基于改进模糊聚类与ANFIS的高速公路事件检测
2013-07-19姚磊刘渊
姚磊,刘渊
1.江南大学物联网工程学院,江苏无锡 214122
2.江南大学数字媒体学院,江苏无锡 214122
基于改进模糊聚类与ANFIS的高速公路事件检测
姚磊1,刘渊2
1.江南大学物联网工程学院,江苏无锡 214122
2.江南大学数字媒体学院,江苏无锡 214122
1 引言
交通事件[1]是指导致道路通行能力下降或交通需求不正常升高的非周期性发生的情况,事件一般可分为可预测的和不可预测的两类。可预测类交通事件包括大型活动、道路修筑、路面养护等。不可预测类交通事件主要包括交通事故、车辆抛锚、货物散落等。
对于不可预测类交通事件,其发生的时间和地点无法事先获知,驾驶员无法采取躲避措施,尤其高速公路具有车流量大和行车速度高的特点,一旦发生交通事故则往往非常严重,不仅一次事故影响的车辆多、伤亡率高,会造成严重的交通阻塞和行车延误,还会引起二次事故的发生,严重影响高速公路的整体通行能力和运营效率。因此,本文主要研究对象为高速公路的不可预测类交通事件。
目前国内外对交通事件检测算法的研究主要集中在新理论和新技术的应用方面,包括神经网络、模糊理论、小波分析以及支持向量机等,例如张良春等[2]采用一种改进的模糊C均值聚类对训练样本进行预处理,提取有可能成为支持向量的训练样本,通过分析事件产生对交通流的影响,选择了支持向量机的输人参数,并进行了算法仿真;Šingliar和Hauskrecht[3]运用动态朴素贝叶斯和EM算法对实测数据进行标签重排,然后利用SVM算法进行分类,取得了较好的结果;彭宇[4]利用突变理论分析了事件发生对高速公路交通流特性的影响,建立了突变交通流模型,并利用小波理论的事件检测算法进行了离线检验。
本文将自适应模糊神经推理系统应用于高速公路事件检测中,提出了用减法聚类对模糊C均值算法进行改进,生成初始模糊推理系统,使模型自适应地确定模糊系统的初始结构和参数,避免了盲目性和随机性;利用ANFIS建立交通事件检测模型,采用最小二乘算法和反向传播算法对模糊规则的参数进行训练获得最终的模型,并进行了仿真验证。
2 ANFIS结构及算法
自适应模糊神经推理系统[5](ANFIS),属于神经模糊网络的一种。ANFIS融合了人工神经网络的自适应学习功能与模糊系统的语言推理功能,并弥补了各自的不足。ANFIS可自动地从输入输出数据中提取规则,并依据神经网络的自学习性,调整优化前件参数和结论参数,提高模糊系统的推理性能。

其对应的结构图如图1所示。
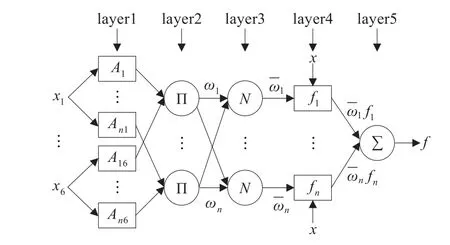
图1 ANFIS结构图
