面向地震宏观异常的主题爬虫研究1
2013-11-26张晓东
方 帅 李 林 张晓东
(中国农业大学信息与电气工程学院,北京 100083)
引言
随着现代社会信息技术的发展,互联网已经超过报纸和电视等传统媒体,成为公众传播和获取信息最迅速的传播平台。地震信息作为公众十分关注的热点信息,在网络上也有着极高的传播量,并且在地震发生的前后一段时间内具有爆炸性的增长。在这些地震信息中,有一类信息是描述地震宏观异常现象的,这类信息与地震的发生之间存在相关性,因此许多科学家致力于研究如何获取网络上的宏观异常信息,并筛选和评价网络上的这些地震宏观异常信息,以期对地震的预测预报服务。网络宏观异常信息和其他网络信息一样日益庞大,采用传统的人工检索的方式采集这类信息无疑费时费力,这就要求我们采用一种新的自动采集方式来获取这类信息。
传统的网络信息自动获取技术,主要指网络爬虫技术。通过网络爬虫,可以尽可能多地爬取网络信息页面,在搜索引擎等信息检索领域有着重大应用。但这种技术在获取特定的网络信息,例如地震宏观异常现象时,依然会采取原有的信息采集方式,消耗大量系统资源、网络带宽和时间,如何提高信息采集效率是本文的研究内容。本文旨在使用主题爬虫技术,改进原有的网络爬虫信息获取方式,提高特定事件信息的获取效率。
1 主题爬虫技术简介
网络爬虫是一种根据既定规则自动抓取网页信息的程序或者脚本。它从一个初始的URL链接或者URL集开始访问,将访问到的网页或者网络文档中所包含的URL放入待访问的URL队列中,之后从队列中取出URL继续访问,然后重复以上活动,直至满足结束条件为止。
主题爬虫是在网络爬虫技术上发展而来的,主要通过对页面内主题内容的鉴别,确定爬虫URL访问顺序,并且根据对主题的判定,确定页面的取舍。因此主题爬虫的核心内容是爬取策略的选取。主要的爬取策略分为三大类:基于文本启发式的策略;基于Web连接分析的策略;基于分类器的策略。
基于文本的启发式的策略是最早出现的主题爬虫采用的策略。1994年,Debra等(1994)提出了一种主题爬虫的雏形,名为Fish Search。1998年,Hersovicim等(1998)在Fish Search基础上改进提出了Shark Search算法。同年,Cho等(1998)也提出了Best First Search算法,他利用了已爬取的网页进行待访问网页主题相关性的预测,从而确定URL的访问顺序。
基于Web连接分析的策略,起源于Brin等(1998)的Page Rank算法,这个算法用于Google搜索引擎的搜索结果排序。利用PR值可以方便地调整URL访问序列,但问题是网络重要度更大的网页不一定与主题相关。
基于分类器的策略,主要基于几种常用的分类数学模型,如:SVM分类器、贝叶斯分类器、BP神经网络分类器等。例如:1999年Chakrabarti提出了基于朴素贝叶斯分类法,这个分类器在只有一个主题的爬虫系统中效果很好,对于爬取的网页可以进行准确的分类。
