基于Q学习的WLAN/WIMAX接入控制网络选择策略*
2013-08-16徐玉滨陈佳美马琳
徐玉滨 陈佳美 马琳
(哈尔滨工业大学通信技术研究所,黑龙江哈尔滨150080)
下一代无线通信系统将趋向于由若干个异构网络组成[1-2].多种无线接入技术将在同一个地区共存,有着不同性能的多模终端会通过时变的无线信道并提出不同的服务需求.这种需求使得接入控制技术的作用越来越得到重视,即解决如何在异构网络环境中合理地接入呼叫用户.接入控制算法的合理应用将会满足不同用户的QoS需求,并且能够提高系统资源利用率.接入控制面临的第一个问题就是网络选择,因此,异构网络选择技术在异构网络性能保证上起着关键作用.
4G草案中提出将融合所有无线网络技术,其中包括3G、WLAN 以及 WIMAX[3].很多文献中讨论过3G与WLAN的融合,但遗憾的是对于WLAN与WIMAX的融合所做的研究并不是很多.考虑到未来无线网络环境会相当复杂,多种不同类型的无线接入网络会同时存在于一个地区,所以很有必要讨论各种网络的相互融合,以便在未来能够提供给用户服务质量最好且价格最合理的接入网络.WLAN网络的优点是传输速率高且价格便宜,但其覆盖范围有限,很难满足未来网络随时随地为用户提供接入网络的服务[4].IEEE802.16能够在大范围内提供数据传输.于是很自然的趋势就是结合 IEEE802.11和IEEE802.16建立一个完全的无线解决方案[5].这个系统可以充分利用IEEE802.11提供的合理价格和IEEE802.16提供的广泛覆盖率,给用户提供便宜且质量更高的服务.
很多著名的方法已经被提出来解决异构网络选择问题,这些方法可以分为两类:基于测量的方法和基于模型的方法.基于测量的方法是有效且易于执行的,但是由于没有任何理论基础,所以很难得到全局优化.更进一步,有一种普遍的基于测量的方法名为多属性决策,这种方法包括简单多属性决策(SAW)[6]、逼近理想解排序法(TOPSIS)[7]和灰度关系分析法(GRA)[8].这些方法都是应用几个QoS参数与相应的权重相乘,再求和,建立回报函数或者代价函数.这些权重一般来自于经验或由几个专家给出,并不精确,而且在服务类型确定后也不能适应网络的动态变化.相反,基于模型的方法由于具有自适应特性而显得更加灵活,因而很流行.但是,很多基于模型的方法[9]并没有真正考虑到异构网络本身自有的特性.文献[10]中用马尔可夫决策(MDP)方法解决网络选择问题,取得了较优的结果,但是它的状态空间的维度和计算复杂度会随着用户数增加而激增,所以并不适合实际的网络环境.鉴于此,文中提出一种不受模型约束的强化学习方法[11],即Q学习方法,来解决异构网络接入控制中的网络选择问题;从一个新的角度分析异构网络的网络状态,使网络状态估计更加准确,从而有利于系统做出更加准确的接入判断.