第一层的功能是输入变量模糊化,输出为各输入变量所对应的模糊隶属度函数。
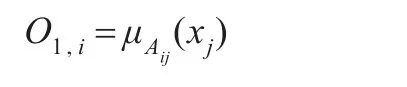
第二层的功能是计算每条规则的适应度,在图中用Π表示,它的输出是所有输入信号的积,表示规则的激励强度,其乘积输出为:

第三层的功能是将所有规则的激励强度归一化,在图中用N表示,它计算第i条规则的激励强度与所有规则的激励强度之和的比值:
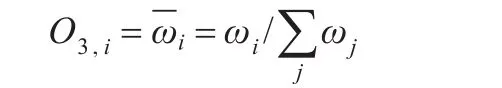
第四层的功能是计算每条模糊规则的输出,这一层的每个节点i都为一个有节点函数的自适应节点:
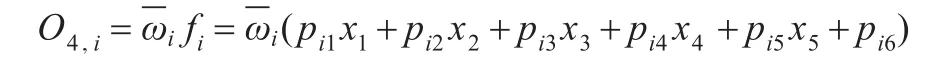
第五层的功能是计算模糊系统的输出,这一层的单节点是一个标以∑的固定节点,它计算所有输入信号之和作为总输出:
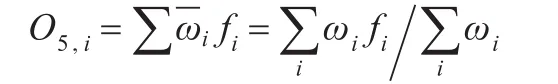
从ANFIS的结构可以看出,ANFIS属于一种典型的自适应网络,其目的是对前件参数与结论参数进行调整优化,当前件参数固定时,系统的总输出可以表示为后件参数的线性组合,用符号表示即:
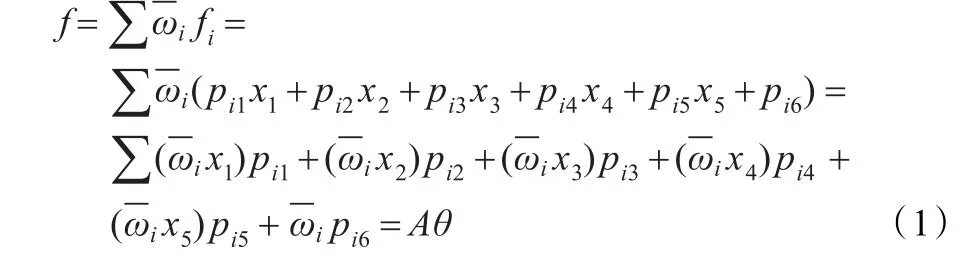
其中,θ={pi1,pi2,pi3,pi4,pi5,pi6}为后件参数集。固定前件参数不变,则式(1)是标准的线性最小二乘问题,使用最小二乘估计算法调整后件参数θ,接下来,固定上一步计算得到的后件参数,对前件参数采用前馈神经网络的BP算法,将误差由输出端反传到输入端,由梯度下降法更新前件参数,从而改变隶属函数的形状,完成前件参数的识别。
3 基于聚类算法的模糊推理系统建模
3.1 减法聚类算法原理
减法聚类[6-7]是一种快速寻找数据集的聚类数和聚类中心的算法,该算法选取数据集中所有数据点为候选聚类中心。令(x1,x2,…,xn)是M维空间中的n个数据点,按照减法聚类选择每一个数据点作为候选聚类中心,使用式(2)计算数据点xi处的密度值:
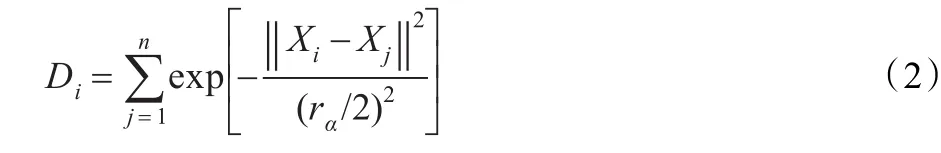
其中,参数rα是密度的作用半径,rα越小则所得到的聚类数目就越多。在计算完每个数据点密度指标后,选择密度值最高的数据点Xc1作为第一个聚类中心,按照式(3)修正该点的密度指标:
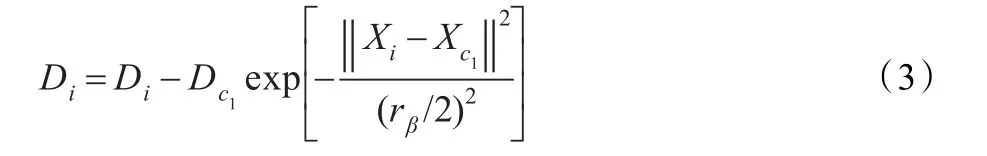
其中,Xc1为选中的聚类中心,Dc1为该聚类中心的密度值,参数rβ定义了密度指标显著减小的邻域,通常rβ=1.5rα,以避免出现距离很近的聚类中心。
