基于网络微博的地震宏观异常信息提取研究——以芦山地震为例1
2013-09-09张群燕黄健熙张晓东苏晓慧
张群燕 黄健熙 张晓东 苏晓慧 张 旭
基于网络微博的地震宏观异常信息提取研究——以芦山地震为例
张群燕 黄健熙 张晓东 苏晓慧 张 旭
(中国农业大学信息与电气工程学院,北京100083)
微博平台有用户群大、公众参与性强、实时性等优点,同时微博平台信息又具有信息真伪难辨、地址信息模糊等缺点。本文以芦山地震为例,针对微博内容如何提取和地址如何定位两方面进行了分析研究,对于如何在网络微博平台中及时的提取地震宏观异常信息,提出了聚焦爬虫技术,并对微博地址进行了分类,同时将正向最大匹配和特征词地址分词的中文地址匹配模型应用于地址信息的提取和地址匹配中;最后将不同的地址类别定位为不同的行政级别,使微博平台和微博信息得到了充分的利用。通过研究认识到微博信息在反应震前异常的发生趋势方面有一定的参考价值(动物异常和气象异常所占比例较大),是不能被忽略的;地址方面可以看出异常随着时间的逼近有向震中聚集的趋势,有一定的参考价值。
微博平台 聚焦爬虫 地震宏观异常 分词技术 地址匹配
引言
随着现代社会的发展,电子设备的应用越来越得到普及,智能手机、IPAD、电脑等已成为不可或缺的工具。其中,微博作为一个大众参与度很高、参与实时性很强的平台已广泛地进入了大众的生活,据统计到2011年10月,中国微博用户总数已达到2.498亿,成为世界第一大国(百度百科)。微博作为低门槛网络平台,公众可以直接上传生活中观察到的异常信息,包括图片、语言描述、视频等,无需通过复杂的上报流程,节省了时间;而且,有些公众会因异常简单单一,比如只是狗叫等一些小现象,不想通过正规的上报流程去上报它而忽略重要的异常信息;最后,本着大部分公众一切就简的心理,公众更倾向于在无需承担责任、无需填写复杂的上报表格、无需跟随后续的落实等环节的微博平台上上报发现的异常,因此公众向地震部门上报的信息就少的多。而微博正是发挥了它的优势,让公众可以没有任何顾虑的上传信息,不管是地裂缝这种相对重大的异常还是只是狗叫的小事件异常,公众均可在微博平台上分享,公众只需要像平时分享心情一样的分享这些异常信息,无需过多的考虑;而且身边有跟你同样感触或发现的人还可以转发你的微薄,而通过转发数量我们还可以获得更多更有价值的信息;只要我们可以及时、准确地收集这些异常信息,就可以为地震的预测提供科学的数据依据。同时,本着群测群防的倡导让最大公众群体参与进来的原则,实现公众范围最大、公众参与数量最多、异常信息上报最多的最终目的,尽可能多的收集异常信息,共同为通过地震宏观异常来进行地震预测服务。因此,微博平台的应用就成了志在必得的事情,而如何更好的应用它就成了值得研究的问题。
1 微博地震宏观异常信息的提取分析
微博信息内容复杂,想从复杂的信息中提取自己想要的信息存在一定的困难。传统的搜索引擎(Search Engine),例如AltaVista、Yahoo!和Google等,一般作为一个辅助人们检索信息的工具成为用户访问万维网的入口和指南。但是,这些通用性搜索引擎也存在着一定的局限性,最主要的局限即是通用搜索引擎对那些图片、数据库、音频、视频多媒体数据等具有一定数据结构的数据无能为力。而地震宏观异常信息中大部分都具有图片,少部分具有音频甚至视频数据,想通过通用的搜索引擎从网络微博中直接提取这些信息就有了一定的难度。聚焦爬虫是一个自动下载网页的程序,它根据既定的抓取目标,有选择的访问万维网上的网页与相关的链接,获取所需要的信息(周立柱等,2005)。与通用爬虫(general purpose webcrawler)不同,聚焦爬虫并不追求大的覆盖,而将目标定为抓取与某一特定主题内容相关的网页,为面向主题的用户查询准备数据资源。为此,本文预选用聚焦爬虫技术软件直接在网络微博中提取相关的信息。
