消息代理机制下的MapReduce数据流优化
2013-07-11葛君伟方义秋
葛君伟,蒋 仙,方义秋
1.重庆邮电大学 图书馆,重庆 4000652.重庆邮电大学 计算机科学与技术学院,重庆 400065
消息代理机制下的MapReduce数据流优化
葛君伟1,蒋 仙2,方义秋2
1.重庆邮电大学 图书馆,重庆 400065
2.重庆邮电大学 计算机科学与技术学院,重庆 400065
1 概述
随着当前信息时代的迅速发展,数据量日益增大,数据处理流程呈现出海量和并行的特点。传统的并行技术如网格计算,由于编程难度大并且处理流程复杂,无法满足当前数据密集型计算DIC(Data Intensive Computing)应用的需求。目前各研究机构(如:Google、Amazon)在解决专门问题领积累了重要的知识基础,随之新型的云计算环境下的并行处理技术也应运而生[1]。
其中,较为流行的是由Google提出的MapReduce并行计算编程模型,极大地简化了在集群上的海量数据处理过程。主流的Apache Hadoop开源开放平台,为MapReduce应用提供了较好的实现平台,从而促使当前大量商用的海量数据分析采用MapReduce并行计算模型。
但另一方面,MapReduce编程模型的简单化也导致了一些问题,尤其是面向数据密集型计算。由于此类应用在很大程度上依赖于集群节点间的数据传输,主节点对节点间的消息处理负载过重,最终造成运行时间长、计算结果值不理想等问题。
而消息代理机制(Message Broker Mechanism)是一种在数据源与目的地之间移动数据使信息处理流畅的消息中间件技术。为了满足云计算环境下对DIC应用的可靠性、可扩展性等方面的要求,在MapReduce并行计算框架中采用消息代理机制,兼具两者优点,并行计算简单化,消息处理独立化。
本文将消息代理机制应用于MapReduce框架中,采用消息代理和消息队列技术,优化数据流,解决面向数据密集型计算的MapReduce应用的负载均衡问题。
2 MapReduce
MapReduce框架把一些DIC应用的数据处理过程简化抽象成map和reduce两个阶段,用户在设计分布式程序时,只要实现Mapper和Reducer两个函数,将数据分片,任务调度,集群容错,集群间通信等问题,交由底层的MapReduce框架处理。
2.1 MapReduce体系架构
Google的研究人员借鉴函数式编程的设计思想,通过总结大量的大规模分布式处理程序共同特征,提出了MapReduce并行编程框架,架构图如图1。
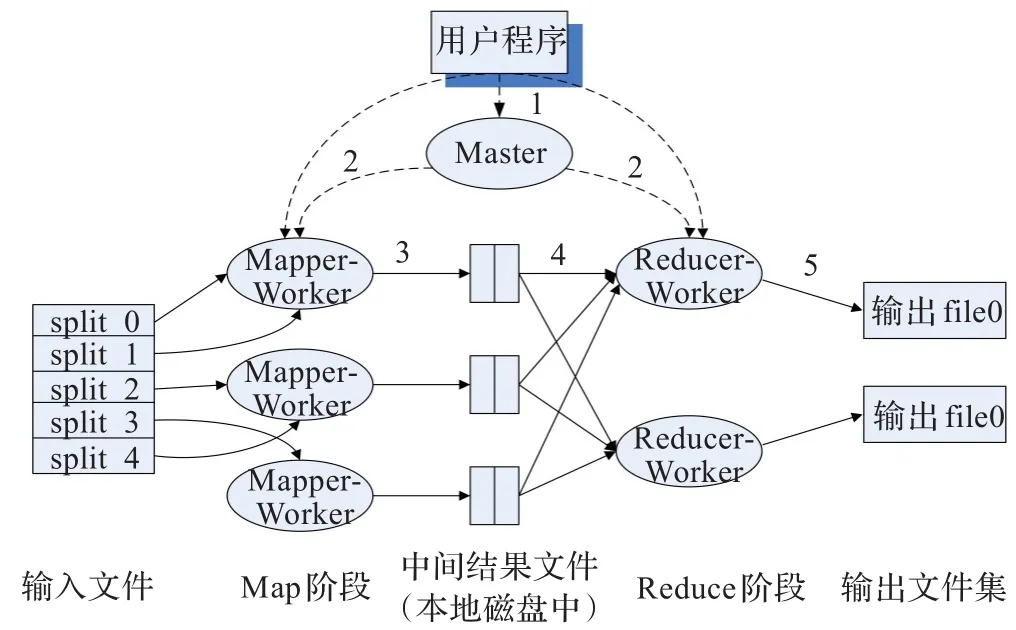
图1 MapReduce架构示意图
从图1可以看到,MapReduce体系结构中主要包括了一个Master节点和若干个Worker节点。Master Node有且只有一个,主要的工作是统一调度并且维护每个Worker Node的工作状态,具有整个架构中的控制中心;Worker Node有多个,其中 Mapper-Worker节点,完成map任务产生中间结果,Reducer-Worker节点完成reduce任务输出最终结果。具体数据处理过程见文献[2]。