在修正第一个数据点的密度指标后,重新选择当前密度值最高的数据点作为下一个聚类中心,利用式(3)对所有数据点进行密度值调整。重复以上步骤,当剩余数据点作为聚类中心的可能性低于某一阈值时,停止聚类中心搜索。
3.2 FCM聚类算法原理
模糊C均值聚类[8-10](FCM),即模糊ISODATA,是用隶属度确定每个数据点属于某个聚类程度的一种聚类算法。其基本思想是通过反复修改聚类中心V和分类矩阵U来实现动态的迭代聚类,使得被划分到同一簇的对象之间相似度最大,而不同簇之间相似度最小。
给定观察空间的一样本集xi(i=1,2,…,n),c为预定的类别数目,mj为每个聚类的中心,μj(xi)是第i个样本对于第j类的隶属度函数。用隶属度函数定义的聚类损失函数可以写为:
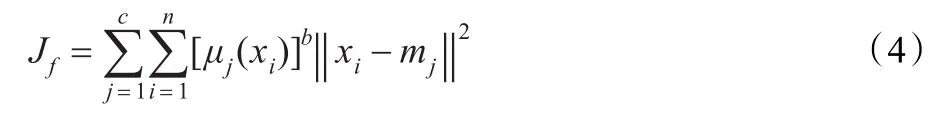
其中,b∈[1,∞)是一个加权指数,可以控制聚类结果的模糊程度的常数,通常取2。标准模糊C均值方法要求一个样本对于各个聚类的隶属度之和为1,即:

令Jf对mj和μj(xi)求导,使得式(4)达到最小的必要条件为:
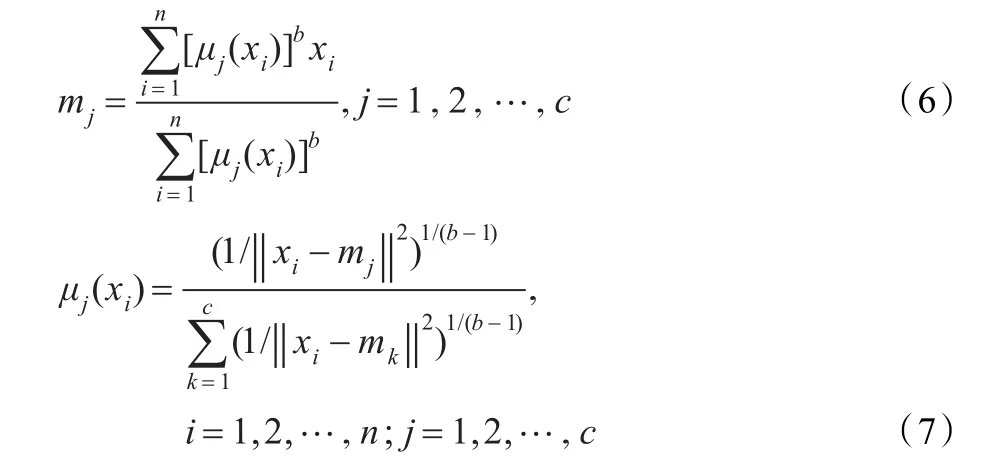
用迭代方法求解式(6)和式(7),算法步骤如下:
步骤1给定聚类数目c,加权指数b,容许误差ε的值。
步骤2随机初始化聚类中心mj(1)(j=1,2,…,c)。
步骤3用当前聚类中心根据式(7)计算隶属度函数。
步骤4根据式(6)修正聚类中心mj(k+1)(j=1,2,…,c)。
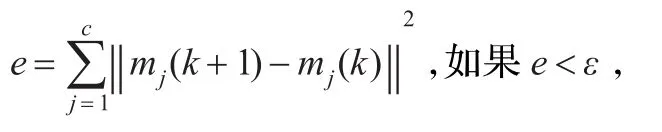
3.3 改进聚类算法
FCM聚类算法必须预先指定聚类中心数,无法充分利用数据信息的特征。而减法聚类无需规定聚类数,根据样本数据即可快速决定聚类中心,既充分利用了数据本身提供的信息,又加快了收敛速度。本文将减法聚类后得到的聚类中心全部用于初始FCM的聚类中心,加快了FCM的收敛速度,减少了由用户确定聚类中心个数的盲目性。
3.4 交通事件检测算法建模
本文采用SFCM-ANFIS算法模型流程图如图2所示,其具体步骤如下:
步骤1 I-880数据库包括上下游速度,流量和占有率的测量值6个参数,首先对该数据进行预处理,利用Matlab的Mapminmax函数将样本数据映射到[0,1]区间进行归一化。
步骤2为减少人工因素干扰,本文利用减法聚类求得处理后样本数据的聚类中心,然后将该聚类中心赋给FCM初始聚类中心,进行FCM聚类得到聚类数和聚类中心,若求得聚类个数为C,则隶属度函数的个数为C×6,从而建立一个6输入1输出的ANFIS结构。
步骤3输入得到的训练样本数据,采用反向传播算法与最小二乘法的混合算法训练ANFIS,若满足训练终止条件,即得到最终模糊推理系统。