网络爬虫是一个自动提取网页的程序,它是从一个或若干个初始网页的URL开始,获得初始网页的URL,然后在抓取的过程中不断的从当前页面提取新的URL放入队列,直到满足条件。在提取的过程中选择不同的搜索策略就是爬取算法实现的过程,根据需求可以选择不同的爬取算法、不同的停止条件,这样获取的结果就会有所不同。聚焦爬虫过程较其他网络爬虫算法会稍显复杂,因为我们需要根据一定的网页分析算法过滤一些与主题无关的链接,首先要将满足条件的网页放入队列中,然后根据一定的搜索策略从队列中选择下一步抓取的URL,直到满足停止条件,然后再采用一定的网页分析方法将所需的数据提取出来放入数据库;将剩下的网页按照一定的分析算法直接进行分析、过滤、提取,并进行存储。
对网络微博进行聚焦爬虫技术,本文采用广度优先的网页搜索策略和基于领域概念的网页分析算法。广度优先搜索策略即在抓取的过程中,先完成当前层次的网页抓取后再进行下一层次的抓取,这样可以实现覆盖网页最广;因为目标数据要求往往是尽可能的全,数量尽可能的大;另外根据微博信息的特点,往往是信息本身就包含了所需的各要素,因此采用广度优先的搜索策略能最大程度的满足需求。同时针对微博信息内容叙述不严谨且叙述方法多样等特点,采用基于领域概念的网页分析算法能最大程度的实现信息要素采集齐全,因为领域本体是由不同的概念、实体及其之间的关系和与之对应的词汇入构项组成,在进行加权计算时,离核心概念越近的权重越高,得到的信息相关性越强,准确性和效率就越高,更能满足需求。
对网络微博进行爬虫技术的实现还有一个亟待解决的问题就是微博URL的开放问题,由于微博URL现在是未公开状态,所以目前获取微博地震异常信息的方法主要有微博公司提供的数据,还有就是通过微博平台的搜索工具来自动搜索的数据,自动搜索采用关键字匹配的方法。登入官方微博后在搜索框中设置关键字为“地震”,同时在高级搜索页面中设定搜索的时间范围和地址范围,比如芦山地震地址范围设为“四川雅安”,时间范围设为地震前后1个月(2013/3/20—2013/5/20),来筛选出与之相关的信息,将搜索到的信息再按照预先设定好的规则进行逐层次的判定,筛选出需要的信息。通过这个方法在芦山地震发生前后1个月的时间段内,通过关键字“地震”可以搜索出21840条新浪微博信息,然后根据一定的判定规则从中筛选出公众上报的一些地震发生前的异常现象,共有33条。其中表1中用黑体字标记出的信息是根据关联度与地址需求要筛选掉的不符合要求的信息(苏晓慧,2013)。
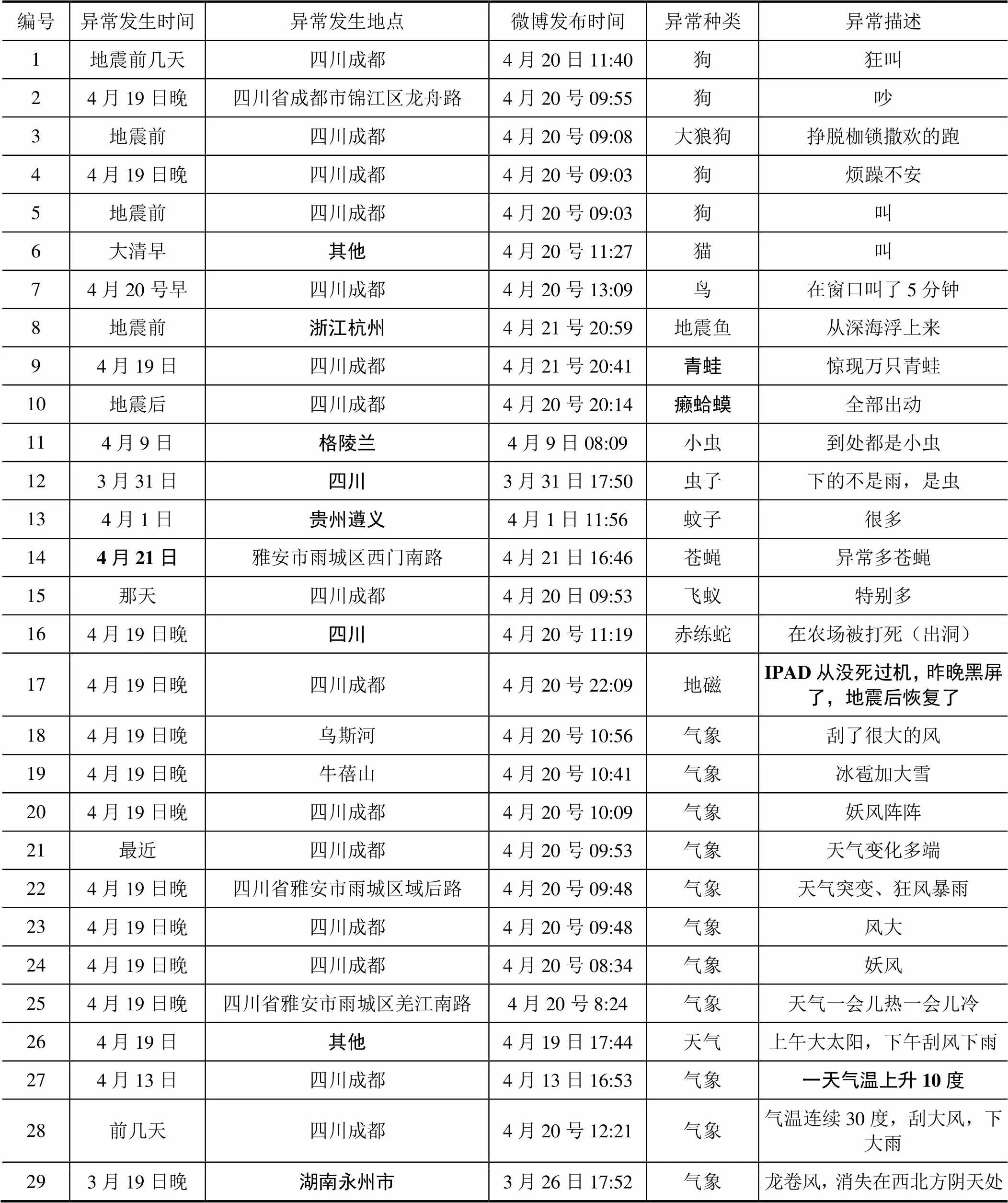
表1 芦山地震前后1个月的微博异常信息整理
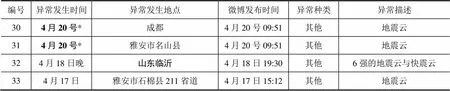
续表
由表1可以看出,微博的地址信息是一个相对复杂的问题,由于人们上传信息习惯的不同,有些信息地址是特别详细具体的,而有些信息地址却是模糊的,因此需要进行一定的研究。本文就如何解决微博地址问题做了深入的探讨,并对以上异常信息进行了图上显示与分析。
2 微博信息地址的分析
