针对搜索服务的操作系统伸缩性研究*
2013-05-08赵玉龙
赵玉龙,王 雷,王 欢
(北京航空航天大学计算机学院,北京100191)
1 引言
操作系统的可伸缩性,是指操作系统随着CPU核数的增加性能增长的能力。如果随着CPU核数的增加系统整体性能呈现线性增长(理想状况)或类似线性增长,则系统的可伸缩性较好。反之,如果随着CPU核数的增加,系统整体性能增长趋势缓慢,或者呈现降低趋势,则系统的可伸缩性不好。
在学术界和工业界研究类Unix系统在共享内存多处理器系统上的伸缩性已有很长历史。研究性项目如 Stanford FLASH[1]以及 SGI、IBM、Sun等公司都已生产拥有几十到几百个处理器的共享内存机器,运行着各种Unix变种。有很多技术用来促使软件伸缩到多核机器上,包括可伸缩锁[2]、无等待 同 步[3]、多 处 理 器 调 度 器[4]、NUMA结构内存[5,6]和基于共享内存的快速消息传递[7]等。
针对搜索服务的Linux内核的伸缩性,提供搜索服务的反向代理服务器是本文研究的重点。首先通过伸缩性实验,分析系统性能数据,找出Linux系统在多核系统下的效率瓶颈,并对Linux内核进行了改进,取得了一定的研究成果。具体的研究内容和取得的主要成果包括:
(1)伸缩性研究实验设计。对于运行Nginx反向代理的64CPU核Linux服务器,每次实验通过设置Linux内核的启动参数maxcpus来启用不同数目的CPU核数,对比不同CPU核数下系统性能差异,实验结果表明该Linux服务器伸缩性不佳。
(2)网卡中断处理负载均衡改进。本文使用ftrace和systemtap等Linux上的动态追踪、性能分析工具来获取系统实验时的一些微观数据,通过这些数据发现瓶颈在于服务器上所有网卡中断和软中断处理都集中在一个CPU核上。对比了Linux系统的RPS(Receive Packet Steering)机制、网卡的 RSS(Receive Side Scaling)机制和 Flow Direction机制,发现对于本系统的64核平台来说,Flow Direction机制的性能是最优的,结合Linux中断的亲和性配置,可以把网络数据包的接收处理分散到所有的CPU核上,可使系统平均吞吐量提升33%左右。
(3)TCP连接亲和性改进。多核环境下网卡中断负载均衡无法保证TCP连接的亲和性,不能保证一个TCP连接的数据包的底层网卡硬件中断、软中断处理与处理该TCP连接的Nginx worker进程在同一个CPU核上运行。本文通过修改Linux内核代码,把内核中TCP监听套接字的全局icsk_accept_queue队列拆分成per-core accept队列,解决了TCP连接的非亲和性问题,吞吐量在之前提升的基础上,又提升了9%。
2 相关工作
2.1 Linux内核伸缩性的发展
Kleen[8]主要介绍了Linux的多核伸缩性。Linux从2.0版本开始支持SMP系统,整个内核包括中断处理程序都在一个大内核锁控制下,内核代码不能被多个处理器并行执行,任何时候最多只有一个处理器可以运行在内核状态下,用户空间代码可以并行执行。
在Linux 2.2内核,大内核锁仍然被用在大部分内核代码上,除了中断处理程序有了自己的自旋锁,允许中断处理程序并行执行。
到Linux 2.4内核,越来越多的子系统从大内核锁的控制下移出。一些数据锁被引入,但是仍然有很多代码锁(锁住整个子系统的自旋锁)。这在很大程度上提升了伸缩性,Linux已经可以在大型系统上很好地运行,但是也有很多瓶颈问题未解决。
在Linux 2.6系列版本中,极少的代码是在大内核锁的控制下,大多数在公共执行路径上的代码锁被转换成数据锁,并且有许多伸缩性的优化来消除共享缓存的抖动。对于关键的子系统,使用了许多先进的消除锁的技术,比如RCU(Read-Copy Update)[9]。引入了一个新的多队列CPU 调度器,避免了对被多个处理器共享的全局运行队列的竞 争,降 低 了 调 度 多 核 并 行 程 序 的 负 载[10,11]。Linux 2.6内核对NUMA架构的支持也越来越完善,在调度器、存储管理、用户级API等方面进行了大量的 NUMA优化工作[12,13]。大量的共享数据被设计成per-CPU结构,以避免被多个核争用。