步骤4利用验证样本数据对得到的FIS模型进行推理判断,与样本数据中类别标签比较得到检测率和误报率两个评价指标,并由此进行对比分析。
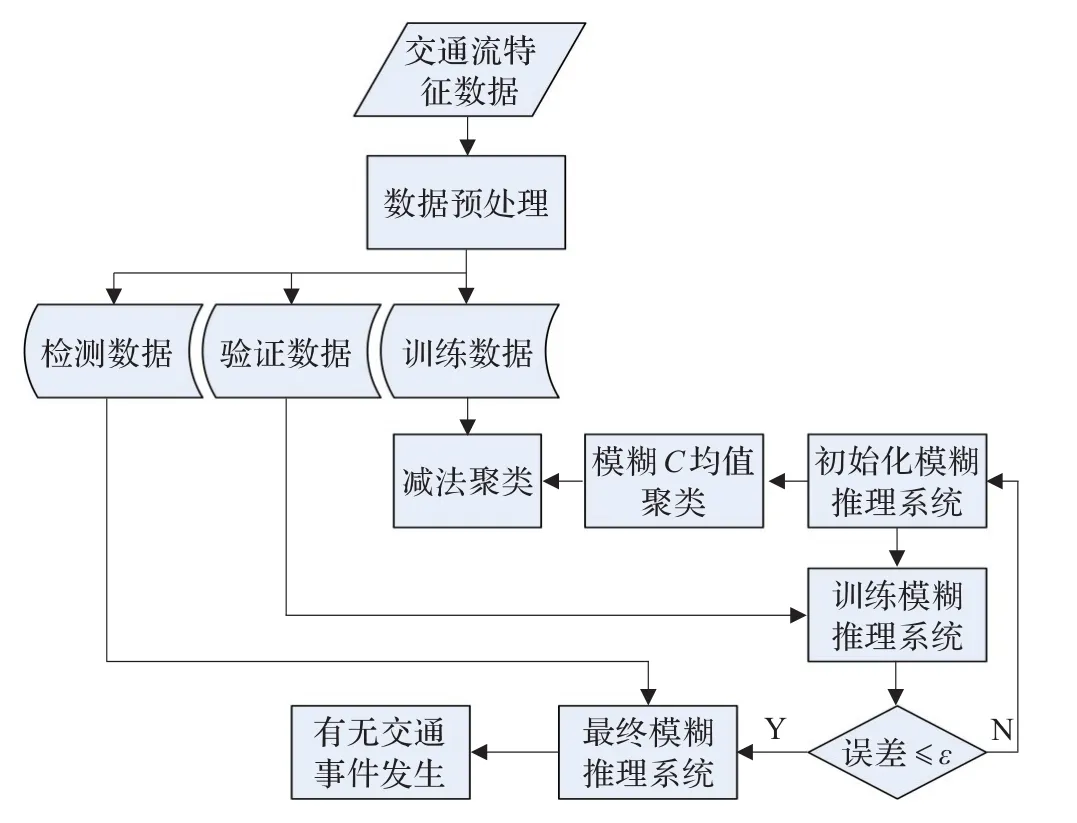
图2 交通事件检测模型流程图
4 评价指标
交通事件检测算法常用评价指标有检测率(Detection Rate,DR)、误报率(False Alarm,FAR)和平均检测时间(Mean Time to Detection,MTTD)。
本文不仅采用常用评价指标,还采用了接收者操作特性曲线[9](Receiver Operation Characteristic Curve,ROC)和曲线下面积(Area Under the Curve,AUC)来评价AID算法。
ROC曲线是以误报率(False Positive Rate,FPR)为横轴,检测率(True Positive Rate,TPR)为纵轴,横轴与长度相等,为单位l,形成一个正方形的二维空间,在此二维空间中将各个(FPR,TPR)点标出,用直线连接各相邻两点构建而成的一条曲线。
ROC曲线是分类器识别算法性能的二维直观描述。为便于比较不同的识别算法,常计算ROC曲线下面积AUC。AUC的理论取值范围在0.5~1.0之间,0.5对应几率线(对角线)下的面积,1.0对应整个ROC平面的面积。ROC越快速逼近左上角,AUC越大,识别算法的性能就越好。
5 实验结果分析比较
5.1 数据来源
本文采用美国加州I-880数据库进行实验仿真,它已经被广泛应用在相似的事件检测算法研究上。该数据库前期采集时间为1993年2月16日—3月19日,后期采集时间为1993年9月27日—10月29日。I-880数据库保存了交通流量、占有率、速度以及交通事件(包括货物散落、车辆故障和交通事故等)的原始数据,是目前最大、最完整的高速公路交通数据库;I-880交通数据总共记录了4 136组交通事故数据样本,共45起交通事件,本文随机选取了其中22起交通事件,共2 100组样本数据,与随机选取的4 343组非事件样本数据,共6 443组数据组成输入样本数据集。本文从样本特征集中随机选取60%的数据作为训练样本,20%的数据作为验证样本,剩下20%的数据作为测试样本;选取上下游检测器检测到的速度、流量和占有率的测量值6个参数组成模型最初的特征输入集,数据样本有7列,最后一列为样本数据的类别标签,+1表示该样本为有事件样本,-1表示该样本为无事件样本。
5.2 实验及结果分析
