基于SVM的CVE漏洞分类框架构造*
2013-09-11李宗寿
彭 华,李宗寿
(吉首大学信息科学与工程学院,湖南吉首 416000)
基于SVM的CVE漏洞分类框架构造*
彭 华,李宗寿
(吉首大学信息科学与工程学院,湖南吉首 416000)
针对CVE字典缺少分类和归纳能力,无法为多重系统漏洞设计有效防御策略的局限,提出了CVE分类器的CVE漏洞分类框架.该CVE分类器根据不同的分类特征对CVE进行分类,在支持向量机的帮助下,CVE分类器自动地从相关的漏洞数据库(包括BID,X-Force和Secunia)中抽取训练数据,并基于该训练数据为分类特征建立学习模型.
支持向量机(SVM);公共漏洞和暴露(CVE);分类特征
安全漏洞是在硬件、软件、协议的具体实现或系统安全策略上存在的缺陷,使攻击者能够在未授权的情况下访问或破坏系统.[1]CVE字典报告了安全漏洞每年显著的扩展,目前保存着30 648个漏洞信息[2].通过公开列举已知的漏洞并以合适的方式命名,多年以来CVE字典在促进安全信息交换、脆弱性分析方面发挥着重要作用,而现在主要为众多安全资源充当索引.然而,由于其缺少分类和归纳能力,在为多重漏洞设计防御策略时,该字典就无能为力了.尽管基于一定分类特征的漏洞分类框架已经存在,但由于其特征抽取和分类过程效率不高,使得它们很少被应用于现实世界的事件响应.为解决该问题并加强CVE字典在漏洞分析和预防入侵的作用,本文提出了一个称为CVE分类器的CVE漏洞分类框架.
通过使用机器学习和数据挖掘技术,本文提出的CVE漏洞分类框架将CVE字典从漏洞的枚举器转换成拥有分类和归纳能力的分类器.该框架将漏洞的分类作为1个监督学习问题,使用SVM为每个分类特征构造1个学习模型;并自动从漏洞数据库(主要来自BID,X-Force和Secunia)中为分类特征抽取训练数据以避免费时的手工操作.此外,本文还使用了词干法和停用词过滤技术来减少由CVE特征向量创建的特征空间的维度.
1 CVE分类框架的设计原理
CVE字典中所有条目使用相同的模板进行描述,该模板包括3个组成部分:基本信息(General),引用(Citation)和摘要(Summary),如表1所示,表1中列出了CVE-2004-0445和CVE-2007-2151的漏洞信息.
