基于GPU的LDPC存储优化并行译码结构设计
2013-11-05刘荣科
葛 帅 刘荣科 侯 毅
(北京航空航天大学 电子信息工程学院,北京100191)
LDPC(Low-DensityParity-Check)码由Gallager于1962最早提出[1],但限于当时的计算机仿真水平,它的出现并没有得到足够的重视.直到20世纪末,Mackay,Neal等人发现其为具有逼近香农限性能的优秀纠错编码,具有很强的纠错和检错能力.准循环低密度奇偶校验码(QCLCPC,Quasi-Cyclic LDPC)以其码字设计的低复杂度,正逐渐取代Turbo码成为信道编码的研究热点.经典的LDPC码的译码方式是基于Tanner图的双相消息传递(TPMP,Two Phase Message Passing)译码算法.TPMP译码算法具有性能优异且易于使用并行计算实现等优点.现今采用的LDPC码译码方式大多由TPMP译码算法演化而来.由于现今采用的LDPC码多为准循环码,其校验阵可按行划分为最大列重不大于1的若干行块,译码时可以将LDPC码看作若干单校验分量码的级联码,利用Turbo原理进行分量码之间的迭代消息传递过程,称为Turbo消息传递(TDMP,Turbo Decoding Message Passing)译码算法[2-3],也称分层译码算法.
在实际应用中,为获得高吞吐量和实时处理能力,LDPC码的译码实现通常采用硬件平台,如FPGA(Field Pregrammable Gate Arrays).但通常硬件平台灵活性和可扩展性较差[4-6],只能胜任某些固定码率和码长的LDPC码的译码工作.由于LDPC码的应用场合不断扩大,对译码灵活性、扩展性的要求越来越高,使得传统硬件平台实现的LDPC码的译码架构难以应付多码长、变码率译码的缺点日益突出.
如今,采用多核并行处理是提升处理器性能的重要方式[7].图形处理单元(GPU,Graphic Processing Unit)通常包含成并行结构的海量运算单元.由于市场的需要对GPU所提出的要求越来越高,GPU已经发展成为了并行度高、多线程、计算快速、储存器带宽大的高性能通用计算设备[8-9].然而传统的GPU编程大多需依靠如Direct3D或OpenGL的标准图形接口,这使GPU编程受限于图形应用程序编程接口,使用这些图像渲染语言要求编程者拥有相应的计算机图形学知识.Nvidia公司发布的统一计算设备架构(CUDA,Compute Unified Device Architecture),通过对标准C语言的一定拓展与改造,使得用户可以通过类C语言代码来实现GPU线程的调度,为GPU在通用计算领域的应用提供了良好的开发环境.
由于GPU执行高并行计算任务体现出的巨大优势,尤其是其相对于传统硬件平台的灵活性与可扩展性优势,其在LDPC码译码领域具有很高的应用前景,得到了广泛的研究.文献[10]中利用OpenGL提供的标准图型接口,在Caravela平台上对5种码字进行译码,相对于CPU译码吞吐量获得3.5倍加速.文献[11]中利用异步数据传输技术在NVIDIA Tesla C1060平台上相比CPU平台未优化结果获得了271倍的译码速度提升.文献[12]中通过分析LDPC码译码的数据结构,提出针对GPU平台的联合内存访问的优化方式,在NVIDIA 8800GTX平台和8位精度条件下,获得了40 MB/s的吞吐量.文献[13]提出通过充分利用显存带宽并引入提前停止准则的方式提高LDPC码TPMP译码的吞吐量.文献[14]采用一种校验阵压缩存储的方式,将校验阵存储在常量内存中,对规则和非规则QC-LDPC码,相比传统存储方法分别获得了2倍和1.5倍的加速.
本文提出一种基于Nvidia公司Fermi GPU架构的LDPC存储器优化分层译码算法实现结构,帧间与帧内并行相结合的并行结构,减少节点信息更新的运算分支,对全局存储器采用高效的联合内存访问以及使用常数存储器.测试结果表明,在同等硬件条件下,本文提出的基于GPU的两级并行和合并访存的译码优化方案可以显著提升LDPC译码速度.