交通事件检测算法常用评价指标有检测率、误报率和平均检测时间。然而,在选择算法时,通常要在这些评价指标中进行权衡,通常来说,为得到较高检测率,必然有高误报率,而为减少平均检测时间,也会相应的降低检测率。因此,本文除了采用均衡的常用评价指标外,还采用了ROC曲线及AUC值来对各种算法进行评价。
本文利用Matlab对算法进行仿真验证[10,-1],并与其他算法进行比较。仿真实验参数:SVM算法中惩罚参数c=300,核函数参数g=0.04,减法聚类中密度作用半径rα=0.3。每种算法分别进行10次实验,训练的迭代次数均为200次,比较结果如表1所示。
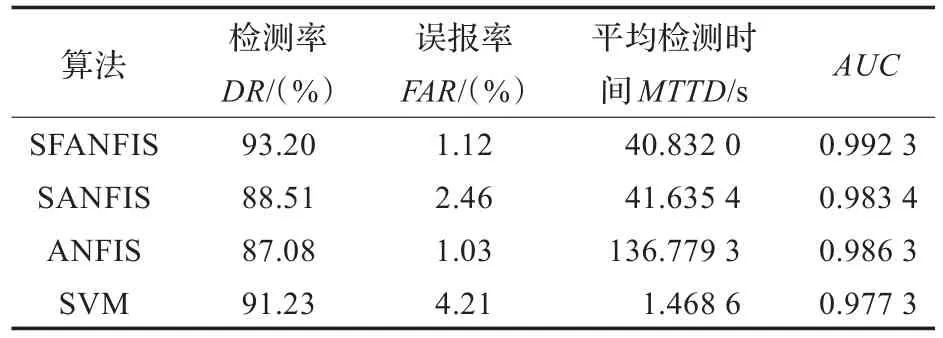
表1 算法检测性能比较
从对比实验看出,无聚类算法的ANFIS平均检测时间最高,无法达到交通事件检测系统实时性的要求;SVM算法虽然得到了较好的平均检测时间,但其误报率较高且AUC值最小;减法聚类与本文所采用的基于改进FCM和ANFIS的算法的检测时间大致相同,但本文所用方法具有较高的检测率和较低的误报率,并且它的AUC值均高于其他算法。

图3 交通事件检测ROC曲线对比图
ROC曲线中的横坐标表示误报率,纵坐标表示检测率,上述4种算法的ROC曲线如图3所示。从图中可以看出,SVM算法曲线在最下方,具有最低AUC值,并且当误报率在0.4左右时,检测率才能达到1.0;无聚类算法的ANFIS与基于减法聚类的ANFIS从曲线上看大致相同,但从表1可知,无聚类算法的ANFIS需要较高检测时间,不满足实时性要求,而且,两种算法误报率在0.2~0.3之间时,检测率才能达到1;SFCM-ANFIS算法误报率在0.1~0.2之间时,检测率就可接近1,并且SFCM-ANFIS算法的曲线基本位于其他算法上方,具有最高AUC值,说明其整体性能较优。
6 结束语
本文提出了基于改进FCM和ANFIS算法的高速公路交通事件检测的新模型,使用减法聚类得到聚类中心初始化FCM算法,通过FCM聚类算法得到前件参数,建立初始模糊神经系统,然后利用混合学习算法对该系统进行训练,得到最终模糊神经系统,最后用检测数据对该系统进行模糊推理,判断是否为高速公路事件。实验结果表明,本文所采用的交通事件自动检测模型是有效的,且总体性能优于一般的事件自动检测方法。同时,结合减法聚类和标准FCM对聚类算法进行改进,不仅充分利用了样本数据信息,而且减少了由用户确定聚类中心个数的盲目性,将改进后的算法应用于模糊系统,从而提高模糊系统的应用效率。为了降低检测时间,满足实时性要求,今后将对交通流数据进一步进行处理,为得到更好的检测结果,将进一步对ANFIS进行优化处理,以提高其在交通事件检测方面的性能。
[1]王晓原,张敬磊,杨新月.交通流数据清洗与状态辨识及优化控制关键理论方法[M].北京:科学出版社,2011.
