基于计算机取证的Linux文件系统解析与设计
2013-07-14刘春枚
刘春枚
(昆明船舶设备研究试验中心,云南 昆明 650051)
0 引 言
近年来,Linux操作系统以前所未有的速度迅速发展,它的高性能、高可靠性赢得了广泛的好评和支持,取证技术在Linux上的应用成为了计算机取证的一个重要方面。Ext2文件系统是Linux操作系统中应用最为广泛的基本文件系统,保存和管理重要的文件信息,挖掘分析其中的有用数据已成为目前计算机调查取证的重要手段和研究方向[1]。
然而,目前国内外缺乏开源的Linux文件系统解析软件供计算机取证使用。因此,本文提出面向对象的思想对Linux文件系统解析软件进行开发,通过类的多态性的思想实现了不同文件系统的解析,将提取到的文件信息转换成友好的用户界面形式,为计算机取证技术在Linux上的应用提供有力工具。
1 Linux文件系统
Linux的文件系统是Linux操作系统最重要的组成部分之一,文件系统中的文件是数据的集合,它不仅包含着文件的数据而且还有文件系统的结构。Ext2是Linux操作系统的基本文件系统,它将所占用设备的逻辑分区分成了多个数据块组,每一个数据块组都包含一些有关整个文件系统的描述信息以及数据块,图1给出了Linux文件系统的物理结构图[2]。
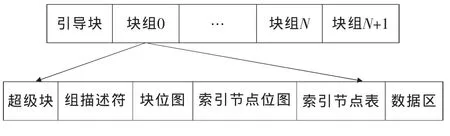
图1 Linux文件系统物理结构图
1.1 Linux的Ext2存储模型
1.1.1 Ext2超级块(super block)
Ext2超级块是用来描述文件系统整体信息的数据结构,它存储着描述文件系统大小和形状的基本信息,可以使用其中的信息来使用和维护文件系统,是Ext2文件系统的核心所在。Ext2在磁盘上的超级块存放在一个Ext2_super_block结构中,主要包括Magic Number(幻数)、Revision Level(修订级别)、Mount count(挂接数)、Block Group Number(块组号)、Block Size(块大小)、Blocks per Group(每组块数)、Free Blocks(空闲块)、Free Inodes(空闲索引节点)、First Inode(第一个索引节点)[3]。
1.1.2 Ext2组描述符(group descriptors)
每个数据块组都有一个描述其数据结构的组描述符,它和超级块一样,在每一个数据块组中都要复制一份数据块组描述符。组描述符放置在一起形成了组描述符表,每个数据块组在超级块拷贝后包含整个组描述符表。每个组的组描述符存放在Ext2_group_desc结构中,数据块组描述符包含的信息如表1所示。

表1 块组描述符
1.1.3 Ext2 索引节点(inode)
在Ext2文件系统中索引节点是一切的基础,文件系统中的每一个文件和目录都使用一个唯一的索引节点,每一个数据块组中的索引节点都保存在索引节点表中。数据块组中还有一个索引节点位图,它用来记录系统中已分配和未分配的索引节点。下面是Ext2索引节点的一些主要的字段:
(1)mode:保存两个信息,一个是此索引节点的描述,另一个是用户拥有的权限。对于Ext2,一个索引节点可以描述文件、目录、符号连接、块设备、字符设备以及FIFO结构。
(2)Owner Information:所有者的用户和组标识符,使得文件系统可以正确地授权某种存取操作。
(3)Size:文件的字节大小。
(4)Timestemps:索引节点建立的时间和索引节点最后修改的时间。
(5)Datablocks:指向存储此索引节点描述文件的数据块的指针。前20个指针是指向存储数据的物理数据块的指针,而后3个指针则包括不同级别的间接指针。
