电网设备错误参数的支路量测标幺值残差代数和均值辨识法
2013-10-17赵雪骞李世明
颜 伟,赵雪骞,陈 俊,李世明
(重庆大学 输配电装备及系统安全与新技术国家重点实验室,重庆 400030)
0 引言
电网设备参数的准确性是各种电网分析计算的基础。实际工程中,由于缺少实测参数而直接采用设计参数、线路改建和运行环境变化、运行年久等原因,容易导致设备参数的使用值存在误差甚至错误。而电网参数错误会严重影响电网分析计算结果的可信度[1-7]。因此,有效辨识电网参数的错误十分必要。
现有参数辨识方法主要基于多个设备的电网关联量测方程[8-13]。如何解决其中的参数与参数之间、参数与量测信息之间的误差甚至错误影响,是这类方法需要解决的一个关键问题。近年来,有学者提出了基于单个设备多时段量测残差均值的参数辨识方法[14],该方法可以避免不同设备之间参数与量测误差的相互影响,同时可以通过多时段样本均值来减小正态分布量测误差的影响,从而有望获得更高的参数辨识精度。类似的均值方法还被应用于参数估计中[15-16],同样取得了良好的估计精度。
理论上,均值辨识方法在消除随机量测误差影响方面具有明显优势,但文献[14]在构造均值辨识判据和确定均值样本数方面存在明显问题,从而严重影响了错误参数的辨识效果。为此,本文在充分论证均值判据的基础上,提出了支路量测标幺值残差代数和均值指标(指标T)及在此基础上的错误辨识法。该方法首先建立单一设备同一时段的综合标幺值残差指标,然后以方差系数为收敛条件,求取多时段综合残差代数和均值的绝对值(指标T),最后根据综合残差均值的大小来辨识设备的错误参数。仿真结果验证了此方法的有效性。
1 指标D的问题及指标T的构造思路
1.1 指标D及其存在的问题
文献[14]基于支路(线路和双绕组变压器)参数及其多时段量测信息,建立了支路量测相对值残差平方和均值指标(指标D),其具体公式如下:

在计算指标D时,文献[14]要求支路至少有一侧配置有PMU,相应地xi,j为PMU量测相量计算得到的估计值。
文献[14]将支路多时段的D值作为参数辨识依据。具体仿真时,先设定一个门槛值Dmin,当D的计算值大于Dmin时则表示该支路参数存在错误。
由式(1)可知,指标D存在如下缺陷。
a.指标D采用平方和形式,不仅不能消除具有正负对称分布的正态分布随机量测误差,而且还有误差叠加的放大作用。当参数误差较大而量测误差较小或者量测误差较大而参数误差较小时,指标D的残差平方和结果可能都一样,因此,无法根据指标D的大小来区分参数和量测错误。
b.指标D采用相对残差形式,当量测状态的估计值 x2,i较小时,即使绝对残差并不大,其相对残差的数值可能非常大,因此,指标D门槛值的有效性很难保证。
c.样本数n的取值没有依据,n取不同的值,D值可能有较大差别,因此,指标D样本数的有效性很难保证。
1.2 指标T的构造思路
为了克服指标D存在的缺点,本文构造了一个新的参数辨识指标——多时段综合标幺值残差代数和均值的绝对值,称为指标T,其具体公式如下:

其中,线路和双绕组变压器对应的xi,j和下标i的定义同指标D。对于三绕组变压器,i取值1、2、3分别对应高、中、低压三侧,xBi,j为变量 xi,j所对应的基准值,xi,j定义可类比线路和双绕组变压器。对于线路和双绕组变压器A={2},对于三绕组变压器A={1,2,3}。其他变量定义同 1.1 节。
相对指标D的平方和形式,指标T采用代数和形式,由此可抵消对称的正负量测误差;相对指标D以量测估计值x2,i为基准,指标T采用标幺值基准xBi,j,由此解决了指标D门槛值选择困难和难以区分参数与量测错误的问题。
2 线路、双绕组变压器和三绕组变压器错误参数辨识的指标T
本文采用的输电线路、双绕组变压器和三绕组变压器等值模型,分别如图1—3所示。

图1 π型等值输电线路模型Fig.1 Equivalent circuit of π-type transmission line

图2 等值双绕组变压器模型Fig.2 Equivalent circuit of double-winding transformer

图3 三绕组变压器等值模型Fig.3 Equivalent circuit of three-winding transformer
2.1 基于PMU量测的指标T
根据1.2节的指标T构造思路,可以得到基于PMU量测的线路、双绕组变压器和三绕组变压器的指标 T,分别为 TL、T2T和 T3T:

其中,Re(·)和 Im(·)分别表示取实部和虚部。
2.2 基于SCADA量测的指标T
类似2.1节方式,可以得到基于SCADA量测的线路和变压器的指标T,具体如下:

3 支路量测标幺值残差代数和的均值计算方法
为了解决样本数的合理选择问题,本文借鉴了蒙特卡洛仿真的随机模拟思想。在蒙特卡洛仿真中,一方面必须能够模拟随机事件,以实现样本的随机抽样;另一方面还要保证随机抽样的样本足够多,使其能够充分代表随机事件的随机特征。后者通常采用样本的方差系数作为评估判据[16]。当方差系数足够小时,新增的随机样本对样本均值及其方差的影响很小,则认为随机抽样的样本数满足要求。
为此,本文采用支路量测标幺值残差代数和的方差系数判据η来确定均值计算的样本数。具体公式如下:
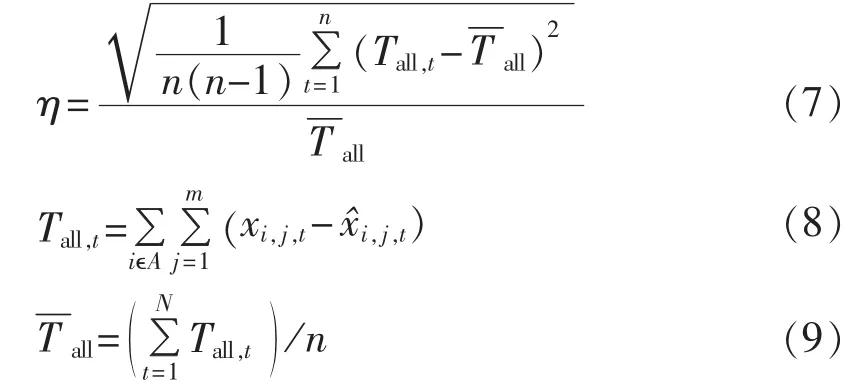
其中,Tall,t为t时刻对应的支路量测标幺值残差代数和;为 n 个时段 Tall,t的算数平均值;n 为 Tall,t总的计算次数,即样本数。
4 算例仿真与分析
4.1 算例基础数据
4.1.1 设备参数真值和参数误差设置方案
本文所用设备参数的真值如下:线路参数,R=1.2×10-3,X=1.65×10-2,B=0.838;双绕组变压器参数,R=6×10-4,X=2.3×10-2,k=1.025,Gm=1.9×10-3,Bm=1.39×10-2;三绕组变压器参数,R1=1.1×10-3,R2=4.55×10-4,R3=1.4×10-3,X1=8.04×10-2,X2=-7.1×10-3,X3=5.01×10-2,k1=1.087 5,k2=1.1,k3=1.05,Gm=9.65×10-4,Bm=1.17×10-3。其中,R、X 分别为电阻、电抗,Gm、Bm分别为变压器的励磁电导、电纳;变压器抽头级差为1.25%,且抽头在高压侧;其他变量定义同第2节。
由于电阻和励磁对潮流状态的影响很小,所以本文在参数辨识时没有考虑这2类参数的错误。在参数误差设置方案中,不设置参数误差或只设置1种参数误差,其余参数均为真值。具体设置方案如下:方案1,所有参数都没有误差;方案2,只有电抗有10%的误差;方案3,只有对地电纳有10%的误差;方案4/5/6,相应地只有三绕组变压器高/中/低压侧电抗有高压侧电抗大小的10%的误差;方案7,只有变压器变比有抽头最小级差的误差。
4.1.2 基础状态信息
4.1.3 量测数据的构造方法
设随机量测误差服从正态分布。根据文献[17]的PMU量测误差标准,电压和电流幅值的最大误差不大于0.5%,相角的最大误差不大于1°。本文取最大误差的1/3作为量测误差的标准差,并在此基础上通过误差传递方式确定SCADA量测的功率误差。
通过设备真值参数和4.1.2节的基础状态数据可推导出其他状态量,采集5 000组完备状态量数据并加入高斯白噪声则形成本文的仿真数据。
4.2 仿真结果分析
4.2.1 不同参数辨识方法的仿真结果比较
基于4.1.3节的PMU数据和4.1.1节的参数误差设置方案1—3,本文对比了基于2种指标的辨识方法的效果,具体结果如表1所示,其中,指标T的方差系数设为5×10-2,后同。由表1可得以下结论。

