基于模糊聚类的海水水质监测技术研究
2013-08-14陈嵩张钢
陈嵩,张钢
(1.国家海洋局天津海水淡化与综合利用研究所 天津 300192;2.天津大学 计算机科学与技术学院 天津 300072)
海水水质监测使用统一的、可比的采样和检测手段,获取海水质量要素,判断海水元素含量比例,为保护海洋环境提供一定帮助(袁道伟等,2011)。据《2012年中国海洋环境状况公报》,我国海域海水环境状况总体较好,符合第一类海水水质标准的海域面积约占我国管辖海域面积的94%;近岸以外海域水质总体良好并保持稳定;沉积物质量状况总体良好,96%以上站位符合第一类海水沉积物质量标准。部分近岸海域污染依然严重,未达到第一类海水水质标准的海域面积为17万km2,高于2007-2011年15万km2的平均水平。海水水质为劣四类的近岸海域面积约为6.8万km2,较上年增加了2.4万km2,严重污染区域主要分布于大中型河口、海湾和部分大中城市近岸海域,主要超标物质是无机氮、活性磷酸盐和石油类。近岸约1.9万km2的海域呈重度富营养化状态。
近几年来,国家对海水水质监测也是在不断地增加投入,扩大海水监测规模(吕建华 等,2012),为全面掌握我国管辖海域水质状况,2012年,国家海洋局组织各级海洋行政主管部门对我国管辖海域水质实施监测,各级监测机构共完成约8 400个站位的监测工作,获得各类海水监测数据240余万个。
海水水质监测系统是一个集数据采集、无线传输、监测中心分析与显示的综合系统(宗荣发等,2011)。数据采集系统主要采用嵌入式技术将海水水质数据进行采集,无线传输主要是3G或者GPRS传输模式,监测中心将收到的数据通过数据预处理与聚类分析,判断数据的有效性并根据聚类分析结果提出预警或者解决方案,同时将监测结果在实时显示。海水水质监测数据项多,而且反馈次数多,因此,在一定时间内,海水水质监测数据量将积累到一定程度,在海量的数据中挖掘出有效的预警信息具有一定难度,本文研究正是建立在此背景下,通过数据挖掘的方法对海水水质数据进行分析,以便更好地在纷繁的数据中提取有价值的信息。
模糊聚类特别适用于对大规模数据分析,用模糊理论完成数据分析和建模,其中模糊C均值聚类算法(FCM)能够实现自动对数据样本进行分类,应用最广泛。而考虑到FCM的应用对象必须是完整的数据样本,适用条件苛刻,本文针对这一不足,对该算法进行适当改进,提出基于不完整数据样本的FCM算法,该算法的适用条件相对宽泛,而且具有效率高的优点,本文详细分析了不完整数据样本的FCM算法,并运用该算法实现对赤潮的聚类分析,这将为赤潮预警提供一定的帮助。
1 海水水质数据分析
海水水质监测主要是对海水的温度、盐度、PH值、溶解氧、氮、磷、钾、氨等元素含量进行监测,在入海口还要对工业元素进行抽样检测,确定入海口的排污是否能够达到海水环境质量要求(董超群等,2011)。海水水质数据项多且复杂,难以根据某一项元素来判断海水的质量,因此必须对监测数据进行一定的聚类与关联分析,判断所有元素项影响下的环境特征。监测海水水质的某一项因素并不能说明具体问题,而多项海水水质数据需要经过聚类分析来对海水水质问题进行定性分析,分类算法可以确定水质的优良等级,而聚类算法则是将海洋水质监测的多项数据进行聚类,由聚类结果判定当前水质的情况,比如赤潮。
从整个海水水质数据监测系统来说,主要包括数据监测系统、无线通信系统和监测中心数据分析系统(李超等,2011),本文主要对监测中心数据分析系统做简要介绍,具体如图1所示。

图1 海水水质监测结构图
数据采集设备将海水元素进行监测得到数据,然后将数据、监测地的GPS数据和监测地属性数据一同以无线的方式传给监测中心,监测中心获得监测地的海水水质监测数据后,结合聚类分析及专家系统,并将分析结果以多媒体、报表、图标或绘图的方式进行输出。本文将着重对海水水质监测数据的聚类分析进行研究,旨在提高海水水质监测数据的聚类效果。
2 模糊聚类FCM算法及其改进
2.1 模糊C聚类均值算法FCM
设监测样本集合X={x1,x2,…xn}⊂Rs。为模式空间中n个模式的一组有限样本集,其中xk={xk1,xk2,…xks}T∈Rs为其中的一个数据样本,xkj为样本xk的第j个指标的监测值(王伟等,2012)。
样本xk与子集 {xi}(1≤i≤c)的隶属关系用uik=uxi(xik)(uik∈[0,1]来表示,为了记录多个子集的隶属函数,采用矩阵的方式来完成,记作。U=[uik]c×nX的模糊C划分空间Mfc:

其中聚类原型模式P={p1,p2,…pc},pi(i=1,2,…c)表示第i类的类中心,pi∈RsFCM算法的计算过程是在保证目标函数Jm最小的同时,求解划分矩阵U=[uik]c×n与聚类原型P={p1,p2,…,pc}的过程(樊东红等,2012;杨静等,2011)。Jm的计算表达式为:
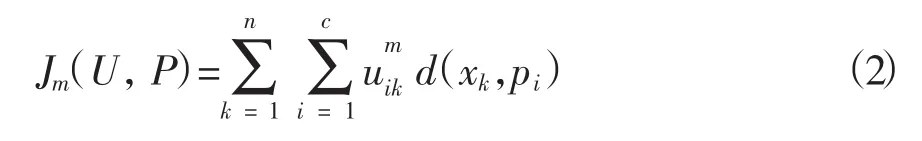
迭代规则公式如下:

FCM算法的具体流程图如图2所示。

图2 FCM算法流程图
其中n表示样本个数,ε为迭代停止阈值。从算法流程图明显可知,整个算法的时间复杂度主要集中在划分矩阵和聚类原型模式矩阵的求解,归根结底,影响算法效率的因素是样本个数n,n的个数影响划分矩阵和聚类原型模式矩阵求解的效率。
2.2 FCM缺点
传统的FCM聚类算法是对完整数据样本进行聚类分析,即 X={x1,x2, …xn} ⊂Rs,xk={xk1,xk2,…xks}T∈Rs,xk(k=1,2,…,n) 的每一维特征都有一个确定的取值。但是对于实际应用而言,一般样本的数据量很大,且要保证整个数据库的完整具有一定难度,而且可用的样本可能也会有丢失值。在这种情况下,就无法直接使用传统FCM聚类算法对数据样本进行聚类分析。而且上节也提到,样本个数n会影响算法效率,当样本个数较大时,FCM的算法的效率会下降,是需要改进的地方。基于不完整数据样本集合的模糊C均值聚类算法,它是对传统FCM聚类算法的一种改进,既解决了样本丢失的不完整数据样本的模糊聚类,又在一定程度上提高了聚类算法的效率。
2.3 基于不完整样本的模糊C聚类均值算法
上一小节提出了传统FCM的缺点,对样本的完整度要求高,缩减了FCM算法的适用范围,当前对不完整样本的聚类处理,主要是丢弃不完整样本集,这种方法的精确度低,本文对传统FCM算法进行改进,较好地满足了不完整样本集的模糊聚类。
定义一 不完整数据样本集合为XA={x1,x2,…xn}⊂Rs,xk=(xk1,xk2,…xks)∈Rs。样本集合XA的子集 XW和 XP,其中 XW={xk|xk∈XA,1≤i≤n},且xk是一个完整的数据样本,XP={xi|xi∈XA,1≤i≤n},且xi是一个不完整的数据样本,XW∩Xp=φ,XW∪XP=XA。特征值集合 XM={xkj|xkj=?1≤j≤s},1≤k≤n},XU={xkj|xkj=确定值,1≤j≤s,1≤k≤n,XM∩XU=φ, |XM|+|XU|=|XA|,||表示集合中元素的个数。
定义二 数据样本XA的完整率η:

定义三 数据样本xk对聚类分析的影响因子ak

定义四 数据样本xi与xj之间的相似度βij:

基于不完整数据样本的模糊C聚类均值算法对传统的FCM改进的核心思想是聚类分析计算方法视样本集合完整率而定。如果值高,则按照现在主流处理方式,删除有丢失值的样本,利用FCM计算;如果值低,根据定义四,由样本相似度之间的关系,将丢失的样本值补齐,然后参照传统FCM计算。该算法的基本流程图如图3所示。

图3 基于不完整数据样本的模糊C聚类均值算法
在进行聚类运算之前,必须先计算样本不完整率,选择运算方法。与传统FCM的迭代规则不同,基于不完整数据样本的模糊C聚类算法采用的迭代规则是:

3 实例仿真
近年来,由于大量工农业废水和生活污水排入海水,特别是未经处理直接排入而导致近海、水生生物特别是藻类将大量繁殖,使生物量的种群种类数量发生改变,破坏了水体的生态平衡港湾富营养化程度日趋严重,海水开发、水产业带来了海水生态环境和养殖业自身污染问题(胡建华等,2011),2012年以来,全海域共发现赤潮73次,累计面积7 971 km2。正是因为赤潮问题严重,对近海的水质监测成为了今年来的研究热点,如何有效地利用海水水质监测数据来预测赤潮发生,减少损失,本文将采用基于不完整样本的模糊聚类算法实现海水数据的聚类,分析赤潮产生的概率。
在海水水质监测系统中,由于赤潮产生的与很多因素有关,需要监测的数据较多(高素兰,1977),本文监测的因素共有16个,分别是海水温度、盐度、PH值、三氧化硅(SiO3)、溶解氧(DO)、卤素(ChA)、铵根(NH4)、化学需氧量(COD)、磷酸根(PO4)、二氧化氮(NO2)、三氧化氮(NO3)、氨(NH3)等含量,这些元素都通过放置在海里的传感器采集而得,传感器采集得数据通过无线网络的方式传递到监测中心,本文将不再详述整个海水水质数据的采集过程,利用公共数据库的监测数据作为实验仿真的数据来源,记录形式如表1所示。
为了在海水赤潮发生之前成功预警,需要运用上表中记录的海水水质数据,并对这些数据进行有效分析,本文中采用模糊聚类的方法,考虑到海水水质监测数据量大的情况,且在无线网络传输中,偶尔有数据漏传和传错的情况,采用不完整样本进行模糊C聚类均值算法完成数据聚类。从公共数据库中随机抽取100个样本作为聚类来源。
文本采用VC++6.0作为实例仿真的软件平台,并运用MFC来实现聚类结果的显示,编写程序,生成运行程序FCM.exe。在聚类参数中输入16个监测因素的值,参考FCM算法流程,设置相应参数,将类别数c设置为2,权重指数m设置为2,迭代阈值设置为0.01,然后点击“聚类”按钮,显示结果如图4所示。

表1 海水水质监测数据表

图4 仿真结果图
如图4所示,坐标系中横轴表示赤潮发生几率,聚类分析结果都集中在离原点处不远的位置,赤潮发生的概率并不大,海水水质数据正常范围之内。监测数据样本是不完整的数据样本,而采用模糊C聚类分析能得到较好的效果,表明基于不完整数据样本的FCM算法能较好地完成不完整数据样本的聚类分析。
4 结语
本文采用基于不完整数据样本的模糊C聚类均值算法对海水水质监测数据进行聚类分析,实现海水灾害的预警。先对传统FCM算法流程进行说明,分析了其聚类的数据样本必须为完整数据样本的缺点,提出了基于不完整数据样本的FCM算法,经实例验证,该算法在处理不完整数据样本的聚类中,具有优良的特性,适合对海水水质监测数据的聚类分析。
董超群,洪波,秦明慧,等,2011.动态Web在海洋环境监测系统中的应用.科学技术与工程,(19):4559-4563,4567.
樊东红,曾彦,王明娟,2012.FCM算法在钦州湾不同时期水质预测中的应用.中南林业科技大学学报,(11):158-162.
高素兰,1997.营养盐和微量元素与黄骅赤潮的相关性.黄渤海海洋,(2):59-63.
胡建华,卢美,王晶,2011.创新海水灾害预警报服务方式探索与实践.海水预报,(2):78-82.
李超,王项南,司惠民,等,2012.软开关技术在海洋环境监测系统供电中的应用.海水技术,(3):85-90.
吕建华,高娜,2012.整体性治理对我国海洋环境管理体制改革的启示.中国行政管理,(5):19-22.
王伟,刘娟,孟志斌,等,2012.卫星云图的多通道FCM分割算法.计算机工程与科学,(10):83-87.
王兴强,刘长兴,刘国伟,等,2012.改进的CSFCM聚类算法及其在赤潮监测中的应用.计算机工程与应用,(8):233-235.
杨静,周惠群,姜兴长,等,2011.改进的FCM自动化建模方法.计算机工程与应用,(33):232-235.
袁道伟,关道明,张燕,等,2011.海洋环境影响报告书质量评估初探.海水环境科学,(3):440-442.
宗荣芳,田锦明,2011.基于虚拟仪器技术的海水水质监测系统设计.仪表技术与传感器,(9):41-43.