1 系统模型
系统做出网络选择判决之前首先需要了解各个子网络的网络状态,因为只有充分了解网络的负载和信道等条件,才能在用户发出接入请求之后,判断接入还是拒绝接入该用户,若接入,还要判断接入哪个子网络.因此网络状态分析显得尤为重要.
1.1 WLAN 系统测量
IEEE802.11标准定义了两种基本的媒体接入控制(MAC)机制,即强制实现的分布式协调机制(DCF)和可选的集中式协调机制(PCF)[12].由于PCF是可选的MAC协议,绝大多数802.11的产品并不支持PCF,因此文中主要关注DCF下容量的研究.
DCF是一种基于载波侦听多点接入/冲突检测标准协议(CSMA/CA)的访问机制.文中分析DCF提供的一种可供选择的4次握手技术,即RTS/CTS(Request-To-Send/Clear-To-Send)机制下的有效带宽.图1为其工作原理图,观察站点是所观察的准备发送数据的站点,它在发送数据前,先侦听信道,发现图中站点A正在发送数据,站点B接收数据,则该站点延迟发送,并将自己的状态设置成“信道被占用”,并退避一段时间[12].退避之后继续再一次监听信道,当检测到信道持续空闲(DIFS)时间时,并不是立即发送数据,而是代之发送一个请求发送帧(RTS),当接收站点收到RTS信号后,立即在一个短针帧间间隔(SIFS)内,回应一个准许发送帧(CTS),告知对方已经准备好接收数据.只有当双方在成功交换RTS/CTS信号后才开始真正的数据传输,其他接收站点检测到信道中的RTS/CTS信号后,会更新其状态为“信道被占用”,然后退避一段时间.观察站点在两种情况下认为信道处于忙的状态,一种是自己的状态处于“信道被占用”,这意味着信道正在被另一个接收站点占用;另一种情况是信道被该接收站点本身作为发送者或接收者占用.这样,累积这些信道忙的时间间隔,站点便能够估计信道利用率以及可用带宽.
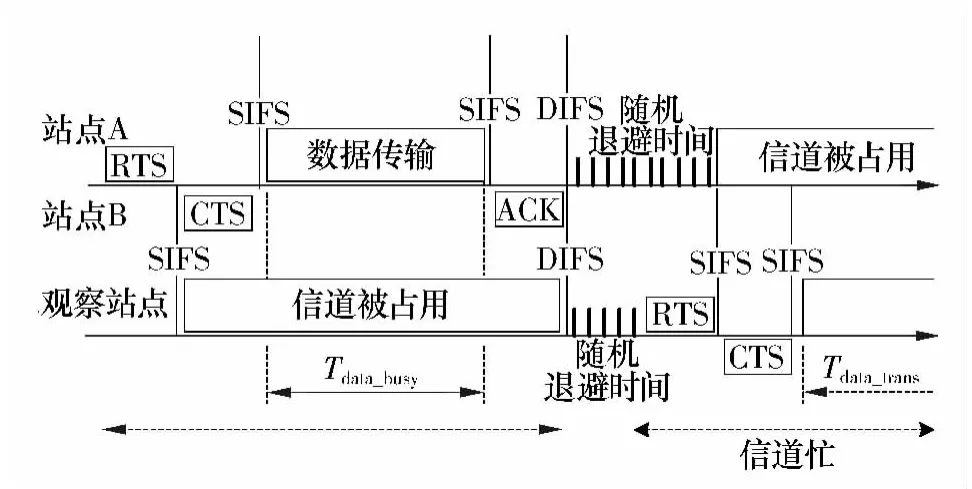
图1 WLAN系统DCF的工作原理Fig.1 DCF operational principle of WLAN system
假设观察时间为 ,在该段观察时间内信道被数据传输所占用的时间可以表示为

