多资源融合的下位词发现
2013-11-30范庆虎昝红英柴玉梅张坤丽贾玉祥
范庆虎,昝红英,柴玉梅,张坤丽,贾玉祥
(郑州大学 信息工程学院,河南 郑州450001)
0 引 言
上下位关系是语义关系的一种,常用于词义消岐、本体、知识库、词典的构建和验证。如果一个词汇NPx的语义内涵包含在另一个词汇NPy内涵之中,此时NPx和NPy有上下位关系,即NPx为NPy的下位词,NPy为NPx的上位词,记作ISA (NPx,NPy)。例如 “水果”的下位词包括 “香蕉”、“葡萄”、“苹果”等,下位词不包括采用一般限定语修饰给定词所构成的合成词。目前,已经有了一些上下位词语关系词典,例如中文概念词典 (Chinese concept dictionary,CCD)、知网 (Hownet)、WordNet等。WordNet是一个英文语义字典,将英文中的名词、动词、形容词和副词组成一个同义词网络概念,在这些词汇概念间建立了同义关系、反义关系、上位关系、下位关系、整体部分关系以及完全关系等多种词汇语义关系。上述上下位关系词典都是通过人工进行构造,其维护成本较高,更新速度较慢,词语的覆盖率较低。随着Web的发展,一些网络知识为上下位关系的获取提供了丰富的资源,例如百度百科、互动百科、维基百科等,基于百科资源的上下位词汇关系可以通过计算机自动获取,容易实现,更新速度较快,有较高的词语覆盖率。本文结合词典和百科资源的优势进行中文词汇下位词发现。
1 相关工作
上下位关系的获取主要有基于模式和基于统计两种方法,当前获取上下位关系主要采用基于模式的方法,Hearst从大规模自由文本语料中提取出上下位关系的一些模式特征进行上下位关系的获取[1]。Asuka提出了基于维基百科的抽取方法,该方法主要对维基百科中文章内容的分层结构进行分析,抽取下位词[2]。Suchanek使用维基百科中分类信息对语义关系进行抽取[3]。刘磊等提出了一种从符合 “是一个”模式的句子中获取下位概念的方法,利用半自动获取的词典和句型对 “是一个”模式进行分析,然后根据不同的规则,分流获取下位概念[4]。Ichiro Yamada提出了一种建立大规模上下位关系语料库的方法,该方法首先从维基百科数据库中抽取和目标词语相似度最高的K个词语,然后结合相似度以及在维基百科中层次距离对K个目标词语分别打分,最后根据打分进行结果输出[5]。Ruiz-Casado等人使用模式匹配的方法从维基百科条目中抽取在 WordNet中并不存在的语义关系[6,7]。