一种基于语义相关度的XML关键字查询排序方法
2013-12-03李瑞霞苏守宝周先存
李瑞霞,苏守宝,周先存
(皖西学院 信息工程学院,安徽 六安 237012)
随着XML数据表示和信息交换的广泛应用,在信息检索中利用XML关键字查询已成为本领域目前研究的热点.传统检索方法通常利用结构查询语言XPath和XQuery进行XML数据检索,可表示复杂的语义,因此能获得较理想的结果,但这种方法要求用户理解XML的结构且掌握其语法.XML关键字检索只需用户输入部分关键信息即可获得需要的内容,但却通常因为查询结果排序的不合理性,可能会提供相关度较小的结果给用户,而忽略相关度较大的重要信息.
与普通文档的关键字查询不同,XML数据上关键字查询的目标通常不是整个XML文档,而是满足包含给定关键字的最紧致XML片段,文献[1]将该问题归结为最小树根节点问题(smallest lowest common ancestor,SLCA).SLCA是关键字查询的一种经典方法,但其未考虑节点的语义,从而影响了查询结果与用户需求的相关度.文献[2]把文档中的元素划分为实体节点、属性节点和连接节点,利用推断方法猜测返回的节点类型,也可视为SLCA算法的变体,未考虑查询关键词的关联;文献[3]利用XRANK方法分别对关键字出现在中间节点和叶子节点两种情况进行了相关度的排序研究;文献[4]在XRANK的基础上考虑了关键字出现的位置和层次信息,进而推断用户需要的目标;文献[5]提出了目标节点和条件节点的概念,并提出了两种不同类型节点的识别算法;文献[6]通过考虑不同类型XML节点出现的频率及查询关键字所在不同位置等对目标节点类型的影响,进行目标节点推断,提高了查询的准确率;文献[7]用自动推断关键词查询条件节点和目标节点类型的算法,并结合XML文档集的模式和统计信息及关键词出现的上下文及其关联关系等推断用户的查询意图;文献[8]通过对路径进行约束实现搜索和排序XML文档.本文提出一种考虑节点语义相关度的排序方法,该方法通过节点对XML文档的区分程度、节点描述XML文档的直接程度及对XML文档概括的精确程度三方面设置其权重,进而利用向量空间模型VSM[9]实现语义相关度的排序.
1 XML文档的表示及信息检索
本文将XML文档以树结构的形式表示.
定义1一个XML文档可由T=(r,E,NE,NV)表示,其中:r表示文档树的根节点;E表示文档树中所有边的集合;NE对应XML文档的元素和属性节点;NV对应XML文档的文本节点,即叶子节点.
当用户提交查询请求时,系统通过大量的文档集合检索用户需要的文档,然后对结果集根据其相关度进行排序.在信息检索领域,通常利用向量空间模型计算查询请求和被检索文档间的相关度.将被检索文档和查询关键字设置成由若干权重组成的向量形式.向量间的相似度即关键字和文档间的相关度.不同的权重利用tf-idf方法获得[10].
例如,L={termi}(i=1,2,…,|L|) 表示检索关键字的集合,D={dj}(j=1,2,…,|D|)表示文档的集合,通过给文档dj中各节点设置不同的权重可将其表示为dj=(w1j,w2j,…,w|L|j),查询关键字可表示为q=(w1q,w2q,…,w|L|q).通过
(1)
可获得关键字和文档之间的相似度.
查询关键字的权重通常设置为相等,而文档中节点的权重通过tf-idf方法设定,但传统的tf-idf方法并不适合结构化的XML文档.XML文档作为一种半结构化数据,除包含文本内容外,还包含文本文档不具有的结构信息,例如同一节点包含的内容在不同位置出现可能代表不同的语义.
2 语义相关度排序
2.1 影响节点语义权重的因素
通过对现有XML关键字查询的研究及分析表明,影响节点语义权重的因素主要有:节点对文档的区分能力、节点是否直接描述文档和节点是否明确描述文档.
1) 相同的节点可能会出现在所有的文档中,而在不同文档中因其表示不同的意义而具有不同的权重,如图1所示,若查询关键字是XML,则节点1和5都包括了该关键字,因此满足用户的查询要求,然而对于节点5关键字出现在一篇文章的title中,所以认为节点5更符合用户的查询需求.因此,一个节点对文档区分能力越强,则其权重越大.权重表示为

图1 XML文档的树形表示Fig.1 A tree of XML document
(2)
其中:di,j表示一个节点的权重,即该节点对文档的区分能力;pj表示该节点j在本文档i中出现的概率,其出现的次数越多,则对文档的贡献越大,权重越大;Hj表示节点的熵.
2) 为了判断一个关键字是否直接描述该文档,可通过其所在位置进行衡量.
定义2节点的距离通过从根节点到该节点所经过的节点个数表示,根节点距离为1.
如图1所示,节点Baum的距离为从articles到Baum经过的节点数量,通过定义2可得其值为4.