从整个数据流程可以看出,MapReduce模型较好地实现了并行计算的数据处理,而且数据的分发、计算及传输对用户是透明的。
2.2 MapReduce DIC应用
基于MapReduce实现的DIC应用相比于传统计算方法,具有高效及可靠的海量数据处理优势。
DIC应用需要处理的数据具有以下几个特点:
(1)数据规模是海量的,达到了TB甚至PB量级。
(2)数据形式是多样的,往往不是真正的关系型数据(或称为结构化数据),而可能是文本、网页、XML文档等无结构或者半结构化数据。
(3)数据分布是非集中式的,存储于不同地理位置的多机架上。
MapReduce应用能自动完成数据密集型任务的分发和并行处理,如Facebook的服务事务日志分析、用户操作分析、用户点击量分析等计算,Yahoo!部署Hadoop、PIG促进开源项日研究[1]。
3 分析与设计
本文的核心是在MapReduce模型框架中引入消息代理实体,管理控制Reduce-Worker传来的接收消息;标记Mapper-Worker产生的中间结果,利用基于标签的消息队列实现异步传输模式,从而实现数据流的优化。
3.1 消息代理机制
3.2 基于消息代理机制的MapReduce模型框架
传统的MapReduce框架中Master Node依赖来自每个Worker Node的定期心跳(heartbeat)消息。每条消息都包含一个数据块报告,Master Node可以根据这个报告验证块映射和其他文件系统元数据。如果Worker Node不能发送心跳消息,Master Node将采取修复措施,重新复制在该节点上丢失的块。然而,通常数据密集型应用会随需要处理信息数据量的增大,Master Node对Worker Node的管控的工作负荷也随之而加重,节点间的消息处理负载过重,导致中间结果数据传输缺乏可靠性、负载不均,最终使得运行效果不理想。为此,将消息处理模块以独立实体形式存在于集群中,使得消息处理独立化,实现中间结果数据可靠传递。
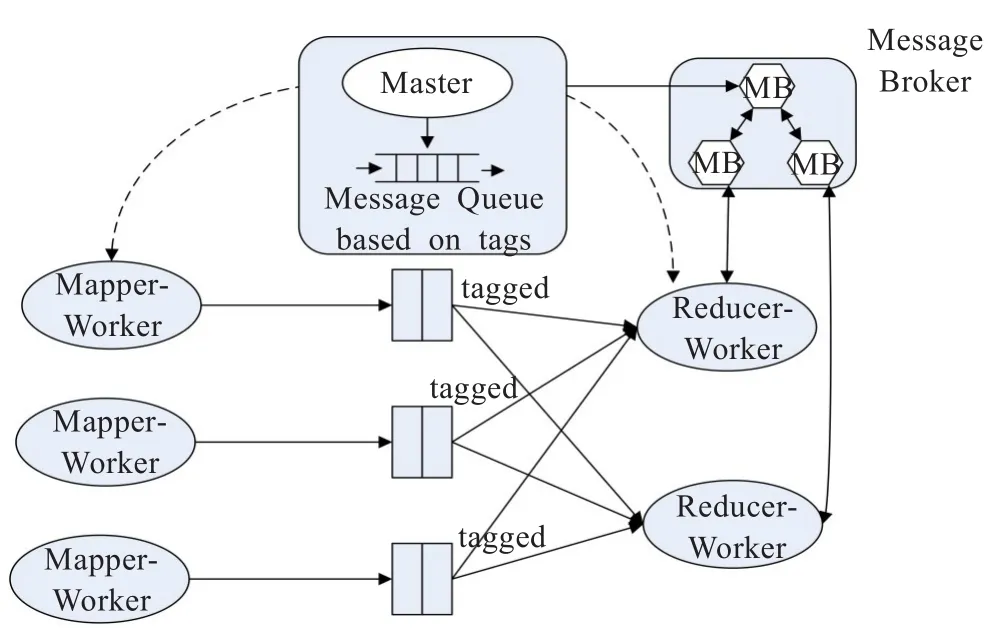
图2 基于消息代理机制的MapReduce模型框架示意图
基于消息代理机制的MapReduce模型中由Mapper-Worker通过map函数产生的中间结果值都被唯一标识。核心部分是由消息代理(Message Broker,MB)和基于标识的传输消息队列两大部分组成。MB以独立实体存在于分布式集群中,管控节点消息通信。而消息队列则驻留在Worker Node的内存中便于其各个节点的数据块传递。同时,各个接口实现消息数据的传递与处理。
消息代理的主要功能是对消息进行管理与控制,采用一对一的消息传送方式。其工作原理是:首先,当一个实例作业(job)开始执行时就会创建一个守护进程-MB进程和其主线程;然后,一旦任务分配后,各个任务(task)创建各自的独立线程,这些线程将各个节点发来的消息交由主线程处理。当Reduce任务执行完毕对应的独立线程也将转为结束状态。MB会把消息划分为三类,临时消息、持久消息和一般消息。一旦临时消息被处理完将立即删除,而持久消息则存储于MB的指定文件中,一般消息将驻留在内存,直到对应的MB线程结束。消息代理的优点表现在一方面,消息代理以独立于的实体存在,便于用户对作业运行状态的动态跟踪与实时监控;另一方面,消息代理记录存储任务执行信息,其数据可用于应用性能分析与进一步改进。