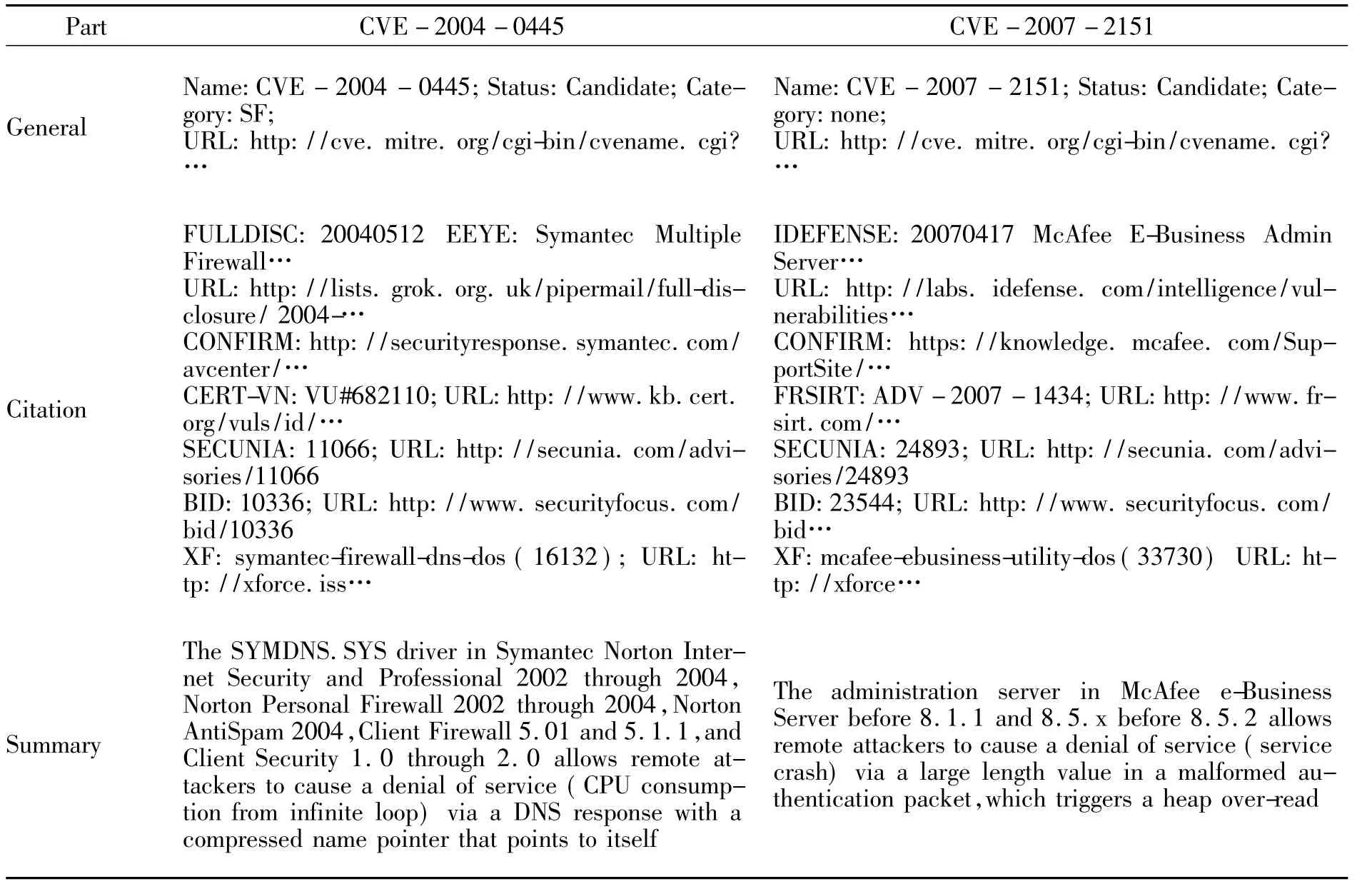
表1 CVE字典中CVE-2004-0445和CVE-2007-2151的漏洞
在基本信息部分中,每个CVE条目被赋予1个唯一标识符,其状态信息(candidate或standard)也可被跟踪.引用部分提供了与该漏洞相关的引用资源集,通常包括与该漏洞相关的安全报告网址和在不同漏洞数据库中的位置.由表1中可以看到这2个漏洞在BID,X-Force和Secunia中的引用.摘要部分则描述了该漏洞的概要信息,通常提供有漏洞的系统及安全漏洞被利用后的征兆等信息,从表1还可以很清晰地看到CVE字典很少提供分类特征(如:漏洞成因和影响)的信息,即使这些分类信息确实存在,也会因为其零散的文字描述使得信息很难抽取.
分类特征的存在使得针对成群的漏洞设计安全策略成为了可能.此外,根据分类特征将安全漏洞系统地分类进一个有组织的结构中,能够自动地对新出现的安全漏洞进行分类.显而易见,分类和归纳能力依赖于所选择的分类特征集合.
本文设计的框架能自动地集成存在于各种漏洞数据库(包括BID,X-Force和Secunia)中的分类特征.例如:从X-Force和Secunia中获得Vulnerability Impact的特征,从BID和Secunia中获得Exploitation Location的特征.对于每个分类特征,CVE分类器定义了其维度(例如:分类的个数),在此上下文中,该漏洞在漏洞的影响(Vulnerability Impact)和漏洞的严重性(Vulnerability Severity)的分类特征上分别有11,5个分类.若1个CVE条目同时属于多个分类,该分类特征是多元的,否则是一元的.在CVE分类器中,由于1个CVE条目存在多方面不好的影响,因此,Vulnerability Impact特征是多元的.例如:CVE-2004-0445可能导致DoS和非授权系统访问.另外,Vulnerability Severity特征是一元的,在该特征上,CVE-2004-0445被标记为极度严重,CVE-2007-2151被标记为较严重.
