流行病学调查报告数据标准化入口的SAS实现*
2013-07-27东南大学公共卫生学院流行病与卫生统计系210009王诗远
东南大学公共卫生学院流行病与卫生统计系(210009) 王诗远 刘 沛
Epidata以其操作简单,界面友好以及强大的录入和核查功能,尤其是可方便地下载免费的汉化版受到了我国流行病与医学统计工作者的青睐〔1〕。但在应用中,尤其在大型流行病学分析报告过程中,由于多方合作及Epidata设计上的不合理等多方面原因,常常出现Epidata数据库变量命名不规范、变量标签及变量值标签缺失或不完整等问题。这些问题的存在不仅对数据整理造成了不便,也为统计分析和统计图表的制作增加了难度和工作量,同时也为标准化自动分析报告程序的构建和应用造成了障碍。针对上述问题,本文对Epidata数据进入SAS的标准化数据入口程序构建进行了研究,在介绍其方法学的同时,通过流行病学实例说明了我们所建立方法的实用价值。
方法介绍
为解决前文所述问题,一般方法是在SAS DATA步中利用RENAME语句对变量进行重命名使其规范统一;利用LABEL语句对变量进行标签添加;利用SAS PROC FORMAT过程自定义输出格式,并用FORMAT语句将格式应用于变量以实现对变量值标签的添加〔2〕。此种方式缺点为在补充信息时需要对照分析数据集,观察变量标签及其取值。当数据库结构复杂,取值多样时,难免增大工作的难度、出错的概率及书写大量信息语句的工作量。此种方式的局限性还表现为当自定义格式包含信息不全时,无法对原有的自定义格式信息进行添加,也无法解决当前已定义的自定义格式中已存在的标签值修改问题。
例如,变量SEX自定义输出格式为:1为男,2为女,但缺失值标签在格式中未定义,传统方法难以解决缺失值标签添加的问题。另外,即使1和2的值标签都已定义,但若想将‘男’替换为‘男性’,也难以实现,为后续的统计表格制作带来诸多不便。本文提供的方法较好地解决了这些问题,从而为自动输出规范化的统计报表提供了便利。
1.变量规范化重命名及标签添加的宏程序
在处理变量规范化重命名及标签添加时,利用SAS中SQL数据字典得到目标分析数据集的变量相关信息保存至数据集,随后输出至excel,并利用其友好的界面,方便直观地进行编辑。最后导入SAS形成参数,利用全局X语句并结合X语句相关的系统选项,实现excel文件的打开并保证程序运行的连续性。导入excel参数后,利用标准化程序实现变量重命名及变量标签的添加及更改。具体程序及参数解释见本文的应用实例。
(1)SQL数据字典简介
SQL可以通过FROM语句查询隐藏逻辑库DICTIONARY下属成员快速获取全部逻辑库、数据集、SAS系统选项及与当前会话相关的外部文件的相关信息。值得一提的是,逻辑库DICTIONARY仅可以通过SQL进行查询。但SAS系统还提供了一系列基于SQL数据字典〔3〕,明确储存在SASHELP逻辑库下的视图来实现DATA及PROC对数据字典的访问功能。部分常用DICTIONARY成员名称、包含信息及对应视图见表1。

表1 常用DICTIONARY成员、包含信息及对应视图
(2)全局X语句简介
X语句是SAS提供的主机操作系统的接口全局语句,分析人员可以通过X语句在SAS会话中直接发布主机操作系统命令,达到系统操作的目的。例如创建文件夹、拷贝文件、打开文件等功能。值得一提的是,结合X语句相关的SAS系统选项,可以让程序的运行更加灵活〔2〕。X语句相关的SAS系统常用选项见表2。