通常认为节点出现的位置越靠近根节点,描述文档越直接,对文档的贡献也越大.其权重表示为
(3)
其中:n=length(j)表示从根节点到节点j的距离;mk表示在经过的节点中第k个节点在该路径出现的次数;k表示一个调节因子(k<1),本文设置k=0.8[11].
文档中节点经过的最大距离也会影响权重的计算.假设文档1中距离最大为3,文档2为7,则根据式(3),若一个关键字出现在文档1中路径的第3个位置比出现在文档2中路径的第4个位置更重要,显然不合理.为了消除这种影响,本文借鉴文献[12]的思想对路径长度进行规范化:
(4)
其中:Rnorm-i,j表示规范化后的节点权重,以此替换式(3)中的权重;length(m)表示文档中包含关键字的节点到根节点的距离.
3) 一个节点是不是明确描述文档,可通过节点包含的字符长度衡量,如对于一篇文章,摘要字数明显多于关键词,实际上摘要也更能使人了解一篇文章的主要内容.本文通过Ei,j表示文档di中节点j的字符长度.
由于文档集中文档大小不同,因此一个很大文档包含的字符数显然比一个很小文档包含的字符数多,但对特定关键字,出现在大文档中并不表明比出现在小文档中更重要,因此为了消除文档大小产生的影响,本文借鉴文献[13]的思想进行规范化:
(5)
其中:Enorm-i,j表示规范化后的权重;tm表示在文档中包含关键字的节点.
2.2 相关度计算模型
基于上述影响关键字语义权重的几个因素,将节点tj在文档di中的权重wi,j定义如下:
(6)
3 实验分析
测试数据集使用实际的DBLP数据集(127 Mb)[14],实验平台为Intel 2.8 GHz Pentium D 处理器,1 GHz RAM,Windows XP操作系统.本文提出的语义相关度查询排序方法简称为SCQR(semantic correlation query and ranking),对比算法选择文献[1]提出的关键字检索方法SLCA.部分测试用例列于表1.选择100篇文档进行测试,测试查询关键字个数为1~4个.为消除运行时产生的误差,每个测试用例都进行5次测试,然后取平均时间.由表1可见,SCQR方法的结果比SLCA方法更精确.图2给出了SCQR方法和SLCA方法查询时间的对比.本文在计算前先对各节点做预处理,所以由图2可见,SCQR方法的性能明显优于SLCA方法.

表1 DBLP数据集上的测试结果Table 1 Results on DBLP dataset
查准率用于度量实验返回节点与用户查询意图的相关程度;查全率用于衡量实验检索出的相关节点与全部相关节点的百分比[15]:

图2 SCQR方法和SLCA方法执行时间的比较Fig.2 Comparison of execution time for SCQR and SLCA
图3通过10组数据的测试给出了SCQR方法和SLCA方法之间查全率与查准率的对比.由图3可见,SCQR方法和SLCA方法的平均查准率分别为0.808和0.628,这是因为SCQR方法在检索中充分考虑了XML文档的语义,并在排序检索结果过程中考虑了满足用户查询要求的相关程度.而SLCA方法在检索过程中只考虑文档是否包含关键字,因而,无论返回何种节点类型,最终查询结果都只可能是一棵以SLCA作为根节点的子树,对于包含关键字的文档不能通过有效地排序返回给用户有价值的信息,因此导致了SCQR方法的查准率高于SLCA方法的查准率.
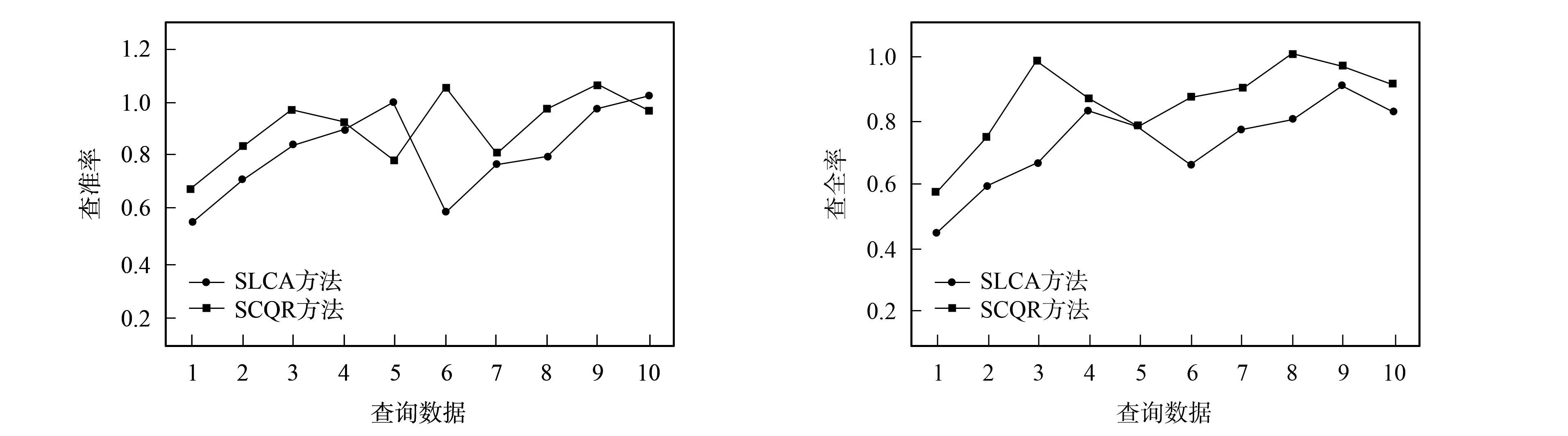
图3 SCQR方法和SLCA方法查询精度的比较Fig.3 Comparison of precision and recall for SCQR and SLCA
综上所述,本文以向量空间模型为基础,摒弃了tf-idf的权重计算方法,利用XML的语义,从节点的区分程度、节点描述文档的直接程度和节点描述文档的明确程度三方面衡量文档中各节点的权重,计算关键字和文档集合的相似性,实现XML语义的相关度排序,得到了满足用户查询要求的最相关结果.通过DBLP数据集实验验证了提出的方法在查全率及查准率上比传统方法有较大改进.