2.2 Linux伸缩性的研究
Boyd-Wickizer S等人[14]探讨了传统操作系统内核设计是否适合现在的多核环境,他们以Linux内核作为实验对象,测试分析了七个系统软件 (Exim、memcached、Apache、PostgreSQL、gmake、Psearchy和 MapReduce)在运行linux-2.6.35-rc5的48核系统上的伸缩性。结果表明,除了gmake之外,其他六个软件都触发了Linux伸缩性方面的瓶颈。发现的瓶颈包括:对共享数据的争用,比如共享的队列、共享计数器、false sharing和一些不必要的锁。解决的办法包括,把共享队列拆分成per-CPU队列;用他们自己设计的可伸缩计数器来替代引起性能瓶颈的共享计数器,也是类似于per-CPU技术,让每个处理器都有一个计数器的副本;用lock-free技术替代锁来保护一些共享数据;把经常修改的共享数据放在不同高速缓存行中来避免false sharing;精心设计部分代码消除某些不必要的锁。通过这些技术,Boyd-Wickizer S等人消除了内核中的这些瓶颈,使得测试程序的性能在多核环境下大幅提升。结果表明,没有直接的伸缩性原因使得要放弃传统的内核设计。
Gough C等人[15]研究 Oracle Database 10g在运行 Linux 2.8.18内核的dual-core Intel Itanium处理器平台上的伸缩性,发现问题在于Linux内核的运行队列、slab分配器和I/O处理。
Cui等人[16]提出了一个用于测试类Unix系统多核伸缩性的微观测试基准程序OSMark,并且用运行Linux 2.6.26.8的 AMD 32核平台来进行评测。微观测试基准程序分别测量Linux内核不同子系统的伸缩性,包括:进程创建与删除、mmap文件创建与删除、文件描述符操作、socket套接字创建与删除和System V信号量操作。结果表明大部分被测试的Linux内核的伸缩性都很差。他们分析后发现,内核中用来保护共享数据的同步原语是限制并行伸缩性的主要原因。Cui Yan等人[17]也评估和比较了 Linux、Solaris和 FreeBSD在AMD 32核平台上的并行伸缩性。对于OSMark的测试,没有一个操作系统表现得完全比另外两个都好,对于并行应用程序postmark,Linux和Solaris不相上下,都优于FreeBSD。
在Cui Yan等人[18]的另一篇论文中,他们使用TPCC-UVa与Sysbench-OLTP测试基准程序和PostgreSQL来研究OLTP(Online Transaction Processing)应用程序在运行Linux 2.6.25内核的Intel 8-core平台上的伸缩性。他们提出一个基于函数伸缩性值的方法来寻找伸缩性的瓶颈。一个函数的伸缩性值被定义为该函数在多核环境下的执行时间减去对应单核环境下的执行时间,通过仔细研究在内核、库、应用程序进程中高伸缩性值的函数,他们发现数据库缓存池竞争、内核调度器和System V进程间通信中的锁竞争是TPCC-UVa的主要瓶颈。对于Sysbench-OLTP,数据库同步原语和内核调度器限制了它的伸缩性。
Veal B和 Foong A[19]使用 SPECweb2005测试基准程序来评估Apache在运行Linux 2.6.20.3内核的8核AMD Opteron系统上的伸缩性。他们确定Linux内核伸缩性问题在于进程调度和目录查找。Boyd-Wickizer S等人[14]也发现目录查找时加在目录项上的自旋锁是一个伸缩性瓶颈,尽管Linux内核中已经用RCU来优化目录缓存的伸缩性[20],但是公共父目录(比如/usr)的目录项自旋锁有时会成为瓶颈,即使路径名最终指向不同的文件。
