地震多属性优选技术的研究与应用
2013-05-11李艳芳
李艳芳,王 成
(中煤科工集团 西安研究院,陕西 西安 710077)
为了减少地震属性解释的多解性,提高构造解释和岩性预测精度,常用多种优化属性联合分析,用以提高预测精度、降低勘探开发风险。随着地震属性技术的发展,地震属性的种类数量增多,因此必须优选地震属性。地震属性优化就是优选出对求解问题最敏感、最有效、最有代表性的属性[1],选出适于工区情况的最佳属性组合。属性优化的方法可分三类:基于模型正演的属性优选、基于数理统计的属性优选、基于人工智能的属性优选。
1 基于模型正演的属性优选
地震模型正演是在假定已知地下介质的结构模型和相应物理参数的情况下,模拟地震波在地下各介质中的传播规律,并计算在地面或地下各观测点所观测到的数值地震记录的一种地震模拟方法,分为物理模拟和数值模拟。地震模型正演技术在地震数据采集、处理、解释领域有着广泛应用。在地震数据采集方面,模型正演有助于合理选择地震采集参数和优化观测系统设计,从而获得高质量的采集资料。在地震数据处理方面,模型正演可帮助选择处理参数,改善处理质量。在地震资料解释方面,模型正演能验证解释结果,提高解释成果精度。在地震属性分析中,除了根据以往经验可做出定性的判断外,可在很大程度上依靠地震模型正演的测试结果。因已知的地质资料毕竟有限,地震模型可视为能替代钻孔的已知资料,地震数学模型正演模拟对属性参数的优选、组合、以及后续的属性灵敏度分析等,都很重要[2]。
2 基于数理统计的属性优选
数理统计法是利用数学方法优选一些属性进行储层预测,例如相关法、粗集、依据井旁地震属性值与测井特征值计算地震属性的有效性等,它是直接利用数学方法选出一些理想的属性、然后分析,删除一些认为不合理的属性,最后利用剩下的一些属性进行预测。其优点是:减少了解释人员的工作量,不要求对工区和地震属性含义进行深入理解,比较客观;缺点是可信度不高,优选的地震属性有时没有明确地质意义。
1)直方图分析。属性提取后,不能盲目分析属性数据,需对各个属性统计分析,以便了解各属性数据的大致情况(包括:直方图分布、相关统计信息、采样点个数、最大值、最小值、均值、协方差等)。图1为某工区异常值删除前后的属性直方图,对其明显的尖峰,通过研究发现:该工区为不规则形状;并在属性提取时,对Inline和Crosslink插值后,范围为矩形;图中的尖峰为0值的样点数,代表了矩形范围外的0值,可认为是区域背景;如果不对此加以处理,将使工区内的局部异常淹没在区域背景中。
2)相关分析。它是描述两个或两个以上变量间关系密切程度的统计方法,变量间关系的密切程度常以一个数量性指标相关系数描述,它是社会学中常用的分析方法。相关分析可分类为:直线相关、非直线相关。并可进一步根据变量层次和数目分类。相关分析可直观地排除接近正相关或负相关的属性。
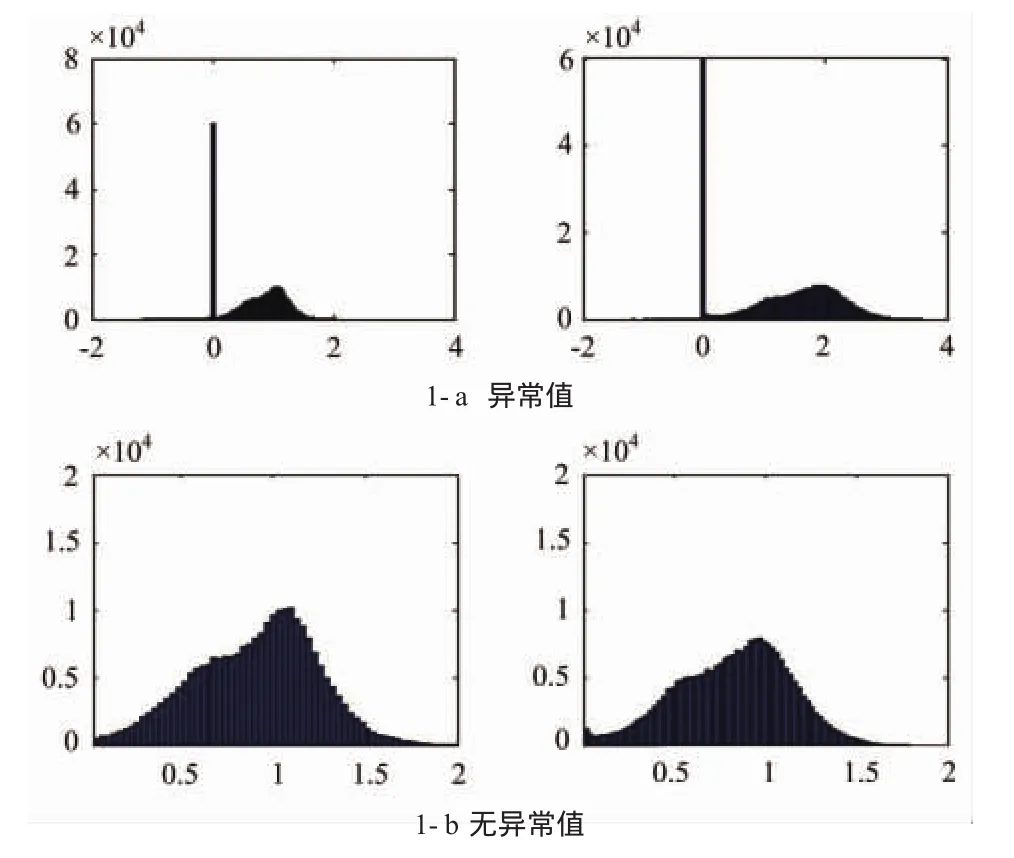
图1 异常值删除前后的属性直方图
3)聚类分析(Cluster Analysis)又称群分析:它是对样品或指标分类的一种多元统计分析方法,它的对象是大量样品,要求合理地按各自的特性进行分类,即在没有先验知识的情况下进行分类。聚类是将数据分类到不同的类或簇的过程,同一簇的对象有很大相似性,不同簇间的对象有很大相异性。聚类分析的目标是在相似的基础上收集数据分类。若将聚类分析和其它方法(例如判别分析、主成分分析、回归分析等)联合起来使用效果更好。
4)主成分分析(Principal Component Analysis ,PCA)也称主分量分析:旨在利用降维思想,在损失很少信息的前提下,把多指标转化为少数综合指标,即主成分;这些主成分要能反映原始变量的绝大部分信息,通常为原始变量的线性组合;各主成分之间互不相关、且按照方差依次递减的顺序排列。主成分分析的计算过程依次为:计算相关系数矩阵、计算特征值与特征向量、计算主成分贡献率及累计贡献率、计算主成分载荷[3]。
3 基于人工智能的属性优选
传统的地震属性优选方法是在某种单一属性与储层参数之间建立关系,例如图2是储层孔隙度参数(porosity)与某种地震属性的交会图,采用线性关系优选属性的方法简单,但预测精度低,图中的拟合精度只有29.8%;此考虑非线性优选。Schultz、Ronen、Hattori、Corbett、谢雄举等提出了地震多属性非线性优选的思路方法[4]。运用人工智能进行属性优选的关键问题是:如何从n种属性中选出m种最优属性,常用的方法有[4]:①穷尽搜索。希望从n种属性中选出m种属性,测试所有m种属性的组合,在所有组合中预测误差最低的就是所求解;若从25种属性中选出5种最好组合,将会有53130种组合,运算量大,耗时长。②单步寻优算法。虽不是最优化,但运算速度快;其理论假设是:已知最好的m种属性组合,那么最好的m+1种属性组合一定包含这m种属性的最优组合,当然以前计算的系数必须被重新计算。具体的实现步骤为:设有多种属性,第一步通过穷尽搜索找出最好的一种属性,称为属性1;第二步在所有与属性1组合的属性中通过求取最小预测误差找出最好的一对属性,称为属性2;然后依次类推。利用这种方法运行时间大大短于穷尽搜索。

