融合音节特征的最大熵藏文词性标注研究
2013-10-15于洪志李亚超冷本扎西
于洪志,李亚超,汪 昆,冷本扎西
(1.西北民族大学 中国民族语言文字信息技术重点实验室,甘肃 兰州730030;2.中国科学院自动化研究所 模式识别国家重点实验室,北京100190)
1 引言
词性标注是根据词语的上下文信息,判定词语词性的过程,是自然语言处理中一项非常重要的基础性工作,被广泛应用于机器翻译、语音识别、信息检索等领域[1]。近几十年来研究者开展了基于隐马尔科夫(Hidden Markov Model,HMM),支持向量机(Support Vector Machine,SVM),最大熵(Maximum Entropy,ME),条件随机场(Conditional Random Fields,CRF)等模型的词性标注研究。最大熵模型能够融合复杂的特征,在英语、汉语等语言词性标注研究中取得了较好的效果,并在形态变化较多的蒙古文词性标注中得到成功运用[2]。
汉语、英语等语言的词性标注研究较为成熟,标注准确度基本达到了可以实用的程度。已有词性标注方法可以分为基于规则方法和基于统计方法。基于规则方法提出时间较早,基本思想为按照兼类词搭配关系和上下文语境构建词类消歧规则[3]。随着标注语料规模的增大,以人工方式提取规则的方法耗费大量的人力、物力,并且词性标注系统在不同领域、不同语言之间的可移植性较弱,这是基于规则词性标注方法的主要不足之处。基于统计的词性标注方法适合处理大规模语料,并且可移植性很强,成为汉语、英语等语言词性标注研究的主流方法,同时也取得了不错的效果。
藏文词性标注研究基础薄弱,陈玉忠[4]在汉藏科技机器翻译系统的研制中,首次对藏文词语进行了分类。苏俊峰[5]研究了基于HMM的藏文词性标记方法,该系统封闭测试正确率达到88%~90%。羊毛卓么[6]采用HMM模型实现了一个藏文词性标注系统,该系统对开放语料词性标记正确率达到89.56%。由于藏文词性标注语料规模有限及藏语语言本身的复杂性,已有公开的藏文词性标注准确度在89%左右,并且都是在私有语料上取得的测试结果。从公开的实验结果来看,其标注效果远低于汉语、英语等语言的词性标注效果,所以藏文词性标注研究任重道远。
本文提出一种融合藏文形态特征的最大熵藏文词性标注模型,根据藏文构词特征,定义上下文特征模板,并融合了上下文音节特征。实验结果表明,最大熵模型能够较好的处理藏文词性标注问题,音节特征能够有效的提高藏文词性标注效果,与基准系统相比使错误率降低了6.4%。
论文的其余部分结构安排如下:第2节阐述最大熵模型及特征选择;第3节介绍本文所采用的藏文词性标注集;第4节给出实验数据,并进行实验结果分析;最后第5节为总结与展望。
2 最大熵模型
最大熵模型最初由E T Jaynes在1950年提出,Della Pietra等[7]将其应用于自然语言处理中。最大熵原理的基本思想是,首先利用给定的训练样本,选择一个与训练样本一致的概率分布,它必须要满足所有已知的事实。在没有更多的约束和假设的情况下,对于那些不确定的部分,则会赋予均匀的概率分布。熵是用来表示随机变量的不确定性,不确定性越大,熵越大,分布越均匀。最大熵模型如式(1)所示。