Shun提出结合每个概念词的图片特征和文本特征的属性继承,从Web获取上下位关系,进行下位词的获取[8]。对于上下位关系的自动验证,刘磊提出了一种基于混合特征的迭代上下位关系验证方法,该方法从语义、语境、空间结构角度,给出一组上下位关系特征,然后将所有特征转化为用于验证的产生式规则,最后利用这些规则进行循环迭代验证[9]。在2012年由中国计算机学会中文信息技术专业委员会主办的词汇语义关系评测,该评测包含下位词的发现,可见下位词的发现是词语语义关系中进一步句法和语义分析的基础,本文提出了多资源融合的下位词发现。
2 下位词发现
2.1 基于词典的方法
中文概念词典 (Chinese concept dictionary,CCD)是一部汉语语义词典,由北京大学计算语言学研究所开发,其保持了与WordNet的兼容,从结构构建上,CCD继承了WordNet的概念、词汇、语义关系,并且根据中文的文化习惯进行了调整[10]。
CCD中的语义关系有同义关系、反义关系、上下位关系、整体部分关系,其中上下位关系在每一个语义范畴中所确定的概念层次结构是一棵标记树,每个节点对应一个概念,每个节点的父节点表示其上位概念,子节点表示其下位概念,CCD中的名词概念和动词概念按照这种上下位概念关系形成一个森林。对下位词的发现和抽取,即对节点的子节点的发现和抽取,CCD中下位词发现如图1所示,分为以下4步:
步骤1 从目标词语料中抽取一个目标词,若为第一个目标词,则直接进入步骤2,否则抽取该下一个目标词,然后进入步骤2。
步骤2 目标词是否在于CCD的同义词集 (CSynset)字段,如果在则获得该字段对应的下位词集 (Hyponym)字段值,以8个数字单位截取该字段值,得到n个ID编号。
步骤3 检索每个ID编号在CCD的offset字段,得到ID编号对应的同义词 (CSynset)字段值,然后进行数据融合 (见第3.1节)、噪音过滤 (见第3.2节),得到下位词集合。
步骤4 若当前目标词为最后一个,则结束,否则跳转至步骤1。
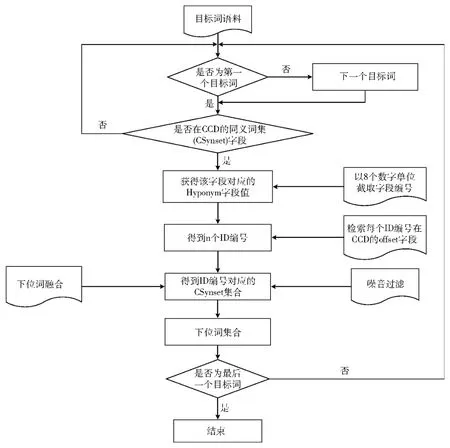
图1 基于词典的下位词发现
2.2 基于百科的方法
开放分类是百度百科、互动百科等百科里面的一个特定语义信息,是指比传统的目录式分类更灵活、更具自主性的分类方式 。本文对下位词的发现主要采用百度百科、互动百科、维基百科等开放分类资源。