1.1.4 Ext2目录结构
Ext2以一种特殊的结构实现了目录,这种文件的数据块把文件名和相应的索引节点号存放在一起。这种目录结构是存放在Ext2_dir_entry_2的结构,Ext2目录项中主要有如下字段:
(1)inode:索引节点号。
(2)rec_len:目录项长度。
(3)name_len:文件名长度。
(4)file_type:文件类型。
(5)name:文件名。
此结构的长度是可变的。该结构的最后一个name字段是Ext2_NAME_LEN个字符的变长数组,因此这个结构是可变的。rec_len字段为指向下一个有效目录项的指针:它是偏移量,与目录项的起始地址相加就得到下一个有效目录项的起始地址。删除目录项目时把它的inode字段置为0并适当地增加前一个有效目录项rec_len字段。
2 面向对象的Linux文件系统解析与设计
2.1 Ext2文件系统类框架设计
在Ext2文件系统的解析过程中,系统的目标是根据Ext2文件系统的结构,从底层的二进制流提取出所有存在的文件、目录、分区等文件信息,并以树形结构的形式将解析出来的文件以友好的界面方式展现给用户,同时提供功能丰富的文件操作接口,更好地对文件进行分析和取证。
基于系统要实现的目标,本文提出了面向对象的文件系统解析思想,即将所有的文件当作一个对象,它封装了对象的各个属性以及对对象操作的各种接口函数,每个对象之间是一个独立的整体。在解析出来的整个文件列表中,工程,硬盘,分区,目录,文件都是从CMyFile继承出来的,其中文件就是一个简单的CMyFile对象。CMyFile根据对象作用的不同,又分别派生出CDevice类和CProject类,分别用来表示设备和工程,其中CProject类表示一个项目,有添加项目的函数,和其他设备一样被当做一个文件放在文件列表中。CDevice类根据对象的不同,又分别派生出CLogicDisk类和CDisk类,分别用来表示分区和硬盘,从而得到整个文件系统的类框架如图2所示[4]。
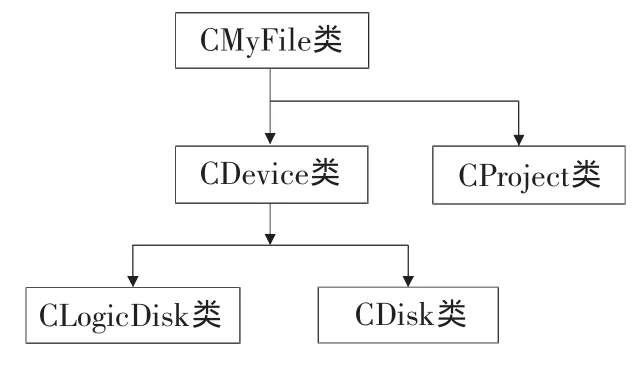
图2 Ext2文件系统的总体类框架图
为了方便对每个文件对象的数据源构建和获取,在每一个CDevice类中里面都定义了一个CSource的对象,CSource是表示这个设备的数据源。根据实际应用中文件系统数据源的不同,又可以将数据源分为硬盘数据源和镜像数据源,因此,从CSource基类中又派生出cDeviceSource和cFileSource两个子类,一个是表示硬盘数据源,一个表示文件数据源,在它们内部都实现了CREATEFILE、READFILE之类的函数,方便在数据源中读取数据,从而得到文件系统资源类继承框架图如图3所示。

图3 Ext2文件系统的资源类框架图
2.2 Ext2文件系统的解析技术
在Ext2文件系统中,所有文件都保存在块组中,节点INODE是文件系统中重要的数据存储结构,记录文件的存储空间和其他各种有用的信息。根据上节对Ext2文件系统原理的阐述,本文设计出Ext2文件系统解析的方法如下:
(1)读取Ext2文件系统的超级块SuperBlock,存储到SuperBlock结构体空间中,获取描述文件系统大小和形状的基本信息。
(2)初始化组描述信息,读取第一个块组的组描述,并存储到内存中。
(3)通过超级块中sFirstInode来获取整个EXT2文件系统的入口地址-根目录的节点号,默认为2。
(4)初始化根目录所在的节点表,并根据节点号从节点表来获取到根目录数据存放的地址空间。
(5)读取目录下存放的文件目录项,循环递归提取出每个文件的文件名等信息和文件的节点号。
(6)根据每个文件的inode号,来获取文件存放的地址空间,并将地址空间用向量形式保存起来。