1 分层译码算法
分层算法(TDMP)是一种按照因子图上的校验节点顺序进行消息更新传递的串行译码机制,对目前广泛应用的QC-LDPC码,将校验矩阵依据列重不超过1的原则分为若干行块,每一行块为一层,层内校验节点的更新可并行完成,层间的消息传递为串行方式.每层可以定义一个新的校验矩阵Ct,各层校验矩阵的总和构成了原校验矩阵,即:
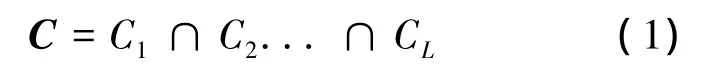
在迭代过程中逐层进行更新,以最后一层的输出作为当前次迭代的译码输出,进行硬判决以及提前停止校验.
基于Log-BP的TDMP的算法描述如下:
第一步:初始化信息:
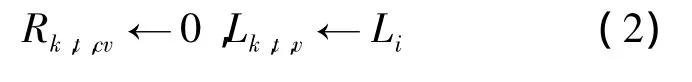
第二步:各层依次进行迭代更新:
在每一层中,对于校验节点c和变量节点v,层间的置信度传递如下计算:
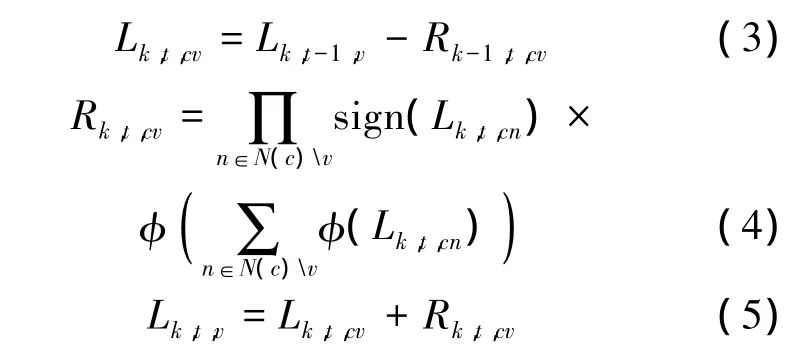
第三步:译码判决.待一次迭代结束后将获得的信息进行比特硬判决:
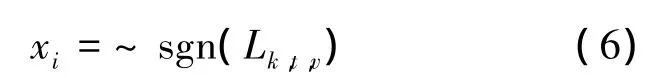
若译码结果满足校验方程或达到最大迭代次数则终止译码迭代.其中,对于第k次迭代中的第t层,校验节点 c传递给变量节点 v的信息由Rk,t,cv表示,变量节点 v传递给校验节点 c的信息由 Lk,t,cv表示,第 t层传递给下一层的变量节点的信息由 Lk,t,v表示,Li表示从信道接收得到的对数似然比软信息,log-BP算法中的函数φ(x)定义为
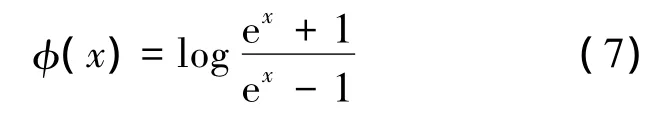
相较于传统的TPMP译码算法,分层译码算法对比特节点的信息利用更加及时,对每一层进行并行译码后,立即将更新的置信信息传递到下一层进行置信度更新,减少了译码的迭代次数.根据文献[3],相对于TPMP算法,分层译码算法能够将收敛迭代次数降低约50%.
部分并行的分层译码算法利于并行资源受限的GPU平台进行译码结构实现,尤其是码长上千的中长码.本文提出的分层译码结构利用帧间与帧内并行相结合,充分发掘了GPU运算潜力.
2 结构优化设计
2.1 校验阵压缩与constant memory
constant memory是GPU的片上只读存储器,其访问延迟相比片外显存中的global memory低两个数量级.在Fermi架构中,constant memory存储空间为64 KB,多用于存储CUDA程序中需读取频繁的只读参数.对于计算能力为2.x的GPU,当属于同一个half-warp的线程访问constant memory中的同一数据时,则发生数据广播,只需一个访存周期即可获取数据.