开源项目 Linux Scalability Effort致力于解决大型系统上Linux内核的伸缩性问题[21],由几个子项目组成,针对Linux不同方面的伸缩性问题,包括:Linux-on-NUMA项目、多核进程调度、锁原语、异步I/O、epoll伸缩性、可伸缩的计数器。该项目中所讨论的很多伸缩性技术已经被现在的Linux内核使用。
3 针对搜索服务的Linux伸缩性实验
用户在使用互联网公司(百度、Google等)提供的搜索服务时,一般通过浏览器向Web服务器发送HTML请求,互联网公司架设的反向代理Web服务器接收用户请求,把请求转发给公司内网的搜索引擎,搜索引擎根据请求产生结果后,再通过Web服务器把结果转发给用户。Web服务器在中间起代理和中介的作用,其效率和吞吐量直接影响搜索服务的响应时间。
本文研究提供搜索服务的Linux多核平台的伸缩性瓶颈及其改进办法。要发现Linux内核的伸缩性瓶颈,需要测量它在不同CPU核数下的性能差异,分析具体的微观数据。本节将先介绍实验平台,然后给出操作系统伸缩性实验设计和实验结果。
3.1 实验平台设计
为了测试提供搜索服务的Linux的多核伸缩性瓶颈,需要有客户端、搜索引擎端和中间反向代理服务器一起构成实验环境。
如图1所示,整个实验环境包括三台客户机,负责发起请求;三台服务器,实际处理用户搜索请求的机器;中间一台服务器充当反向代理。
三个client和三个server:一颗四核i7-2600 CPU,4GB内存,Intel 82579LM 千兆网卡,是一个UMA (Uniform Memory Access)系统,四个处理器核分别拥有自己的32KB八路组相连L1高速数据缓存和指令缓存、256KB八路组相连L2高速缓存,并且共享16路组相连8MB L3高速缓存。
中间反向代理服务器:超微H8QGI64核服务器,四颗16核心的AMD Opteron(TM)Processor 6272CPU 芯片,128GB内 存,Intel X520T2万兆网卡。一颗6262芯片由八个Bulldozer模块组成。一个Bulldozer模块有两个处理器核心,每个核心有16KB四路组相连L1数据缓存,共享64KB二路组相连L1指令缓存,共享2MB 16路组相连L2高速缓存。四颗6272芯片组成一个八节点的NUMA系统,节点之间用HT总线互联。
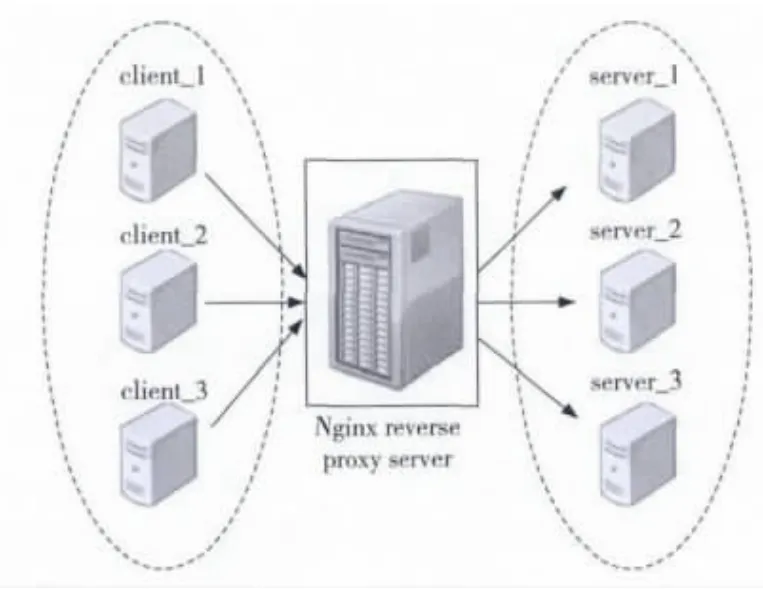
Figure 1 Topology of experimental图1 实验环境拓扑图
3.2 实验结果及分析
在建立好实验环境后,在三个server上运行genData,模拟搜索引擎,提供搜索服务。本文使用Firebug[22]工具,选取20个常用搜索关键词作测试点,测得百度、搜狗、谷歌和有道的搜索结果页的平均大小如表1所示。本文的研究主要针对百度公司的搜索引擎,所以设置genData在接收到用户请求后返回18.8KB大小的随机内容。
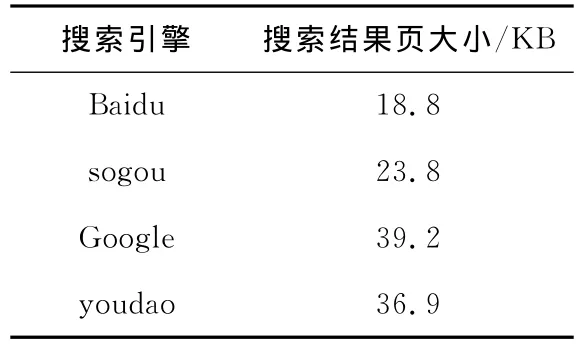
Table 1 Result page size of 4search engines表1 四个搜索引擎的搜索结果页大小
在三个client机器上运行webbench,设置并发量为1 000,向中间Nginx服务器发送搜索请求。在中间反向代理服务器上运行Nginx作反向代理服务。首先,设置Nginx服务器的Linux内核的启动参数maxcpus=1,只启动一个CPU核,在该CPU核上启动三个Nginx worker进程,进行实验,测试10分钟内整个系统共处理的请求数。然后逐次增加Nginx服务器启用的CPU数,利用Linux进程的亲和性设置,在每个启用的CPU核上启用并绑定三个Nginx worker进程,测试10分钟的系统处理请求数,结果如图2和图3所示。
图2横坐标表示本次实验中间Nginx服务器所启用的CPU核数,在每个使用的CPU核上启动三个Nginx进程,并绑定到该CPU核上;纵坐标表示相应CPU核数实验的请求量。从图2可以看出,中间Nginx服务器启用的CPU核数超过八个后,再启用更多的CPU核对整个系统的性能提升不大。