式中,Tdata_busy表示信道被其他站点(如站点A)占用的时间内用来传输数据所用的时间,Tdata_trans表示观察站点在竞争到传输周期后传输数据所用的时间.那么信道利用率就可写为

然而,如图1所示,在信道忙时并不是所有时间都用来传输数据,因为CSMA/CA还明确规定了SIFS以及DIFS等帧间间隔,以及随机回退时间等.由此可以得到信道忙期的时间内纯粹用来传输数据的比例为

式中,μdata为观察站点所要传输的平均数据长度,其以字节为单位.μR/C/A为RTS/CTS/ACK帧的长度总和,TSIFS、TDIFS分别为SIFS和DIFS的持续时间,Tbackoff(t)为平均随机回退时间,C(t)为时间t处的数据速率.通过以上的信息就能计算可用带宽,即

1.2 WIMAX 系统测量
与WLAN类似,文中也为WIMAX网络进行网络负载能力分析,即网络状态分析.需要注意的是,WIMAX中的资源分配方法与WLAN中是不同的.WLAN中的资源是被多个用户以竞争的方式共享,但是WIMAX中的资源被基站分为上行和下行两部分,因此在考虑网络负载能力时,需要分别考虑上、下行两方面的资源[13],可用带宽应该为
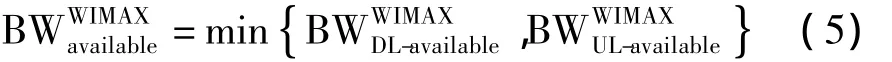
假设将WIMAX中的带宽资源以数据突发的形式分配.每个数据突发包含几个整数倍的物理时隙(PSs).定义Tframe为传输一帧所需的时间,SDL-total与SUL-total分别为上、下行一帧中的总的物理时隙数.假设在观察时间 内,存在整数倍的帧个数.那么帧的个数可以表示为