传统的校验阵存储方式是将校验阵中每一行的非零元素所对应的列号依次存储至片下global memory存储器中.译码过程中对校验阵的频繁读取会导致译码延迟.本文提出的LDPC码分层译码结构采用constant memory存储校验矩阵,如图1.短码的校验矩阵可以直接写入存储器,但对中长码,其校验矩阵规模远超过constant memory大小,必须对校验阵进行压缩存储.
对于大部分QC-LCPC码,其校验矩阵可分割为多个子方阵,每个子方阵为零阵或经循环右移后的单位阵.对非零子阵,其所在列号、层号、层内序号及右移次数即可表征其全部性质,层内序号U指本子阵在本层内为第U个非零子阵.存储校验阵时,仅需记录非零子阵的位置信息与其单位阵右移位数即可.如图1所示,将第L层层内序号为U非零子阵的列号及其循环右移的位数分别存至两个位宽为32 byte的constant memory区块中的第L行第U列内.故存储校验阵非零子阵列号及右移次数所需空间分别为G×32 byte.其中G为校验阵总层数.以码长40960校验位24576,子方阵阶数2048的QC-LDPC码为例,校验阵层数为G=24576/2048=12,存储空间共需32×12×2=768 byte.

图1 校验阵压缩方式
2.2 global memory的联合访问
global memory位于GPU片外的显存中,在联合读取的条件下,global memory可提供很高的访问带宽,否则会产生分区访问冲突,造成较高的访存延迟.联合访问是指对于计算性能为2.x的Fermi架构GPU,当同一warp中的32个线程按照一定字长依次访问对齐后的数据段时,仅需一次传输就可处理warp内线程的访存要求.
对QC-LDPC码的分层译码结构,式(2)、式(3)中的 Rk,t,cv和 Lk,t,v的对数似然比数值存储于global memory中.对于一个校验阵大小为P×Q,子阵为D阶方阵最大行重为B的QC-LDPC码,对校验节点 c传递给变量节点 v的信息 Rk,t,cv,传统的访存方式的存储地址为

其中,pc为当前线程更新的 Rk,t,cv对应列号;U 为当前线程更新的 Rk,t,cv所在子阵的层内序号,这种访存方式的访存位置依据于线程处理的Rk,t,cv对应于校验阵的位置,易于理解,但访存不能满足联合的访问要求.
本文提出的访存模式如图2所示,Rk,t,cv的存储位置不依据校验阵的位置,而依据于线程所在线程网格的位置.通过对 Rk,t,cv重新排列,将编号为 T 的线程所读取的 Rk,t,cv存放于:

T代表当前线程编号;M代表该线程所处线程块编号.通过重排不同线程访存地址随线程号增加,使得每个线程块内的线程依次访问global memory内连续存储空间,满足联合存储要求.
对于译码过程中层间传递信息 Lk,t,v,传统访存方法为按块对齐,当某warp访问至对齐边缘时,若不能满足同一warp内的32个线程同时处于对齐边缘内,则会产生分区冲突,导致多次访存.如图3a中,当某warp访问至子块边缘时,若第K号线程与第K+1号线程属于同一warp,则会发生分区访问冲突.