百科的词条结构是由词条名、百科名片、段落标题和目录、词条正文、正文图片与图册、地图、模块、词条内链、参考资料、扩展阅读、相关词条、开放分类 (或分类)等组成,每一部分都是 “标记”了词条语义信息的内容,其中 “开放分类 (或分类)”是词条的所属分类,即目标词与所属分类存在上下位关系,我们定义开放分类中的每个分类内容为一个语义分类主题,同一个词条会存在多个语义分类主题,例如刘德华即属于歌手分类,又属于演员、艺人等分类。
基于百科的下位词发现如图2所示,分为以下4步:
步骤1 从目标词语料中抽取一个目标词,若为第一个目标词,则直接进入步骤2,否则抽取该下一个目标词,然后进入步骤2。
步骤2 分别抽取目标词的百度百科、互动百科、维基百科,以下UTF-8(目标词)表示对目标词的UTF-8编码。对百度百科的 URL抽取规则为:http://baike.baidu.com/taglist?tag=UTF-8 (目标词)&tagfromview,若目标词的百度百科Tag分类页面存在,则抽取Tag分类页面的主题标题,否则跳转至步骤1。对互动百科的URL抽取规则为:http://fenlei.baike.com/UTF-8 (目标词)/?prd=zhengwenye_left_kaifangfenlei,若目标词词条存在,则抽取词条中 “分类热词”栏目的主题标题,否则跳转至步骤1。对 维 基 百 科 的 URL 抽 取 规 则 为:http://zh.wikipedia.org/wiki/Category:UTF-8 (目 标 词),若 目标词词条存在,则抽取词条中 “分类”栏目的主题标题,否则跳转至步骤1。
步骤3 对百度百科、互动百科、维基百科中抽取的主题标题进行资源融合 (见第3.1节)、噪音过滤 (见第3.2节),得到下位词集合。
步骤4 若当前目标词是最后一个目标词,则结束,否则跳转至步骤1。
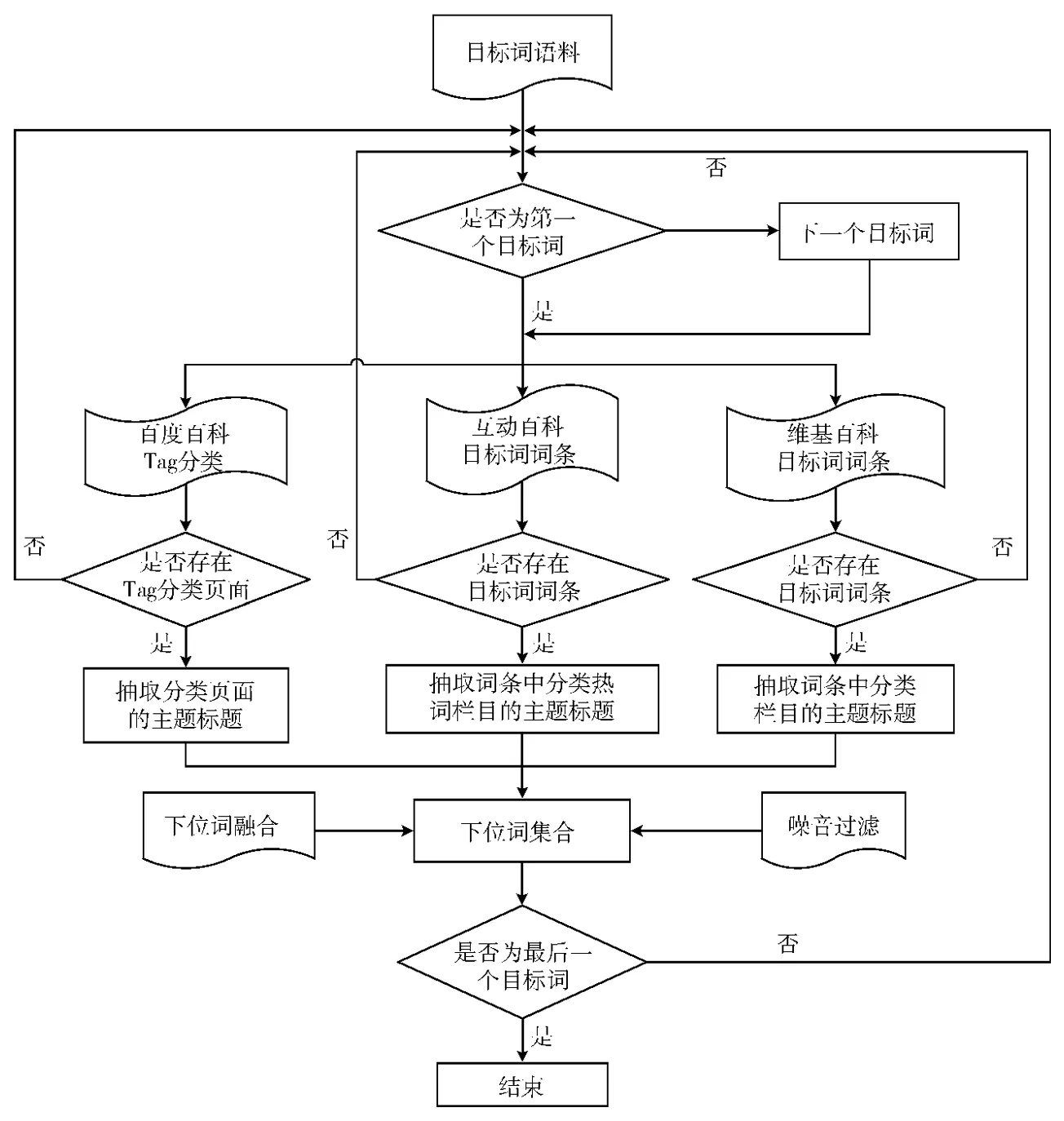
图2 基于百科的下位词发现
2.3 基于百度相关搜索的方法
百度的相关搜索可以通过参考别人的搜索来获得一些启发,按搜索热度、搜索相关度、该词的百度流量等规则进行排序。百度相关搜索的结果不仅与目标词存在同义关系、反义关系、上下位关系,而且存在其他的相关关系,基于百度相关搜索的下位词发现如图3所示,分为以下几步。
步骤1 从目标词语料中抽取一个目标词,若为第一个目标词,则直接进入步骤2,否则抽取该下一个目标词,然后进入步骤2。
步骤2 对目标词进行百度搜索,若存在目标词的 “相关搜索”,则抽取目标词的相关搜索结果,否则跳转步骤1。