为了更清楚地说明问题,下面给出了各个时间概念之间的关系:

那么,时间内空闲的物理时隙数为
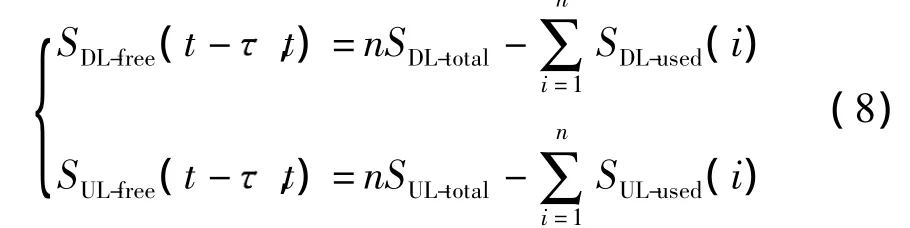
式中,SDL-used(i)、SUL-used(i)分别为每一个上行、下行的帧里被占用的PSs数.
根据上面的介绍,WIMAX的上、下行可用带宽分别可表示为

式中,CDL-slot(t)、CUL-slot(t)分别是上、下行的一个PSs中能够传输的比特数.
2 Q学习基础
当一个系统所做出的决策不仅依赖于环境当前的状态,也依赖于接下去的状态以及他们相关的动作时,强化学习就成了这种优化决策的一个合适的学习技术[14-15].文中接入控制的优化策略通过一种不受模型约束的强化学习方法即Q学习方法得到.
Q学习系统用一个控制者(学习者)来学习如何通过历史经验优化它的决策.在决策时隙t,控制者观察到环境的当前状态st然后执行动作at.执行动作后,环境会通过给予控制者正回报或负回报rt+1来指示所执行的动作正确与否,而后转换到下一个新状态st+1.控制者的最终目的是为所有状态s找到最优策略*(s)∈A,也就是一系列动作{a1,a2,…},其能够使得系统的总期望折扣回报最大.系统的总期望折扣回报能够被定义为一个值函数,其表达式如下
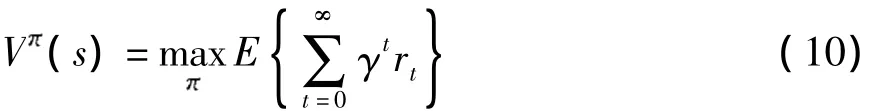
式中,E代表取期望操作,rt为在时间t得到的回报函数.在Q学习中这个回报函数不需事先定义,而只需要定义在每个状态下执行动作后的立即回报即可.γ为折扣因子,它是立即回报的重要性表现且0≤γ≤1.最优值函数V*s为
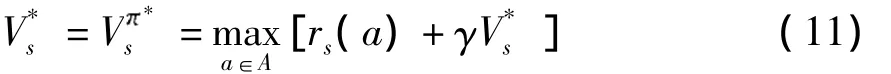
式中,rs(a)为在当前状态动作对(s,a)下得到的立即回报.该立即回报不是整体的回报函数,而是一个实时回报值,更加能够体现算法的自适应性.V*s为未来执行了最优可用动作后的期望折扣回报,那么最优策略可以表达为
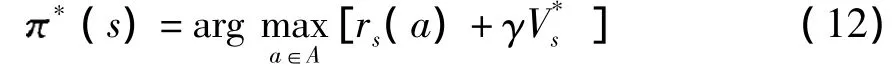
Q学习不需知道回报函数及状态间转移概率的具体分布便能得到最优决定策略*.为获得独立性,式中方括号内部分被定义为Q值,用Qs(a)表示,即