图2 Rk,t,cv 联合存储信息更新模式
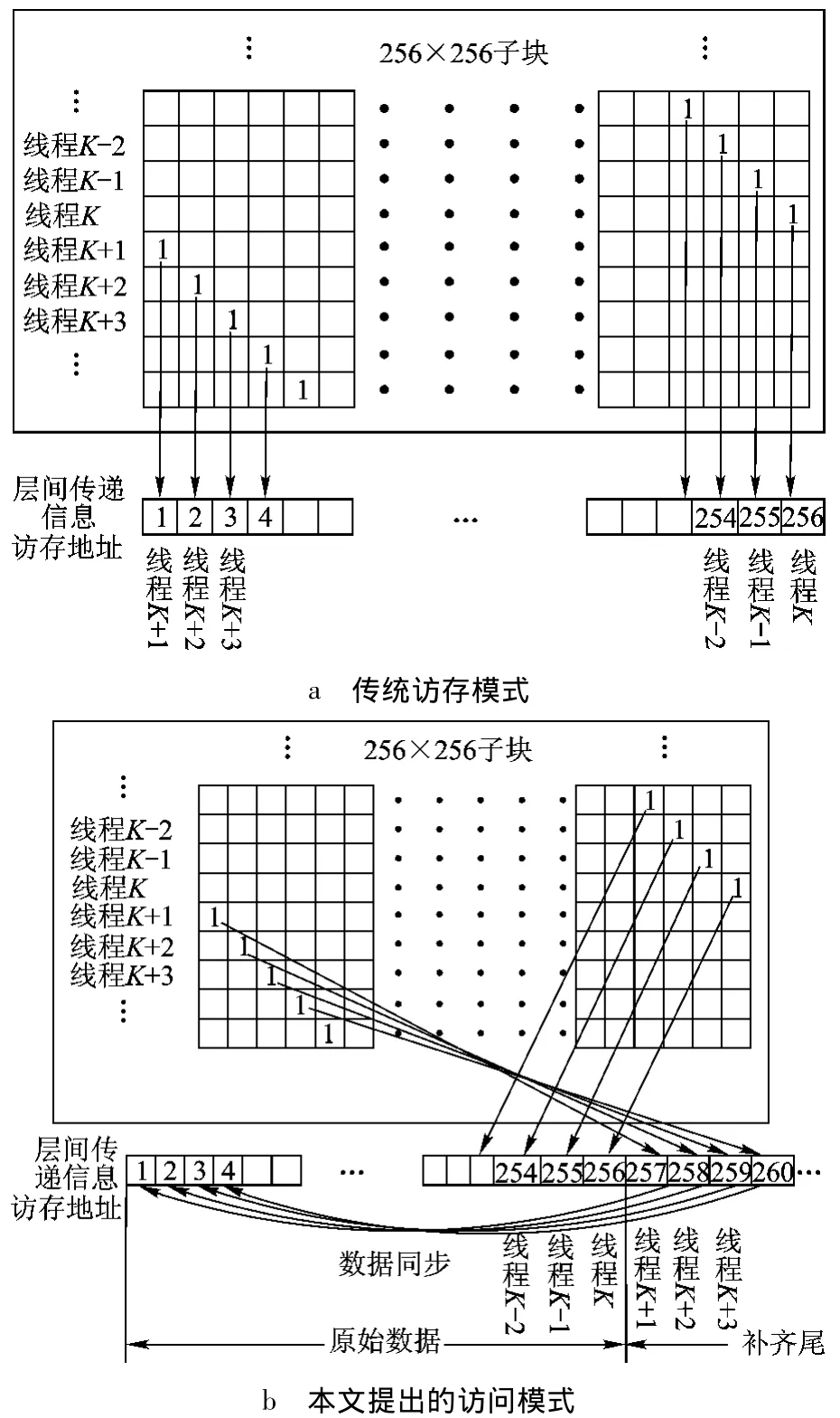
图3 更新至子块边缘时访存状况
对此,本文所提译码结构采用图4所示访存模式:图中W为warp的包含的线程总数,对于Fermi架构的GPU,W取为32.图中LK,D代表第K个子块中的第D个层间传递信息,在按块大小对齐的原信息块基础上前后分别添加长度为W-1的数据作为对齐头和补齐尾,将第K个子块的前W-1个数据拷贝至第K个子块的补齐尾,将第K个子块的后W-1个数据拷贝至第K个子块的对齐头,并保持数据同步.当某warp访问至对齐边缘时,如图3b,若第K号线程与第K+1号线程属于同一warp,则将线程号大于K的线程得出的层间传递信息数据写入补齐尾,以保证同一warp内的线程数据满足联合读取,再将补齐尾中的数据同步至原始数据中对应的字段.译码判决时,只需舍弃对齐头与补齐尾,便可进行译码判决.

图4 Lk,t,v 联合存储信息更新模式
2.3 多帧并行处理
对于Fermi架构的 GPU,每个流多处理器(SM,Streaming Multiprocessor)至少需运行576个线程才能隐藏算数流水延迟.而分层译码算法要求每一层的列重至多为1,这限制了GPU架构下分层译码结构的并行度,对GPU资源形成浪费.以本文在实验中采用的40 960×24 576层宽为2048的QC-LDPC码为例,单个码字的最大并行度即为层宽,假设每个SM内放置1 024个线程,则译码过程占用两个 SM,仅为 GeForce GTX580提供的SM总数的12.5%.