本框架以分类特征为基础对CVE漏洞进行分类的过程分为3个阶段:CVE描述;构造学习模型;无标记样例的分类.在第1阶段中,1个CVE的文本片段被转换成可用于机器学习的格式.即:文本中词的位置被忽略,每个CVE被当做1个词包,并且使用特征向量进一步描述,词包中的每个词将充当1个特征(或属性),该特征的值就是对应CVE条目中该词出现的次数.为减少由所有CVE特征向量构成的特征空间的维度(特征的数目),CVE分类器使用词干法将具有相同词干的词进行合并.停用词由于仅仅具有语法功能,如典型的冠词、助词、连词、代词、助动词、介词等,因此可以过滤停用词以便进一步减少特征空间的维度.通过正常化特征向量不但消除了CVE条目长度上的差异,而且让它们拥有了相同的单位长度.
在学习模型构建阶段,CVE分类器首先为每个特征自动地从漏洞数据库BID,X-Force和Secunia中搜集训练数据,然后建立SVM学习模型.每个CVE条目的极度简短的描述使得CVE特征向量是稀疏的,这也使得能够将SVM应用到此框架中.由于CVE文本通常是由领域专家书写的,不太可能包含有噪声的或多余的信息,因此SVM在框架中的应用也避免了复合特征选择的过程.数据过分拟合的SVM的鲁棒性和独立于特征空间维度的学习能力,也有助于CVE分类过程的简化和自动化.
最后阶段中,对不能包含在训练数据中的无标记CVE条目,由CVE分类器进行分类.对于1个多元特征,学习模型由多个相互区别的SVM二类分类器组成;对于1个一元特征,通常建立1个多类分类器.借助该学习模型,CVE字典中所有CVE漏洞根据分类特征系统地进行组织.例如,若顺序地根据1组分类特征(如Service Type、Vulnerability Cause、Exploitation Location)进行分类,则能建立1个漏洞层次结构.
2 基于SVM的CVE漏洞分类
2.1 构建CVE条目的特征向量
为将CVE条目转换成对应的结构化描述(适合于使用机器学习算法进行自动化的描述),CVE分类器首先将每个CVE条目摘要部分的文本作为1个token的序列,通过忽略文本中token的具体位置,该CVE条目被描述为1个词包.CVE的特征向量可表示为:每个不同的token作为一个特征,且某token的出现次数作为对应特征的值.CVE分类的特征空间由所有CVE的特征向量的集合构成,其维度是该学习任务计算复杂性的关键性决定因素.为减少特征空间的维度,本框架使用了信息检索中的Porter词干算法[3].具有相同词干根的token通过去除复数、过去分词和其他后缀来进行合并;得到的词干又进一步转换成对应的小写形式以便压缩特征空间.例如:词干法处理完后且被放入特征向量中之前,表1中CVE-2004-0445的token:security,firewall和cause,分别被转换成它们的词干secur,firewal和caus.CVE-2004-0445和CVE-2007-2151条目的词干法处理结果如表2的“Word Count”所示.

表2 CVE字典中CVE-2004-0445和CVE-2007-2151的特征向量
本框架为进一步减少特征空间的维度使用了停用词过滤过程.若某个token仅仅只有语法功能,在句子中没有增加新的语义,该token就被当作1个停用词.本框架中的停用词列表包含了418个token,大多数都是冠词、助词、连词、代词、助动词和介词.例如:在停用词过滤过程中,CVE-2004-0445中形如the、in和through这样的token将从其特征向量中移除.本框架将在整个CVE条目中出现次数超过某指定的阈值(默认为3)的词配置为候选特征.
为消除CVE条目长度的不一致,本框架对每个CVE特征向量正常化为单位长度,通过将CVE特征向量中每个属性的权重除以该向量的欧几里德长度来得到.
2.2 使用SVM进行CVE分类
对于1个给定的训练数据集T={,yi}(i=1,…,m),每个数据点(或样例)∈Rd具有d个特征和一个真标记yi∈Y={l1,…,lk}.监督学习任务是为了构建1个模型,该模型试图平衡T上的分类准确性和在不可见样例上的归纳能力.当模型赋予给某个样例的标记与其真标记冲突时,分类错误就发生了.SVM试图构建在随机选择样例上最小化分类错误上边界的模型[4],当标记集Y={l1=-1,l2=+1}时,该学习模型就是1个二类分类器,通过寻找分离超平面来区分数据点是属于正值类还是负值类.这样,从超平面到最近的正例和负例的最短路径的总和被最大化.分离超平面可以表示为+b=0,权重向量¯w∈Rd对于超平面是正常的,操作符(·)计算了向量和的内积,b是偏移量.1个SVM二类分类器的目标函数可以表示为最小化‖w‖2,其中,Cb是分类错误的惩罚参数,ξi(ξi≥0,i=1,…,m)为T中第i个样例的非负松弛变量;对于正例,¯w·¯xi+b≥+1-ξi;而对于负例+b≤-1+ξi.显然,参数Cb控制了训练错误和分类准确性间的平衡.