式中,Vs'为系统在下一状态s'的值函数.继而定义最优Q值(a),
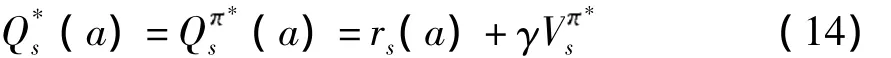


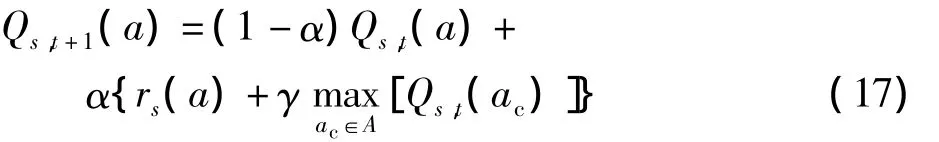
式中,ac表示所有可选动作,Qs,t+1(a)为经过更新之后的Q值,α为学习参数,一个Q学习控制者在每个特殊的状态st执行一个动作,并通过在未来获得的立即回报或惩罚估计动作执行的结果.通过在不同的时隙执行动作,它学习到最优动作,即能够获得长期的最大折扣回报的动作.
3 接入控制算法设计
3.1 动作与回报定义
异构网络中用户偏向于选择总是能够获得最好服务的网络,基于此,应该设计算法合理地将用户接入WLAN网络或WIMAX网络,所以定义所执行的动作:

在每个状态下执行动作后就获得立即回报,这个立即回报与动作执行后的网络负载性能有关.如果一个用户被接入到WLAN网络,获得立即回报rs(a)=1,若其被接入到WIMAX网络,同样rs(a)=1.如果两个网络都没有足够的资源,那么该呼叫就被阻塞,立即回报rs(a)=-2.
3.2 Q学习算法步骤
图2是异构网络接入控制的Q学习过程的结构图.

图2 接入控制系统的Q学习框架Fig.2 Framework of Q-learning in the access control system
定义向量

则系统的状态向量可表示为
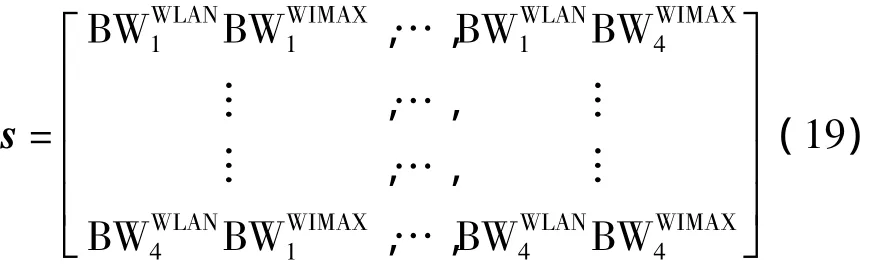
对于每个状态st都有一系列可用动作A={a1,a2,…,ak},每个可用动作代表选择一个子网络.因此,此算法不仅可以用于WLAN和WIMAX网络,还可以容易地被扩展到多个网络.Q学习算法的控制者执行一个动作然后计算回报rs(a).根据这个回报,控制者按照公式更新每个动作对应的Q值表.具体的Q学习步骤如下:
(1)初始化Q值表.
(2)在每个新呼叫到达时:①在动作集选择可用动作并记录该动作;②在用户到达时间记录系统状态st时,在执行动作后记录下一状态st+1.
(3)当异构网络状态变化后,计算立即回报rs(a).
(4)根据下式更新Q值:
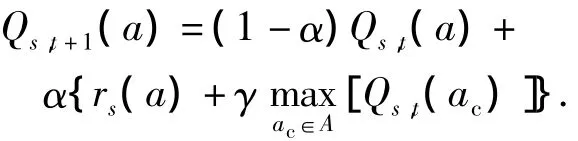
(5)令ΔQ(s,a)为Q值更新前后的值之间的差值.如果满足 ΔQ(s,a)< ε,∀s∈S,a∈A,则说明收敛条件满足;否则继续返回执行步骤(2)-(4).
4 算法验证与仿真分析
4.1 仿真环境
仿真考虑一个融合的WLAN/WIMAX系统,其包含一个WLAN网络和一个WIMAX网络.WLAN系统重叠覆盖在WIMAX系统之上.WLAN的基站AP的覆盖半径是100 m.物理层应用IEEE802.11b协议,平均比特速率是11 Mb/s,并且应用瑞利信道模型.信标间隔为20 ms;CFP的最大持续时间为15ms;物理层的时隙为9 μs.WIMAX基站与网络边缘的最远距离是1000m,物理层应用IEEE802.16e协议,支持的数据速率是24Mb/s.
学习因子α设置为0.1,折扣因子γ设置为0.95.这两个参数由经典的文献给出[16].对于18个用户进行考察,并假设用户在任意时间内必在WLAN或者WIMAX的覆盖范围内.假设WLAN/WIMAX融合网络的新呼叫服从泊松分布,平均到达速率为 .定义平均到达速率和一个呼叫的平均持续时间为话务强度.假设用户在WIMAX网络内平均分布,并且对于每个用户的移动模型应用经典的随机行走模型.类似地,WLAN中的所有用户位置也是随机分布的.基于蒙特卡洛进行仿真.
4.2 仿真结果
仿真比较了文中提出的Q学习算法与文献[10]中提出的马尔科夫决策(MDP)算法的性能.
图3(a)、3(b)分别给出了语音和数据呼叫业务的阻塞率随呼叫到达率的变化趋势.可以看到随呼叫到达率的增大,业务阻塞率随之增大.这是由于,呼叫到达率越大,被占用的网络资源越多,因此越容易发生阻塞.并且,Q学习算法的阻塞率性能明显优于MDP算法,在到达率高时,Q学习算法的优势更加明显.这是由于在到达率低时,网络内用户少,可用资源充足,两者都能保持较低阻塞率,随着用户到达率的增大,由于Q学习算法考虑了更加符合实际的、也是更重要的系统能力测量参数,而且Q学习算法的自我学习的性能使其能够更好适应网络动态变化,从而能够获得更低的阻塞率.

