复杂地理计算并行算法性能评估技术研究
2013-08-08方金云闵伟陈翠婷李栋宾
方金云,闵伟,陈翠婷,李栋宾
(1.中国科学院计算技术研究所,北京 100190;2.重庆大学软件学院,重庆 401331)
0 引言
随着对地观测技术的飞速发展,地理信息系统(GIS)正呈现出数据海量化、应用广泛化、处理实时化的特点。为满足这些需求,必然需要更强大的数据存储和计算能力,因此,需要借助于高性能计算来解决这类问题[1]。地理计算既是数据密集型计算又是计算密集型计算,同时地理数据具有空间相关性的特点。因此,高性能地理计算与面向计算密集型的并行计算和面向数据密集型的分布式计算既有区别又有联系。同一地理计算算法从设计到实现,依赖程序设计和实现者的能力,程序的性能千差万别;同时由于并行程序在执行过程中的复杂性及不可预见性,给并行程序的调试和优化带来了困难。因此并行程序开发人员迫切需要一套调试评测工具,以发现并行程序性能的瓶颈和热点,为地理计算算法并行开发提供程序设计、实现和优化指导。
国内外已经开发出一批用于并行程序进行分析及调试的性能评估工具,这些工具各有优势和不足[2],有些关注于工具的可扩展性[3],有些关注于更快的性能分析[4]。例如美国伊利诺斯大学开发的ParaGraph[5],提供了20多种通用视图,包括饼状图、柱状图和通讯流量图等;美国威斯康星大学麦迪逊分校开发的Paradyn[6]通过W3模型实现,可以提供对性能问题的自动查找,通过预设的可能性能问题,逐一判断并验证定位性能问题;Scalasca[7]的一个明显优点就是具有良好的可扩展性;HPCToolkit[8]是一个可以对串行程序和并行程序进行性能评估的工具。国内在性能可视化方面做了一些工作[9,10]。以上都是针对高性能计算的性能评估工具,主要面向计算密集型的计算,而地理计算既是计算密集型又是数据密集型的计算,因此本文主要对复杂地理计算并行算法性能评估工具中涉及的关键技术进行研究。
1 性能评估工具技术架构
1.1 性能评估工具架构
本文性能评估工具架构(表1)主要由代码插桩模块、事件搜集(监测)模块及展示模块组成。MPI[11]程序源代码在经过编译插桩和PMPI库链接后生成可执行程序,在程序运行过程中会对事件信息进行管理,同时收集每个进程及线程的信息,每个事件的定义将会在主进程中统一。在事件分析过程中,采用并行模式搜索和串行模式搜索同时进行的方式可减少事件分析的时间,通过预先定义的事件模式计算性能信息,如通信时间、函数运行时间、通信量等。最后评估工具读取性能分析文件,可视化性能信息、性能指标提供交互操作的浏览方式,选择某一性能问题,可以展示该问题出现的代码位置、函数调用层次结构、所属进程,整个系统运行的流程如图1所示。

表1 评估工具架构Table 1 Architecture of the evaluation tools
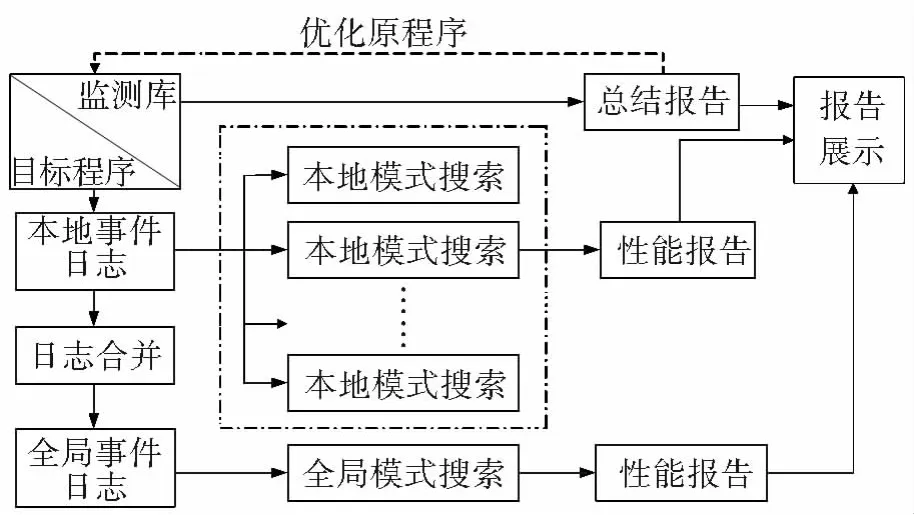
图1 性能评估流程Fig.1 Flow diagram of performance evaluation
1.2 代码自动插桩
本性能评估工具采用事件跟踪的方法,即静态地插入事件监测函数到应用程序源代码中,运行时采集关心的事件,运行后根据产生的事件跟踪文件进行性能分析。它可以自动对所评估的程序结构插入性能检测库函数,通过编译、链接,生成可执行文件,性能监测函数记录程序执行的事件,最后根据这些事件跟踪文件进行性能数据分析。
1.3 运行监测及事件收集
被评测的程序和测量库编译在一起,形成可执行文件。在程序运行过程中,产生本地事件日志,此时分为2个步骤,一方面在机器本地进行并行模式搜索,寻找程序热点,生成模式分析报告;另一方面本地事件日志在主节点进行合并,生成全局事件日志,再对其进行模式搜索,生成模式报告。最后对两份模式分析报告进行合并,通过评测工具展示,生成的报告指导原程序进行优化。评测工具生成的事件日志还可以经过转化,以便第三方事件查看软件查看。
1.4 性能日志数据分析展示