上述几类爬取策略在实现难度,适用领域,算法效率方面都有不同的优缺点。对于不同主题,应当充分考虑目标主题及目标信息的特点,选取合适的爬取策略,设计有针对性的主题爬虫。对于地震宏观异常现象这个主题而言,可能发生异常的事物主体在以往的资料中多有记录,因此可以采取文本启发式的策略,将与地震宏观异常现象有关的词语作为主题描述词,挖掘页面内容与主题描述词组的相关性,利用Best First Search的方式预测待访问网页链接的主题相关性,从而形成符合地震宏观异常现象主题的主题爬虫爬取策略,并获取网络中的地震宏观异常信息。
2 主题爬虫方案设计
2.1 主题爬虫框架
本文设计的主题爬虫是在Heritrix的基础上进行的二次开发。Heritrix是Source Forge上的开源产品,是一个JAVA语言下的爬虫框架。它是由一系列组件构成的,开发者可以根据自己的需要方便地修改和扩展各个组件,来定制一个属于自己的爬虫。Heritrix主要包括:范围部件、边界部件、处理器链。范围部件主要根据规则决定进入访问队列的 URL;边界部件跟踪将被访问的URL和已访问的URL,选择下一个待访问的 URL链接,去除已处理的URL;处理器链包含几个处理器获取URL,分析结果并将其传给边界部件(孙庚等,2010)。Heritrix的框架构图如图1所示。
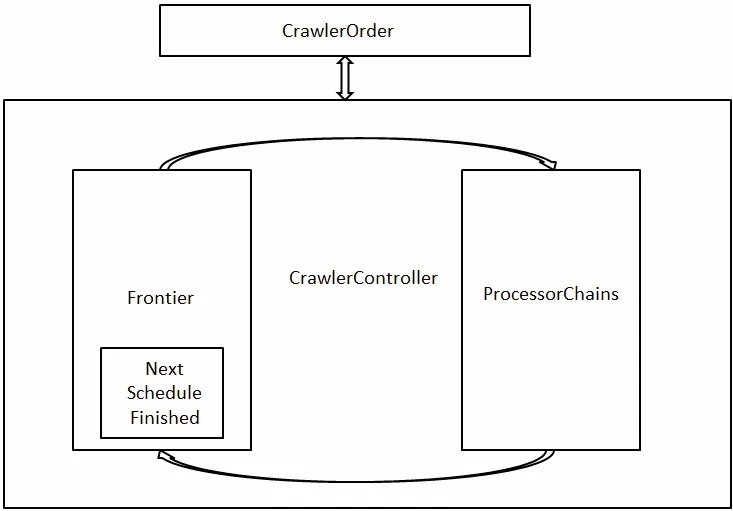
图1 Heritrix框架图Fig. 1 Framework of Heritrix
从图1可以看到Heritrix的主要组件:CrawlOrder、CrawlController、Frontier、Processor Chains。Heritrix的工作流程为:CrawlController是Heritrix的控制器,由它开始一次任务;CrawlOrder决定这次抓取工作的起点,从Frontier取出URL,传递给ProcessorChains中的线程池;ProcessorChains控制爬取线程,访问并返回网页信息,从中获取发现新的URL交由Frontier;Frontier通过对ProcessorChains下载的网页分析并获取新的URL,根据访问策略提供新的URL给CrawlOrder,继续爬取工作。当满足任务结束条件时,由CrawlController结束整个任务。
初始 URL集应当选择与地震宏观异常信息相关的网站,通过对网络上地震相关网站的查询与搜集,共选择198个地震专业网站,24个新闻门户网站作为初始的URL集。对于定制的主题爬虫,根据爬取策略和主题内容重写Frontier组件即可。在Frontier组件中,有三个接口是实现地震宏观异常主题判别与爬取策略的关键,它们分别是:Finished、Schedule、Next。Finished接口负责分析ProcessorChains下载的页面,从中取出URL,而计算主题相关性正需要进行页面分析,因此需要在这里重写该接口,添加相关度计算模块,利用地震宏观异常主题描述词组与相关度计算算法,计算该页面的主题相关度与页面内URL链接的相关度。之后,根据计算出的相关度,利用Schedule接口调度 URL队列,最后利用Next取出需要爬取的URL交予CrawlOrder,实现爬虫的主题判别与爬取策略。