MB将处理完成后的消息都捎带一个标识符,此标识符与各自中间结果值的标识符一致。这些消息通过MB与主节点的通信接口,传递到主节点的预留缓存区,对应的标识符也将送入到消息队列中。Master Node的JobTracker进程将从队列中遵循先进先出读取各个消息,并依据消息内容分配调度TaskTracker进程需要的资源。读取后的消息在Master Node调度完各个reduce任务之后再次返回给MB记录并销毁。
基于消息代理机制的MapReduce模型下,相比于传统模型在数据流上有所改变,从图3可对比得出。
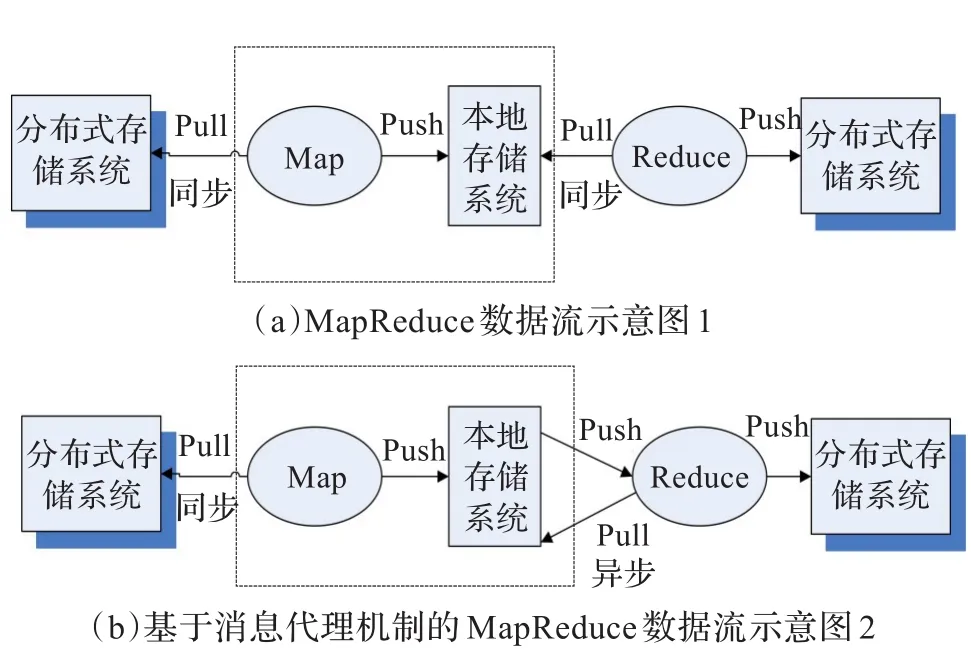
图3 MapReduce数据流对比示意图
由图3可以看出,传统的MapReduce数据流(示意图1)可简单概述为:首先,将存储于分布式存储系统中的每个输入文件从各个map工作节点中获取(Pull)而来,进行map函数计算。然后,中间结果值以推(Push)方式存储于本地系统。同样reduce工作节点以远程传输方式获取(Pull)数据源,再将计算完的最终结果值推(Push)入分布式存储系统。整个MapReduce的数据流处理对于每个工作节点来说都是同步实现的。而基于消息代理机制的框架下(示意图2),由于消息代理对消息的独立处理,使得数据流在中间结果值到reduce工作节点变为了异步传输方式,本地存储系统可以主动将数据推送(Push),也可以是reduce工作节点主动获取(Pull)数据。从数据流角度看,大大减缓了数据传输上的压力。
4 实验测试
本实验的测试环境是由美国印第安纳州大学India. Futuregrid.Org(https://portal.futuregrid.org/)提供的Eucalptus云计算IaaS(Infrastructure as a Service)服务,其中使用到的硬件配置清单见表1。实验的运行环境是由一组实例化虚拟集群组成,通过配置其镜像系统(Linux 2.6.x),自主搭建的Hadoop[3](Apache Hadoop-0.20.2版本)集群(本实验选的集群大小为10个虚拟镜像),NarabaBroker(4.4.2版本)为消息代理实体。
本实验通过Last.fm网络音乐电台对用户提供的公共API接口,获取其音乐家信息元数据集,在此数据集上计算各个音乐家之间的相似度。此实例在两个不同的计算环境上运行,Sim-c1-MB(MB运行的节点配置为c1)和Sim-m1-MB(MB运行的节点配置为m1),用Linux系统下命令记录它们在1min、5 min和15 min时间间隔的平均负载变化,如图4、5。
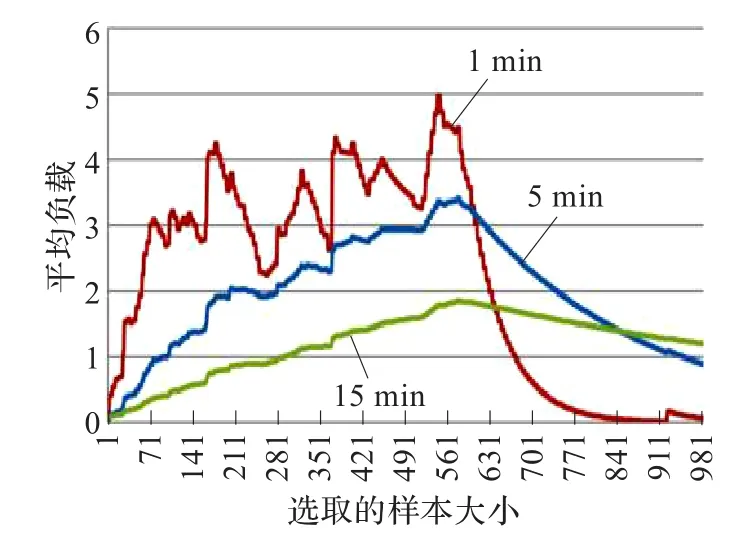
图4 Sim-c1-MB的平均负载
