基于种子词汇的话题标签抽取研究
2013-10-15寇宛秋
寇宛秋,李 芳
(上海交通大学 计算机科学与工程系,上海200240)
1 引言
当今社会已经进入信息大爆炸的时代,信息量以几何级别速度不断增加。据调查显示,《纽约时报》一周的信息量相当于17世纪学者毕生所能接触到的信息量的总和。伴随着信息爆炸的是信息匮乏,海量的信息鱼龙混杂,收集信息所花费的成本已经超过了信息本身的价值。如何获取有价值的信息,已经成为信息爆炸时代极为重要的议题。
话题模型被普遍用来解决这个问题。话题通常被表示成词项的概率分布,话题模型通过对文档集进行降维,将词项空间中的文档变换到话题空间,模拟文档的生成过程。在话题模型中,一个话题用一组关键词来表示,有些话题有一个明确的语义信息,例如,“房价”、“住房”、“土地”、“市场、“上涨”,有些话题没有,例如,“网友”、“创意”、“得意”、“广电总局”、“影像”。因此,在实际应用中,需要一个标签来表示话题的语义信息。相对于单个词项,短语能够表示较完整的语义信息,如何从话题模型中得到更具解释性的短语描述,作为话题的标签是本文研究的目的。
本文的组织结构如下:第2节主要介绍相关工作,第3节是话题标签抽取方法的描述,第4节是实验结果和分析,第5节是结论和展望。
2 相关工作
话题模型应用最广的是LDA模型,是DAVID BLEI在2003年提出的[1]。之后很多研究者基于文档特点对LDA做了很多拓展,例如,Blei在2004年提出的Hierarchical LDA[2],将话题间的结构描述为树;Hidden Topic Markov Model(HTMM)[2]用句子的分布来表示话题;Author Topic Model(ATM)[3]在话题模型中引入作者信息,用以处理科技文献。
话题标签抽取研究可以分为四种方法,第一种是调整话题模型结果的权重,例如,Weighted Latent Dirichlet Allocation(WLDA)模型[4],在 LDA模型中,每个单词都被等同看待,而WLDA为每个单词赋予一个不同的权重。很多特征权重被用在该模 型 中,例 如,Pointwise Mutual Information(PMI),CHI测试,信息增益等。本文方法采用了WLDA的思路,利用权重公式对LDA建模结果进行权重调整处理。
第二种方法是采用短语为单元描述话题,传统话题模型采用单个词语作为话题关键词,而一些研究者用短语取代单个词语。例如,Multiword-Enhanced Author Topic Model[5],该模型根据词性标注信息抽取符合特定短语模式的短语,然后基于这些短语和单词构建话题模型。本文方法采用这一思想,用短语取代单词表示话题。