[2]张良春,夏利民,石华玮.基于模糊聚类支持向量机的高速公路事件检测[J].计算机工程与应用,2007,43(17):206-208.
[3]Šingliar T,Hauskrecht M.Learning to detect incidents from noisily labeled data[J].Machine Learning,2010,79:335-354.
[4]彭宇.基于小波分析的高速公路事件检测算法[J].湖南交通科技,2011,37(3):123-126.
[5]张智星,孙春在,水谷英二.神经-模糊和软计算[M].西安:西安交通大学出版社,2000.
[6]曲强,陈雪波.基于ANFIS的铁水脱硫系统的建模[J].模式识别与人工智能,2004,17(2):218-221.
[7]蒋静芝,孟相如,李欢,等.减法聚类——ANFIS在网络故障诊断的应用研究[J].计算机工程与应用,2011,47(8):76-78.
[8]边肇祺,张学工.模式识别[M].2版.北京:清华大学出版社,2000.
[9]薛胜君,聂靖.基于混合优化模糊C均值算法的网格资源聚类[J].计算机应用研究,2010,27(6):2153-2155.
[10]朱喜林,武星星,李晓梅.基于改进型模糊聚类的模糊系统建模方法[J].控制与决策,2007,22(1):73-77.
[11]张国良,王海娟,柯熙政,等.模糊控制及其MATLAB应用[M].西安:西安交通大学出版社,2002.
YAO Lei1,LIU Yuan2
1.School of Internet of Things,Jiangnan University,Wuxi,Jiangsu 214122,China
2.School of Digital Media,Jiangnan University,Wuxi,Jiangsu 214122,China
In order to accurately and timely detect highway traffic accident,reduce traffic delay and improve highway safety, this paper combines subtractive clustering and FuzzyC-Means(FCM)clustering method to cluster the input sample data to build the initial fuzzy inference system,then the hybrid algorithm is used to train the parameters of the fuzzy system,determine the fuzzy reasoning rules,and establish a final training fuzzy model.Compared with the simulation experimental results,the method obtains excellent performance on ROC(Receiver Operation Characteristic)curve,shows the validity of the modeling method based on the improved fuzzy clustering and Adaptive Neural Fuzzy Inference System(ANFIS).
freeway incident detection;FuzzyC-Means(FCM)clustering;subtractive clustering;Adaptive Neural Fuzzy Inference;ROC curve
为了准确并及时地发现高速公路上的交通事故隐患,减少事故引发的交通延迟,提高高速公路运行安全性,结合减法聚类与模糊C均值(FCM)聚类算法对输入样本数据进行聚类,建成初始模糊推理系统,然后通过神经网络的自学习机制,训练模糊系统参数,确定模糊推理规则,建立最终模糊模型。通过仿真实验结果对比,验证了基于改进模糊聚类与自适应神经模糊推理系统(ANFIS)建模方法的有效性。
交通事件检测;模糊C均值聚类;减法聚类;自适应神经模糊推理;ROC曲线
A
TP39
10.3778/j.issn.1002-8331.1112-0613
YAO Lei,LIU Yuan.Freeway incident detection based on improved fuzzy clustering arithmetic and ANFIS.Computer Engineering and Applications,2013,49(19):242-245.
国家自然科学基金(No.61103223);江苏省自然科学基金重点研究专项(No.BK2011003)。
姚磊(1986—),女,硕士,主要研究领域为模式识别,事件检测;刘渊(1967—),男,教授,主要研究领域为软件工程,网络应用。E-mail:yjs_latte@163.com
2012-01-04
2012-04-18
1002-8331(2013)19-0242-04
CNKI出版日期:2012-05-22http://www.cnki.net/kcms/detail/11.2127.TP.20120522.1108.008.html