图3中横坐标的意义与图2的一样,纵坐标表示平均到每个使用的CPU核的每秒吞吐量,单位是requests/s/core。从图3中曲线的快速下降可以看出,本Nginx服务器的CPU伸缩性不佳,系统的性能没有随启用的CPU核数而线性上升,在理想伸缩性情形下,图3中的线应该是一条接近水平的线。
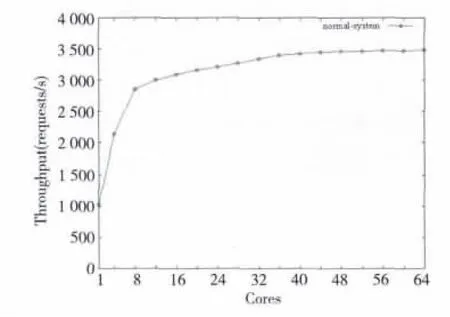
Figure 2 Throughput of the Nginx server with different number of CPUs图2 在不同CPU核数下的Nginx服务器吞吐量
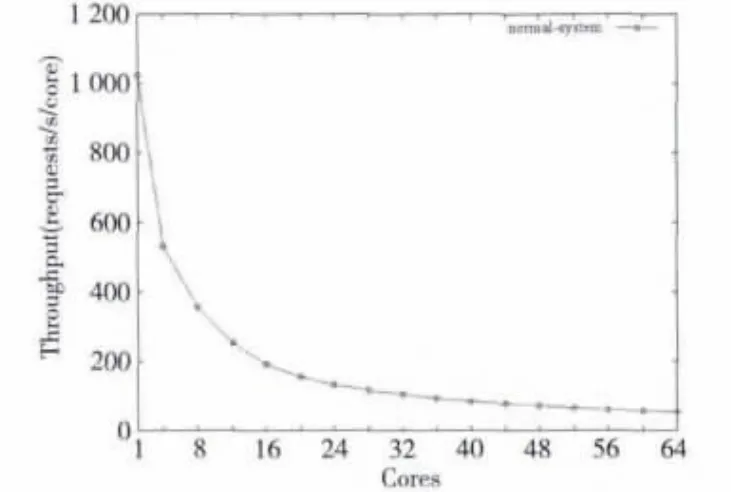
Figure 3 Average throughput on every CPU of the Nginx server with different number of CPUs图3 在不同CPU核数下Nginx服务器平均到每个CPU核的吞吐量
最后经过仔细研究发现,系统瓶颈出现在Nginx服务器上操作系统的网卡中断和软中断处理,即网卡硬件中断处理程序和网络协议栈程序。以Nginx服务器启用64核的实验为例,所有发送的网络数据包的网卡中断和软中断处理均在Nginx worker进程所在的CPU核上处理,如图4所示,这样的负载分担很好地发挥了多核处理器的能力。
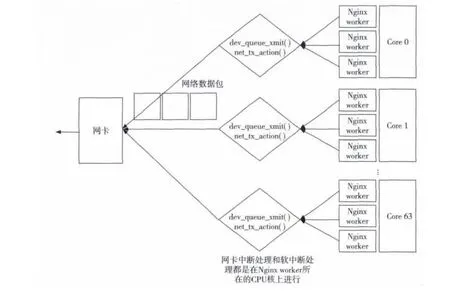
Figure 4 Packet and NIC interrupts and soft interrupt handling schematic启用64核时,数据包发送的网卡中断和软中断处理均在上层应用Nginx所在的CPU核上
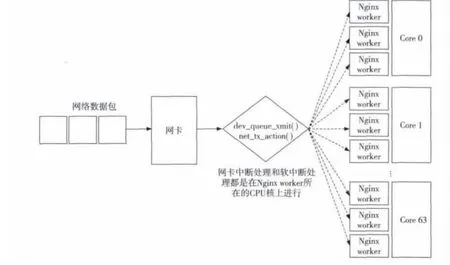
Figure 5 Packet receive NIC interrupts and soft interrupt handling schematic图5 启用64核时,数据包接收的网卡中断和软中断处理均在Core 0上处理
然而所有接收网络数据包的网卡中断处理和软中断处理都是在Core 0上进行,如图5所示,造成Core 0上的负载过重,成为系统吞吐量提升的瓶颈。在启用了64核的实验环境下,用Linux内核的ftrace工具测得网络数据包接收的网卡中断处理和软中断处理的平均用时是62.7μs,通过读取/proc/interrupts,测 得 10 分 钟的 时 间 里,在Core 0上共发生9 077 448次数据包接收中断。可以算出Core 0花在数据包接收处理上的时间百分比是:9077448*62.7μs/(10*60s)*100%=93.8%。以此,本文认为数据包的接收处理集中在Core 0上,而且Core 0的处理能力有限,是本系统的一个主要伸缩性瓶颈。下面将给出一个解决本系统数据包接收处理负载的方案。
3.3 数据包接收硬件中断和软中断的负载均衡改进评测
对于本系统中的64核Nginx服务器上的X520-T2网卡,需要选一个合适本系统的方案来消除网卡中断处理的伸缩性瓶颈。
Linux内核的RPS是Google工程师Tom Herbert提交的内核补丁,在2.6.35进入Linux内核。这个patch采用软件模拟的方式,实现了多队列网卡所提供的功能,把数据包接收的软中断处理分散到各个CPU处理。
X520-T2的RSS是一种把网络包分配到不同的硬件接收队列上的机制,对数据包的包头的五元组(源IP、目的IP、源端口、目的端口和协议)进行哈希运算,哈希值的低七位用来索引一个128表项的表,每个表项四个bit,用来标识一个接收队列。RSS将不同的流负载到不同的CPU上,同一流始终在同一CPU上,避免TCP顺序性和CPU并行性的冲突。
Flow Direction是另一种多接收队列机制,可以把不同数据包映射到64个硬件接收队列。Flow Direction在一个哈希表中查找一个流对应的硬件接收队列。这个哈希表存储在网卡中,并且通过一些指令内核可以修改该表,每个表项映射一个流的哈希值到一个6bit的硬件接收队列标识符。