第三种方法是在话题结果中引入语义信息,例如,POSLDA 模 型[6],该 模 型 是 LDA 模 型 和HMMLDA模型[7]的扩展,该模型将文档中的词项分为三个类别,形容词、动词和名词,可以表示话题涉及的事物、动作和描述信息。
第四种方法是对LDA生成的话题结果进行组合处理,例如,Turbo Topic[8],该方法基于 LDA 的结果抽取可能的短语。算法步骤如下:
(1)对文档进行LDA建模,得到文档-话题分布,词项-话题分布和每个单词所属话题的词对:
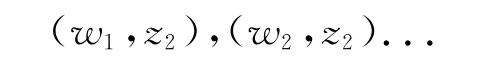
(2)对每一个单词,判断该单词周围的单词是否和该单词属于同样的话题,如果属于,则这两个单词可能组成一个短语,再根据似然估计,判断它们是否可以组成短语,如果可以,则加入到短语集合中;
(3)重复步骤(2),直到找不出新的短语。
本文综合了以上几种方法,引入了特征权重、词性分析、短语表示等因素,产生话题的标签,有效提高了话题模型结果的可解释性。
3 方法介绍
话题标签信息是话题内容的概括与总结,能够综合地反映话题内容,增强话题的可解释性。表1展示了LDA建模生成的话题信息和采用本文方法抽取的话题标签信息。

表1 话题信息与对应的话题标签
表2为本文使用到的主要符号和定义。
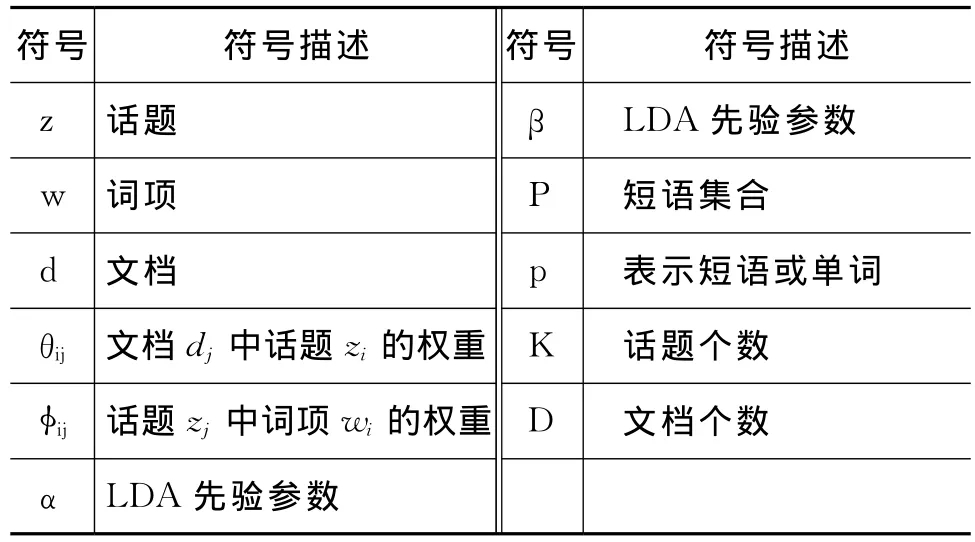
表2 话题标签抽取研究涉及的符号
话题标签抽取方法主要包括四个步骤:话题建模,种子词抽取,关键短语抽取和话题标签选择。话题建模是利用LDA模型对输入的文本集合进行建模,种子词抽取是对LDA话题结果进行重排序,选择权重最大的前三个词作为种子词,关键短语生成是根据种子词和其他词汇出现次数等信息生成短语,话题标签选择是从这些短语中选择最终话题标签。
3.1 种子词抽取
根据文献[9]提出的LDA结果重排序方法,根据下面公式对LDA结果,调整话题词项的权重,进行重排序。

TF-IDF被广泛用于评估词项在文档中的重要性。词项在文档中出现的次数越多,包含该词项的文档数目越少,就越重要。wi在话题zj中的重要性权重计算如式(1)所示。

(b)话题覆盖度
用于计算一个话题在文档集合上的覆盖程度,覆盖度高的话题中词项的权重更大。话题覆盖度用一个话题在所有文档中的概率之和除以总文档数来表示(如式(2)所示)。
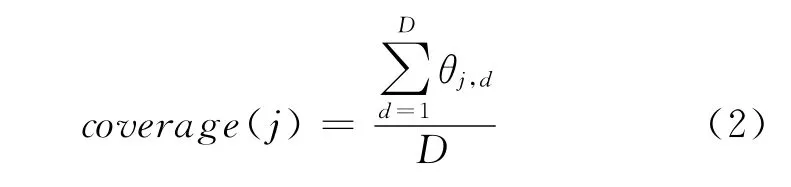
(c)PMI
PMI统计概率分布中两个变量的相关性,公式如式(3)所示。

词汇wi与同一话题(top-10)中其他9个词汇越相关,则该词汇的权重越高,某一词汇的关联度计算用PMI的平均值。
