基于分片的高维稀疏数据存储模式优化研究
2013-07-20邵慧萌舒红平郑皎凌许源平文立玉
邵慧萌,舒红平,郑皎凌,许源平,文立玉
成都信息工程学院 软件工程系,成都 610225
基于分片的高维稀疏数据存储模式优化研究
邵慧萌,舒红平,郑皎凌,许源平,文立玉
成都信息工程学院 软件工程系,成都 610225
1 引言
1.1 问题的提出
本问题来源于东汽工模具分厂质量管理系统,下面通过该系统中的“零件质量表”说明本文将要解决的问题。
在该工模具分厂零件质量管理系统(数据库采用Oracle数据库)的开发维护过程中,发现存在例如“零件质量表”的一类关系表。其中id为唯一主键,代表零件批次的编号;除id外的其他各列,分别为某一批次的某一种不合格原因,其中某一批次的零件的不合格原因有多种。“零件质量表”中数据如表1所示。
“零件质量表”除主键id外还有15个属性列(维度),共有53 579条记录,具有维度较高、数据量较大的特点。
由于仅在主键id上建立了索引,在执行查询操作时,Oracle将读取表中所有的行,并检查每一行是否满足语句的WHERE限制条件。此时,Oracle顺序地读取分配给表的每个数据块,直到读到表的最高水线处(High Water Mark,HWM,Oracle中用于标识表的最后一个数据块),即对整个关系表进行全表扫描(Full Table Scan)[1-2]。对该表进行的全表扫描将耗费大量的磁盘读写(I/O),增大了系统开销,影响最终的查询效率[3]。

表1 零件质量表
另外,由于同一批次的零件只有一个或多个不合格原因,所以“零件质量表”的不合格原因属性列中的内容是稀疏的。由于大量的空白数据的存在,Oracle数据库对其进行存储时仍占用了固定的存储空间,造成存储空间的浪费。
为了后文表述的方便,这里将“零件质量表”形式化地表述为下列样式:

其中id为关系表T_fact的唯一主键,cοli(1≤i≤n)为T_fact的其他属性,并满足如下特定:
(1)n相对较大(例如n≥10);
(2)cοli(1≤i≤n)列中对应数据有大量空值存在。
在“零件质量表”中,cοl1,cοl2,…,cοln对应各个不合格原因属性列。本文所用到的符号如表2所示。

表2 本文所用到的符号
1.2 问题的解决方案
针对1.1节提出的问题,采用列式存储数据库的思想,对表进行了分片和过滤空值的操作。对原表进行改造后,降低了磁盘读写(I/O),减小了系统开销,使查询效率得到提高;同时过滤空值后达到节省磁盘空间的目的。
2 相关工作
传统行存储数据库主要应用于更新密集型的OLTP应用中。在行存储数据库中,读某个列必须读入整行,这样就在无形之中增加了I/O开销;每一行的数据宽度不等长,修改数据可能导致行迁移[4],并且在行存储数据库中,行迁移不可避免,通过增加每个块的大小可以减少行迁移的可能性,但也会造成更大的空间浪费;在行数据较多的情况下,当执行insert操作插入数据时,可能导致行链接[5-6]。
随着企业信息化程度的提高,只读的OLAP查询等分析型数据库应用的有着不同于传统数据库应用的新需求,对高性能查询处理有更高的要求。列存储数据模型如Sybase IQ、C-Store和MonetDB已经被证明在只读的数据仓库查询处理中具有非常好的性能[7-9]。很多实验也表明对于高选择率、高投影率和大量聚集计算的OLAP查询,列存储的性能大大好于过行存储[10-11]。
以国内市场占有率较高的列式存储数据库GBase 8a为例,它具有列式存储数据库查询响应时间短,不读取无效数据、高压缩比等优点。它能够降低I/O开销,同时提高每次I/O的效率,大大提高查询性能。查询语句只从磁盘上读取所需要的列,其他列的数据是不需要读取的。例如,有两张表,每张表100 GB且有100列,大多数查询只关注几个列,采用列存储,不需要像行存数据库一样,将整行数据取出,只取出需要的列。磁盘I/O是行存储的1/10或更少,查询响应时间提高10倍以上。另外它的压缩比可以达到5~20倍以上,数据占有空间降低到传统数据库的1/10,节省了存储设备的开销[12]。
然而由于传统行存储数据库与列存储数据库的底层物理存储模式不同,使得用户很难在同一数据库系统中根据需要自由转换两种存储模式来存储数据及执行查询。同时企业同时部署行存储和列存储两种数据库系统也无疑增大了部署和维护开销,对于绝大部分企业都是无法承受的[13]。本文基于行存储数据库,采用列式存储数据库的思想,对原始表进行了分片和过滤空值的操作,达到降低磁盘读写(I/O),减小系统开销,提高查询效率和节省磁盘空间的目的。
3 数据表的分片设计及实现
表T_fact具有多个属性列(n≥10),直接对其执行查询操作(例如下面的sql语句)时,需要对整个数据表进行扫描,增大了系统开销,影响最终的查询效率[14]。