图2 属性交会图
3.1 神经网络
人工神经网络 (Artificial Neural Network,ANN)是模拟生物神经网络的结构和功能的人工系统。人工神经网络算法在确定两个测量变量之间的非线性函数关系,特别是未知非线性函数关系方面,具有速度快、误差小的优点;作为多学科的交叉科学,神经网络的并行处理能力、自组织自学习能力、高度的计算能力,引起人们的普遍兴趣[4]。目前,在地震、重力、电磁法、磁法等方面都进行了应用探索。1986年Rumelhart提出了反向传播(Back Propagation)学习算法(BP算法),目前应用最广模型之一。BP网络能学习和存贮大量的输入-输出模式映射关系,它的学习规则是用最速下降法,通过反向传播调整网络的权值和阈值,使网络的误差平方和最小。运用神经网络进行多属性优选,以较大的训练样本量为基础,但随着样本数量的增加,有可能相关性反而降低,出现“过拟合”现象(见图3)。

图3 训练数据过拟合图
3.2 支持向量机
支持向量机 (Support Vector Machines,SVM)是Corinna Cortes和Vapnik等于1995年提出,以最小化错误率的理论界限为思想,以统计学习理论(Statistical Learning Theory,SLT)为基础,服务于小样本统计估计和预测学习的一种新的机器学习方法。它能根据有限样本信息在模型的复杂性和学习能力之间寻求最佳折衷,提高模型的泛化能力,得到全局最优解,又不存在“过拟合”问题,较好地解决了小样本的学习问题。支持向量回归是用一个非线性映射将训练数据集非线性映射到一个高维特征空(Hilbert空间),并在此空间中构造最优分类超平面,以求最优解的实现过程[5]。针对地震勘探中已知样本数目偏少的实际情况,可用基于SVM方法进行多属性的非线性优选。图4为某工区运用已知孔插值形成的预测图,图5为运用基于SVM的属性优选后的预测图。
4 结束语

图4 已知孔插值形成的预测图

图5 SVM预测图
本文从模型正演、数理统计、人工智能方面讨论了地震多属性的优选技术;阐述了运用相关分析、聚类分析、主成分分析、神经网络进行地震属性的优选方法;重点阐述了基于小样本的支持向量机优选属性方法,并将SVM方法和多属性优选方法应用于煤层气预测中。实际资料应用结果表明,针对地震勘探中已知钻孔较少的情况,基于SVM的属性优选方法是一种较为有效的方法。
[1]印兴耀,周静毅.地震属性优化方法综述[J].石油地球物理勘探,2005,40(4):284-289.
[2]蒋先艺,刘贤功,宋葵.复杂构造模型正演模拟[M].北京:石油工业出版社,2004.
[3]印兴耀,孔国英,张广智.基于核主成分分析的地震属性优化方法及应用[J].石油地球物理勘探,2008,43(2):179-183.
[4]谢雄举,季玉新.优选地震属性预测储层参数的方法及其应用[J].石油物探,2004,43(S):127-131.
[5]遵德.储层地震属性优化方法[M].北京:石油工业出版社,1998.