图3 呼叫阻塞率随用户呼叫到达率的变化曲线Fig.3 Call blocking probability curves with the arrival rate
由图3还可以看出,呼叫阻塞率达到稳定后,语音业务的阻塞率大于数据业务的阻塞率,这是由于给语音和数据业务分配了不同的排队模型.由于语音业务用户通常在呼叫发生阻塞后将不会等待,所以没有给语音用户建立排队模型,即语音用户在呼叫得不到服务后会立即离开网络;对数据业务用户则采用M/M/n排队模型,因此其稳态阻塞率会比语音用户低.
图4为系统获得的总折扣回报.很明显可以看出,Q学习算法都能够获得比MDP算法更大的总回报,其原因是Q学习算法能够更精确地反应系统的状态,从而做出准确的接入决策.另外,由于Q学习算法具有自学习能力,其能够随环境变化而自适应地变化接入策略,因此,应用Q学习算法能够接入更多的用户,并且同时保证业务的QoS.两条曲线平直的原因是仿真中每次仿真设置的用户数是一样的,所以在算法收敛后,取得的回报是相等的.这也说明,回报的大小和到达率是没有关系的,只和应用的算法和仿真次数有关.

图4 总折扣回报随用户呼叫到达率的变化曲线Fig.4 Total discount reward curves with the arrival rate
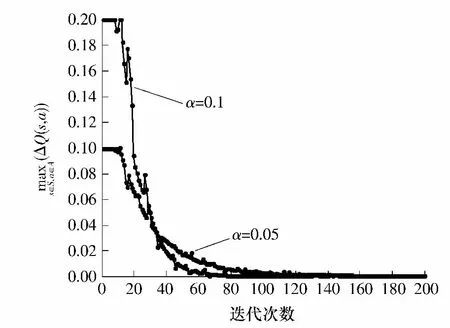
图5 学习因子α对收敛性指标ΔQ(s,a)的影响Fig.5 Influence of learning parameter α to convergence performanceΔQ(s,a)
5 结论
提出一种不受模型约束的Q学习方法,用以解决WLAN/WIMAX异构网络中的接入控制问题.算法从一个新的角度分析了WLAN和WIMAX两种网络的状态,从而能够更加符合实际的反应网络的负载能力变化,为Q学习算法提供更加精确的底层参数.系统应用值迭代的思想逼近Q值,从而获得了使系统总回报达到最大的最优策略.仿真结果表明,所提出的Q学习算法比传统的基于MDP的算法能够获得更高的期望总回报和更低的呼叫阻塞率.
[1]Lu Ke-jie,Qian Yi,Guizani Mohsen,et al.A framework for a distributed key management scheme in heterogeneous wireless sensor networks[J].IEEE Transactions on Wireless Communications,2008,7(2):639-647.
[2]Lai Yen-cheng,Lin Phone,Cheng Shin-ming.Performance modeling for application-level integration of heterogeneous wireless networks[J].IEEE Transactions on Vehicular Technology,2009,58(5):2426-2434.
[3]Angoma Blaise,Erradi Mohammed,Benkaouz Yahya,et al.HaVe-2W3G:averticalhandoffsolutionbetween WLAN,WiMAX and 3G networks[C]∥International Wireless Communications and Mobile Computing Conference.Istanbul:IEEE CS,2001:101-106.
[4]Zhai Hong-qiang,Chen Xiang,Fang Yu-guang.How well can the IEEE 802.11 wireless LAN support quality of service?[J].IEEE Transactions on Wireless Communications,2005,4(6):3084-3094.
[5]Nie Jing,Wen Jiang-chuan,Dong Qi,et al.A seamless handoff in IEEE 802.16a and IEEE 802.1 in hybrid networks[C]∥International Conference on Communications,Circuits and System.Hong Kong:IEEE CS,2005:383-387.
[6]Lee SuKyoung,Sriram Kotikalapudi,Kim Kyungsoo,et al.Vertical handoff decision algorithms for providing optimized performance in heterogeneous wireless networks[J].IEEE Transactions on Vehicular Technology,2009,58(2):865-881.
[7]Zhang Wen-hui.Handover decision using fuzzy MADM in heterogeneous networks[C]∥Wireless Communications and Networking Conference.Atlanta:IEEE Inc,2004:653-658.
[8]Stevens-Navarro Enrique,Wong Vincent W S.Comparison between vertical handoff decision algorithms for heterogeneous wireless networks[C]∥IEEE 63rd Vehicular Technology Conference.Melbourne:IEEE Inc,2006:947-951.
[9]Gelabert Xavier,Perez-Romero Jordi,Sallent Oriol,et al.A Markovian approach to radio access technology selection in heterogeneous multiaccess multiservice wireless networks[J].IEEE Transactions on Mobile Computing,2008,7(10):1257-1270.
[10]Yu Fei,Krishnamurthy Vikram.Optimal joint session admission control in integrated WLAN and CDMA cellular networks with vertical handoff[J].IEEE Transactions on Mobile Computing,2007,6(1):126-139.
[11]Venkatesh T,Kiran Y V,Murthy C S R.Joint path and wavelength selection using Q-learning in optical burst switching networks[C]∥IEEE International Conference on Communications.Dresden:IEEE Inc,2009:1-5.
[12]IEEE 802.11 WG,Part 11:Wireless LAN medium access control(MAC)and physical layer(PHY)specifications.IEEE Standard[S].
[13]IEEE 802.16 WG,Part 16:Air interface for fixed broadband wireless access systems.IEEE Standard [S]
[14]Saker L,Ben Jemaa S,Elayoubi S E.Q-learning for joint access decision in heterogeneous networks[C]∥IEEE Wireless Communications and Networking Conference.Budapest,Hungary:IEEE CS,2009:1-5.
[15]Zhang Dong-mei,Ma Hua-dong.A Q-learning-based decision making scheme for application reconfiguration in sensor networks[C]∥International Conference on Computer Supported Cooperative Work in Design.Melbourne:IEEE CS,2007:1122-1127.
[16]Nasri Ridha,Altman Zwi,DubreilHervé.Optimal tradeoff between RT and NRT services in 3G-CDMA networks using dynamic fuzzy Q-learning[C]∥The 17th Annual IEEE International Symposium on Personal,Indoor and Mobile Radio Communications.Helsinki:IEEE Inc,2006:1-5.