H(P)是模型P的熵,C是满足条件约束的模型集合,下面需要寻求P*,P*的形式如式(2)所示。

Z(x)是归一化常数,表示形式如式(3)所示。λi为特征的权重参数。

2.1 特征选择依据
使用最大熵模型对藏文进行词性标注,即根据当前词x的上下文特征,确定当前词的词类y,最重要的是确定合适的特征集合。
(1)常规特征,一个词的词性由其上下文环境决定,因此当前词的前后n个词可以作为判断当前词词性的依据。
(2)藏文构词特点,藏文属于拼音文字,是一种形态丰富的语言,其语言范畴是以内部屈折形式来表现的,如通过词缀及附加词缀的交替来表现动词的现在、将来、过去时和命令式,构成自动词和使动词的对立等[8]。出现形态变化的往往是动词、名词等实词,而数词和虚词一般是没有变化的。因此,在藏文词性标注中上下文词和当前词的形态特征都是很重要的可以利用的信息。
2.2 特征模板定义
根据对藏文构词特征和统计结果分析,本文共进行了词内部特征,前后依存词特征以及混合特征的藏文词性标注实验。
2.2.1 词内部特征
词内部特征表现一个词内部的变化,包括词根信息和词缀信息。以藏文动词为例,藏文动词的屈折形态可以分为两类,同根类型和异根类型[9]。
同根类型指动词屈折变化的各个形式属于同一个词根,绝大多数屈折变化的动词属于这一种形态。如,雕刻)”词根是异根类型指的是屈折变化的各个形式不属于同一词根,这样的动词占所有动词的比例很少,但是对一部分不规则动词识别具有重要的意义。
词根不一定出现在词首,很可能会出现在词中的其他位置,例如,bcags-chags,行、走)”的词根是“ ,cag(chag)”。因此,藏文词汇的词首、词尾音节对于判断藏文词汇的词类起着重要的作用。词首音节特征函数定义为:

词汇词尾音节特征函数定义为:

词内部信息特征模板如表1所示。

表1 词内部特征
2.2.2 前后依存词特征
前后依存词特征表示藏文句子中与当前词紧密联系的词之间的关系,前后依存词的相关信息可以在一定程度上解决兼类词问题。例如,句1它是支撑着所有知识的根基,充当着所有语言的元素”,句2实践一切所学的知识)”中,知识、学习)”在句1中为名词,表示“知识”之义,在句2中为动词,表示“学习”之义。本文采用的前后依存词特征如表2所示。

表2 前后依存词信息特征模板
2.2.3 混合信息特征
根据藏文词汇的形态变化以及构词特征,将当前词的词首音节、词尾音节,前、后词,前驱词的词尾音节、后继词的词首音节等特征混合在一起,定义混合信息特征如表3所示。

表3 混合信息特征模板
3 藏文词性标注集
藏文词性标注集没有一个统一的规范,西藏大学、青海师范大学、西北民族大学均有自己的相关标注规范。本文采用西北民族大学中国民族信息技术研究院祁坤钰教授的藏文词性标注集。该标注集在参照了《信息处理用现代汉语词类标记规范》的基础上,根据藏语语法特点增加了一部分类别,共21个大类,61个子类,由于语料规模限制本文只进行大类实验。

表4 藏文词性标注集
4 实验及分析
4.1 实验准备
本文采用的藏语文小学课本标注语料,由中国民族信息技术研究院组织标注,语料统计如表5所示。
由于藏文词性标注语料严重缺乏,已有的词性标注语料数量较少,且覆盖度差,语料的选择会影响实验效果。为此,本文的测试语料从整体语料中随机抽取。表6为训练、测试语料的详细统计信息,可以看出,训练集和测试集中词性分布基本相同,说明本文实验中训练语料和测试语料较好的代表了藏文词类分布特点。其中,名词、动词、介词、标点符号、助词等出现的比例较大。

表5 语料统计

表6 语料详细统计
经过统计,在测试语料中未登录词主要是名词、动词和数词,所占比例分别为74%、8%、8%。
本文采用标注准确度对标注结果进行评价,标注准确度定义如式(4)所示:

4.2 实验设置及结果分析
在本文实验中,采用张乐最大熵工具包①http://homepages.inf.ed.ac.uk/lzhang10/maxent_toolkit.html和CRF++(v0.51)②http://crfpp.googlecode.com/svn/trunk/doc/index.html实现最大熵模型和条件随机场模型。根据第2节的分析,我们采用不同的特征进行如下实验,以下实验均采用表2所示的前后词依存信息,不同的是音节特征,实验设置及实验结果见表7,其中表2所示的词依存特征在下文中用T1表示。