2.2 地震宏观异常主题的表示
所谓地震的宏观异常现象,就是人的感官可以直接察觉到的,或者利用一些简单的工具可以观测到的与地震的发生具有一定联系的自然现象。地震的宏观异常现象表现形式复杂多样,根据国内外有关资料,异常的种类多达几百种,异常的现象多达几千种,大体上可分为动植物异常、地下水异常、地形变异常、电磁异常、气象异常等。通过对一些国内权威机构出版的地震宏观异常资料查阅分析,共得出10大类,216小类异常现象(中国地震局监测预报司,2010)。
由于网络上的地震宏观异常信息主要以文本信息为主,所以已确定的异常现象类别选取一定数量的关键词用于描述地震宏观异常现象这个主题。一条完整且有价值的地震宏观异常现象应当具备时间、地点、事物主体、经过、结果五大组成部分。其中与地震异常相关的主要是事物主体、经过、结果三个部分。由于地震宏观异常的具体现象种类繁多,对单一事物某类行为是否属于地震宏观异常需要特别分析,在此主要选择可能发生地震宏观异常现象的事物主体作为主题相关词。同时,为了确保异常信息与地震相关,最好采集到的信息已经包含对该现象是否是地震宏观异常现象的判断。关键词的选取如表1所示。

表1 地震宏观异常现象主题关键词Table 1 Keywords of earthquake macro-anomaly
2.3 主题相关度计算
主题相关度的计算应当达到两个方面的目的:判别当前页面的相关性;预测待访问URL的相关性。
2.3.1 当前页面相关性
由于主题关键词已经确定,因此计算主题相关性采取向量空间模型的方法较好,可以将关键词中的词语视为该向量空间的特征。因此对于关键词组有特征向量:
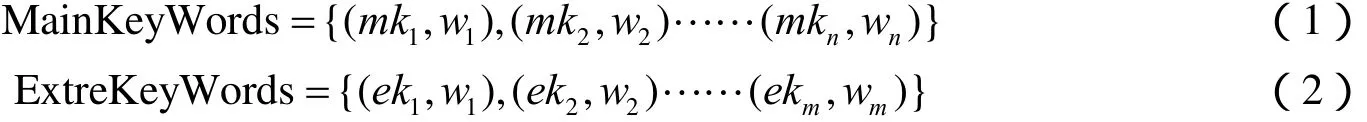
式中,MainKeyWords为异常的事物主体关键词组特征向量;ExtreKeyWords为异常判别的关键词组特征向量。
对于一个页面而言,由于其结构化的特性,包含了不同的内容块,如:导航块、广告块、主体块等,因此可以利用页面标签及内容对页面进行分块。可以得到页面内容块的特征向量:

通过以上步骤,可以将当前待处理的页面文本特征化,使用向量表示当前页面。之后使用向量夹角余弦来计算主题相关度:
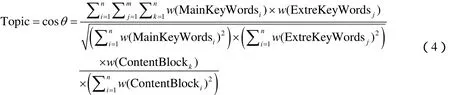
式中,w代表权值,对于不同向量的权值,其计算公式也不同。
同时,由于页面文本分为不同的文本块,因此对于异常的事物主体关键词组特征向量MainKeyWords,其第i个特征权值有:
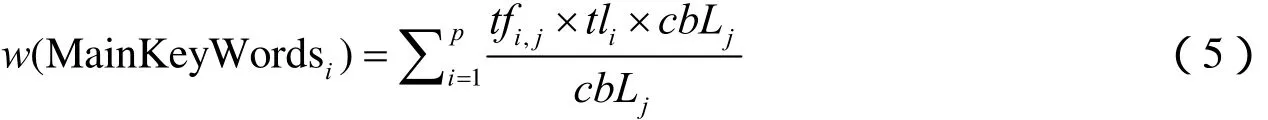