如果采用Linux内核的RPS机制,则不能充分发挥X520-T2的多硬件接收队列的优势,若采用网卡的RSS机制,最多只能启用16个硬件接收队列,绑定到16个CPU核上,不能充分利用64个CPU核。所以,本文最终采用X520-T2提供的Flow Direction队列功能。
启用X520-T2的多硬件接收发送队列、MSIX中断、Flow Direction特性,在系统中会出现64个网卡接收发送中断。通过设置中断的CPU亲和性,绑定该网卡64个接收发送中断到Nginx服务器的64个CPU核上,关闭Linux内核的RPS机制,让数据包的网卡中断和软中断在一个CPU核上处理。然后再进行3.2节中的实验,与3.2节的实验结果进行对比,得到的结果如图6和图7所示。
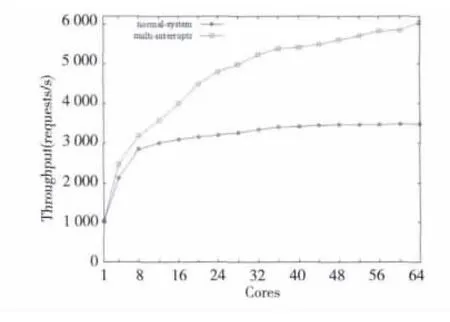
Figure 6 Nginx server throughput comparison图6 消除网卡中断瓶颈后的Nginx服务器吞吐量对比
图6 中,曲线multi-interrupts是配置启用网卡多硬件接收队列、多个MSI-X中断后进行的实验,曲线normal-kernel是3.2节中的实验,作为对比。横坐标表示本次实验Nginx服务器所启用的CPU核数,在每个使用的CPU核上启动三个Nginx进程,并绑定到该CPU核上,纵坐标表示相应CPU核数实验完成的请求次数。从图中可以看出,从1核到64核平均吞吐量上升了33%,启用64核时,改进后的系统吞吐量上升了84%。
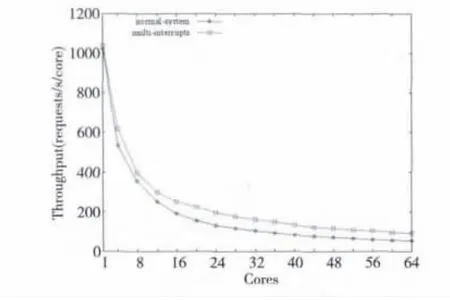
Figure 7 Nginx server throughput comparison on each CPU图7 消除网卡中断瓶颈后的Nginx服务器每CPU核吞吐量对比
图7 中,横坐标的意义与图6的相同,纵坐标表示平均到每个启用的CPU核的每秒吞吐量。平均到每CPU核的每秒吞吐量也有对应的提升。
下面再从微观方面观察,启用Flow Direction机制后网卡硬件中断处理和软中断处理是否实现负载均衡。
重点对比分析启用64个CPU核时的实验,未启用网卡多接收发送队列,网卡中断的分布如图8所示。图8横坐标表示64个CPU核的每个核的id,纵坐标表示整个实验过程中发生在该CPU核上的数据包接收网卡中断次数。从图8中可以看出,所有的网卡中断和软中断处理都在Core 0上进行,造成了瓶颈。
图9则是启用网卡Flow Direction多接收发送对列进行64核实验时数据包接收网卡中断分布。从图9可以看出,网卡中断比较均匀地分散在所启用的64个CPU核上,由于未启用Linux内核RPS机制,数据包接收软中断也在对应网卡中断的CPU核上处理,故而也实现了均衡。

Figure 8 NIC interrupt distribution on 64CPUs without flow direction图8 未开启Flow Direction启用64核实验时网卡中断分布

Figure 9 NIC interrupt distribution on 64CPUs with flow direction图9 开启Flow Direction启用64核实验时网卡中断分布
4 TCP连接亲和性改进
在第3节的实验中,本文通过配置Nginx服务器上的X520-T2网卡的Flow Direction多接收队列机制,并结合Linux中断亲和性配置,实现了数据包网卡硬中断和软中断处理的负载分散,提升了整个搜索系统的吞吐量。
在解决了数据包处理的负载均衡之后,又出现了新的问题,每个搜索请求和响应是用一个短时间的TCP连接完成的,但现有的内核机制下不能保证一个TCP连接的数据包的底层网卡硬件中断、软中断处理与处理该TCP连接的上层应用在同一个CPU核上运行,这称为非亲和的TCP连接。相反,如果一个TCP连接数据包底层处理和它的上层应用在一个CPU核上运行,称为亲和的TCP连接。亲和TCP连接相比非亲和TCP有很大的性能优势,会大幅减少CPU的高速缓存失效率和锁竞争等待的时间。