图1 对“零件质量表”进行分片后表结构的变化

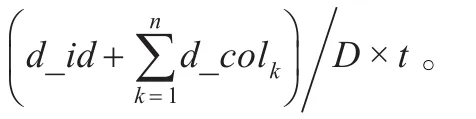
由此可知,每次查询所占用的I/O空间数据块为((n+1)×d)/D×t,其中d为平均每个属性列所占字节数。
在列式存储[15]数据库中,数据库首先在各属性列上执行选择操作,然后将各组的结果进行连接,最后根据需要进行分组、排序等操作后得到最终查询结果,这样就避免了对全表进行扫描。基于列式存储数据库的思想,对表进行了分片操作。
下面,举一个例子进行说明:
例1如图1所示,将“零件质量表”垂直分片。将“零件质量表”分为“零件质量表_刻线问题表”,…,“零件质量表_物件丢失表”,“零件质量表_其他原因表”,“零件质量表_报废表”,共n张表。其中为了程序设计的方便,每个列表的表名是由原始表表名和当前列的列名组成的。每个表中包含有“零件质量表”的id及cοli(1≤i≤n)共两个属性列,其中id为“零件质量表”的外键,cοli(1≤i≤n)为该元组在“零件质量表”中cοli(1≤i≤n)列上的取值。
接下来,将原表中的数据导入到分片之后的表中。由于原始除主键id列外,其他各列都存在着大量的空值数据,所以有必要对原表中的数据进行处理,避免导入大量空值数据。在这里,采取直接将空值过滤的方法,通过执行如下sql语句,将原始表中的非空数据导入到对应的列表中。

例2通过分析,通过如下sql语句,将原始表“零件质量表”中的非空数据导入到各个列表中。

对空值进行过滤后,使得每个列表中没有空值数据的存在。效果如图2所示。
4 存储空间率分析
通过以上处理,大大减少了数据所占用的存储空间。下面给出处理过之后与原始表所占用存储空间的比率:
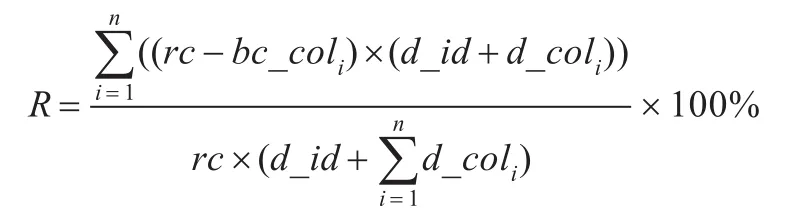
假设bc_cοl为原始表T_fact平均每列空值的个数,d_cοl为平均列宽,则存储空间比可以简化为:


图2 对“零件质量表”进行分片、空值过滤后,表中数据的变化情况
例3在关系表“零件质量表”中,该表的记录数rc= 3 579,主键id列宽d_id=32 Byte,其余列宽d_cοl=512 Byte,该表每列空白记录数bc_cοli(1≤i≤15)分别为1 954,2 148,1 113,1 647,751,944,1 031,641,1 019,2 526,666,115,1 787,574,2 871。
在本例中,原始表所占存储空间为3 579×(32+15× 512)=27 601 248 Byte≈28 MB,分片之后所占用存储空间为(15×3 579-(1 954+2 148+1 113+1 647+751+944+1 031+ 641+1 019+2 526+666+115+1 787+574+2 871))×(32+ 512)=18 440 512 Byte≈18 MB。通过计算,得出该表的存储空间比为18 440 512/27 601 248≈67%。
5 基于分片存储模式的查询实现
将表进行分片之后,sql语句可以等价转化为:

其中原有查询的关系代数形式:
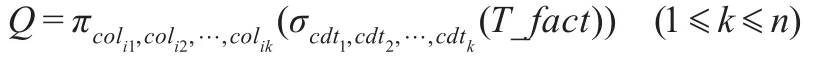
转化为如下形式:
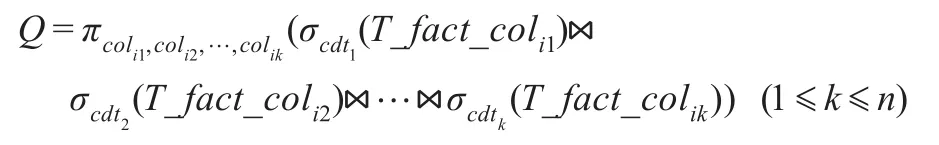
该sql语句执行过程中,所需要的I/O数据块为:

其中,p=3为本次查询所涉及到的表的个数,D为一个数据块的大小(Byte),t为关系表T_fact的元组数,d_id为属性列id所占的空间(Byte),d_cοlk为每个属性列所占用的字节数。
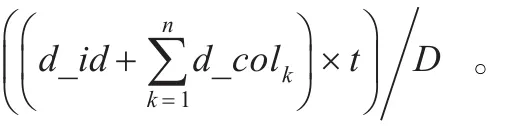
假设各个列宽都为d,分片后每个列表又存储了T_fact的主键id,因此所涉及的列数最大为2×p,分片后查询语句所需I/O数据块个数可简化为(2×p×d)/D×t;而针对原表的查询语句所占空间为((n+1)×d)/D×t。当2×p小于n+1时,以下算式成立:(2×p×d)/D×t<((n+1)×d)/D×t。
例4根据一定的条件,从数据库中选出三列。其中sql语句1直接从原有“零件质量表”中获取数据;通过对关系表进行分片,sql语句2从三个列表“零件质量表_刻线问题表”、“零件质量表_零件丢失表”和“零件质量表_其他原因表”中获得数据。
sql语句1:
select t.刻线问题,t.零件丢失,t.其他原因
from零件质量表 t
where t.id>4 600 and t.id<10 001;
sql语句2:
select t1.刻线问题,t2.零件丢失,t3.其他原因
from零件质量表_刻线问题表t1,
零件质量表_零件丢失表t2,
零件质量表_其他原因表t3
where t1.id=t2.id(+)and t1.id=t3.id(+)and
t1.id>4 600 and t1.id<10 001;
其中,查询所涉及到的表的个数p=3,id列宽d_id= 32 Byte,其余各列列宽d_cοl=512 Byte,表中记录条数为t= 53 579,数据块大小D=8 192 Byte。代入以上公式得,原始表对应的查询所需I/O块个数为:53 579×(15×512+32)/ 8 192=50 440,分片后对应的查询语句所需I/O块个数为53 579×(3×(512+32))/8 192=10 674。
由于在该方法中只对有限的几个属性列表进行扫描,避免了对具有n个属性列的关系表T_fact进行全表扫描,降低了整个查询I/O,从而提高了性能。并且由上式可知,当关系表的列数越多、查询所涉及的表的个数越少,就越能够提高查询性能。
6 实验结果与分析
6.1 存储空间分析
6.1.1 理论值分析
在对该集团公司工模具分厂的相关关系表进行改造后,占用的磁盘存储空间变小,查询所需要的I/O数据块减少,达到了实验的预期效果。
首先分析关系表占用存储空间,通过0分析和参照例3的计算步骤,随机抽取4张关系表,计算得出了在改造前后所占用的理论存储空间大小(KB),如图3所示。

图3 对表进行改造后,理论存储空间大小对比
从图3中可以看出,对原始表进行改造后,其所占理论存储空间有了明显的减少,改造前后的存储空间比取决于存储空间的比率R。
6.1.2 实际值分析
下面通过执行如下sql语句来查看Oracle为原始表实际分配存储空间大小(KB),其中本机Oracle版本为10 g Release 2(10.2.0.2)64位。其中user_segments视图存储了DBMS为每个表分配的存储空间,where语句限定要查询的表。