因此,结合 TF-IDF,覆盖度以及和PMI,权重计算公式如式(4)所示。
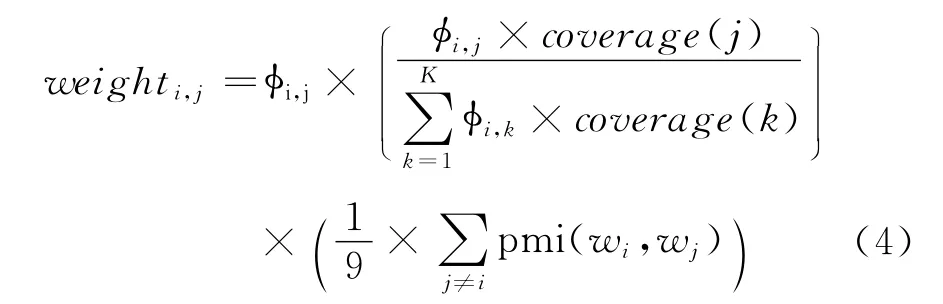
根据式(4),对每个话题前十个单词进行权重重排序,选出前三个单词作为关键短语抽取的种子词。
3.2 关键短语集合生成
初始关键短语集合等于种子词集合,运用bootstrapping算法迭代生成短语,当短语的权重大于阈值,则加入到关键短语集合中。用Wseed表示种子词集合,用P表示关键短语集合(初始阶段等于Wseed),用 WLDA表示LDA话题前十个词。短语(p1,p2)同时满足下述条件,则为关键短语:
(1)p1,p2是属于P∪WLDA中的任意短语或单词
(2)p1,p2中至少有一个属于P
(3)(p1,p2)的权重大于阈值
算法1描述了关键短语生成的过程。

算法1 话题关键短语生成算法
3.3 话题标签选择
在抽取出关键短语后,需要从关键短语集合中最终选出解释性强的短语作为话题标签。本文提出两种标准选择话题标签:短语的完整性和泛化度。
3.3.1 短语完整性标准
湖州市推动绿色矿业发展的实践与展望(龚西征) ........................................................................................9-13
根据实验结果,有些权重最高的关键短语缺乏关键信息,例如,关键短语“卡恩涉嫌”、“同比增长”、“中方支持”。这些短语在语义上并不完整,“卡恩涉嫌”缺少宾语,“同比增长”缺少主语,“中方支持”缺少宾语。大部分不完整的短语均是动词性短语。因此,短语完整性规则如下:如果关键短语集合中权重最高的短语是动词词组,而且缺少主语或宾语,则按照完整性规则,在关键短语集合中重新选择。
判断以及选择方法如下:
假设关键短语集合P中权重最高的短语为pmax,那么有以下两种情况。
(1)如果该短语第一个词为动词,或者第一个动词前没有名词,则判定短语pmax缺乏主语;
(2)如果该短语最后一个词为动词或者最后一个动词后面没有名词,则判定pmax缺乏宾语。
对于判定缺乏主语或宾语的短语pmax,在关键短语集合P中,按权重从高到低的顺序搜索满足如下条件的短语p,作为最后的标签:
(1)p包含短语pmax;
(2)p中含有主语(动词前的名词)或宾语(动词后的名词)。
实验发现了另一种现象,即权重最高的关键短语只是描述话题特定的方面,例如,“治理北京大气污染”,而其他的关键短语为“大气污染”“大气污染防治”,更好的描述短语是“大气污染”。这类短语一般是名词性短语,为了解决这种问题,本文引入概念泛化规则:关键短语集合中权重最高的短语,如果是名词短语,则根据该集合中其他词汇进行泛化,选择关键短语最大的公共子串作为该话题的标签。