表7 实验结果
实验1采用传统的词依存特征,取得90.32%的准确度,为本文的基准系统。实验2加入当前词词首、尾音节特征后取得了90.89%的准确度。相比实验1准确度提高了0.57%,错误率降低了5.9%,说明音节特征对提高基于最大熵的藏文词性标注效果有较大的帮助。
实验3、4、5加入了当前词词首、尾音节及前、后词的音节等混合特征,其中实验4取得了最好的实验结果,实验3和实验5的实验结果低于实验2,说明在混合特征中当前词词首、尾音节与后继词词首音节的混合特征可以提高基于音节特征的藏文词性标注结果。
实验4加入当前词词首、尾音节和后继词的词首音节特征,取得了最好的实验结果,比实验1的实验结果提高了0.62%,错误率降低了6.4%。
为了对比最大熵与条件随机场的实验效果,在下文中,采用条件随机场、最大熵的词性标注结果分别表示为CRF、ME,采用的特征见表2,实验结果如表8所示。
从表8实验结果来看,基于ME的实验结果优于基于CRF的实验结果,比基于CRF的词性标注实验结果高了约0.5%。虽然最大熵模型存在标记偏置(label bias)问题[10],而条件随机场模型不存在这个问题,但是从本文的实验结果来看,基于 ME的藏文词性标记实验结果较好。