表2 全局语句X相关系统选项及功能
2.变量自定义格式定制、修改、补充的宏程序
在处理定制、修改、补充自定义格式的问题上,可以巧妙利用PROC FORMAT的输出控制数据集选项CNTLOUT=〔4〕,将格式信息转换成输出控制数据集并在数据集层面实现自定义格式的定制、修改、补充功能。在上一步工作完成后利用输入控制数据集选项CNTLIN=,通过外部数据集创建自定义格式〔4〕。输入输出控制数据集中关于格式定义的常用关键变量见表3。

表3 输入输出控制数据集常用变量功能
同样,在数据集层面的定制、修改、补充自定义格式的工作也可以利用excel界面进行编辑和配置参数,并用全局X语句及相关的系统选项,实现excel文件的操作并保证程序运行的连续性。具体程序及参数解释见本文的应用实例。
应用实例
以我们参与的国家科技重大专项“艾滋病和病毒性肝炎等重大传染病防治”中生命质量调查数据为例,说明标准化入口程序的使用过程及部分关键语句的释义。该数据库共分人口学特征、健康状况等7个维度共213个变量。数据库存在多种问题如:变量命名不规范、变量标签设置不合理、变量标签缺失、变量值标签缺失、变量值标签不统一等。本文选取其中有代表性的部分问题变量列于表4。
通过数据标准化入口程序完成数据的标准化过程如下:
1.调用宏%CHANGENAMEANDLABEL
宏程序中参数CHANGENAMEANDLABELIN表示目标数据集,CHANGENAMEANDLABELEXCEL表示输出excel位置及名称。程序运行过程如下:
(1)生成局部宏变量LIB和DATASET,分别存放通过截取CHANGENAMEANDLABELIN参数获得的逻辑库和数据集名称。如果用户提供一级名称则默认LIB=WORK。
(2)通过LIB和DATASET或取数据集变量名称及其标签,并生成两个新变量用于存放新变量名及标签。

表4 流行病现场调查中的部分问题变量

(3)生成EXCEL参数表,并利用X语句打开完成参数配置,见表5(选取部分变量)。


表5 重命名及标签添加、修改参数表
(4)读取参数配置结果,读取新变量名参数及原变量名分别存放在宏变量NEWNAMELIST和RENAMELIST中,新变量标签参数及原变量名至宏变量至NEWLABELLIST和RELABELLIST中,同时计算重命名参数及变量标签参数个数分别存放在NAMENOBS和LABELNOBS中,为建立循环自动更新做准备。值得注意的是,可以通过读取非空的定义参数使上述RELABELLIST和NEWLABELLIST、NEWNAMELIST和RENAMELIST中的单元数目相等且一一对应。
(5)通过循环实现重命名、标签添加和更新。

参数DEFINEVARFORMATIN为目标分析数据集,CLASSFIABLEEXCEL为存放 Exce的位置及名称,CLASSFIABLELEVELLIMIT参数为判断是否为分类变量的数值标准,高于此水平的便认为定量变量,也就无需进行自定义值标签。如果要对定量变量进行区段定义值标签,可以通过在配置表和输入控制数据集中增加相应END变量实现,此处不再赘述。
(1)类似%CHANGENAMEANDLABEL,首先生成局部宏变量LIB和DATASET分别存放用户指定的DEFINEVARFORMATI参数通过截取获得的逻辑库和数据集名称。利用LIB和DATASET通过SQL数据字典取得目标数据集变量名称、标签、长度、类型、格式五个变量储存至数据集。为了程序运行高效简洁,在上述生成数据集中生成新变量VALUELIST,使下一步中读取变量取值并更新至数据集。
(2)读取每个变量全部取值,用分隔符分隔并更新至数据集。

/*读取数据集中所有变量名储存在varnamelist宏变量中,计算变量数记如宏变量varno中以便下一步建立循环*/
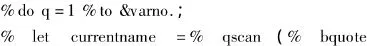

