自然语言处理中的语义消歧研究
2013-08-15贾媛媛
贾媛媛
(淮南师范学院 数学与计算科学系,安徽 淮南 232038)
1 简介
自然语言处理(又叫自然语言理解,计算语言学)是当前IT领域的重要技术之一。随着互联网信息的急剧增长,搜索引擎成为人们获取信息不可缺少的工具。但是基于关键字索引的工具已经越来越无法满足用户的需求,相反用户更希望计算机能理解句子的意思以帮助我们更好地处理信息和组织信息,这就需要自然语言处理技术来解决,例如中文分词、词性标注、句法分析、依存关系分析、语义消歧等等。要真正理解句子的含义,这些最基本的处理是必须的。
语义消歧是比分词、词性标注、句法分析更高级的自然语言处理技术,但面临的困难也更大。例如,“我是她的粉丝”,要理解这句话,首先必须对句子进行分词和词性标注,得到这样的结果“我/代词 是/动词 她/代词 的/助词 粉丝/名词。 /句号”。其次需要对这句话做句法分析,也就是说必须让计算机知道,这句话的主要成分是“我是粉丝”,“她的”是用来修饰和限定“粉丝”的。然后从语义的角度上分析,“我”是人,人不能是“粉丝”,因此这里“粉丝”应该指的是网络用语中的“粉丝”,意思是“fans”。这样这句话所要表达的意思就比较清楚了。
语义消歧通常指根据一个词所处的上下文来判断这个词在这个上下文中的意思。语义消歧是自然语言处理的重要方面,很多现实的应用都必须以语义消歧为基础。
语义消歧的方法大致分为四个类别,即基于背景知识的语义消歧、监督的语义消歧方法、半监督的学习方法和无监督的学习方法。
2 基于背景知识的语义消歧
基于背景知识的语义消歧方法,就是建立在一个已有的背景知识库上的方法。这种背景知识库通常是一种人工建立的可被计算机读取的字典,这个字典通常具有一个有向图结构,其中每个节点代表一个概念,每个概念包含了能够表示此概念的所有的词(同义词集),因此,词与概念之间的关系是多对多的关系,即一个词可以对应多个概念,一个概念又可以对应多个词。每个概念的父节点是比此概念更一般的一个概念,它的子节点则是比它更特殊的概念。
2.1 概念之间的相似度
在MRD的基础上,很多工作都是考虑如何衡量两个概念之间的相似度。例如下面是一个常用的衡量标准①Claudia Leacock and Martin Chodorow.Filling in a sparse training space for word sense identification.ms.,March 1994.,其中Path(C1,C2)是概念C1和C2在一个语义网中的路径,D为这个语义网络的最大深度。可以看出,两个概念在语义网中距离越近,那么它们相似度越高。

除此之外,还有很多其它的相似度量法,如[Resnik 1995]中,作者用信息容量(Information Content)来定义两个概念相似度,即:
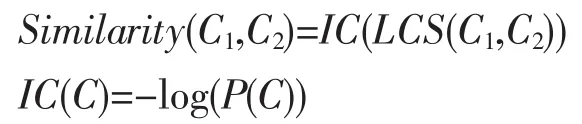
其中,LCS(C1,C2)为能够包含这两个概念的上意概念(Least Common Subsumer),也即这两个概念在语义网中对应节点最接近它们的共同父亲节点;IC(C)即概念C的信息容量,直观讲,一个概念越频繁,那么它的信息量越少。
2.2 选择倾向(Selectional Preference)
选择倾向是定义词用法的一种简化方式,例如:我们常说“喝可乐,喝中药,喝酒,喝水”,其实我们有一种对“喝”这个词用法的定义,即喝后面通常跟可食用的液体,这样我们就知道“可乐”这里指的是一种饮料。也就是说如果使用选择倾向来帮助我们做语义消歧可以很大程度提高消歧的准确率。那么如何得到这些选择倾向呢?直接从人标注的语料库中得到这样的知识,像“可乐”这样的词已经被人工标注了它的正确义项,通过语料库,我们把“可乐”,“水”,“酒”都归属于“饮料”这个概念,而“中药”,“口服液”等则归属于“药水”,这样可以得到两个选择倾向:喝[饮料],喝[药水]。 当然,也可将“饮料”,“药水”上升到“液体”,从而得到:喝[液体]。选择倾向实际上是一种词和概念(Word-to-Class)的搭配,所以可以设定一个阈值,当一个词和概念对的度量达到这个阈值时,就可以认为是一个选择倾向配。
2.3 双语对齐语料的利用
另外,利用双语对齐的语料库也可以建立一个标注语料库。有时一个有歧义的词,当知道了它对另外一种语言的翻译时,就知道它的义项。如“可乐”一词在某个句子中如果它的英文翻译是Cola,而Cola本身是没有歧义的,那么我们就可以用Cola的义项来标注“可乐”,这样就得到一个标注的语料库②William A.Gale,Kenneth W.Church and David Yarowsky.A Method for Disambiguating Word Senses in a Large Corpus.Computers and the Humanities.pp.1-30.1992.。
3 有监督的语义消歧
一般来说,监督学习(Supervised Learning)的方法也就是数据的类别在学习之前已经知道。在语义消歧的问题上,就是说每个词所有可能的义项都是已知的。有监督的语义消歧方法通过一个已标注的语料库学习得到一个分类模型。
在此框架下,剩下的主要问题就是如何选择能够比较好地区分词的不同语义的特征。人们理解一个词的真正意义,通常是根据这个词所处的上下文来判断。而在现有技术中,提取特征的方法也是根据这个原则进行的。例如,目前语义消歧常用的特征包括:Co-occurrence,词语搭配(Collocation),NGram,词性(Part-Of-Speech),predicate-argument,动宾结构,主谓结构等。同时,为了避免大量跟当前词没有关系(如距离较远)的词影响消歧结果,提取特征通常被限定在一个固定的窗口大小内。
4 无监督的语义消歧