具体步骤如下:
计算关键短语集合P中短语p的泛化度。
(a)对于同时满足条件i和条件ii的短语p,按照式(5)计算泛化度
i.短语p属于P中权重最高的三个短语或者权重前三的短语包含p;
ii.P中至少存在两个包含p的短语

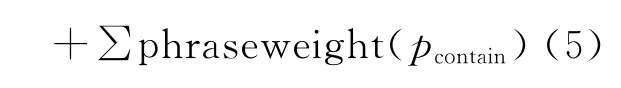
(b)对于不满足(a)中条件的短语p,按照式(6)计算泛化度。话题标签根据如下规则得出:
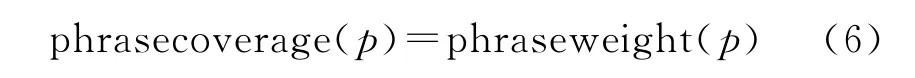

4 实验结果分析
4.1 实验语料
实验共选取了两个语料集进行测试:2013年两会新闻数据集和在2009至2013年发生的新闻事件集合。先预处理,分词并抽取名词动词形容词,去掉单个字以及高频低频词,然后用LDA对其进行建模。实验设置参数α==0.01,其中K为话题数目。我们采取了一套自适应的话题数目计算方法,根据新闻文本数目以及信息量随时间的变化趋势确定话题数目[9]。表3是不同事件对应的新闻数目、词汇数目、话题数目等信息,按照话题数目从小到大的顺序展示。
4.2 实验结果展示
话题标签抽取方法对新闻语料进行处理,主要包括三个步骤:种子词抽取;关键短语集合生成;话题标签选择。表4和表5分别展示了事件语料话题标签抽取实验和两会语料话题标签抽取实验各步骤的结果。
实验结果显示,种子词抽取方法能够有效去除话题背景词,抽取相关的重要词汇。例如,台湾领导人选举话题2,话题关键词中有很多背景词,例如,“台湾”“马英九”等,根据3.1节提出的权重公式计算后,降低了背景词的权重,提高了“两岸关系”等词汇的权重,更能反映话题的语义信息。
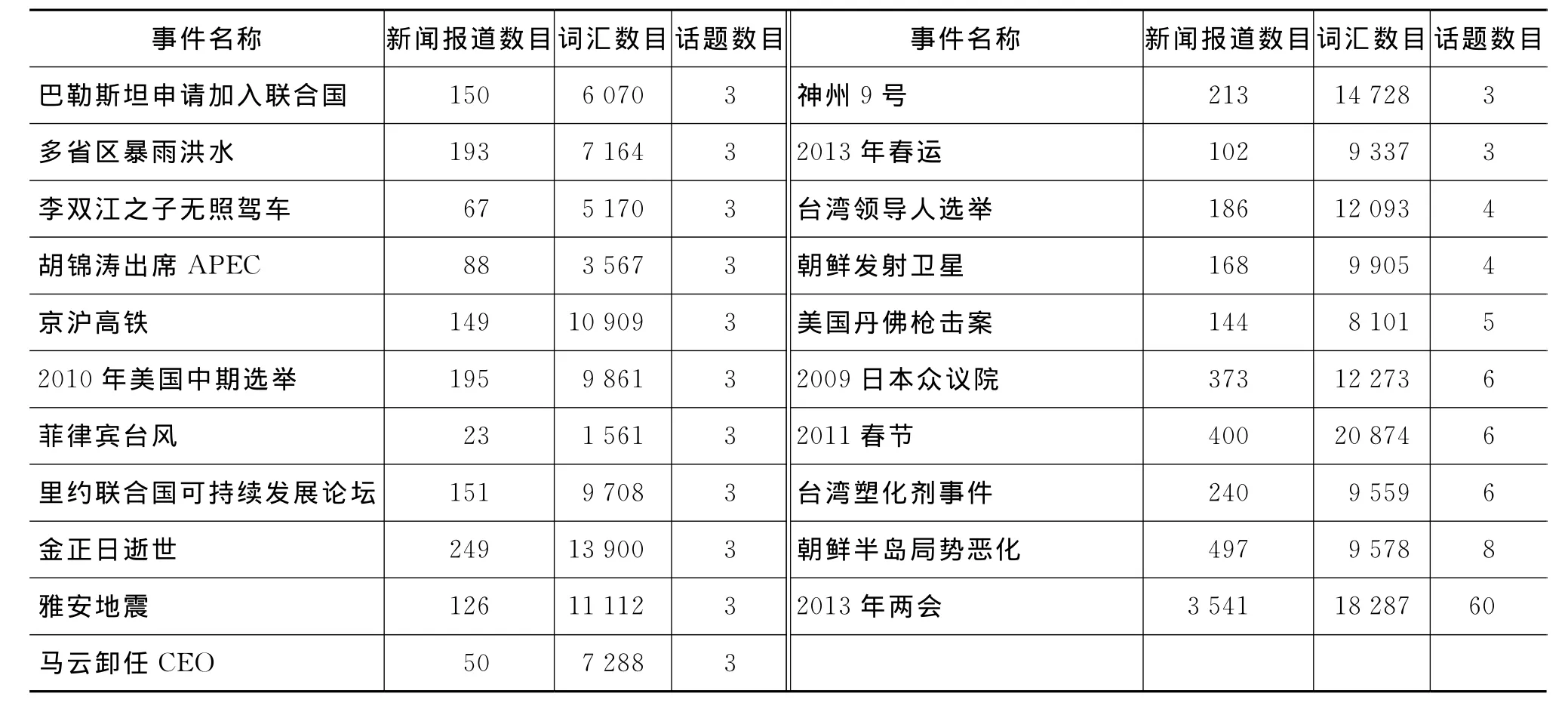
表3 实验语料说明

表4 事件语料话题标签抽取结果
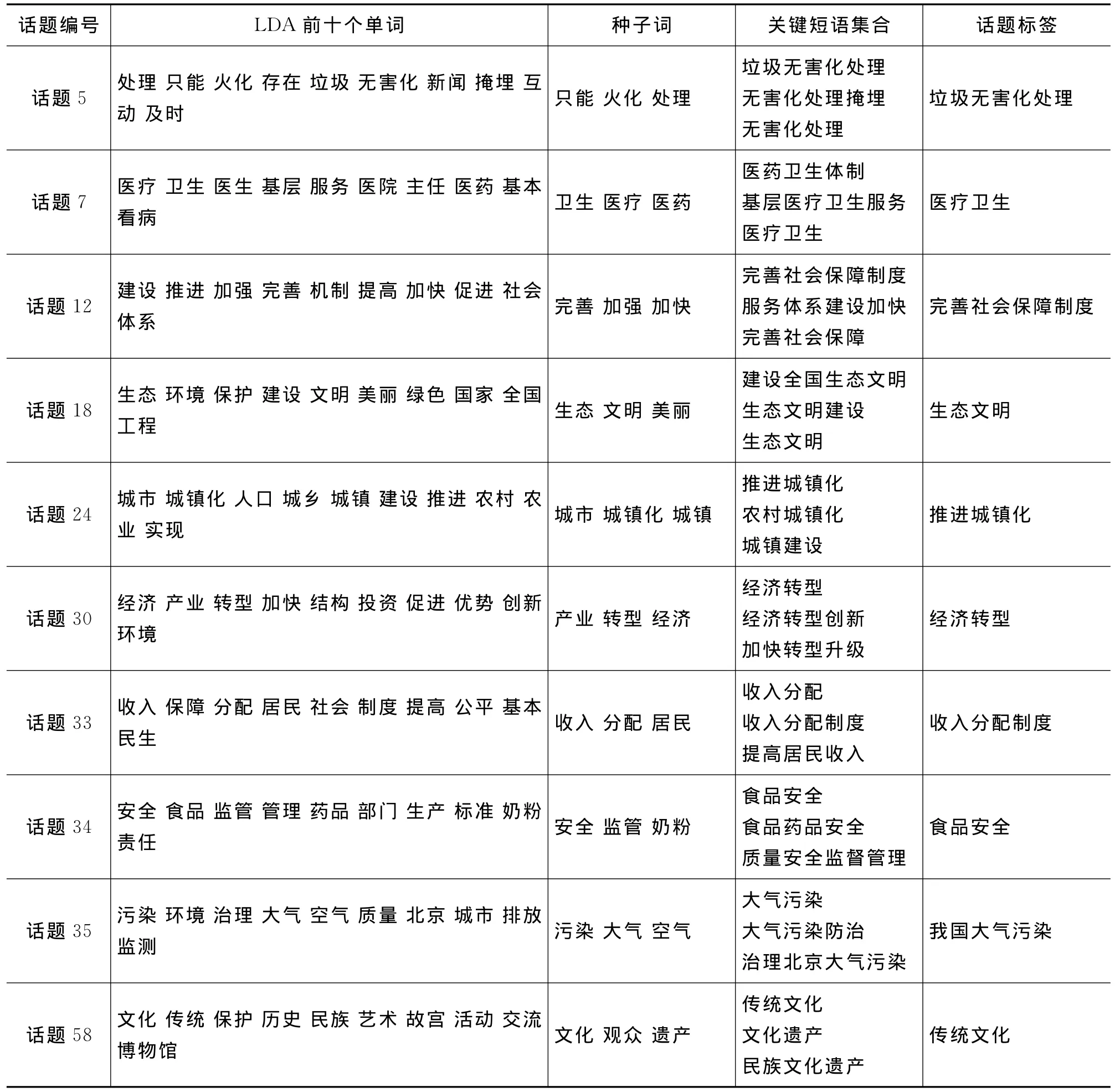
表5 两会语料话题标签抽取结果
关键短语生成步骤可以产生有效的话题关键短语,例如台湾领导人选举事件中能够生成和事件有关的“台湾领导人选举”、“台湾领导人”等短语;2011年春节事件中能够生成“回家过年”、“燃放烟花”等短语;两会事件话题58中能够生成和文化领域相关的“传统文化”、“文化遗产”等。
根据完整性和泛化规则选择的标签可以给出话题特定的语言信息,例如,2011春节话题4,“接待游客同比增长”而不是缺乏主语的“同比增长”。另一方面,台湾领导人话题2“两岸关系”作为标签,“两岸关系”的泛化程度比“两岸和平”高;例如,两会话题30,话题标签“经济转型”更能概括话题关键短语的信息。