通过执行如下sql得到分片后,所有列表占用的存储空间大小(KB)总和。其中下划线在Oracle中为特殊字符,需要用ESCAPE关键字转义。

得到原始表“零件质量表”占用存储空间大小为15 360 KB,分片后所有列表占用的存储空间大小总和为4 288 KB。通过对上面随机抽取的4张关系表进行执行sql语句,得到查询结果如图4所示。

图4 对表进行改造后,实际存储空间大小对比
如图4所示,由于Oracle默认为4张原始表分配了同样的存储空间15 360 KB,实际值与理论值出现偏差;如理论分析相同,在对表进行分片后所需要的实际存储空间大大减小。
6.2 查询所需I/O数据块数量分析
根据分析,在对分片后的关系表进行查询操作时,I/O所需数据块的个数随着查询所涉及关系表个数的增加而增加;而在对原关系表进行的查询操作中,所涉及关系表的个数与所需I/O数据块个数无关。从图5可以看出,查询所涉及的关系表的个数与所需I/O数据块个数的关系(横坐标为查询所涉及表的个数)。与例4的执行步骤一样,4次查询操作都是对同一个关系表“零件质量表”进行原始表查询和分片查询。
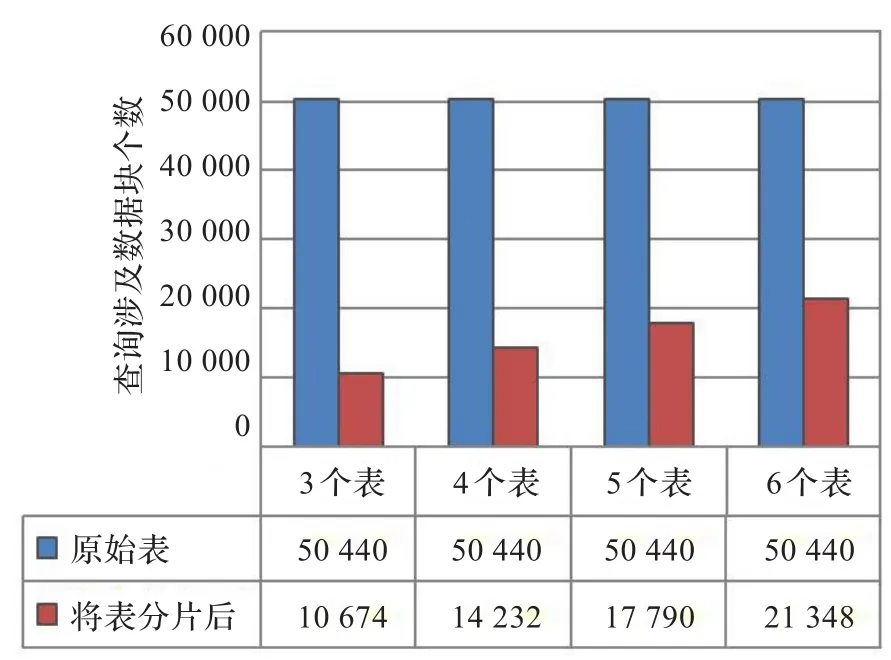
图5 查询所涉及关系表的个数,对数据块个数的影响
另外,图5也反应了查询所需数据块个数与所涉及关系表的个数的关系。可以看出,在对原始表进行查询时,无论查询所涉及表的个数是多少,I/O数据块的数量始终都是50 440。而对表进行分片后,查询所需I/O数据块的个数随着涉及表的个数的增加而增加,呈现出递增的趋势,并且在涉及关系表个数很少的情况下可以达到理想的I/O开销。
7 结束语
在实验中,采用列式存储数据库的思想,对表进行了分片和过滤空值的操作。从实验结果中可以发现,在对原表进行改造后,达到了减少查询所需要的I/O数据块的个数,降低磁盘读写(I/O),减小系统开销的目的,使查询效率得到提高。同时在对空值进行过滤后,显著降低了磁盘占用空间。
另外,在改造后的列表中有相当多的重复数据的存在,在下一步实验中将采用压缩编码技术使存储空间压缩比更加理想。
[1]周志德.Oralce数据库的SQL查询优化研究[J].计算机与数字工程,2010(11):173-178.
[2]Halverson A,Bechmann J.A comparison of c.store and row. store in a common framework[C]//Proc of the 32nd Int Conf on Very Large Databases(VLDB),2006.
[3]刘博.Oracle数据库性能调整与优化[D].大连:大连理工大学,2007.
[4]张仁惠.消除行迁移与Oracle数据库性能调优[J].科技信息:科学教研,2007(33).
[5]苏大威,张乐.基于Oracle数据库开发系统的物理设计优化策略[J].计算机工程,2002(2).
[6]巢子杰.Oracle数据库优化探究[J].软件导刊,2010(2):142-144.
[7]Sybase IQ[EB/OL].[2012-11-24].http://www.sybase.com/products/datawarehousing/sybaseiq.
[8] C-Store[EB/OL].[2012-11-25].http://db.csail.mit.edu/projects/cstore/.
[9]MonetDB[EB/OL].[2012-11-25].http://www.monetdb.org/Home.
[10]李超,张明博,邢春晓,等.列存储数据库关键技术综述[J].计算机科学,2010(12).
[11]王珊,肖艳芹,刘大为,等.内存数据库关键技术研究[J].计算机应用,2007(10):2353-2357.
[12]南大通用.GBase 8a新型列存储分析型数据库产品介绍[EB/ OL].[2012-11-25].http://www.gbase.cn/cp-8a.html.
[13]于利胜,张延松,王珊,等.基于行存储模型的模拟列存储策略研究[J].计算机研究与发展,2010(5):878-885.
[14]宋彩霞,路新春.Oracle数据库基于索引SQL优化方法的研究与实现[J].计算机工程与设计,2004(12):2327-2330.
[15]周军锋,田姗姗,蓝国翔,等.TDCOL:列式存储的XML关键字查询处理策略[J].计算机科学与探索,2012,6(9):829-843.