对生成的性能日志数据进行可视化展示,显示被评估程序的性能特征,例如:执行时间、通信操作数、同步操作数、通信量、负载平衡指数等。同时对每个被选中的性能特征,展示更加精细化的特征,如选择可执行时间,展示该可执行时间由哪些函数及操作构成,每个函数和操作各占用多长时间。通过这种方法可以找出程序哪部分执行时间最长,哪部分是性能瓶颈。性能特征采用树状图的展示方式,如通讯这一指标下面有点到点通讯、搜集通讯,点到点通讯下面有发送操作和接收操作,搜集通讯下面有交换操作,作为源操作和目的操作。树状图把性能问题表现得更加直观。
2 性能评估工具关键技术
2.1 性能数据采集技术
性能数据采集是性能评估的第一步,它通过采集、事件跟踪等方法收集有关的性能数据,作为分析的依据。采样是以一定的采样周期对所关心的系统性能数据进行记录,事件跟踪是由所关心的系统事件触发跟踪机制,记录事件发生时的性能数据。采样法容易产生大量的性能数据,适合用硬件实现。事件追踪可以只记录敏感事件的有关性能信息,数据量小于采样法,使用更加灵活,故本文采用事件跟踪法。
通过gcc的finstrument-functions编译选项完成对函数的插桩,从而在进入函数时调用:void__cyg_profile_func_enter(void*this_fn,void*call_site);在函数退出时调用:void__cyg_profile_func_exit(void*this_fn,void*call_site);获取函数执行时间、函数调用关系;对于MPI程序,利用MPI库的包装器PMPI获取MPI操作的通讯数、通讯量等信息。
2.2 降低采样干扰技术
事件追踪法采用代码插桩的方法,但代码插桩会改变程序原有的行为特征,干扰程序的正常运行。目前降低干扰的方法有:1)对干扰量进行控制,在干扰插入和记录事件信息时,根据干扰量对插入代码进行动态调整,尽量减少对程序的影响;2)用硬件实现对性能数据的搜集,这种方法可以显著减少对程序的干扰,但是受制于硬件条件。本文主要采用第一种方法,同时通过补偿机制减少代码插桩对原程序的影响。
2.3 性能日志并行分析技术
性能日志数据经常达到几个G甚至几十G[12],产生如此巨大的性能日志数据的原因可以归结为:1)进程数。随着进程数的增加,性能日志数据总量随之增加,同时通讯操作数及同步操作也随之增加。2)粒度。事件的多少取决于单位时间内事件被产生的频率。3)事件参数。一个事件的典型参数是进程ID、时间戳、类型ID,此外还有很多特定参数。4)问题规模。一个典型的例子就是迭代数,随着迭代数的增加,问题的执行时间和事件数也随之增加。
事件跟踪数据指向源代码区间、调用路径和通讯操作等。为了减小跟踪数据的存储空间以及减少冗余事件,用标示符ID表示对象。为了避免不同进程之间的额外通讯,每个进程可能使用不同的标示符ID表示相同的对象。然而,在对程序行为进行全局分析时,必须使用全局的对象ID,具有不同ID的相同本地对象必须被同一个全局对象ID替代,这个过程称为归一化。
每个进程都有独立的收集缓冲区用来存储本地的事件跟踪数据以及本地对象定义,这样可以避免合并事件跟踪数据之后再重新提取上述信息。当程序的测量阶段结束之后,每个进程轮流发送自己的本地对象定义以及相应的对象ID映射信息表给主进程,主进程把本地对象定义归一合并成一个全局对象定义。主进程把合并之后的ID映射信息表再发回给每个子进程,子进程利用全局ID映射信息表生成本地分析报告。
被评估程序在运行过程中在本地产生性能数据,存放在本地内存中,当本地计算任务完成时,可以利用该进程对本地内存中的性能数据进行分析,生成的结果发送给主进程,减少主进程对该部分性能数据进行分析的工作量。同时有些分析必须等本地性能数据被合并成一个全局性能数据后才能进行分析,所以每个进程还要完成本地性能数据发送给主进程的任务。主节点在等到所有从节点的性能数据后,将所有性能数据合并,然后进行性能数据的串行分析。通过每个从进程并行分析本地性能数据的方法,可极大减少主进程的工作量,从而减少性能分析时间。
3 实验分析
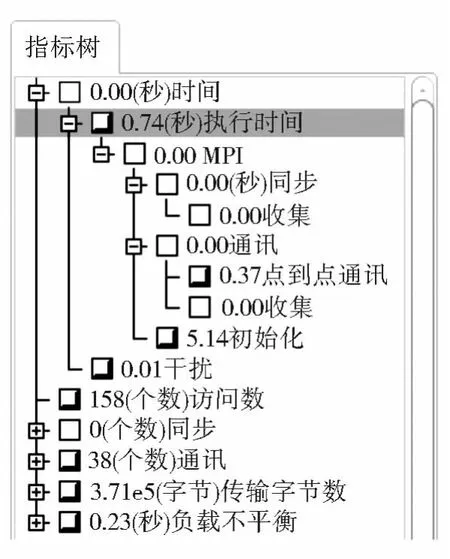
图2 缓冲区分析的性能评测局部视图Fig.2 The local view of performance evaluation of the buffer analysis