本节首先通过实验验证非亲和性的TCP连接带来的性能下降,然后就Linux内核TCP/IP网络协议栈的实现来说明为什么会出现非亲和性的TCP连接,最后给出本文的解决方案以及实验评测结果。
4.1 非亲和性TCP连接带来的性能下降
从3.1节可以知道,Nginx服务器上的Core 1和Core 3分别有自己的L1Cache、不共享L2 Cache、共享L3Cache。在启用64核的Nginx服务器上,关闭X520-T2网卡的Flow Direction多接收队列机制,并把唯一的一个网卡中断绑定到CPU 核Core 1(从0开始编号)上,在 Core 3上启用并绑定3个Nginx worker进程,进行发送搜索请求的实验,这样所有用于发送请求和返回结果的TCP连接都是非亲和的。然后,把网卡中断绑定到Core 3上,让所有用于发送请求和返回结果的TCP连接都是亲和的,进行对比实验,期间用oprofile来测量Linux内核中网络协议栈函数的运行时间,以及运行期间的L2Cache失效次数,结果如表2所示。

Tabel 2 Performance comparison between non-affinity TCP connection and affinity TCP connection表2 非亲和性TCP连接与亲和性TCP连接性能对比
从表2中可以看出,对于亲和性TCP连接,Linux内核协议栈的函数执行时间较非亲和性TCP连接下降了32%,一个请求的响应完成时间下降了13%。所以,解决TCP连接的亲和性问题可以给系统带来可观的性能提升。
4.2 非亲和性TCP连接的形成原因
Linux中,TCP三次握手建立连接的过程如图10所示。当收到客户端发送的建立TCP连接请求的SYN包时,Linux首先会创建一个请求套接字struct request_sock,把它放入侦听套接字的syn_table哈希表里,然后发送SYN/ACK包给客户端,当客户端再发来ACK包,该请求套接字被放入侦听套接字的icsk_accept_queue的先进先出接收队列中。当程序在该侦听套接字调用accept()系统调用时,便从icsk_accept_queue中取走一个请求套接字,建立了一个新的连接。
若启用X520-T2的RSS或Flow Direction机制,会产生大量的非亲和性TCP连接。在图11中,在CPU M 和CPU N 上分别有一个 Nginx worker进程处理来自用户的TCP连接,TCP连接A的数据包都被网卡映射到CPU N上处理。当内核完成对连接A的三次握手时,可能由Nginx M通过accept()系统调用获得了连接A的处理权。在第3节启用网卡Flow Direction机制的实验中,当启用了n个CPU核时,因为一个TCP连接被映射到n个CPU核上处理的机会是均等的,
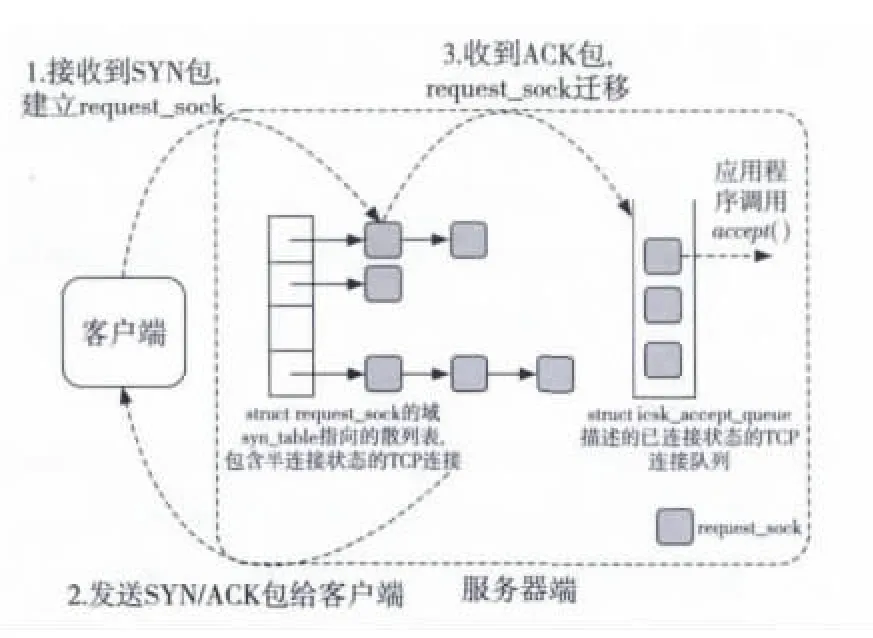
Figure 10 Three-way handshakes of TCP connection on server end in Linux kernel图10 Linux内核中TCP连接三次握手服务器端实现
所有亲和性TCP连接数量只占整个TCP连接的1/n。从以上分析可以看出,若能把所有的非亲和性TCP连接转变为亲和性的,则对整个系统的性能提升有很大的帮助。
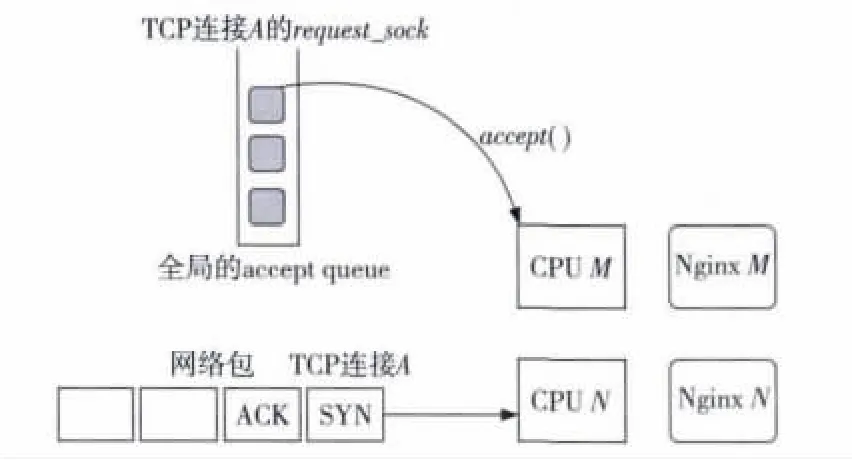
Figure 11 Non-affinity TCP connection generation process图11 非亲和性TCP连接产生过程
4.3 消除非亲和性的TCP连接的方案以及实现