表8 词性标注对比实验
从实验结果来看,标点符号、介词标注结果较好,并且在各个模型之间实验结果很稳定。标点符号和介词是封闭类(the close class),这类词的数量比较固定,因此在实验中标注效果较好。
终结词是较为具有藏文特点的词类,添加在一句话的末尾,表示语义上的结束。在藏文中一共有11个终结词,是封闭类,但是可以当作兼类词。从实验结果来看,ME可以完全标注出来,而CRF对其识别效果不太好。
名词、动词是开放的类,开放类的识别效果直接影响整体识别结果。从对比实验结果可以看出来,CRF和ME对名词识别效果较好,CRF对动词识别效果较好。
4.3 词性标注错误分析
表9是基于最大熵的藏文词性标注错误详细分析,其中动词、名词、形容词和数词的标注错误占了所有标注错误的很大比例。主要错误为,形容词标注成了名词、数词和动词;数词标注成了名词和助词;动词标注成了名词和助词;名词主要标注成形容词,并且名词可以标注成连词、副词、终结词、方位词等。在表9中,以第一行为例,a表示当前词是形容词,比例为9%,表示在所有的标注错误中,形容词标注错误占了9%的比例,错误原因中“72%n;11%m;11%d”表示在名词标注错误中72%把a标注为n,11%把a标注为m,其余表示方法如上所示。
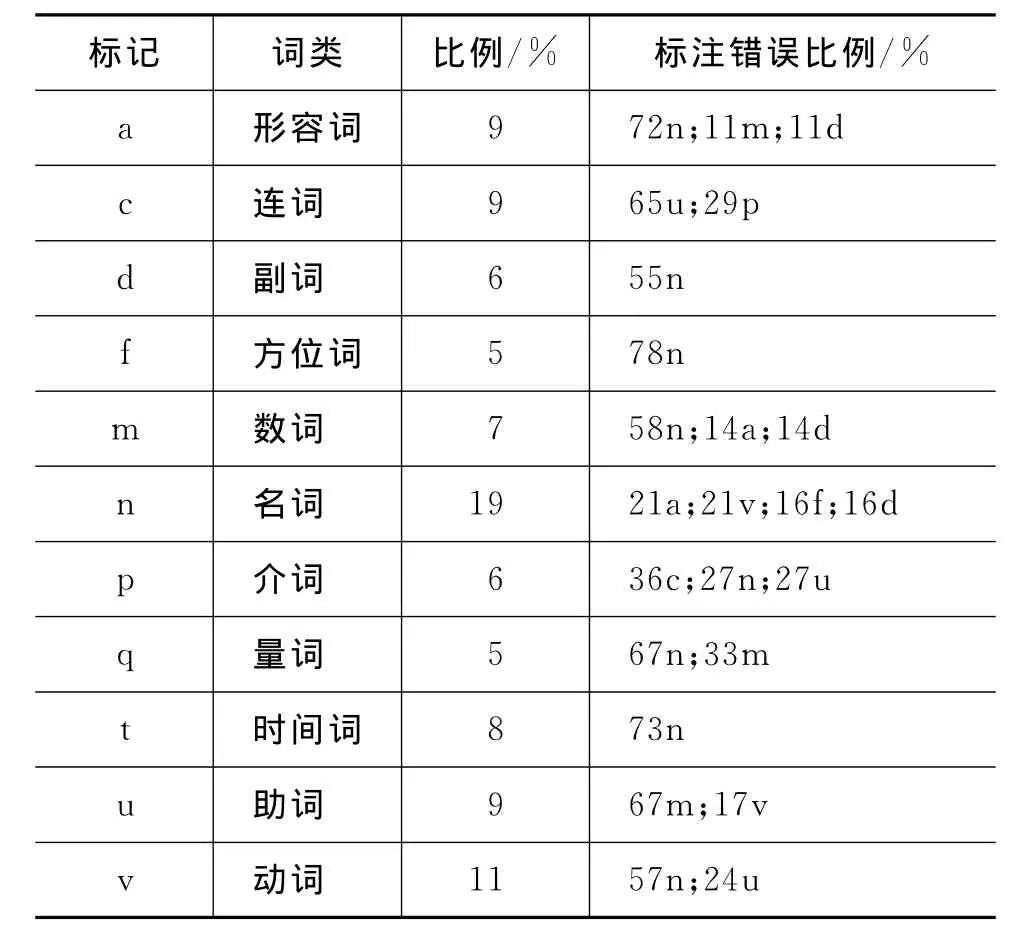
表9 ME标注错误
5 总结与展望
本文介绍了融合音节特征的最大熵藏文词性标注的研究工作,重点在于特征选择上,根据藏文的形态特征,选取当前词词首、尾音节和前驱词词尾音节,后继词词首音节等混合形态特征信息,构建了藏文词性标注系统。实验结果表明最大熵可以为藏文这种丰富形态特征语言的词性标注提供一个有效的模型,来建模上下文信息,音节特征可以显著提高藏文词性标注准确度,在本文实验中取得了90.94%的准确度,与基准系统相比准确度提高了0.62%,错误率降低了6.4%。由于本文实验所使用语料规模有限,词性标注的整体效果有待进一步提高。
在下一步工作中,我们希望更加深入的研究藏文词汇的内部结构特征,对特征模板集进行改进,通过对标注结果的错误分析,进一步修正特征模板的定义,最终提高藏文词性标注结果。
[1]宗成庆.统计自然语言处理[M].清华大学出版社,2008.
[2]张贯虹,斯·劳格劳,乌达巴拉.融合形态特征的最大熵蒙古文词性标注模型[J].计算机研究与发展,2011,48(12):2385-2390.
[3]刘开瑛.中文文本自动分词和标注[M].商务印书馆,2000.
[4]陈玉忠,俞士汶.藏文信息处理技术的研究现状与展望[J].中国藏学,2003,04:97-107.
[5]苏俊峰.基于HMM的藏语语料库词性自动标注研究[D].西北民族大学硕士学位论文,2010.
[6]羊毛卓么.藏文词性自动标注系统的研究与实现[D].西藏大学硕士学位论文,2012.
[7]Adam L Berger,Stephen A DellaPietra,Vincent J Della Pietra.A Maximum Entropy Approach to Natural Language Processing[J].Computational Linguistics,1996,1(22):39-71.
[8]宋金兰.藏语形态变体的分化[J].民族语文,2001,1:29-33.
[9]瞿霭堂.藏语动词屈折形态的结构及其演变[J].民族语文,1985,1:1-15.
[10]J Lafferty,A McCallum,F Pereira.Conditional Random Fields:Probabilistic Models for Segmenting and Labeling Sequence Data[C]//Proceedings of ICML-2001,2001:282-289.