式中,,ijtf为关键词i在j内容块中的词频;itl为第i个关键词的词长;jcbL为j内容块的文本长度;jcbi为j内容块的重要度。计算方法为该部分页面代码占页面内总代码的百分比。
对于异常判别的关键词组特征向量ExtreKeyWords,其第i个特征权值有:
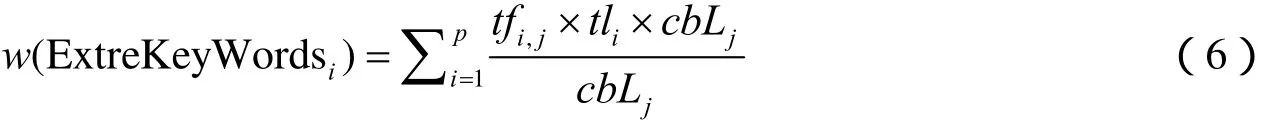
由于异常判别这类关键词并不是必需的,因此为防止页面中未出现该类关键词时,该权值为0,故设其权值+1。
对于页面内容块的特征向量ContentBlock,其第i个特征权值有:
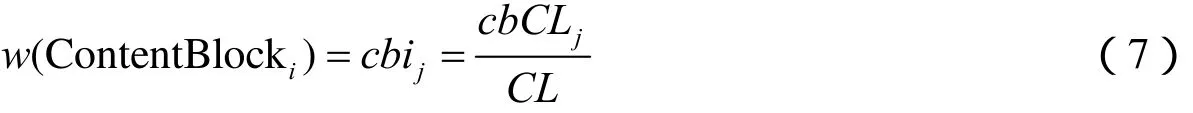
通过上述算法可以计算得出当前页面的相关度Topic。设阈值M,当Topic>M时,则认为当前页面符合地震宏观异常现象这个主题,保存它的页面内容,URL链接,主题相关度值、标题、时间等信息,以便进一步爬取和进行下一步信息处理。这里的M值将由试验确定。
2.3.2 URL相关性
得到页面的相关度后,需要对页面内的URL进行预测及排序。URL相关度的计算一般考虑URL地址、锚文本、上下文相关度,在这里考虑锚文本和上下文相关度,使用页面相关度作为上下文相关度(刘朋等,2009)。其计算公式为:
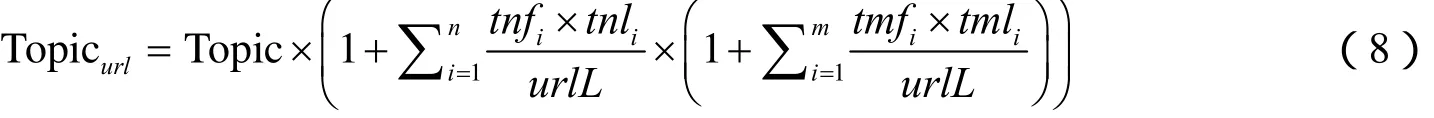
式中,itnf、itmf分别为事物主体关键词和异常判别关键词的词频;itnl、itml为事物主体关键词和异常判别关键词的词长;urlL为锚文本长度。
通过计算Topicurl并与URL队列中非初始URL比较排序,然后插入URL队列相应的位置中。至此,完成URL访问策略的制定与主题相关度的计算,进入常规的爬虫工作流程。对于Heritrix,其URL队列的控制主要由Frontier组件完成,因此重写Frontier组件中相应接口即可,主要是负责ProcessorChains中完成URL的下载后进行链接抽取和页面相关度计算的Finished,以及负责处理URL队列的Schedule和负责提供下一个Next。
3 实验分析
实验的目的主要是为了确定页面相关度的阈值R以及比较添加主题相关性预测的爬虫,和为具备此项功能的爬虫采集结果,共设计了两项实验。实验环境为台式PC机,中央处理器为core2双核2.7GHz,2G内存,32位WIN7操作系统。所使用的Heritrix爬虫为1.14.4版本,在Eclipse环境下,采用的JRE1.7版本。
第一项实验为确定页面相关度的阈值R,设定爬取线程为10,爬取深度为3,时间为900s,分别设定R值为0.1、0.3、0.5、0.7、0.9时进行爬取,结果如表2所示。
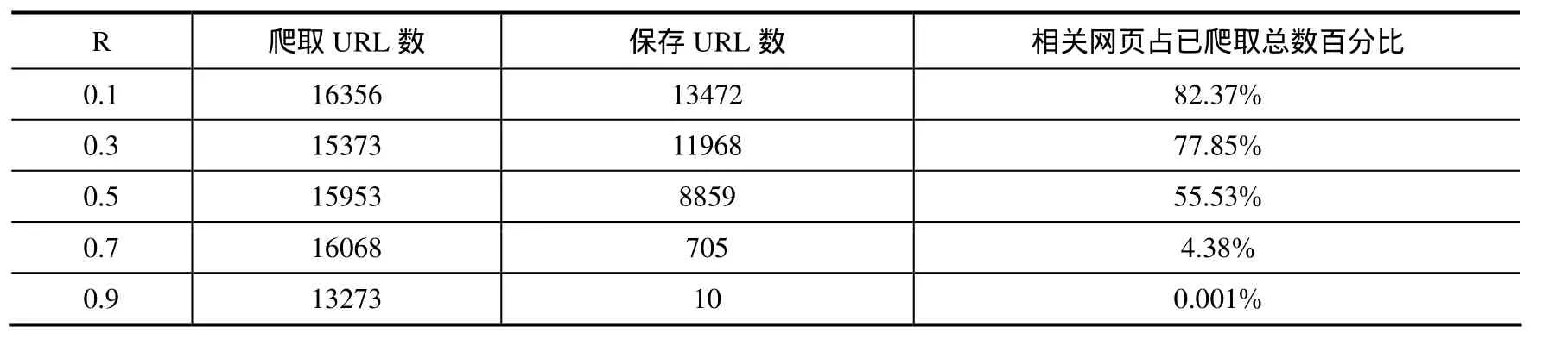
表2 阈值R实验结果Table 2 Experimental results of threshold value R
由该实验结果可以看出,当R值超过0.5后,符合主题的网页急速减少,说明主题爬虫的针对性更强。因此若想获取更加准确的网页,应当将R值设置超过0.5。