4.3 话题标签实验评测
4.3.1 精度评测
人工评测话题的标签是否符合话题的语义。评测需要的数据是话题标签以及该话题所占权重最大的文档标题。评测者根据新闻题目人工总结出关键短语,并和自动抽取的话题标签进行比较,语义相关的判定话题标签正确,评分为1,部分相关的评分0.5,不相关的为0。例如,人工总结的短语是“两岸和平”,计算机抽取的是“两岸关系”,则该标签的精度为0.5;例如,人工总结的短语是“救援情况”,计算机抽取的标签是“登陆美国”,则该标签的精度是0。
本文实验中有两位评测者对全部语料进行评测。计算出的精度如表6所示。结果显示,话题标签抽取方法在两会语料的精度可以达到39.5%,在事件语料上的精度可以达到27.9%。
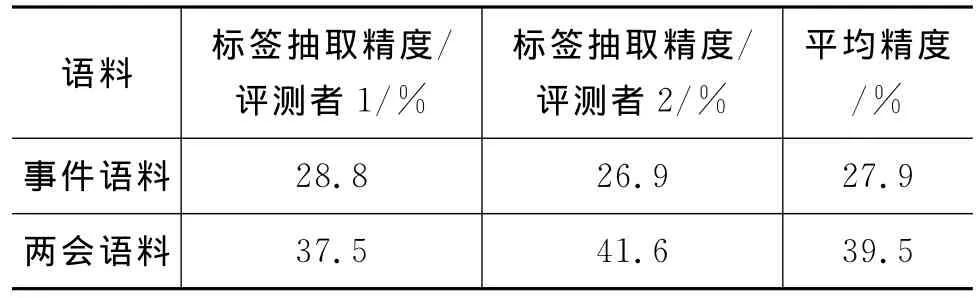
表6 实验评测结果
根据实验评测结果,可以得到如下结论。
(a)话题标签抽取方法能较好的总结话题内容,所抽取的标签短语由话题关键词组成,能够表示特定的语义信息。
(b)两会语料的精度要高于事件语料,主要因为两会语料讨论的是话题,有一些固定的主题,例如,“国防军事”“教育”“住房问题”等,两会语料中抽取的话题标签往往由名词性短语组成。而事件的话题信息比较特定,包括与事件有关的信息,事件语料中抽取的话题标签有很多包含动词短语,反映事件特定的信息。
线索标签抽取方法存在不足,最主要是精度较低,这是因为本文提出的关键短语作为话题标签,短语更能反映话题的语义信息,但人工评测时,短语比词汇更容易错误。另一方面,不同人对同一类文档总结的标签也不相同,很难得出一个正确的答案。表7展示了部分错误的话题标签。
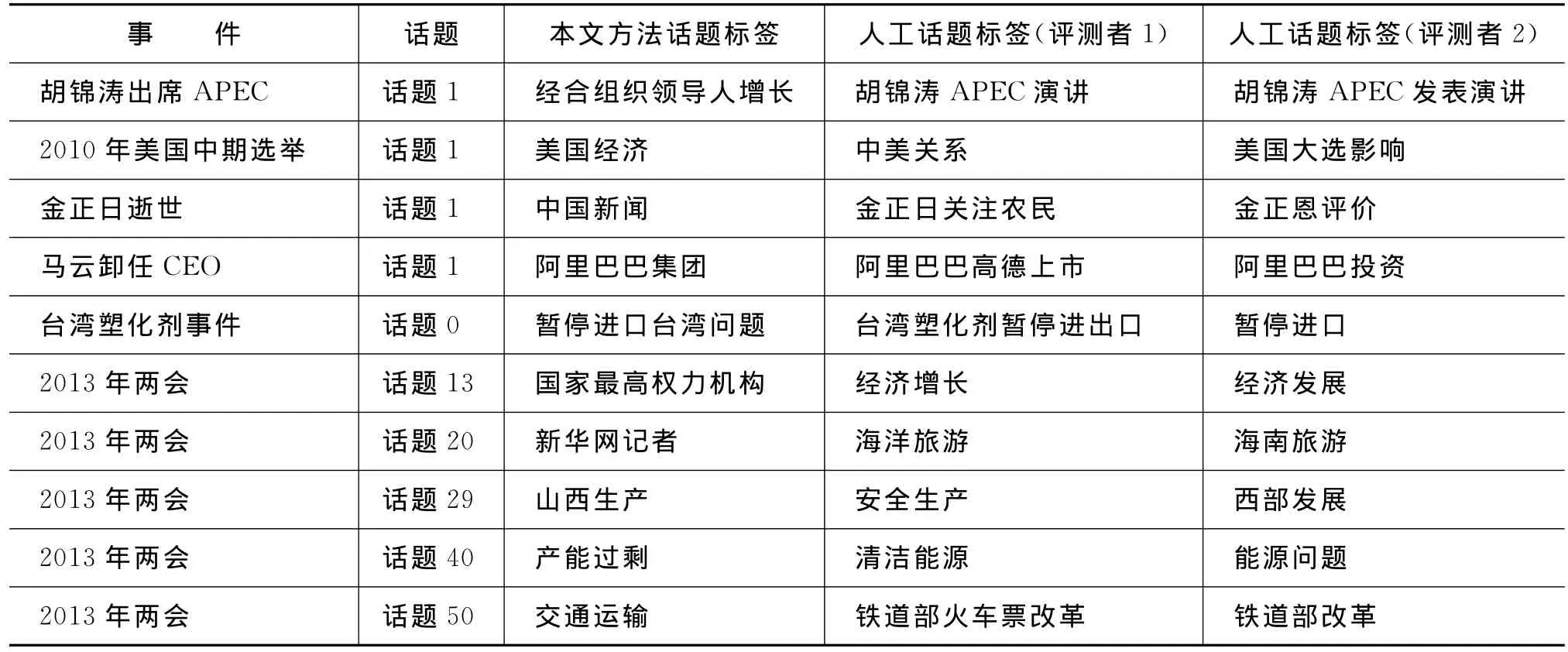
表7 错误结果分析
从错误结果可以看出(表7),错误原因包括以下几个方面。
(1)部分LDA话题结果语义不明确,例如,两会话题20,话题关键词为“旅游”、“新华网”、“全国”、“江苏”、“建设”、“市长”、“人大代表”、“老百姓”、“记者”、“游客”,并不具有明显的语义信息。生成的关键短语只有“新华网记者”。
(2)对动词词组的处理不完善,例如,事件“2011年春节”话题3,关键短语为“回家过年”、“拜年方式”、“过年回家”,方法判定“回家过年”缺乏宾语,判定错误。方法在判断包含动词的短语和动词性短语的关系上有所欠缺。
(3)部分短语泛化性偏高或偏低。例如,事件“马云卸任CEO”,抽取的标签为“阿里巴巴集团”,过于概括,不能表示具体的话题信息。例如两会事件话题29抽取的标签为“山西生产”,过于具体。方法在选择适中的泛化度上有待提升。
4.3.2 对比实验