(3)在数据步中拆分取值并生成变量自定义格式的excel参数表,并完成参数配置,见表6(选取部分变量)。

表6 变量自定义格式修改、生成、补充参数表


读取参数表,生成自定义格式并用自定义格式驱动变量,最终结果见表7。
(1)生成程序控制参数LOGIC,如果LOGIC=1则利用原有自定义格式并生成其输出控制数据集_TEMPFORMATDATA。
(2)读取由分析人员定制的excel参数表,并完成关键变量的整理使其符合输入控制数据集格式保存为_TEMPVALUEDATA。在此过程中完成格式命名,命名规则为:变量名+FORM。并利用ID变量标记需要格式驱动变量,并将所有需要驱动的变量名存储在宏变量OUTNEEDFMTVARNAME中。
(3)依据控制参数LOGIC完成是否合并_TEMPVALUEDATA和_TEMPFORMATDATA。为了方便说明列举LOGIC=1时程序如下:

/*生成判断变量,并依据判断变量完成已存在自定义格式的修改*/
/*合并用户指定的excel的自定义格式及逻辑库本身自带的自定义格式信息,完成修改,添加,补充*/
(4)依据输入控制数据集生成自定义格式,并依据宏变量OUTNEEDFMTVARNAME完成自定义格式与变量的关联,结果见表7。


表7 通过标准化入口程序的数据
讨 论
本研究设计的程序具有自动化和标准化的特点,虽以Epidata数据库为例,但贯穿其中的基本思想及其实现过程、编程方法均建立在SAS数据集的层面,所以具有通用性,适用于各类数据管理软件如 excel、CSPRO等,较好地解决了SAS与数据管理软件的接口问题,在自动化分析报告程序的开发和应用中也有着重要意义。但值得注意的是,良好的数据结构不仅能提高工作效率,还能保证数据分析的准确性和统计报表的规范性。因此,事先良好的调查表设计是至关重要的一环,某些条件下甚至是其他环节无法弥补的,但在现实工作中往往被忽视。在程序的编写过程中笔者总结了几个需要注意的问题,现分述如下:
1.程序设计和修改时,应注意更新变量名与更新变量标签的语句顺序。更新变量标签的语句应在前,以防先更新变量名称后,更新变量标签时无法找到原变量名而报错。将整个过程分为变量名、标签的操作和自定义格式的操作也出于上述考虑。
2.在程序中大量使用了利用分隔符分隔储存多个参数的单个宏变量,在两个这样的宏变量进行对接时应注意单元间的对应关系,尤其注意首个是分隔符或者因为扫描到空值而产生的两个连续分隔符,常常使SCAN函数无法扫描到正确单元。
3.利用SQL查询得到的是变量的输出格式值,而并非数据真值,所以在构建excel参数表时变量格式信息是必须的,在进行参数设置时应综合考虑。
4.在输出控制数据集与分析人员定义的格式数据集合并过程中,常常会存在矛盾观测。而且分别来源于已存在自定义格式的输出控制数据集和分析人员自定义的格式数据集,这部分观测有相同的起始值、类型和格式名。由于分析人员欲通过其定制的自定义格式数据集中观测替换自定义格式输出数据集的观测来达到自定义格式某特定值标签修改的目的,因此就需要对来源进行识别,删除输出控制数据集中的矛盾观测,保留分析人员自定义的部分。
5.在关联变量与自定义格式时,利用了自定义变量输出格式的命名规则(变量名+form.),方便有效地达成了目的。
6.在利用SQL中SELECT语句DISTINCT关键词进行取值时,查询结果会自动排序,所以缺失值都在第一位。
1.胡静.EpiData软件的特点及使用简介.疾病监测,2006(5):273-275.
2.Sas Institute Inc.Sas 9.1.3 Help and Documentation.Cary Nc:Sas Institute Inc,2003.
3.Sas Institute Inc.Sas Institute Inc.Sas9.1.3 Sql Procedure Users Guide.Cary,Nc,2006.
4.Sas Institute Inc.Sas Institute Inc.Base Sas9.1.3 Procedures Guide:Statistical Procedures.Cary,Nc,2006.