(7)如果当前读取的是文件,则需要进行深入解析;如果当前读取的是目录信息,而通过递归,继续往下从步骤5开始深入解析,直到全部文件解析完成。
(8)根据每级文件存储的父子节点信息,将所有解析出来的文件构建成目录树的形式。
根据上述分析,设计出LINUX下Ext2文件系统解析的流程图如图4所示。
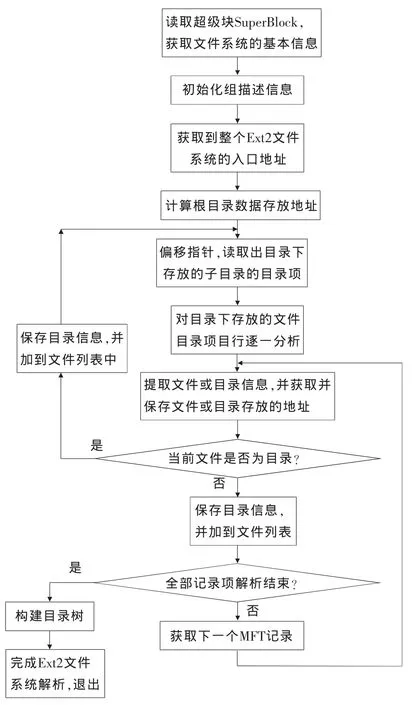
图4 Ext2文件系统的解析技术流程图
2.3 计算机自动取证模型的建立
根据目前计算机取证的基本需要,本文在获取到证据文件的基础上,构建出计算机自动取证的模型,本模型主要实现的功能包括获取用户痕迹,如上网记录、打印记录、回收站删除记录等;即时通信地解析,如对 QQ、Skype、MSN、新浪 UC、淘宝旺旺、飞信等主流聊天工具的解析,获取这些聊天工具的用户信息和聊天记录等信息,挖掘其中有用的数据供计算机取证调查分析;客户端邮件解析,如outlook express、foxmail等邮件内容的提取和分析;网页邮件的解析,如网易邮箱、GMAIL、新浪邮箱、163等主流邮件的提取和分析;文件分析和关键字搜索,如对系统日志、注册表等信息的获取,以及对敏感关键字搜索等功能,挖掘分析其中的有用线索能为案件侦破提供有力依据。通过多线程技术,实现多个功能模块的同时取证,将大大提高计算机取证的工作效率,实现对计算机的自动取证[5]。
基于计算机取证系统要实现的功能,本文建立的计算机自动取证系统的模型如图5所示。
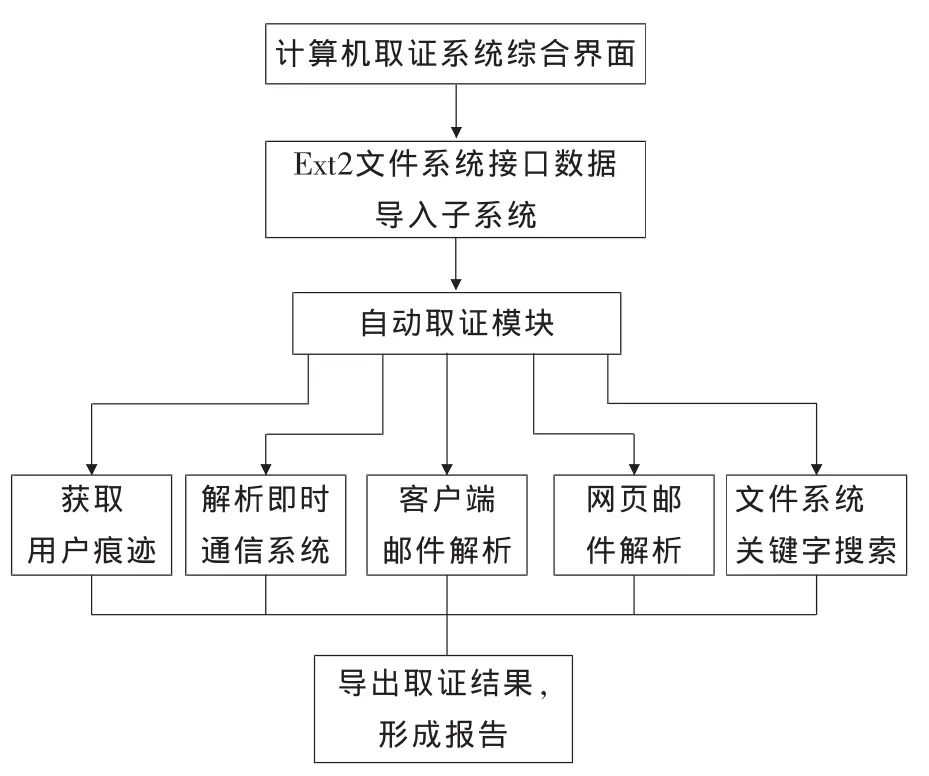
图5 计算机取证系统模型图
2.4 软件总体实现的流程图
在进行文件系统解析时,获取到设备有可能是整块硬盘,也有可能是分区,因此要对设备类型进行判断,对分区和硬盘采取不同的方法进行解析,具体软件的实现流程见图6[6]。
3 系统测试与验证
本文研究中,采用Windows XP+SP2和Linux双操作系统,在Microsoft Visual C++2005开发环境下编程实现了上述方法。在对Linux操作系统下进行多种文件系统的解析,包括Ext2、EXT3、SWAP等格式进行分区格式化,用本软件进行解析,均能得到正确的解析结果。结果表明,面向对象的Ext2文件系统解析是可行的,并且对Linux下其他文件系统解析具有一定的兼容性,解析结果具有友好的人机交互界面,为计算机取证在Linux上的进行提供了可靠的数据来源,实现计算机的自动取证。
4 结束语

图6 面向对象的Linux文件系统解析流程图
本文针对计算机取证在Linux中应用对文件系统解析的需求,提出了面向对象的Linux文件系统解析方法,即利用类之间的继承关系以及类的封装性,对不同数据源进行深度解析,为计算机取证提供了对文件操作的各种接口,同时以友好的界面形式向用户展示Linux文件信息,为计算机取证在Linux上的应用提供可靠的数据保证,对调查分析软件的研究开发具有较好的参考价值。
[1]张荣亮,余敏,余文斌.Linux文件系统内核机制分析与研究[J].计算机与现代化,2007(12):14-21.
[2]陈莉君,康华,张波.Linux的内核设计与实现[M].北京:机械工业出版社,2006.
[3]包怀忠.Ext2文件系统[J].计算机工程与设计,2005(4):1022-1024.
[4]梁金民.面向对象的系统分析与设计(UML版)[M].北京:清华大学出版社,2005.
[5]陈祖义,龚俭,徐晓琴.计算机取证的工具体系[J].计算机工程,2005,31(5):162-165.
[6]汪诗林.数据结构算法与应用C++语言描述[M].北京:机械工业出版社,2000.