在图11中,TCP连接A变成非亲和性TCP连接的问题在于,连接A的request_sock在TCP监听套接字的全局icsk_accept_queue队列上,所有CPU核上运行的Nginx worker进程都可能获取到,如果能让连接A的request_sock只能由CPU N上的Nginx worker进程获取,那么问题可迎刃而解。本文采用的方案是,把TCP监听套接字的全局icsk_accept_queue队列拆成per-core队列,即每个CPU核有专属于自己的本地的accept queue队列。

Figure 12 Per-core’s accept queue图12 per-core的accept queue
如图12所示,TCP连接A被网卡映射到CPU N上进行底层数据包处理,它的request_sock被放进TCP监听套接字在CPU N的本地accept queue上,当Nginx N 运行accept()系统调用时,直接从本地的accept queue上取得元素;同样,Nginx M 也从 CPU M 的本地accept queue上获取request_sock,这样能够保证只有CPU N 上的Nginx worker进程才能够获得TCP连接A的上层处理权,从而保证了TCP连接A的亲和性。
为了不对其他网络协议的内核代码造成影响,本文把TCP监听套接字struct tcp_sock复制NR_CPUS-1份(NR_CPUs是当前启用的CPUs核数),从而icsk_accept_queue也复制了 NR_CPUS-1份,每个启用的CPU核拥有其中的一份,通过这种方式实现icsk_accept_queue队列的per-core拆分。
4.4 per-core accept queue改进的实验评测
重新编译修改过后增加了per-core accept queue改进的 Linux 3.2.0内核,并与4.1节的multi-interrupts机制做对比实验。
首先,设置Nginx服务器的Linux内核的启动参数maxcpus=1,只启动一个CPU核,在该CPU核上启动三个Nginx worker进程进行实验,测试10分钟内整个系统共处理的请求数。然后,逐次增加Nginx服务器启用的CPU数,利用Linux进程的亲和性设置,在每个启用的CPU核上启用并绑定三个Nginx worker进程,测试10分钟的系统处理请求数,如图13所示。
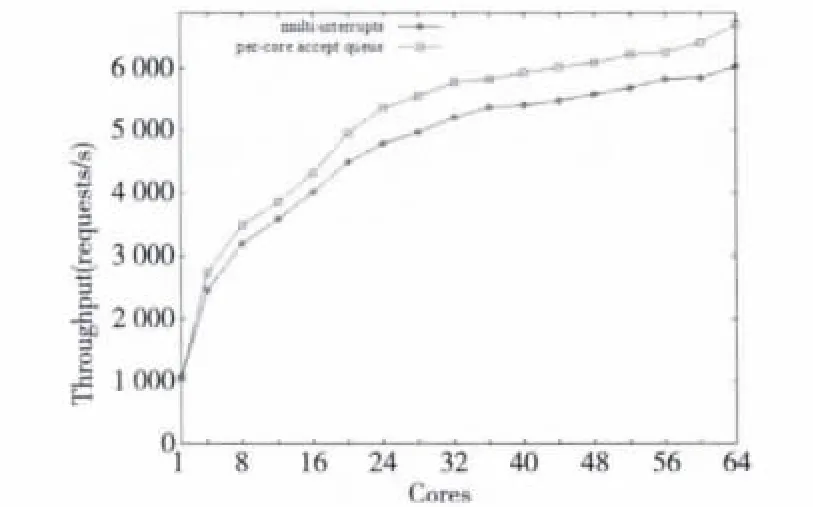
Figure 13 Throughput comparison between per-core accept queue and multi-interrupts图13 启用per-core accept queue机制与multi-interrupts的总吞吐量的对比
图13 的横坐标表示启用的CPU核的个数,纵坐标是对应的吞吐量。启用per-core accept queue机制后,总的吞吐量较 multi-interrupts上升了9%。
5 结束语
针对搜索服务的Linux内核的伸缩性,提供搜索服务的反向代理服务器是本文研究的重点。首先通过伸缩性实验,分析系统性能数据,找出Linux系统在多核系统下的效率瓶颈,并通过修改Linux内核进行了改进,取得了一定的研究成果。
在TCP连接的亲和性改进中,应用程序调用accept()系统调用只能从本地CPU核上的accept queue队列上获取request_sock,也就是说,如果网卡不能把TCP连接均匀地映射到所有CPU核上的话,会造成CPU核上的accept queue队列长度不均匀,某些CPU核处理的TCP连接少,另外一些CPU核处理的TCP连接多,导致负载不均衡。极端的情况下,有些CPU核负载过轻,有些CPU核的负载过重,成为瓶颈,最终造成系统整体性能下降。在未来的工作中,会实现TCP连接负载均衡的方案,让负载轻的CPU核可以从负载重的CPU核上取走一些TCP连接来处理,减轻TCP连接极端不平衡时的危害。
[1] Kuskin J,Ofelt D,Heinrich M,et al.The stanford FLASH multiprocessor[C]∥Proc of the 21st ISCA,1994:302-313.