对此,本文采用多帧并行处理,即在GPU内并行进行多帧译码,以提高GPU资源利用率.文献[14]中指出多帧处理会带来大量条件分支,在GPU架构下将导致warp内的指令执行延迟增加,降低译码吞吐量.本文采用减少控制流指令及谓词执行(predicate execution)的方式以减少条件分支对译码吞吐量的影响.谓词执行是指将分支中的指令作为代码块处理,并将其中指令与谓词关联,执行时,谓词为假的指令随谓词为真的指令共同执行,但不将结果写回.
表1以利用 GeForceGTX580GPU对40960×24576层宽为2048的LDPC码进行译码为例,分别展示了采用8帧并行处理与单帧处理时GPU内的资源的利用情况以及可用运算资源总量.
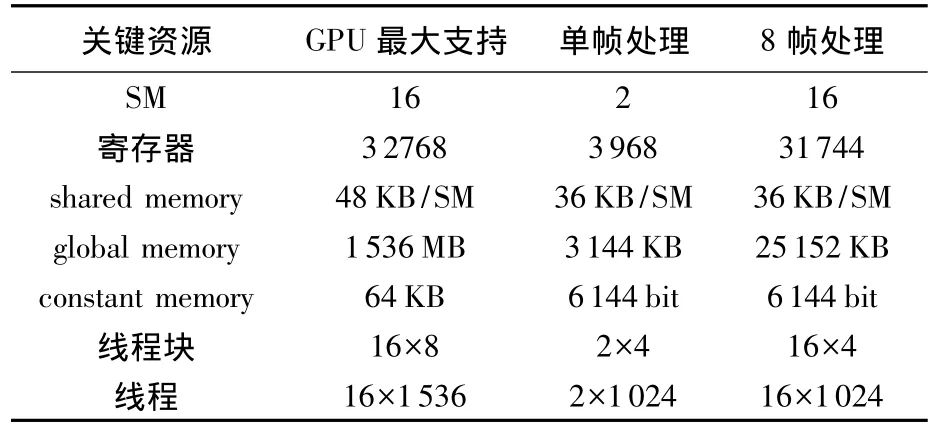
表1 单帧处理与8帧并行时GPU资源使用情况
由表1可得,采用多帧并行处理技术可以提高SM的使用效率,更好的利用GPU提供的资源.图5展示了信噪比为1.1 dB时在不同并行帧数下相对于单帧处理时的译码吞吐量倍率.
根据图5,在GPU架构下采用多帧并行可以的提升LDPC码译码的吞吐量.
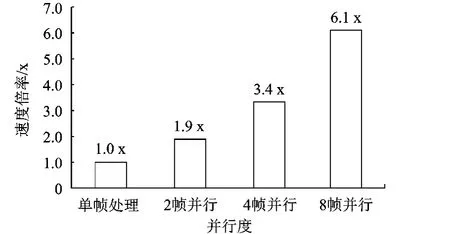
图5 不同并行帧数下译码吞吐量
3 实验结果
3.1 硬件原则与编译环境
表2显示了本文采用并行译码结构硬件环境.其中基于 GPU的 LDPC码译码结构采用Nvidia公司CUDA4.0版本编译器编译,基于CPU的LDPC码译码结构则采用Visual Studio 2010提供的标准的C编译器编译.

表2 硬件环境
3.2 测试结果
本文对所提出的分层译码结构在两种不同长度的QC-LDPC码条件下分别进行测试,最大迭代次数设定为20次.H矩阵选取CCSDS标准[15]中的码型.校验矩阵的详细参数参见表3.
在消息迭代过程中本文采用32 bit量化标准以及双曲正切函数实时计算的方式,以获得更优的译码性能,相比FPGA译码实现平台,GPU平台具备更优秀的高精度运算优势.