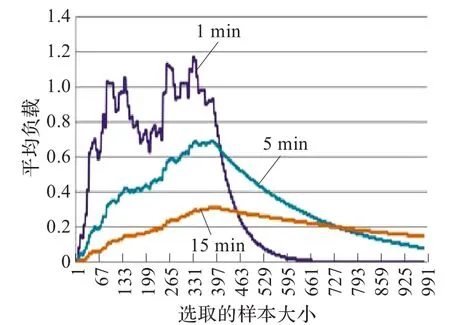
图5 Sim-m1-MB的平均负载
随着计算的运行,消息代理支配节点间的数据传输和资源调度,各时间点的进程状态是动态变换的(等待或运行),因此集群的平均负载值也随之波动,直到计算结束波动曲线也趋近为零。
比较图4和图5可以看到,Sim-c1-MB的平均负载整体上远大于Sim-m1-MB,即排队等待运行的平均进程数远大于Sim-m1-MB。图4中Sim-c1-MB的等待运行平均进程数为3.35,最大进程数为5.01,而图5中Sim-m1-MB分别为0.79和5.01。两者的运行时间分别为352 s和237 s。
从实验中可以得出,数据密集型计算的性能依赖于消息代理的配置;消息代理的消息处理能力直接影响节点间的数据传输效率。实验证明,基于消息代理机制的MapReduce框架能提高数据密集型应用上的负载均衡。
5 总结与展望
综上所述,面对处理海量数据处理,基于消息代理机制的MapReduce改进模型在运行效率上有一定的提高。但由于本文只针对MapReduce的数据密集型应用进行数据流优化与实验分析,具有一定的局限性,并且观察该模型框架在其他问题域的应用性能研究有待进一步展开。

表1 硬件配置清单
[1]孙兆玉,袁志平,黄宇光.面向数据密集型计算Hadoop及其应用研究[C]//2008年全国高性能计算学术年会.无锡:[s.n.],2008.
[2]Dean J,Ghemawat S.MapReduce:simplified data processing on large clusters[C]//Proceedings of the 6th Symposium on OperatingSystem DesignandImplementation.New York:ACM Press,2004:137-150.
[3]Apache Hadoop.Hadoop[EB/OL].[2009-03-06].http://hadoop. apache.org/.
[4]Condie T,Conway N,Alvaro P,et al.MapReduce online,UCB/EECS-2009-136[R].Berkeley:EECS Department,University of California,2009.
[5]戴俊,朱晓民.基于ActiveMQ的异步消息总线的设计与实现[J].计算机系统应用,2010,19(8):254-257.
[6]李乐平,吴泉源.消息代理中间件InforBroker中集群技术的应用[J].微计算机信息,2006,22(27):140-142.
GE Junwei1,JIANG Xian2,FANG Yiqiu2
1.Department of Library,Chongqing University of Posts and Telecommunications,Chongqing 400065,China
2.College of Computer Science and Technology,Chongqing University of Posts and Telecommunications,Chongqing 400065,China