SHAO Huimeng,SHU Hongping,ZHENG Jiaoling,XU Yuanping,WEN Liyu
Department of Software Engineering,Chengdu University of Information Technology,Chengdu 610225,China
In large databases,empty fields in high dimensional sparse table may occupy a large amount of storage space.To deal with this problem,a slicing based database structure,which simulates the principle of column-store database in traditional rowstore database,is designed.By analyzing on testing results,the storage space is decreased about 27.42%lower than the original model.The number of I/O data block is reduced to 35.27%when five fields of high-dimensional sparse data are queried,and 28.22%when four fields are selected.There will be a further reduction when the number of fields reduces.Therefore the accessing efficiency for database is improved.
high-dimensional;sparse data;column-store database
针对大型数据库中高维稀疏关系表空字段对存储空间的占用问题,通过利用传统行存储数据库模拟列式存储数据库的工作原理,设计了一种基于分片的数据库结构。通过实验分析,数据库存储空间比原始模式降低了27.42%左右。在对高维稀疏数据中五个字段进行查询时,I/O数据块个数降低至原始模式的35.27%,对高维稀疏数据中四个字段进行查询时,I/O数据块个数降低至原始模式的28.22%,而随着字段的减少I/O数据块仍会进一步减少,从而提高了数据库的访问效率。
高维;稀疏数据;列式存储数据库
A
TP311.13
10.3778/j.issn.1002-8331.1301-0266
SHAO Huimeng,SHU Hongping,ZHENG Jiaoling,et al.Storage model optimization toward high dimensional sparse data based on slicing.Computer Engineering and Applications,2013,49(18):99-104.
国家重点基础研究发展规划(973)(No.2012CB518500);国家自然科学基金青年基金(No.61202250,No.61203172);四川省教育厅青年基金项目(No.11ZB088);四川省应用基础计划(No.2012JY0112);成都市科技计划项目(No.12DXYB100JH-002);成都信息工程学院中青年学术带头人科研基金(No.J201208,No.J201101);成都信息工程学院引进人才项目(No.KYTZ201110,No.KYTZ201111);四川省科技支撑计划项目(No.2011SZZ027)。
邵慧萌(1986—),男,硕士,研究领域为数据库与知识工程、计算机在制造业中的应用;舒红平(1974—),男,教授,研究领域为软件工程、数据库与知识工程、数据挖掘;郑皎凌(1981—),女,博士,副教授,CCF会员,研究领域为数据库与知识工程、机器学习。E-mail:huimengshao@163.com
2013-01-23
2013-03-11
1002-8331(2013)18-0099-06
CNKI出版日期:2013-04-08 http://www.cnki.net/kcms/detail/11.2127.TP.20130408.1646.003.html