表3 校验阵参数
表4、表5为对10 000帧进行译码所需时间以及吞吐量对比.其中表4是校验矩阵为H1信噪比为1.8 dB对应的测试结果,表5是校验矩阵为H2信噪比为1.1 dB的测试结果.其中优化方式Ⅰ代表global memory联合访问的优化方式,优化方式Ⅱ代表校验阵压缩与采用constant memory优化方式.其中H1和H2分别采用并行度为32和8的多帧并行译码.
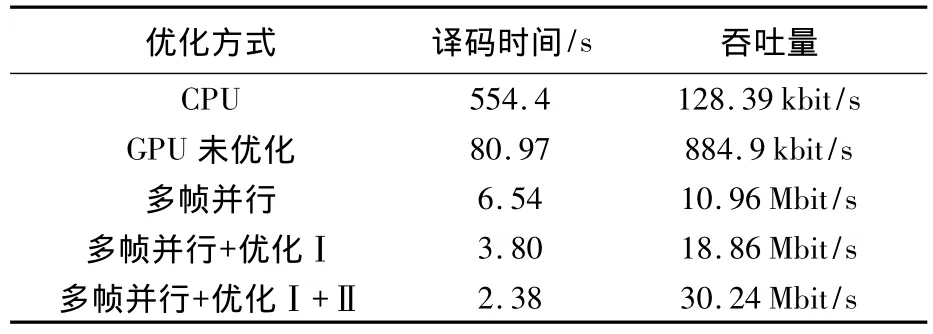
表4 检验矩阵为H1时译码时间与吞吐量
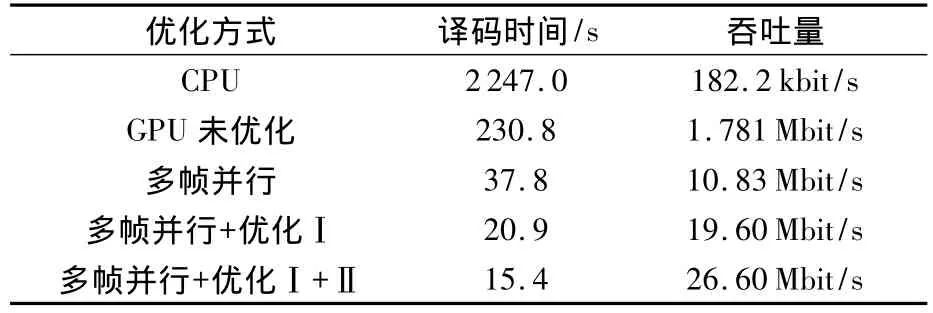
表5 检验矩阵为H2时译码时间与吞吐量
根据表4、表5,对于10000帧进行译码时,校验矩阵为H1和H2的码对应的译码时间分别为2.38 s和15.4 s,而未优化的译码时间则分别为80.97s和230.8s,优化后的相对于未优化的GPU译码吞吐量分别提升34.8倍和14.9倍.
分块子矩阵的维数即码字层宽较低时,吞吐量的提升较大,其主要原因是码字层宽较低时采用多帧处理对吞吐量的提升较大.通过采用多帧并行处理可以分别提升校验阵为H1的码字和校验阵为H2的码字译码速度12.4倍和6.1倍,这是由于校验阵为H1的码字层宽即分块子矩阵的维数为256,采用单帧处理时最高并行度为256,严重限制了GPU译码器的并行度.在采用多帧并行处理时对分块子矩阵的维数较低的LDPC码可采用较高的并行帧数,以获得更大的吞吐量提升.由此可得对于利用分层译码算法对分块子矩阵的维数较低的LDPC码进行译码时采用多帧并行处理优化效果优于对分块子矩阵的维数较高的LDPC码进行分层译码算法,可以有效消除帧内并行度不足对译码吞吐造成的限制.
采用global memory的联合访问的优化方式对于译码速度的提升达到约1.8倍,这是由于未优化的译码器在消息节点更新过程中由于访存冲突导致极大地访存延迟.