步骤3 对相关搜索结果进行下位词融合 (见第3.1节)、噪音过滤 (见第3.2节),得到下位词结合,若当前目标词是最后一个,则结束,否则跳转至步骤1。
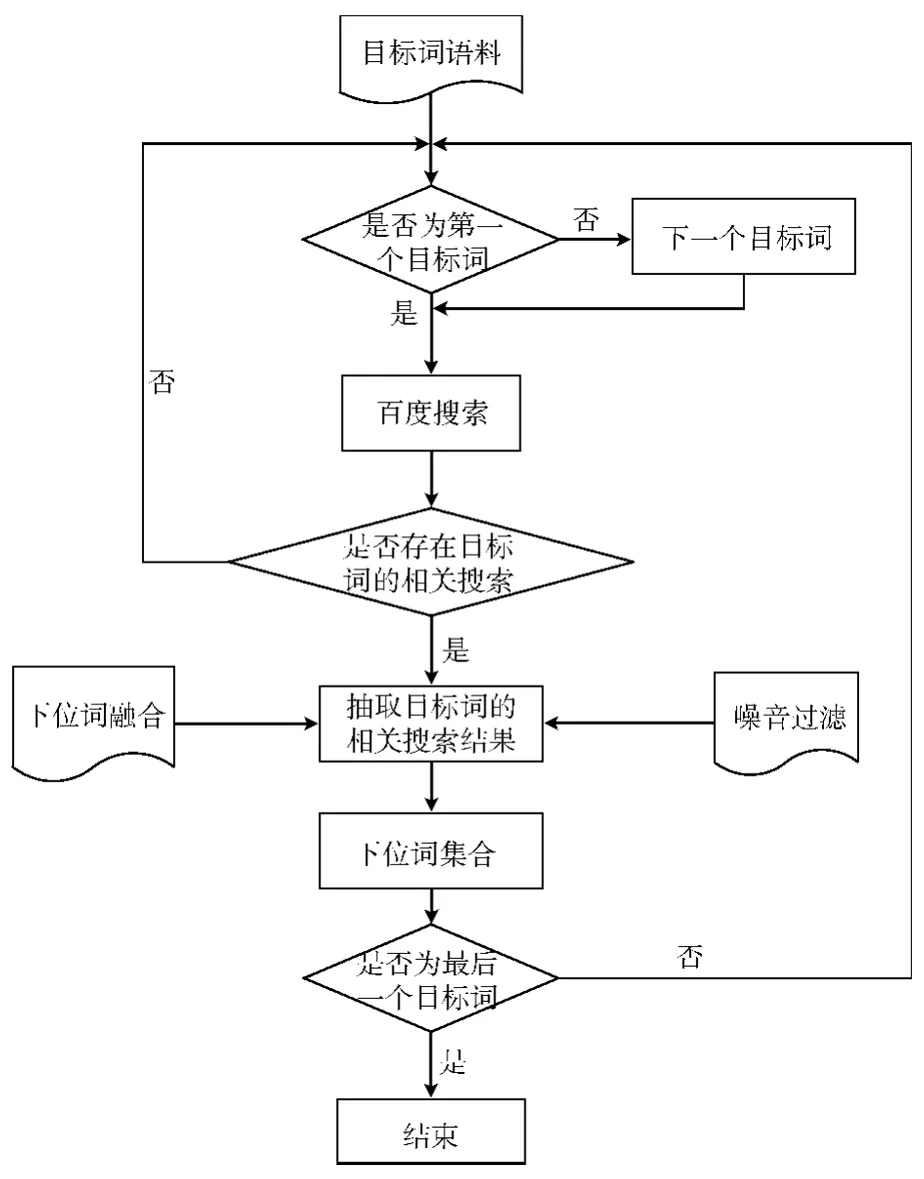
图3 基于百度相关搜索的下位词发现
相关搜索结果与目标词是否存在上下位关系是问题的关键。为了验证相关搜索结果含有上下位关系,假设基于词典方法的结果为H1,基于百科方法的结果为H2,基于百度相关搜索方法的结果为H3,若 或 ,则可证明相关搜索结果含有上下位关系。例如词语 “儒家”在百度相关搜索结果如图4所示。

图4 “儒家”相关搜索结果
图4 所示相关搜索结果即H3={儒家思想,儒家经典,儒家文化,……},基于百科方法 (见第2.2节)的结果H2={孟子,中庸,千字文,伏念,墨家,儒家思想,格物致知,……},则H2∩H3={儒家思想,……}≠ 。
3 下位词数据处理
3.1 下位词数据的整合
在数据预处理阶段采用网络爬虫获取Web资源,下载目标词的百度百科、互动百科、维基百科、百度相关搜索等HTML网页文本,为了便于下位词的发现,过滤HTML网页文本中的标记,提取出其中的纯文本内容,并且保留了其中的开放分类、分类、分类热词等关键标签文本内容。词条内容可用三元组Q (Word,Content,Catagory)表示,其中Word表示词条,Content表示词条的正文内容,Category表示词条的开放分类、分类、分类热词等文本内容。
通过不同的方法获取的下位词数据各有差别,因此不同的数据整合方法会产生不同的结果。数据整合的方法可以分为[11]:
(1)直接合并。将不同方法获得的下位词数据直接加入下位词集合,并且进行下位词的去重。
(2)加权合并。根据获取不同下位词方法的可信度,可以对不同的方法进行加权,最终对下位词的结果进行排序,然后设定阈值进行获取。
为了保证下位词数据的召回率,本文下位词的获取主要采用直接合并的方法对下位词的结果进行整合,通过词典发现的下位词集合为R1、百科发现的下位词集合为R2、百度相关搜索的下位词集合为R3,则最终的下位词集合为R={R1∪R2∪R3}。
3.2 下位词数据的噪音过滤
百科知识为信息的获取提供了丰富的资源,但是由于百科知识的开放性,具有不同知识背景的人都可以对百科词条内容的编纂,词条内容难免会出现数据噪音,因此数据噪音的过滤对下位词的发现至关重要,对数据噪音的处理如下:
(1)对含有噪音特征词语的结果进行过滤。例如 “儒家”的相关搜索结果中 “儒家思想的核心”很明显不为“儒家”的下位词,其中的特征词为 “的”。通过人工对相关搜索结果的分析构造的部分特征词语及例子如表1所示。

表1 部分特征词及例子
通过分析构造的特征词语:的、什么、是、多少、吗、特殊字符 (字母、数字、空格、标点符号)、怎么、下载、吧、有、哪、和、如何、之、大全、全集、作用、关于、在、意思、图片、高清、价格、含义、用途、方法、不、公司、原因等。
(2)同音词过滤。同音词指的是声、韵、调完全相同,而意义完全不同的一组词。例如词语 “车站”的相关搜索结果中出现 “车展”, “车站”和 “车展”是同音词 (che zhan),但这两个词语明显不存在上下位关系,本文使用pingyin4j对同音词进行处理。
4 实 验
4.1 实验数据
实验数据采用NLP&CC2012中文词汇语义关系任务中的评测数据。下位词评测数据集包括10000个词汇。数据来源包括普通词典、百科词条、叙词表等多种资源,词汇的词性包括普通名词和专有名词。
4.2 评测方法
评测数据的结果采用人工标注,最终生成256个目标词的标准答案,据此进行评测。
评测采用3个指标:正确率 (Precision),召回率 (Recall)和F值 (F-measure),并分别计算其微平均值和宏平均值。
4.2.1 微平均
微平均以每个语义关系为一个计算单元,具体计算公式如下:
正确率表示发现的语义关系 (同义或下位)中出现在标准结果中的比例,计算式 (1)如下

其中,词表中的每个词汇与发现的每个同义词 (或下位词)为一条语义关系。发现的同义词之间的关系不计算在内。
召回率表示标准结果中被正确发现的语义关系比例,计算式 (2)如下

F值是正确率和召回率的调和平均数,计算式 (3)如下

4.2.2 宏平均
宏平均以每个词为一个计算单位,每个词的评价指标正确率计算式 (4),召回率计算式 (5),F值计算式 (6)如下所示


宏平均值正确率计算式 (7)、召回率计算式 (8)、F值计算式 (9)如下所示

其中,N为评测词汇总数。
4.3 实验结果
为了验证不同方法对下位词发现的影响,本文分别使用基于词典、基于百科资源、基于词典和百科资源相结合的方法进行实验,实验结果如表2所示。
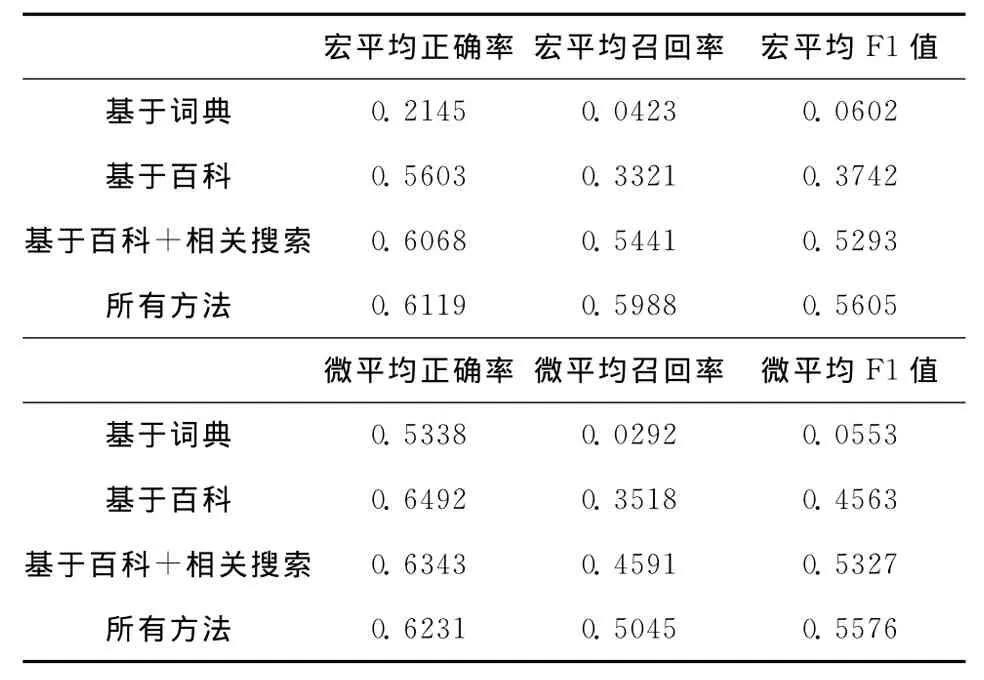
表2 不同方法的实验结果