无监督的语义消歧主要是通过对每个词所处的上下文环境来将相同意义的词聚类到一起。也就是说这种方法假设具有相同上下文的词将具有相同或者类似的意义③David Yarowsky.Unsupervised word sense disambiguation rivaling supervised methods.Proceedings of the 33rd annual meeting on Association for Computational Linguistics(ACL'95).pp.189-196.1995.。无监督方法不借助任何背景知识,即这种方法事先并不知道每个词可能具有哪些不同的意思,因此,这种无监督的方法也并不给同一个聚类一个语义标签。这种方法仍然采用监督学习方法里面表示每个词的方法,即向量空间模型。因此,只要是基于VSM的所有聚类算法也都适用于无监督的语义消歧。另外,聚类方法对于建立选择倾向也有帮助作用。
5 半监督的语义消歧
半监督的方法介于监督和无监督方法之间,它不需要人工标注大量的语料库,而是通过一些标注的样例作为种子集合,通过一种迭代的方式来不断地扩展这个集合,如Self-Training,Co-Training以及Bootstrapping的方法都属于此类①Rada Mihalcea,Paul Tarau and Elizabeth Figa.PageRank on Semantic Networks,with Application to Word Sense Disambiguation.Proceedings of the 20th International Conference on Computational Linguistics(COLING'04).2004.。
半监督方法可以很好地缓解数据稀疏的问题,但这种迭代的方法很容易引入一些错误的样例(噪声),错误的积累最终导致此方法的性能也无法达到令人满意的程度。关于如何建设大规模标注语料库,可参考②Jin Peng,Wu Yunfang,Yu Shiwen.Survey of Word Sense Annotated Corpus Construction.Journal of Chinese Information Processing.22(3):16-23.May,2008.。
6 讨论与展望
我们可以看到现有的工作使用了各种机器学习方法以及各种有用的特征,然而究竟哪些方法和那些特征具有较好的效果呢?在③Yoong Keok Lee and Hwee Tou Ng.An Empirical Evaluation of Knowledge Sources and Learning Algorithms for Word Sense Disambiguation.Proceedings of the ACL-02 conference on Empirical methods in natural language processing(EMNLP'02).pp.41-48.2002.中,作者比较了几种较流行的机器学习方法,包括SVM,朴素贝叶斯,AdaBoost和决策树。实验结果表明SVM方法得到了最好的效果,其次是朴素贝叶斯。其中WSD问题本身存在严重的数据稀疏问题,而在很多稀疏问题上,SVM和朴素贝叶斯都有比较好的表现。
要更好地解决WSD问题,有两个方法可以做,一是标注大量的数据集,二是建立一套完善的背景知识。对于“完善的背景知识”主要是指能够反映每个词在不同场合的用法的定义,这个思想类似于选择倾向,但比选择倾向更加具体。例如,对于喝,可以定义喝[可饮用的液体],而同时,如果其他的概念(concept),具有[可饮用的液体]属性的,就可以与喝搭配。那么对于一个词,如“可乐”,如果具有两个不同的义项,其中一个具有[可饮用的液体]的属性,另一个不具有,则当“喝”在“可乐”之前出现时,就可以很容易判断“可乐”的义项。但是当前的选择倾向都是通过统计的方式获得,这就导致了这种用法的过于一般性和不完善性。一个更好的关于词的“用法”的词典应该由人工来完成,然后将这样的词典作为有用的背景知识库。
另外一方面,在进行WSD之前,必须很清楚地知道句子的组成方式,也就是说必须知道哪个词修饰哪个词,而区分一次词的义项通常只由修饰它的词或者它修饰的词决定。例如,句子“他在喝可乐”,判断“可乐”义项时,应该通过“喝”判断,而不应该通过“他”来判断,否则会得到完全不同的结果。因此,WSD需要更精确地划分句子成分(Syntactic Parsing)。
最后,很多词的用法比较相似,尤其是一些可以互相替换的同义词,如果能够找到这样一些用法相似的词,一方面在缺乏背景知识情况下,这些词可以缓解数据稀疏的问题。例如④Dekang Lin.Using Syntactic Dependency as Local Context to Resolve Word Sense Ambiguity.Proceedings of the 35th Annual Meeting of the Association for Computational Linguistics.pp.64-71.1997.中,作者利用所有相似词,而不是单一词作为训练集,来训练监督的语义消歧方法。在⑤Peng Jin,Xu Sun,Yunfang Wu and Shiwen Yu.Word Clustering for Collocation-Based Word Sense Disambiguation,Proceedings ofthe InternationalConference on IntelligentTextProcessing and Computational Linguistics(CICLing'07),LNCS4394.2007.pp.267-274.中,作者通过聚类方式得到相似的词。另一方面,这种处理方式也可以辅助人工进行背景知识库的建立。
