基于布尔矩阵Apriori算法的改进研究
2013-09-17汪浩,吴静
汪 浩, 吴 静
(西南科技大学 信息工程学院,四川 绵阳 621010)
0 引言
关联规则是数据挖掘中的一个重要问题。Agrawal与 Srikant[1]于 1994年提出的 Apriori算法是数据挖掘中提取频繁项集之间关联规则的一种经典算法。该算法采用频繁项集的反单调性压缩搜索空间,实现了频繁项集的快速提取。但存在一些难以克服的性能瓶颈:①多次扫描数据库,需要很大的 I/O负载;②可能产生庞大的候选集。基于布尔矩阵的 Apriori算法是将事务数据库映射到布尔矩阵中,整个挖掘过程只扫描一次事务数据库,大大降低了 I/O负载,但仍需要产生大量候选集。本算法在研究基于布尔矩阵的 Apriori算法的基础上提出了一种改进的算法 PMApriori,先将事务数据库映射到布尔矩阵上,然后根据相关性质对布尔矩阵的行列进行修剪,最后直接生成频繁项集。不需要进行连接和减枝步骤,不需要生成候选项集,提高了算法效率。
1 关联规则基本概念
现介绍关联规则挖掘中的一些基本概念与知识[2]:

关联规则挖掘问题一般可以分为两个子问题[4]:①找出事务数据库中所有大于等于指定的最小支持度(minSup)的频繁项集;②根据频繁项集与用户设定的最小置信度得到关联规则。
对于第二个子问题的实现相对较为容易,因此,目前大量的研究工作都集中在第一个子问题上,它是关联规则挖掘算法中的核心问题。
2 基于布尔矩阵的Apriori算法
算法思想[5-6]:只扫描数据库一次,此算法将事务数据库映射成一个布尔矩阵,矩阵中行代表事务,列代表数据项,通过逐行扫描相应的列就能得到项的频度。详细描述如下:
首先将事务数据库初始化为布尔矩阵。扫描事务数据库D,假设数据库D中有m个事务,n个数据项。令:fDM→即事务数据库D映射成的布尔矩阵M为其中
图1表示一个事务数据库D及经过初始化之后映射成的布尔矩阵M。然后依次计算矩阵M各列的列向量之和即可
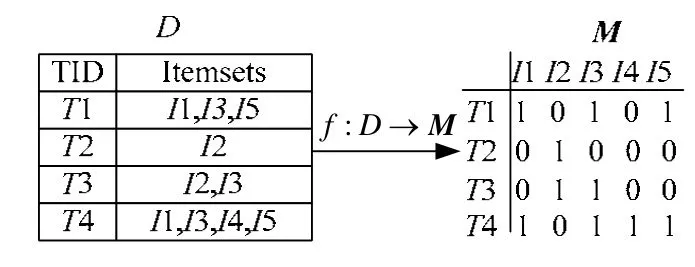
图1 事务数据库D及初始化后的布尔矩阵M
得1-项集{Ii}的频度,对于其值小于最小支持度的项集予以删除,生成频繁1-项集1L。再通过1L自连接产生候选2-项集C2,若要得到2-项集{Ii,Ij}的频度,只需对矩阵M的第i列和第j列进行按位“与操作”,结果中1的个数即为所求项集频度。同理,要得到k-项集的频度,只需对矩阵的第1,2,…,k列进行按位“与操作”。最后生成频繁k-项集Lk,直到候选k-项集kC=Ø则算法终止。假设最小支持度minSup=2,算法执行过程如图2所示。
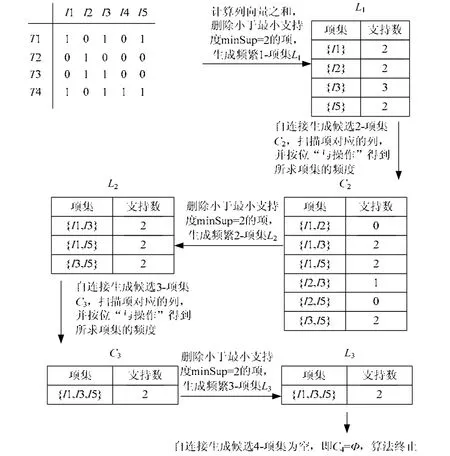
图2 基于矩阵的Apriori算法流程示例
由图2可知,算法在求得频繁项集kL时,仍需要频繁项集1kL-进行自连接,将产生大量的候选项集Ck。故针对此算法的不足,提出优化算法PMApriori。