[1] XU Yu,Papakon Y.Efficient Keyword Search for Smallest LCAs in XML Data Bases [C]//Proceedings of the ACM SIGMOD International Conference on Management of Data.New York:ACM Press,2005:537-538.
[2] LIU Zi-yang,CHEN Yi.Identifying Meaningful Return Information for XML Keyword Search [C]//Proceedings of the 2007 ACM SIGMOD International Conference on Management of Data.New York:ACM Press,2007:329-340.
[3] GUO Lin,SHAO Feng,Botev C,et al.XRANK:Ranked Keyword Search over XML Documents [C]//Proceedings of the 2003 ACM SIGMOD International Conference on Management of Data.New York:ACM Press,2003:16-27.
[4] LI Xia,LI Zhan-huai,CHEN Qun,et al.XObject:An XML Keyword Search Method Based on Structural Retrieval [J].Journal of Northwestern Polytechnical University,2010,28(4):602-608.(李霞,李战怀,陈群,等.XML关键字检索中推断用户需求信息对象的方法XObject [J].西北工业大学学报,2010,28(4):602-608.)
[5] BAO Zhi-feng,Ling T W,LU Tia-heng.Effective XML Keyword Search with Relevance Oriented Ranking [C]//Proceedings of the 25th International Conference on Data Engineering.Shanghai:IEEE Computer Society,2009:517-528.
[6] GUO Wen-qi,CHEN Qun,LOU Ying.Method for Inferring XML Keyword Search Target Node [J].Computer Engineering,2012,38(8):41-49.(郭文琪,陈群,娄颖.一种推断XML关键字检索目标节点的方法 [J].计算机工程,2012,38(8):41-49.)
[7] LI Qiu-shi,WANG Qiu-yue,WANG Shan.Query Understanding for XML Keyword Search [J].Journal of Software,2012,23(8):2002-2017.(李求实,王秋月,王珊.XML关键词检索的查询理解 [J].软件学报,2012,23(8):2002-2017.)
[8] WEN Yan-long,ZHANG Ying,LIU Zhong-qi.Searching and Ranking XML Documents via Path Contraints [J].International Journal of Digital Content Technology and Its Application,2012,6(1):462-470.
[9] Christopher D M,Prabhakar R,Hinrich S.Introduction to Information Retrieval [M].New York:Cambridge University Press,2008.
[10] Ricardo B Y,Berthier R N.Modern Information Retrieval:The Concepts and Technology behind Search [M].New York:ACM Press,2011.
[11] GAO Ning,DENG Zhi-hong,JIANG Jia-jian,et al.Combining Strategies for XML Retrieval [C]//Proceedings of INEX Conference.Berlin:Springer-Verlag,2011:319-331.
[12] ZHANG Li-jun,LI Zhan-huai,CHEN Qun,et al.Classifying XML Documents Based on Term Semantics [J].Journal of Jilin University:Engineering and Technology Edition,2012,42(6):1510-1514.(张利军,李战怀,陈群,等.基于关键字语义信息的XML文档分类 [J].吉林大学学报:工学版,2012,42(6):1510-1514.)
[13] LOU Ying,LI Zhan-huai,CHEN Qun,et al.Effective XML Keyword Search with Considering Semantics of Tags [J].Journal of Huazhong University of Science and Technology:Natural Science Edition,2011,39(9):82-86.(娄颖,李战怀,陈群,等.一种考虑标签语义的XML关键字查询算法 [J].华中科技大学学报:自然科学版,2011,39(9):82-86.)
[14] UW CSE,UW Database Group,DAN Su-ciu.XML Data Repository [EB/OL].2002-11-21.http://www.cs.washington.edu/research/xmldatasets/.
[15] 花芳.文献检索与利用 [M].北京:清华大学出版社,2009.