第二项实验为测试主题爬虫与传统爬虫的效果比较。设定主题爬虫R为0.5,利用相关度计算模块计算传统爬虫的爬取结果,实验时间为900s,结果如表3所示。

表3 主题爬虫效果实验结果Table 3 Experimental results of the topic crawler
由表3可以看出,虽然主题爬虫在单位时间内爬取数量不及传统爬虫,但获取符合要求的信息的效率大大强于传统爬虫,这说明主题爬虫在面向地震宏观异常现象这个主题的网络信息获取方面具有优势。
4 结束语
主题爬虫是较好的地震宏观异常现象信息的自动采集方式,但是其爬取策略的制定和主题相关性的判别依然是问题的难点。由于地震宏观异常现象本身的复杂多样,目前的主题表述仍然是不足的,因此需要进一步的研究,丰富主题关键词组,在主题相关性上进行进一步优化,这样的主题爬虫将能够更好地解决地震信息采集问题。
刘朋,林泓,高德威,2009. 基于内容和链接分析的主题爬虫策略. 计算机与数字工程,37(1):22—26.
孙庚,冯艳红,于红等,2010. 一种基于Heritrix的网络主题爬虫算法——以渔业信息网络为例. 软件导刊,(5):47—49.
中国地震局监测预报司,2010. 地震宏观异常摘编. 北京:地震出版社.
Brin S., Page L., 1998. The anatomy of a large-scale hypertexual Web search engine. See: B. Furht. Proc. of the 7th World Web Conference, Brisbane [sn]. 30 (1): 107—117.
Cho J., Garciam H., Page L., 1998. Efficient crawling through URL ordering. See: Computer Networks and ISDN Systems. 30 (17): 161—172.
Debra P., HouBen G., Kornatzky Y. et al., 1994. Information retrieval in distributed hypertexts. See: M. Diligenti.Proc. of the 4th Riao Conference, NewYork. 23 (25): 481—491.
Hersovicim, Jacovim, Maarekys, 1998. The Shark-Search algorithm: an application tailored Web sitemapping. See:H. Philip. Proc. of the 7th International World Wide Web Conference, Brisbane [sn]. 2 (10): 65—74.