异常信息的地址信息在对异常信息进行判定和应用时发挥着重要作用,地址信息决定着异常发生的地点和将来灾害可能的发生地点,可以说没有地址信息的数据是不完整的数据信息,是不能被采用的信息,因此地址信息作为网络上报信息的一个重要因素必须高度重视。
2.1 微博信息地址的分类
基于微博平台,地址信息似乎是一个很难解决的问题,由于人们在网络平台上发布信息的习惯和使用的工具(电脑、智能手机和普通手机等)的不同,微博信息的地址呈现出的格式也是多种多样的,经过整理大体可分为以下四种情况。
(1)在信息中明确标明异常信息发生的地址
这类地址信息一般包含在原文中,是上传信息者明确写明异常发生的地址。在搜集到的17条芦山地震微博异常信息中,有2条信息在内容中标明了异常发生的地址。
(2)通过智能手机进行自动定位的地址
随着现代社会的发展以及智能手机的普及,使用智能手机的用户也越来越多,因此自动定位地址的比例也比其他几类地址要高出很多,简单统计的结果是这类地址可以达到40%以上。自动定位的地址同时又包含了两种情况:一种是上传信息者直接在地图上定位,还附有定位的地图链接;另一种是上传者自己命名的地址,这类地址存在命名是否规范的问题,在进行地址匹配时要做到特殊处理即地址规范化等。芦山地震微博异常信息中有定位地址的信息为4条。
(3)用户注册地址
这类地址是指微博信息内容中无任何明确标明的地址信息,也没有任何自动定位信息,只能获取用户注册时提供的地址字段的地址信息,考虑到这类信息也占据着很大的比例,芦山地震微博异常信息中通过用户注册地址得到异常发生地址的信息有12条,所占比例较大不能舍弃,因此只能应用用户的注册地址信息进行定位(一般精确到市县级,这在地震的预测领域也是有重要参考价值的);但是这类信息在应用定位时要给出标注和说明。
(4)无地址信息
一般指微博信息内容中没有明确的地址,也没有注册地址,而且异常的发生地址与用户的注册地址明显不是同一个地址的一类地址。这类地址所占比例较小,据简单统计,比例为1%左右。没有地址的信息是不完整的信息,应当舍弃。
2.2 微博信息地址的匹配
提取微博信息的目的之一是想通过一定的规则判别出地震宏观异常信息,并通过分析地震宏观异常的类别、发生时间、发生地点以及多种异常的关联,来识别最终地震有可能发生的地点及震级,最终目的是为地震的预测提供一定的数据支持。因此将各种异常信息进行定位并在图上显示就显得合理和必要。通过一定的规则将异常发生的地点进行匹配定位就成了必须解决的问题。通过对应用需求和程序实现的困难程度的多方面考虑,本文制定了下面的匹配流程对各类微博地址进行匹配,最终实现图上显示(图1)。
要进行自动地址定位就需要有事先建立好的分词字典库和标准的地名地址库(钱敏等,2012),分词字典库即进行地址拆分和微博信息中提取地址信息时应用,并将地址信息拆分为标准的地名地址库所识别的格式;不同的微博地址类别需要实现不同精度的定位,因此所需的标准的地名地址库的精度也是不同的。当然标准地名地址库的精度越细越好,但考虑到全国地名地址太复杂,县以下有很多重名地址,所以最后决定将详细的地址信息定位到县级行政单位,而对于精度只到市级的地址信息就直接定位到市级行政单位。将两者均定位到行政单位的政府所在地的位置。