MapReduce programming model is a kind of parallel computing framework which is distributed under the environment of mass data processing system.Currently,the MapReduce applications are widely used for commercial data intensive computing,the data transmission between the nodes on cluster has a large extent dependence.It causes that the load of message handling between the nodes is heavy.This paper puts forward an improved model of MapReduce based on message broker mechanism,to optimize the MapReduce data flow.The experimental data indicates that based on message broker mechanism the MapReduce framework can improve the load balance in data intensive applications.
message broker;MapReduce;data intensive computing;data flow
MapReduce编程模型是广泛应用于云计算环境下处理海量数据的一种并行计算框架。然而该框架下的面向数据密集型计算,集群节点间的数据传输依赖性较强,造成节点间的消息处理负载过重。提出基于消息代理机制的MapReduce改进模型,优化数据流。经实验数据表明,基于消息代理机制的MapReduce框架能提高数据密集型应用上的负载均衡。
消息代理;MapReduce;数据密集型计算;数据流
A
TP391
10.3778/j.issn.1002-8331.1107-0421
GE Junwei,JIANG Xian,FANG Yiqiu.Optimization of MapReduce data flow with message broker mechanism.Computer Engineering and Applications,2013,49(5):120-122.
葛君伟(1961—),男,博士,教授,主要研究领域为云计算、软件工程;蒋仙(1987—),女,硕士研究生,主要研究领域为并行计算;方义秋(1963—),女,副教授,主要研究领域为中间件技术。E-mail:gejw@cqupt.edu.cn
2011-07-20
2012-01-13
1002-8331(2013)05-0120-03