表1 线路指标D和T的效果比较Tab.1 Comparison of effect between line index D and T
a.对于不同的参数误差设置方案,指标T样本数不固定,由方差系数收敛判据自动确定。当采用方案1时,其需要762个样本,而采用方案3时,仅需121个样本。
b.参数有误差情况下的指标T与无误差时的差别较大,特别是当只有对地电纳B有10%误差时(方案3),T值为 1.55×10-1,是无参数误差对应 T值4.43×10-4的300多倍,辨识效果良好;而无论参数是否有误差,指标D的数量级均为10-2,难以辨识参数错误,这说明指标D采用的相对残差平方和的计算方法存在量测误差和参数误差混淆的问题,不能通过均值形式很好地消除量测误差的影响。
4.2.2 样本数对参数辨识效果的影响
基于4.1.3节的PMU数据和4.1.1节的参数误差设置方案1—3,采用随机选取样本数的方法(简称随机法),分别以样本数100和2 000计算指标T值,结果如表2所示。

表2 随机法对应的指标T值Tab.2 Index T of random approach
由表2可以看出,当样本数为100时,方案1对应的T值为4.80×10-3,方案3对应的T值为1.65×10-1,有2个数量级的跃变,可有效辨识出对地电纳错误。但方案2对应的T值仅为5.70×10-3,和无参数误差时的指标T十分接近,电抗参数错误辨识失败。而当选择较多样本数2 000时,其辨识效果同自动确定样本数的方法(简称自动法,结果见表1)类似,并未对其有明显改善。
由此可得,当随机确定样本数时,样本数过少则可能导致辨识失败,而过多则并不能使其相对自动法有所改善,反而需要提取更多的量测数据,增加计算时间。所以以方差系数作为收敛判据,根据数据和参数误差的不同自动确定样本数是必要的。
4.2.3 不同参数误差对辨识效果的影响
对于不同设备,采用不同的参数误差设置方案,利用方差系数收敛判据自动确定样本数,计算得到基于PMU和SCADA的指标T如表3—5所示。

表3 基于指标T的线路参数辨识方法的仿真结果Tab.3 Simulative results of line parameter identification based on index T

表4 基于指标T的双绕组变压器参数辨识方法的仿真结果Tab.4 Simulative results of double-winding transformer parameter identification based on index T

表5 基于指标T的三绕组变压器参数辨识方法的仿真结果Tab.5 Simulative results of three-winding transformer parameter identification based on index T
由表3—5可以看出,无论是基于PMU量测还是SCADA量测,当参数没有误差时,指标T是一个极小的值,数量级为10-5或10-4,而当参数存在错误时,T有多个数量级的放大。如基于SCADA数据的三绕组变压器,当无参数误差时,T为1.47×10-5,当变比有1.25%错误时(方案7),T达到了2.42×10-2,变为无参数误差时的将近2000倍。变化最小的情况出现在基于PMU数据的线路指标T计算中,当仅有电抗存在10%误差时(方案2),T值为3.90×10-3,是无参数误差的T值4.43×10-4的将近10倍,依然可以有效辨识参数错误。
由此可得,本文所提出的支路量测标幺值残差代数和均值辨识法对于不同设备的不同参数错误均能有效辨识出来。
另外,在仿真过程中发现,辨识效果的规律为:以电抗或电纳参数10%的误差、变比1.25%的误差为边界,当参数误差大于此边界时,T在数值上会更大,变化更加显著。而当电抗或电纳参数的误差小于此边界时,辨识效果会随着参数误差的减小而变差,甚至不能辨识。由于变压器的最小档差为1.25%,所以不存在变比误差小于1.25%的情况,故对于任何变压器变比错误都能很好地辨识出来。
5 结论
本文提出了基于单一设备多时段PMU或SCADA量测,以方差系数作为收敛判据的支路量测标幺值残差代数和均值参数辨识法。该方法具有以下特点:
a.采用标幺值残差而不是相对残差,避免了指标D数值上的不稳定问题;
b.采用残差代数和均值而不是平方和均值,可以有效消除随机量测误差的影响,实现错误参数的有效辨识;
c.方差系数收敛条件的使用,使得该方法能够自动确定样本数,保证了均值计算的稳定性,提高了辨识方法的鲁棒性;
d.相对指标D辨识方法,指标T辨识方法不仅具有更高的辨识精度,而且具有更广阔的适用范围。