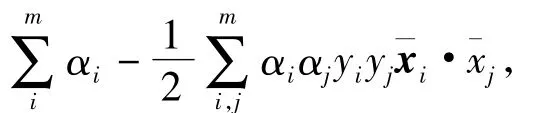
图1描述了Vulnerability Impact特征的gain system access分类的二元模型.正例(如CVE-2004-0445)以实心圆表示;负例(如CVE-2007-2151)以空心圆表示;数据点则充当支持向量,在图1中以额外的圆表示.例如:CVE-2004-0445和CVE-2007-2151就是支持向量并且各自存在于超平面Hpos:+b=1和Hneg:+b=-1上.显然,没有任何数据点落在Hpos和Hneg间,分离超平面与Hpos和Hneg的距离是相等的.无标记的CVE-2008-0005被图1的二类分类器赋予负值,因为它落在分离超平面的负的一边.
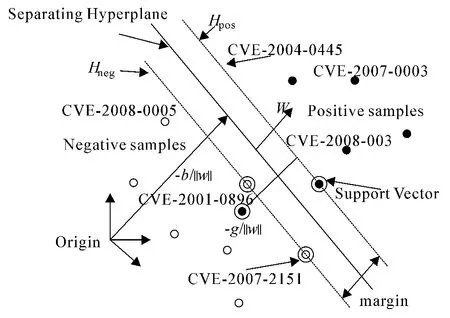
图1 不可分离训练数据集的超平面
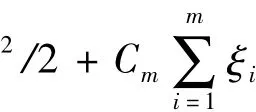
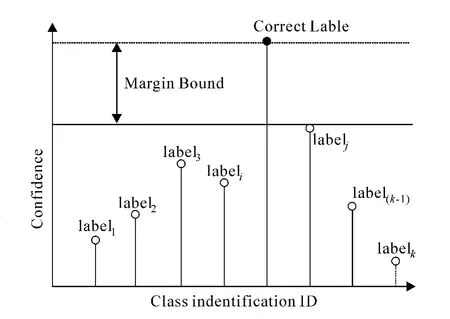
图2 多类模型下对样例的正确分类
图2描述了通过多类优化方法建立的学习模型,其中,带有不同标记的圆赋予到数据点上,带有Labeli圆的高度表示其信任度,该信任度由数据点¯x的特征向量和W的第i行的内积进行定义,正确的标记被绘制为1个实心圆.显而易见,图2的学习模型正确地对数据点进行分类.从目标函数的Wolfe对偶形式和1个SVM分类器的解决方案来看,能观察到数据点仅仅以内积的形式出现.通过指定1个映射函数Ф:Rd→H,能将训练数据的特征向量从空间Rd转换至拥有更高维度(可能无限)的空间H,这样,构建在空间H中的模型仅仅通过Ф(xi)Ф(xj)形式的函数依赖于数据点.使用核心函数K(xi,xj)=Ф(xi)Ф(xj)能在目标函数及其约束中用K(xi,xj)替换xi·xj;并通过使用K而不是Ф进行计算来建立空间H下的学习模型.同样,1个不可见样例的标记可以通过函数K而不是Ф,计算其特征向量和参数w的内积来获得.本框架中的核心函数可以是多项式函数,径向基函数或sigmoid函数[4].