采用constant memory存储校验阵对于对校验阵为H1和H2的码字速度提升别为1.6倍和1.35倍.对于校验阵为 H1的 LDPC码采用constant memory存储校验阵优化效果优于校验阵为H2的 LDPC码,这是由于校验阵为 H1的LDPC码的平均行重和列重大于校验阵为H2的LDPC码,译码过程中对校验阵读取更加频繁,因此采用此优化方式效果相对更明显.
4 结论
1)本文提出一种新的基于Fermi架构GPU平台下的QC-LDPC码存储器优化并行译码结构设计.本设计采用32 bit精度值的分层译码算法.实验结果表明,相对于未优化GPU平台下分层算法译码结构,本文提出译码结构在校验阵为7168×4096层宽为256和校验阵为40960×24 576层宽为2048的QC-LCPC码情况下分别可以获得34.8倍和14.9倍的译码吞吐量提升.
2)通过采用多帧并行译码处理,可提高译码并行度,分块子矩阵的维数较低时,GPU译码器的并行度受到限制,采用本文的多帧并行译码处理对译码速度提升效果尤为显著.通过采用多帧并行处理可以分别提升子矩阵维度为256和2048的QC-LDPC码译码吞吐量12.4倍和6.1倍.
3)在校验阵为7168×4096层宽为256和校验阵为40 960×24 576层宽为2 048的QC-LCPC码情况下,采用global memory的联合访问以及constant memory存储压缩校验阵两种优化方式分别可以提升译码吞吐量2.76倍和2.45倍.
References)
[1] Gallager R G.Low-density-parity-check-codes[J].IRE Trans-In-formation Theory,1962,18:21-28
[2] Mansour M M,Shanbhag N R.Turbo decoder architectures for low-density parity-check codes[C]//Chi-kuo Mao.Global Telecommunications Conference.Taipei:Cornell University,2002:1383-1388
[3] Mansour M M,Shanbhag N R.A 640-Mb/s 2048-bit programmable LDPC decoder chip[J].IEEE Journal on Solid-State Circuits,2006,41(3):684-698
[4] Zhang T,Parhi K.Joint(3,k)-regular LDPC code and decoder/encoder design[J].IEEE Trans Signal Processing,2004,52(4):1065-1079
[5] Dielissen J,Hekstra A.Low cost LDPC decoder for DVB-S2[C]//Cyprian Grassmann.Proc Conf Design,Automation and Test in Europe(DATE ’06).Munich,Germany:Designers’Forum,2006:130-136
[6] Daesun Oh,Keshab K Parhi.Low-complexity switch network for reconfigurable LDPC decoders[J].IEEE Transactions on Very Large Scale Integration Systems,2010,18(1):85-94
[7] Blake G,Dreslinski R G,Mudge T.A survey of multicore processors[J].IEEE Signal Processing Magazine,2009,26(6):26-37
[8] Sanders J,Kandrot E.CUDA by example[M].New Jersey,USA:Addison-Wesley,2010:4-6
[9] Goodnight N,Wang R,Humphreys G.Computation on programmable graphics hardware[J].IEEE Computer Graphics and Applications,2005,25(5):12-15
[10] Falcão G,Yamagiwa S,Silva V L.Parallel LDPC decoding on GPUs using a stream-based computing approach[J].Journal of Computer Science and Technology,2006,24:913-924
[11] Chang Chengchun,Chang Yanglang,Huang Minyu,et al.Accelerating regular LDPC code decoders on GPUs[J].IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing September,2011,4(3):653-659
[12] Gabriel Falcão,Leonel Sousa,Vitor Silva.Massively LDPC decoding on multicore architectures[J].IEEE Transactions on Parallel and Distributed Systems,2011,22(2):309-322
[13] Wang Guohui,Wu Michael,Sun Yang.A massively parallel implementation of QC-LDPC decoder on GPU[C]//Walid Najjar.2011 IEEE 9th Symposium on Application Specific Processors.San Diego,CA,USA:IEEE Computer Society,2011:82-85
[14] Ji Hyunwoo,Cho Junho,Sung Wonyong.Memory access optimized implementation of cyclic and quasi-cyclic LDPC codes on a GPGPU [J].Journal of Signal Processing Systems,2010,64(1):149-159
[15] CCSDS 131.1-O-2 Low density parity check codes for use in near-earth and deep space applications[S]
