规则算法实现网页推荐时覆盖率的比较

表2 WRCA算法、 传递闭包算法及关联规则算法实现网页推荐时精确度的比较
综上所述, 本文通过分析Web日志信息, 对网页进行聚类和序列模式挖掘, 可很好地应用于个性化网页推荐, 通过采用糯米网中用户访问日志作为数据集进行算法实验, 在保障网页页面推荐覆盖率的条件下, 有较高的精确度, 验证了该算法和模型指标的有效性. 由于算法着重分析了Web日志, 不需要用户注册信息及概貌文件, 在推荐时不会打扰用户, 从而解决了输入信息偏差或过时的问题.
[1] YAN Liang, LI Chun-ping. Incorporating Pageview Weight into an Association-Rule-Based Web Recommendation System [M]. Lecture Notes in Computer Science. Berlin: Springer, 2006: 577-586.
[2] YANG Zheng-yu, WANG Wei-ping. Real-Time Web Page Recommendation Research Based on User Access Sequence [J]. Computer Systems & Applications, 2008, 17(5): 50-53. (杨正余, 王卫平. 基于用户访问序列的实时网页推荐研究 [J]. 计算机系统应用, 2008, 17(5): 50-53.)
[3] Forsati R, Meybodi M R. Effective Page Recommendation Algorithms Based on Distributed Learning Automata and Weighted Association Rules [J]. Expert System with Applications, 2010, 37(2): 1316-1330.
[4] Géry M, Haddad H. Evaluation of Web Usage Mining Approaches for User’s Next Request Prediction [C]//Proceedings of the Fifth ACM International Workshop on Web Information and Data Management. New York: ACM Press, 2003: 74-81.
[5] Jiang C B, Wang H, Chen L. A Research on Personalized Recommendation Based on Web Log Mining [C]//Proceedings of 6th International Conference on Innovation and Management. Sao Paulo, Brazil: [s.n.], 2009: 1409-1415.
[6] HU Jian-wu, HE Zhen-ming, ZHANG Yi-quan. Research and Realization of Web Log Ming [J]. Computer Engineering and Applications, 2004(14): 156-158. (胡建武, 何贞铭, 张贻权. WEB日志挖掘及其实现 [J]. 计算机工程及应用, 2004(14): 156-158.)
[7] Omran M G H, Engelbrecht A P, Salman A. An Overview of Clustering Methods [J]. Intelligent Data Analysis, 2007, 11(6): 583-605.
[8] Jain A K, Dubes R C. Algorithms for Clustering Data [M]. Trenton: Prentice-Hall, 1988: 1-334.
[9] FAN Li. Research on Learning Resources Personalization Recommender Method Based on Web Log Mining Technique [D]. Changchun: Jilin University, 2012. (樊丽. 基于Web日志挖掘的学习资源个性化推荐方法研究 [D]. 长春: 吉林大学, 2012.)
[10] Borgelt C, Kruse R. Induction of Association Rules: Apriori Implementation [C]//Proc 14th Conf on Computational Statistics. Berlin: Springer, 2002: 395-400.