表2实验结果表明,基于词典的下位词发现召回率偏低 (仅为0.0423),基于百科的方法对下位词发现的召回率有明显的提高 (为0.3321,提高近30%),表明基于百科方法的有效性;基于百度相关搜索的方法不仅提高下位词的召回率,而且提高了正确率 (基于百科资源和相关搜索方法的结合与基于百科资源方法不仅宏平均F1值提高15%,而且微平均F1值提高8%),表明基于百科相关搜索的有效性;最后将所有方法的结果进行直接合并,不仅提高了召回率,而且宏平均F1值和微平均F1值相比第三种结合方法分别提高3%和2.5%,这进一步表明多资源融合的方法可以避免单一方法对下位词发现的数据稀疏问题,从而提高下位词发现的召回率和正确率,更加有效的解决对词汇语义关系发现的问题。
本文研究参加了2012年中国计算机学会中心信息技术专业委员会举办的 “中文微博情感分析和词汇语义关系抽取评测任务”中下位词发现的评测任务,评测结果如表3所示。
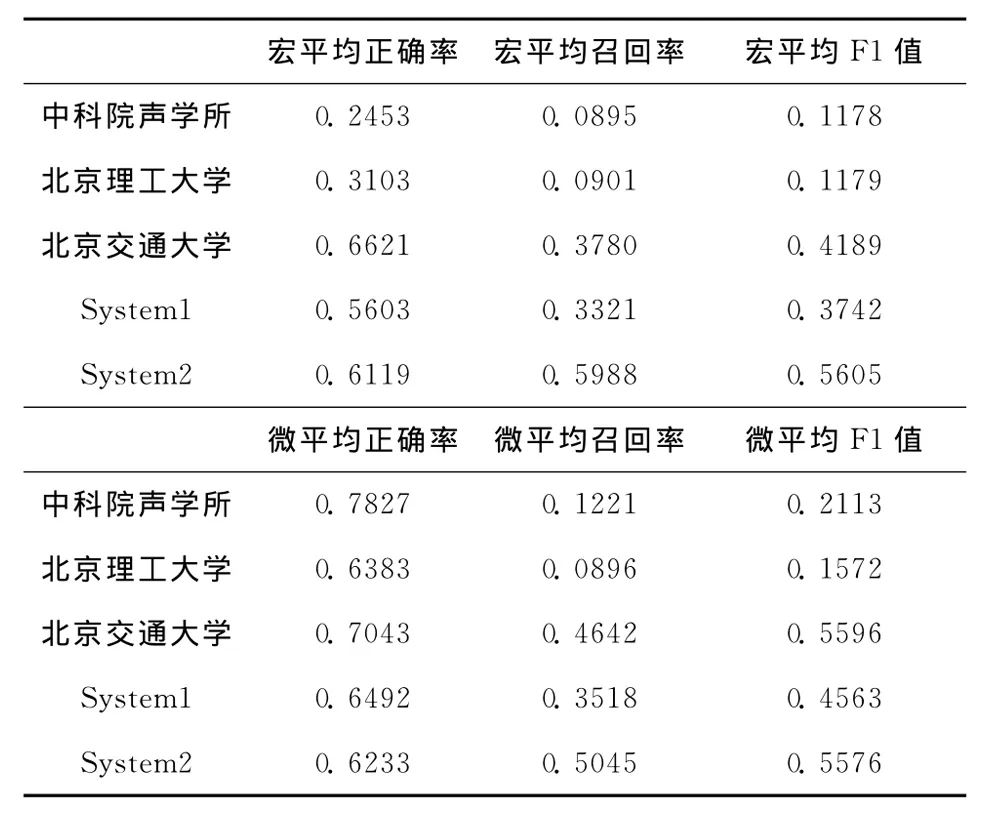
表3 下位关系评测结果
表3中system1是采用基于词典和百科资源结果相融合的方法,system2是在system1方法的基础上融合了百度相关搜索的结果,结果中宏平均召回率提高26%,微平均召回率提高15%,宏平均F1值提高19%,微平均F1值提高10%,表明了百度相关搜索对下位词的发现有很高的可信度,system2实验结果表明,多资源融合的方法能够有效地对下位词进行发现。
5 结束语
下位词信息是自然语言处理中很重要的资源,是进一步进行句法和语义分析的基础,而此类语义词典的手工构建是一项非常耗时耗力的浩大工程,存在着不易更新、覆盖度不去等诸多缺陷。本文结合网络资源的优点:通过计算机自动获取、容易实现、更新速度较快、有较高的词语覆盖度,对百度百科、互动百科、维基百科、百度相关搜索等多种资源的分析,并且结合已有语义词典进行下位词的发现;最后对各种方法抽取的下位词进行数据融合、噪音过滤。实验表明,多方法的融合能够有效地进行下位词发现。本文所述下位词发现的方法虽然比较有效,下一步工作:首先,结合更多的语义词典 (如Hownet),来提高正确率和召回率;其次,不断完善数据噪音特征,提高数据的正确率;最后,使用 “是一个”和模式匹配的方法对下位词进行发现,进一步提高召回率。另外,将抽取下位词的方法推广到其他语义关系密切的词类。
[1]Hearst,Marti A.Automatic acquisition of hyponyms from large text corpora[C]//Proc of the 14th International Conference on Computational Linguistics,1992:539-545.