3 PMApriori算法
3.1 主要性质
性质1:若布尔矩阵中,列向量中1的个数小于最小支持度,则可删除此列。
证明:根据频繁项集的反单调性[7],即频繁项集的所有非空子集必然也是频繁的。列向量中1的个数表示此项的出现次数,若此列向量中1的个数小于最小支持度,则说明此列表示的项为非频繁项集,与产生频繁项集无关,故可删除。
性质2:若布尔矩阵中,行向量中1的个数小于k,则可删除此行。
证明:行向量中1的个数表示此次事务中包含的项数,在求频繁k-项集时,当行向量中1的个数小于k时,说明此事务项中包含的项小于k,与产生频繁k-项集无关[8],故可删除。
3.2 基本步骤
基本步骤如下:
1) 扫描事务数据库D,将事务数据库映射成布尔矩阵,并对布尔矩阵中的行向量和列向量中1的个数分别计数。
2) 由性质1可知,当列向量中1的个数小于最小支持度 minSup时,该项目列为非频繁项集,与产生频繁 2-项集无关,可删除该项目列,若大于等于最小支持度,则保留。
3) 由性质2可知,当行向量中1的个数小于k时,此行事务项与产生频繁 k-项集无关,也可删除,故删除行向量计数小于k的事务项,保留1的个数大于等于k的事务项。
4) 在求k(k≥2)维项集的频度时,扫描布尔矩阵对应的列,求 k-项集{I1,I2,…,Ik}的频度,只需对矩阵的第1,2,…,k列向量进行按位“与操作”,然后对向量运算后的结果中的 1计数,如果大于等于最小支持度minSup,则为频繁k-项集的子集。扫描完布尔矩阵,保留下来得子集则为所求频繁k-项集。
5) 重复步骤 2~3,不停的压缩矩阵,一方面可以降低矩阵的大小,另一方面可以提高算法的运行效率。然后再执行步骤4, 直到kL为空, 算法终止。
3.3 示例说明
假设最小支持度 minSup=2,使用图 1中所示的事务数据库及映射后的布尔矩阵,对矩阵的行列向量进行计数先得到频繁项集1L,然后对矩阵进行修剪压缩,接着扫描修剪后的矩阵,挖掘出频繁项集Lk,算法执行过程如图3所示。
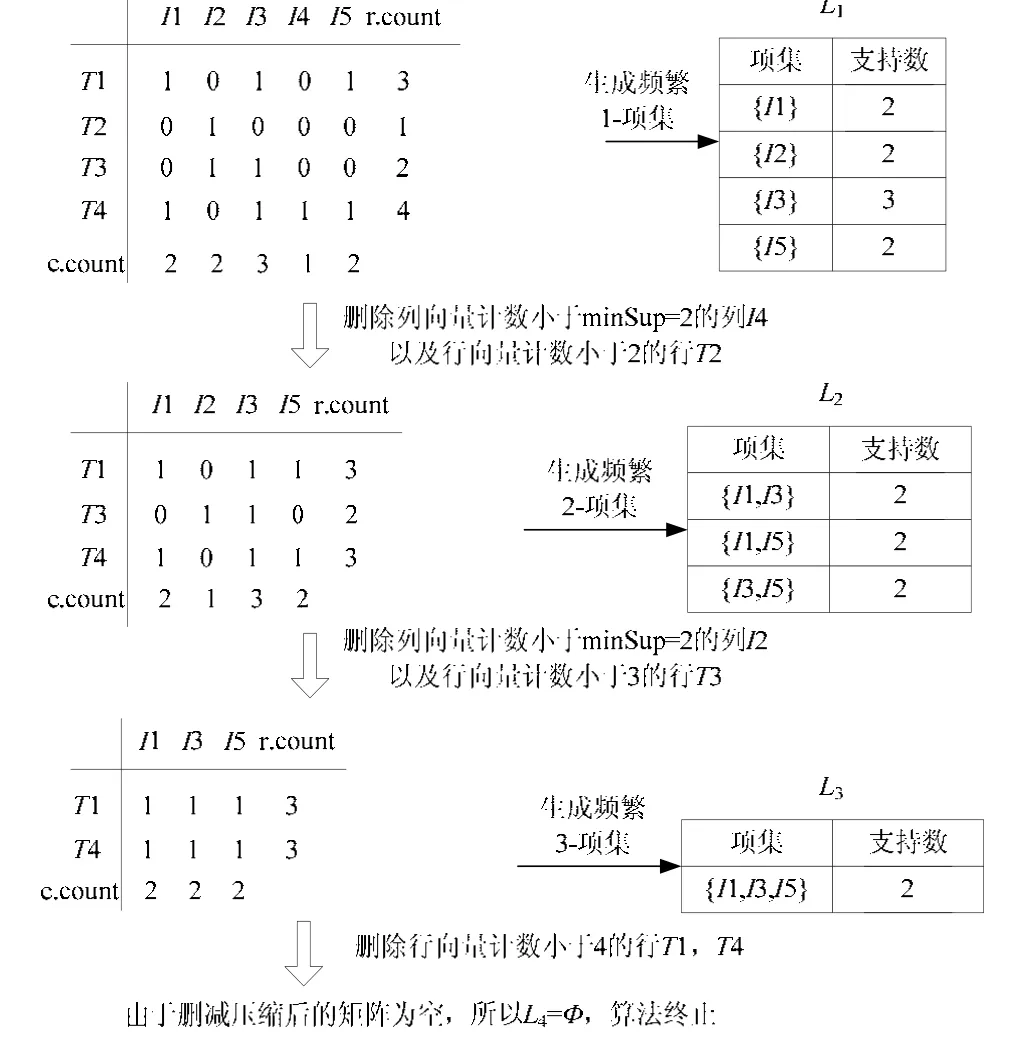
图3 PMApriori算法流程示例
3.4 性能分析
为了验证 PMApriori算法的效率,将基于布尔矩阵的 Apriori算法与 PMApriori算法在相同的实验环境下经行比较测试,验证算法所用的实验硬件环境为:处理器为 Intel(R)Core(TM)2 Duo CPU T550,主频1.83 GHz, 内存2 G,硬盘容量160 G,操作系统 Windows 7 旗舰版,系统类型 32位。两种算法均采用 Visual C++语言实现,测试数据库为SQL Server 2005所自有的 foodmart.mdb数据库,挖掘样本为对 dbo.sales_fact_1997表中数据预处理过的事务数据表,所含事务数据分别选取 1 000条、2 000条、3 000条、4 000条、5 000条。设定最小支持度为20%,实验结果如图4所示。