本文方法同文献[9]中提出的方法进行了比较,均根据LDA话题结果生成话题标签短语,如表8所示。
实验结果可以看出,本文的方法得到的短语能够表示特定的语义信息,例如两会话题33,文献[9]标签为“收入”,而本文选择了“社区养老服务”,语义上更为完整;例如,台湾领导人选举话题2,本文标签为“两岸关系”比文献[9]“两岸和平”更泛化和确切。本文方法部分实验结果不如文献[9]中方法,例如,台湾领导人选举话题0,本文标签“台湾地区”泛化度偏高,不如文献[9]“台湾地区领导人选举”。

表8 对比实验结果
根据同样的标准答案,表9是两种方法精度的对比结果。可以看出本文方法的精度要高于文献[9],在两会语料中提高精度12%,在事件语料上提高精度4%。说明短语的完整性以及泛化度考虑方法的合理性。

表9 对比评测结果
5 结论和展望
本文提出了一种基于种子词的话题标签抽取方法。方法首先根据提出的权重计算公式抽取每个话题的种子词,然后,采用bootstrapping思想,迭代产生包含种子词汇的关键短语集合,最后根据短语的完整性和泛化度选择话题标签。
本文对新闻事件语料和两会报告语料进行了实验,结果表明本文方法能够有效地抽取出话题标签,相对于文献[9]中的方法,本文抽取的短语完整性和概括性更高。本文主要的贡献是:将种子词抽取与bootstrapping方法引入到话题标签抽取的研究中;利用词性标注与短语结构信息抽取话题标签;根据短语的完整性和泛化原则,抽取表达力更强的标签短语。
本文的方法还存在很多不足之处,后续工作包括以下三个方面:研究题目信息与话题之间的关系;使用更有效的LDA结果重排序公式;将话题标签抽取工作融合进话题模型中,以短语为基本词汇单元,同时引入词性标注信息等信息。
[1]Blei David,Ng Andrew,Jordan Michael.Latent Dirichlet Allocation[J].The Journal of Machine Learning Research,2003,3:993-1022.
[2]徐戈,王厚峰.自然语言处理中主题模型的发展,计算机学报[J],2011,34(8):1423-1436.
[3]Rosen-Zvi M,Griffiths T,Steyvers M,et al.The author-topic model for authors and documents[C]//Proceedings of the 20th conference on uncertainty in artificial intelligence.AUAI Press,2004:487-494.