由于每种地址类型在微博信息中位置的不同,每种地址类型的提取方法也是不同的。地址信息包含在微博信息原文中的地址,需借助爬虫工具爬取地址信息所在的句子,然后经过分词技术提取纯地址信息(分词流程见图2),将得到的最终完整的地址信息写进数据库,达到获取地址信息的目的。通过智能手机自动定位的地址,只是爬取地址信息即可,但手机定位地址一般都不是标准的地址名称,很大一部分是信息发布者自定义的地址名称,这就需要将获取的定位地址首先进行地址标准化,然后再将得到的标准地址写进数据库,来进行最后的地址匹配。第三种地址类型即需要获取用户注册地址的只能通过锁定用户信息的关键字段来获取地址,这类地址比较统一,一般都精确到市级行政单位,将这类地址信息直接写进数据库,最后通过定位到市级政府所在地来进行定位并图上显示。
考虑到微博平台地址信息大部分不能获得详细的地址信息,同样考虑到项目应用的匹配精度需求,拟采用正向最大匹配和特征词的地址分词的中文地址匹配模型。正向最大匹配是按照一定的策略将待分析的汉字串与一个“充分大的”机器词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功(识别出一个词);正向最大匹配法扫描的方向是由左到右的方向(孙亚夫等,2007)。
不管是在地址匹配的过程中还是在地址信息的提取过程中均需要分词技术的支持,分词技术将地址信息所在的句子或是地址信息进行拆分,以期与分词字典库和标准地名地址库进行匹配(谭侃侃,2011),进行分词的前提是已建好分词字典库,根据不同的应用需求和分词方法选取的不同,分词字典库可以有不同的设计和不同的精度,因为原数据是经过网络爬虫工具爬取出的包含地址信息的句子或是微博中心直接给出的微博上传时的具体的地址信息,所以无需中文大字典这样的分词字典,采用包含所有地址因素的字典库更准确有效,即可参考《中华人民共和国行政区划代码》和《县以下行政区划代码编制规则》编制分词字典库(洪莹,2008)。综合考虑到应用的需求,拟采用基于字符串匹配的分词算法,分词方法流程如图2所示。
经过微博地址信息的提取、分词和匹配,即可将微博平台中搜索到的宏观异常信息进行空间定位,达到统计、分析和辅助预测地震发生地的目的。
以芦山7.0级地震为例,通过微博平台共搜集到18条有效信息。其中在信息中包含具体地址信息的共2条(编号为17、18);含有自动定位信息的共4条(编号为2、21、24和32);其余信息是通过用户的注册信息得到的地址信息共12条;分别按照上面的原则,将宏观异常信息进行图上显示(见图3)。
地震发生后,为进一步了解灾区地震情况并搜集地震宏观异常信息,我们于2013年6月份,赶到地震灾区进行了现场调研,搜集了大量材料和信息,其中搜集到宏观异常信息共86条,包括动物异常41条(占47.7%)、气象异常22条(25.6%)和地声、地雾、地下流体、地磁、人体异常共23条,信息具有一定的真实性和可信度。可以此为参照从三个方面来对比分析微博信息的质量。
地址方面,从图3可以看出异常信息主要分布在安宁河谷带和河西走廊带两大地震带的内部和边缘,并且随着时间的逼近异常有沿着地震带向震中聚集的趋势,这与我们前往芦山周边及震中调研的异常信息的分析结果是相符的,即震前1天各种异常向震中聚集。根据图上显示震中附近无异常而大量的动物异常均分布在外围,笔者认为原因很可能是震中为广大的农村,笔者曾去芦山县震中附近调研,发现震中是一个村庄,农村对地震宏观异常现象认知有限,对于宏观异常敏感度较低,同时网络不发达,即使发现了宏观异常现象也不会及时通过微博上传信息,造成震中无异常的现象。