3 分类特征的训练数据生成及SVM学习模型构造
3.1分类特征的训练数据生成
作为1个监督学习任务,为分类特征构建的学习模型要求训练数据以T={,yi}(i=1,…,m)形式进行表达.其中∈Rd是第i个数据点的特征向量;yi∈Y={l1,…,lk}是其真标记.显然,若是手动地搜集和标记T,将费时费力.因此,本框架通过使用每个CVE条目中的引用池(如:表1中CVE-2004-0445或CVE-2007-2151的引用部分)来自动产生训练数据.CVE中大量的引用为CVE分类器提供了搜集分类信息的丰富资源,另一方面,不同资源中私有的数据格式、冲突的分类模式以及不一致的特征含义使整个信息抽取过程复杂化了.考虑到特征数据的引用次数和质量,本框架主要使用漏洞数据库BID,X-Force和Secunia作为来源产生训练数据.
BID的条目使用模板来进行创建,该模板由4个部分组成:Info,Vulnerable,Discussion和Exploit,其中Info部分包含了问题中条目的唯一性标识和描述性标题,如表3所示.Vulnerable部分则列出了有漏洞的系统或产品,用“+”号来表示漏洞的主要贡献者,用“-”号表示次要的贡献者.与BID比较而言,Secunia漏洞数据库也通过一定的特征对安全漏洞进行分类,BID和Secunia在一些公共的分类特征(如:Exploitation Location)上对漏洞进行分类.同时,它们在其他的分类特征上是互补的,例如:Vulnerability Cause仅存在于BID,而Vulnerability Severity仅在Secunia出现.

表3 BID漏洞数据库中BID-10336和BID-23544条目

续表
3.2 构造SVM学习模型
在为分类特征搜集完训练数据后,就可使用SVM建立学习模型.当分类特征的维度(标记集Y的大小)是2时,学习模型就是1个SVM二类分类器.对于|Y|>2的分类特征,学习问题使用多类到二类削减方法被分解成|Y|个二类分类任务.然后,使用1对多训练方法建立|Y|个二类分类器;通过将训练数据中具有li标记的数据点作为正例,剩余的数据点作为负例,将Y的li标记的学习任务转换为2个分类.例如: Gain System Access是分类特征Vulnerability Impact中11个分类中的1个.在其训练数据中,CVE-2004-0445被认为是正例,CVE-2007-2151被认为是负例,即使后者拥有DoS的真标记.当分类特征是一元的情况下,本框架也为其创建1个多类分类器而不是将其削减为二类分类任务.
4 结语
通过命名标准化和按时间顺序列举所有已知漏洞,CVE字典已成为安全资源和信息交互的媒介和中枢.本文通过设计一种新的CVE分类框架即CVE分类器,提供了漏洞的分类和归纳的能力,加强了CVE字典的功能.为下一步研究数据融合和数据清理过程来消除训练数据的不一致,采用n倍交叉验证方法来评估学习模型的效果.
[1] 贾俊新.基于CVE知识库的主机入侵防御系统[D].哈尔滨:哈尔滨理工大学,2008.
[2] 李 菲.基于CVE的网络入侵防御系统的研究和实现[D].哈尔滨:哈尔滨理工大学,2008.
[3] 吴恩竹,钱 庆,胡铁军,等.词干提取方法及工具的对比分析研究[J].图书情报工作,2012,56(15):109-115.
[4] 何其慧,王 翠,王军军.基于随机模糊样本的统计学习理论基础[J].合肥学院学报:自然科学版,2011,21(3):5-11.
(责任编辑 陈炳权)
Construction of a Categorization Framework for CVE Based on SVM
PENG Hua,LI Zong-shou
(College of Information Science and Engineering,Jishou University,Jishou 416000,Hunan China)
The CVE dictionary can not design effective defense strategies for clustered system’s vulnerabilities because of it’s lack of categorization and generalization capabilities.To address such shortcomings,this paper propose a CVE categorization framework called CVE Classifier,which can categorize CVEs according to various taxonomic features.CVE classifier automatically extract the training data from the associated vulnerability databases (including:BID,X-Force and Secunia)and builds learning models for taxonomic features based on it by using SVM.
Support Vector Machine(SVM);Common Vulnerabilities and Exposures(CVE);taxonomic feature
TP393.08
A
10.3969/j.issn.1007-2985.2013.01.016
1007-2985(2013)01-0066-06
2012-10-26
湖南省科技厅科技计划资助项目(2011FJ3209);湖南省教育厅科学研究资助项目(11C1025)
彭 华(1980-),男,湖南吉首人,吉首大学信息科学与工程学院讲师,硕士,主要从事网络安全和嵌入式系统研究.