[4]Ruifeng XU,Lu YE.Reader's Emotion Prediction Based on Weighted Latent Dirichlet Allocation and Multi-label k-nearest Neighbor Model[J].Journal of Computational Information System,2013,9:6.
[5]Johri N,Roth D,Tu Y.Experts'retrieval with multiword-enhanced author topic model.Proceedings of the NAACL HLT 2010workshop on semantic search[C]//Proceedings of Association for Computational Linguistics,2010:10-18.
[6]William Darling,Fei Song.Probabilistic Topic and Syntax Modeling with Part-of-Speech LDA[C]//Proceedings of Association for Computational Linguistics.2005.
[7]Griffiths T L,Steyvers M,Blei D M,et al.Integrating topics and syntax[J].Advances in neural information processing systems,2005,17:537-544.
[8]Allison J.B.Chaney,David M.Blei.Visualizing Topic Models[C]//Proceedings of Association for the Advancement of Artificial Intelligence.2012.
[9]闫泽华.基于LDA的新闻线索抽取研究[D].上海交通大学硕士论文,2012.
[10]Teh Y W,Jordan M I,Beal M J,et al.Hierarchical dirichlet processes[J].Journal of the American Statistical Association,2006,101(476).
[11]Blei D M,Lafferty J D.Visualizing topics with multiword expressions[J].arXiv preprint arXiv:0907.1013,2009.
[12]Wallach H M.Topic modeling:beyond bag-of-words[C]//Proceedings of the 23rd international conference on Machine learning.ACM,2006:977-984.
[13]Wang X,McCallum A,Wei X.Topical n-grams:Phrase and topic discovery,with an application to information retrieval[C]//Proceedings of Data Mining.ICDM 2007.Seventh IEEE International Conference on.IEEE,2007:697-702.
[14]Nallapati R,Feng A,Peng F,et al.Event threading within news topics[C]//Proceedings of the thirteenth ACM international conference on Information and knowledge management.ACM,2004:446-453.
[15]Lau J H,Newman D,Karimi S,et al.Best topic word selection for topic labelling[C]//Proceedings of the 23rd International Conference on Computational Linguistics:Posters.Association for Computational Linguistics,2010:605-613.
[16]Carmel D,Roitman H,Zwerdling N.Enhancing cluster labeling using wikipedia[C]//Proceedings of the 32nd international ACM SIGIR conference on Research and development in information retrieval.ACM,2009:139-146.
[17]Song Y,Pan S,Liu S,et al.Topic and keyword reranking for LDA-based topic modeling[C]//Proceedings of the 18th ACM conference on Information and knowledge management.ACM,2009:1757-1760.