[2] Mellor-Crummey J M,Scott M L.Algorithms for scalable synchronization on shared-memory multiprocessors[J].ACM Transactions on Computer System,1991,9(1):21-65.
[3] Herlihy M.Wait-free synchronization[J].ACM Transactions on Programming Languages System,1991,13(1):124-149.
[4] Vaswani R,Zahorjan J.The implications of cache affinity on processor scheduling for multiprogrammed,shared memory multiprocessors[C]∥Proc of the 13th SOSP,1991:26-40.
[5] Brock B C,Carpenter G D,Chiprout E,et al.Experience with building a commodity Intel-based ccNUMA system[J].IBM Journal of Research and Development,2001:45(2):207-227.
[6] Bryant R,Barnes J,Hawkes J,et al.Scaling Linux to the extreme[C]∥Proc of the Linux Symposium,2004:133-148.
[7] Bershad B N,Anderson T E,Lazowska E D,et al.Lightweight remote procedure call[J].ACM Transactions on Computer System,1990,8(1):37-55.
[8] Kleen A.Linux multi-core scalability[C]∥Proc of Linux Kongress,2009:1.
[9] McKenney P E,Appavoo J,Kleen A,et al.Read-copy update[C]∥Proc of Ottawa Linux Symposium,2001:1.
[10] Aas J.Understanding the Linux 2.6.8.1CPU scheduler[EB/OL].[2005-02-15].http://josh.trancesoftware.com/linux/.
[11] Mauerer W.Professional Linux kernel architecture[M].First Edition.Beijing:Posts &Telecom Press,2010.
[12] Dobson M,Gaughen P,Hohnbaum M,et al.Linux support for NUMA hardware[C]∥Proc of Linux Symposium,2003:1.
[13] Luck T.Linux scalability in a NUMA world [EB/OL].[2012-05-16].http://www.linux-mag.com/id/6868/.
[14] Boyd-Wickizer S,Clements A T,Mao Y,et al.An analysis of Linux scalability to many cores[C]∥Proc of the 9th USENIX Symposium on Operating Systems Design and Implementation(OSDI’10),2010:1.
[15] Gough C,Siddha S,Chen K.Kernel scalability—expanding the horizon beyond fine grain locks[C]∥Proc of the Linux Symposium 2007,2007:153-165.
[16] Cui Yan,Chen Yu,Shi Yuan-chun.OSMark:A benchmark suite for understanding parallel scalability of operating systems on large scale multi-cores[C]∥Proc of the 2nd International Conference on Computer Science and Information Technology,2009:313-317.
[17] Cui Yan,Chen Yu,Shi Yuan-chun.Parallel scalability comparison of commodity operating systems on large scale multi-cores[C]∥Proc of the Workshop on the Interaction between Operating Systems and Computer Architecture,2009:1.
[18] Cui Yan,Chen Yu,Shi Yuan-chun.Scaling OLTP applications on commodity multi-core platforms[C]∥Proc of 2010 IEEE International Symposium on Performance Analysis of Systems &Software,2010:134-143.
[19] Veal B,Foong A.Performance scalability of a multi-core web server[C]∥Proc of the 3rd ACM/IEEE Symposium on Architecture for Networking and Communications Systems,2007:57-66.
[20] McKenney P E,Sarma D,Soni M.Scaling dcache with rcu[EB/OL].[2004-01-15].http://www.linuxjournal.com/article/7124.
[21] Linux scalability effort project[EB/OL].[2012-05-17].http://lse.sourceforge.net/.
[22] Firebug[EB/OL].[2012-05-17].http://getfirebug.com.