异常的种类和数量方面,比较微博搜集的宏观异常信息和现场调研的异常信息,可以看出两种方式得到的信息中动物异常和气象异常均占据了较大的比例,因此可以认为微博信息在一定程度上能够说明震前异常的发生趋势。对比芦山地震和2010年汶川8.0级地震,异常发生的种类均集中在动物异常、气象异常、地声异常三大类异常(许敦煌,2010)。
时间方面,微博平台是一个实时性很强的平台,不管是人们上传异常信息,还是获取异常信息,都是可以随时进行的;和地震部门异常信息上报流程相比,微博可以节省更多更宝贵的时间,同时省去很多上报异常的细节,提高了人们上报异常的热情和参与积极性。但是考虑到人们每当事件发生后才会注意到事情的严重性这一心理习惯,往往收集到的信息是人们回忆的地震前的异常信息,这样只能为震后异常分析和后续地震预测先验知识的提出提供一定的借鉴价值。
由此可见,微博在地震的群防群测工作中,在专群结合政策的倡导中是具有一定的社会服务能力的,同时作为搜集地震宏观异常信息的途径之一是不能被忽视的。
3 结语
微博平台具有低门槛、实时性强、公众参与度高等优点,可以为收集地震宏观异常信息提供一个实时的和长期的途径;但是作为低门槛平台,微博信息内容不可控制,有些人会上传一些虚假信息或者一些子虚乌有的信息引起人们的恐慌,而且微博信息地址一般不够规范,没有统一的格式或者使用一些地名的别名等。本文以芦山地震为例,介绍了如何进行微博信息的搜集,并且针对搜集的特点采用了聚焦爬虫技术,并对爬虫技术进行了简单的介绍,同时也探讨了其中包含的地址信息的分类,并且给出了针对项目需求每种地址类型的解决途径;当然可能存在统计不全面、解决方法不够具体等缺点。下一步的工作将就文中提到的微博信息的提取技术和地址信息的匹配方法进行程序实现,实现整个过程的自动化。
微博虽已拥有了相当数量的用户,但从用户群体来看,这些用户一般是上班族和学生,而且这些用户群体一般居住在城市或者学校;而地震宏观异常一般发生在动物比较多、生存环境比较自然的农村,考虑到这点,微博信息异常种类就比较单一了。而且微博也有它的局限性,对网络和电子设备要求较高,但这不能掩盖它作为搜集异常信息的途径之一的现实意义。要发挥各方面的优势,尽可能全面及时的搜集各种异常信息,为地震的预测提供科学的数据基础。
总之,微博平台作为一个发布信息快速、信息传播的速度快、公众参与度高、可以实时的提供公众信息的平台,一定要得到好的利用。呼吁大家一定不要上传虚假信息,要即时分享自己发现的异常信息,而且上传信息时要做到内容真实不夸张,时间、地点、对象等要素信息齐全,做到简而不漏,让微博更好地为地震宏观异常信息的提取服务。
洪莹,2008. 城市地名地址匹配方法研究与实验. 辽宁:辽宁工程技术大学.
钱敏,顾国强,2012. 用于地址(地理位置)匹配的关键路径法. 计算机应用与软件,29(1):211—214.
孙亚夫,陈文斌,2007. 基于分词的地址匹配技术. 中国地理信息系统协会第四次会员代表大会暨第十一届年会论文集,114—125.
苏晓慧,2013. 公众参与式的地震异常信息提取与评价方法研究. 北京:中国农业大学.
谭侃侃,2011. 基于规则的中文地址分词与匹配方法. 济南:山东科技大学.
许敦煌,2010. 汶川大地震前宏观异常的现场调查. 地震,30(2):121—133.
周立柱,林玲,2005. 聚焦爬虫技术研究综述. 北京:清华大学.
Micro-blogApplication in Extracting Information of Earthquake Macro-anomalies