[2]Asuka Sumida,Kentaro Torisawa.Hacking Wikipedia for hyponymy relation acquisition[C]//Proceedings of the Third International Joint Conference on Natural Language Processing,2008:883-888.
[3]Fabian M Suchanek,Gjergji Kasneci,Gerhard Weikum.Yago:A core of semantic knowledge unifying wordnet and wikipedia[C]//Proceedings of the 16th International World Wide Web Conference,2007.
[4]LIU Lei,CAO Cungen,WANG Haitao,et al.A method of hyponym acquisition based on “isa”pattern[J].Computer Science,2006,33 (9):146-151 (in Chinese).[刘磊,曹存根,王海涛,等.一种基于 “是一个”模式的下位概念获取方法[J].计算机科学,2006,33 (9):146-151.]
[5]Ichiro Yamada,Kentaro Torisawa,Jun’ichi Kazama,et al.Hypernym discovery based on distributional similarity and hierarchical structures[C]// Proceedings of the Conference on Empirical Methods in Natural Language Processing,2009:929-937.
[6]Ruiz-Casado Maria,Alfonseca Enrique,Castells Pablo.From Wikipediato semantic relationships:A semi-automated annotation approach[C]//the Third Annual European Semantic Web Conference,2006.
[7]Ruiz-Casado Maria,Alfonseca Enrique,Castells Pablo.Automatising the learning of lexical patterns:An application to the enrichment of WordNet by extracting semantic relationships from Wikipedia[J].Data Knowledge and Engineering,2007,61 (3):484-499.
[8]Shun Hattori.Hyponym extraction from the web based on property inheritance of text and image features[C]//The Sixth International Conference on Advances in Semantic Processing.2012:109-114.
[9]LIU Lei,CAO Cungen.Hyponymy relation verification method based on hybrid features[J].Computer Engineering,2008,34(14):12-16 (in Chinese).[刘磊,曹存根.基于混合特征的上下位关系验证方法[J].计算机工程,2008,34 (14):12-16.]
[10]YU Jiangsheng,YU Shiwen.The structure of chinese concept dictionary[J].Journal of Chinese Information Processing,2002,16(4):12-20 (in Chinese).[于江生,俞士汶.中文信息概念的结构[J].中文信息学报,2002,16 (4):12-20.]
[11]LU Yong,ZHANG Chengzhi,HOU Hanqing.The structure of chinese concept dictionary[J].Journal of Library Science in China,2010 (1):56-62 (in Chinese).[陆勇,章成志,侯汉清.基于百科资源的多策略中文同义词自动抽取研究[J].中国图书馆学报,2010 (1):56-62.]