对超过40M的中国城市点数据集进行并行缓冲区分析,运行4个MPI进程,生成的性能数据展示图如图2所示。通过查看图2缓冲分析的性能评测结果可知程序运行过程中的详细情况。首先需要说明的是,该性能指标树中的时间是程序运行过程中MPI使用的所有进程的时间总和。例如该缓冲分析程序非MPI操作部分耗费了0.74s,但4个进程每个使用的时间分别为0.25s、0.22s、0.19s、0.08s。通过该图可知MPI的点到点通讯操作耗费了0.37s,初始化耗费了5.14s,总共有38次通讯操作,传输了371 000的字节数。实验证明该性能评测工具可以有效评测地理计算。
4 结论
本文介绍了针对复杂地理计算并行算法的性能评估工具及关键技术。通过在程序编译期间对函数进行插桩并链接监视库,对并行程序多进程之间的通讯信息及函数调用依赖关系进行捕获分析,形成性能评估报告帮助开发者分析和优化并行程序。目前基于编译器选项及PMPI性能检测库获取程序信息,通过并行技术分析大规模的性能日志。下一步要做的工作是进一步优化分析模块性能、进一步研究合适的评估模型及丰富性能数据可视化。
[1] 蔡蕾.地理计算并行处理技术及性能评价模型研究[D].国防科技大学,2011.
[2] MOORE S,CRONK D,LONDON K,et al.Review of Performance Analysis Tools for MPI Parallel Programs[M].Springer,2001.
[3] GEIMER M,WOLF F:Scalable parallel trace-based performance analysis[A].Proc.13th European PVM/MPI Conference[C].Springer,Heidelberg,2006.
[4] WOLF F,MOHR B,DONGARRA J,et al.Efficient pattern search in large traces through successive refinement[A].Proc.of the European Conference on Parallel Computing[C].2004.
[5] HEATH M,FINGER J.ParaGraph:A Performance Visualization Tool for MPI[D].University of Illinois,University of Tennessee,2003.
[6] MILLER B P,CALLAGHAN M D,CARGILLE J M.The Paradyn Parallel Performance Measurement Tool[S].IEEE Computer,1995.
[7] JULICH SUPERCOMPUTING CENTRE.Scalasca toolset for scalable performance analysis of large-scale parallel applications,http://www.scalasca.org/.2012-06-30.
[8] ADHIANTO L,BANERJEE S,FAGAN M,et al.HPCTOOLKIT:Tools for performance analysis of optimized parallel programs[A].Concurrency and Computation:Practice And Experence[C].2010.
[9] 林贻珀.可视化并行性能调试环境的设计与实现[D].清华大学,2005.
[10] 刘华.并行程序性能可视化工具及集成开发环境[D].上海大学,2003.
[11] Message Passing Interface Forum,MPI:a message passing interface standard,June 1995.http://www.mpi-forum.org.2012-06-30.
[12] WOLF F,FREITAG F,MOHR B,et al.Large event traces in parallel performance analysis[A].8th Workshop Parallel Systems and Algorithms(PASA),Lecture Notes in Informatics,2006.