Zhang Qunyan, Huang Jianxi, Zhang Xiaodong, Su Xiaohui and Zhang Xu
(College of Information and Electrical Engineering, China Agriculture University, Beijing 100083, China)
Micro-blog is characterized with large user groups, strong public participation and real-time information although it is often difficult to verify the accuracy and authenticity of the information. Taking Lushan earthquake as an example, we performed analysis on how to extract the information and how to locate the addresses. Firstly, we use the focused crawling technique to extract the Macro-anomalies from Micro-blog in time. Then we put the addresses into four classifications and chose the model of Maximum Matching from beginning and characteristic words segmentation as the algorithm in the address matching perform. Finally, we locate the different address classification to the different administrative units which makes full utilization of the micro-blog platform and information. Our results suggest that the information on micro-blog may provide some
regarding to animal behavior anomaly and the weather anomaly.
Micro-blog; Focused crawling technique; Earthquake macro-anomalies; Word segmentation algorithm; Address matching
1基金项目国家“十二五”科技支撑计划课题(2012BAK19B04-03)
2013-08-09
张群燕,女,生于1987年。硕士。专业:计算机技术。E-mail: ytqunyan@163.com
黄健熙,男,生于1976年。副教授,博士生导师。研究方向:农业遥感与灾害遥感应用。E-mail:jxhuang@cau.edu.cn
张群燕,黄健熙,张晓东,苏晓慧,张旭,2013. 基于网络微博的地震宏观异常信息提取研究——以芦山地震为例. 震灾防御技术,8(4):429—437.