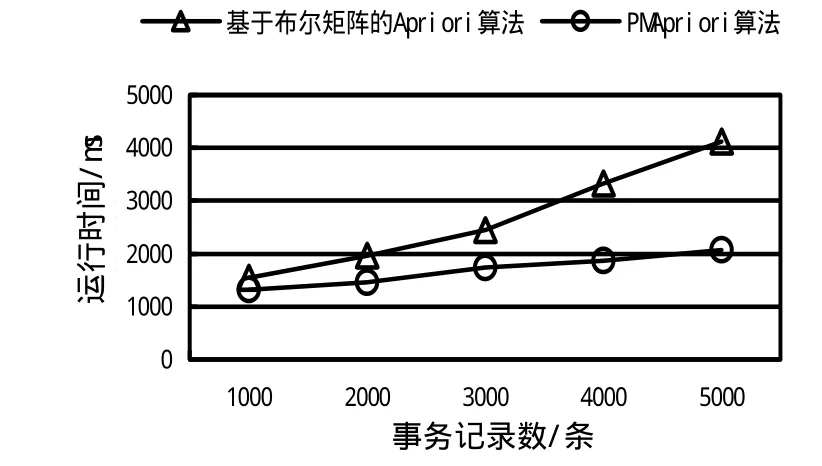
图4 记录数不同时算法性能对比
由图 4可知,在相同数据集的前提下,PMApriori算法运行效率始终优于基于布尔矩阵的Apriori算法。PMApriori算法与基于布尔矩阵的Apriori算法相比,运行时间增长趋势更加平缓,说明在针对大型数据库进行数据挖掘时,算法运行效率更加显著。算法的运行时间与算法执行过程有着紧密的关系,PMApriori算法在时间特性和空间特性上有显著优势,原因在于产生频繁项集前对存储数据的矩阵进行有效的修剪压缩,而且不用产生候选集,降低了内存开销;不需要经行自连接、测试等操作,然后直接生成频繁项集,有效地提高了算法的运行效率。
4 结语
关联规则挖掘作为数据挖掘领域中的重点研究内容,其受重视程度也将日益彰显。为了提高关联规则挖掘算法中频繁项集的生成效率,在基于布尔矩阵的Apriori算法的基础上提出了一种新的改进算法 PMApriori算法,并且与基于布尔矩阵的 Apriori算法做了性能对比分析,PMApriori算法性能更加优越,此算法只需扫描一次数据库,降低了 I/O开销;能对矩阵的进行有效的修剪压缩,且不需要生成大量候选集,减小内存空间的消耗;对项集计数只需扫描矩阵中的部分数据,提高了算法执行效率。通过实验结果可知,PMApriori算法能有效而又快速地从事务数据库中提取频繁项集,表现出了良好的性能。由于实验数据的局限性,算法在海量数据挖掘的效率还没有验证,需要进一步深入研究。
[1] AGRAWAL R, SRIKANT R. Fast Algorithms for Mining Association Rules[C].Santiago: Proceedings of the VLDB International Conference,1994:487-499.
[2] 朱明.数据挖掘[M].第 2版.合肥:中国科学技术大学出版社,2008:160-163.
[3] 肖冬荣,杨磊.基于遗传算法的关联规则数据挖掘[J].通信技术,2010,43(01):205-207.
[4] 张圣.一种基于云计算的关联规则 Apriori算法[J].通信技术,2011,44(06):141-143.
[5] 周文秀.关联规则挖掘算法的研究与改进[D].武汉:武汉理工大学,2008.
[6] 裴古英.一种基于布尔矩阵的关联规则快速挖掘算法[J].自动化与仪器仪表,2009,5(145):16-18.
[7] 郑岩. 数据仓库与数据挖掘原理及应用[M].北京:清华大学出版社,2011:168.
[8] 朱嘉杰,蔡伟.一种安全事件模糊关联规则挖掘算法[J].信息安全与通信保密,2010(04):63.
