基于向量空间模型的层次聚类算法在文本挖掘中的应用
2013-05-08张浩
张 浩
(温州职业技术学院 计算机系,浙江 温州 325035)
0 引 言
文本数据挖掘是指抽取有效、新颖、有用、可理解的、散布在文本文件中的有价值的知识,并且利用这些知识更好地组织信息的过程[1]。相较于数据库中的结构化数据,诸如新闻数据、邮件数据、文档数据、Web数据等文本数据的结构表达非常有限;文本数据中的内容是人类的自然语言,现有的数据挖掘技术仍无法解决利用计算机来处理语义的难题,这就需要对文本进行预处理,抽取其特征的元数据,作为文本的中间表达形式。常用的文本信息特征表示有布尔逻辑模型、向量空间模型(VSM)、概率模型及混合模型,其中向量空间模型最大的优点在于将非结构化和半结构化的文本表示为向量形式,使得各种数学处理成为可能。
随着文本数据挖掘技术的不断深入,文本数据挖掘技术中的聚类分析得到了较快的发展。文本聚类是基于“聚类假设”,其关键是将预先给定的若干无标记的文本数据对象聚集起来使之成为有意义的类。文本聚类中常用的层次聚类算法是对指定的文本数据集进行层次分解,直到满足某种条件为止。层次聚类的优点是距离和规则的相似度容易定义,不需要事先确定聚类个数,容易发现类的层次关系,聚类成其它形状。本文基于向量空间模型,采用文本聚类中的层次聚类算法,实现文本数据的挖掘。
1 文本聚类工作原理
基于文本聚类的过滤思想[2-3]是:在预定的层次目录下,获取特征词的关联矩阵,作为特征词扩充的依据。关联矩阵反映了在该目录下的文本中词的关联,利用它进行扩充,可以有效防止因用户兴趣扩充而出现的“漂移”情况。对用户模板进行聚类,将具有相同和相似兴趣的用户模板分为一类,通过与类重心向量的匹配,将符合要求的文本推送给相应的一类用户,以提高文本过滤的准确度。
文本聚类主要依据相似度假设,即同类型的文档相似度较高,不同类型的文档相似度较低,把一个文本集分成若干称为簇(cluster)的子集,每个簇中的文本之间具有较大的相似性,而簇之间的文本具有较小的相似性[4]。因为是无监督的学习方式,聚类既无需训练也无需预先手工标识类别,只需对原始文档集进行相应的预处理,建立索引并抽取特征词,计算文档间相似度,再根据一定的算法进行聚类,算出每一类文档的质心。当加入新文档时,将此文档按相似度归类并重新对该类计算质心。文本聚类系统的工作流程如图1所示。

图1 文本聚类系统的工作流程
2 基于向量空间模型的层次聚类算法及实现
向量空间模型是将文档空间看作是由一组正交词条矢量组成的矢量空间,且每个文档表示为一个规范化矢量V(d)=(t1,ω1(d);…;ti,ωi(d);…;tn,ωn(d);…;),其中,ti(i=1,2,…,n)为词条项,ωi(d)为ti在d中的权值,这样一篇文章就表示成为高维空间中的一个向量[5]。一般还需要构造一个评价函数用以表示词条权重,其计算的唯一准则就是最大限度地区分不同文档。
基于向量空间模型的层次聚类算法的步骤如下:
(1)对于给定的文档集D={d1,d2,…,di,…,dn},将D中每个文档di当作一个簇,即ci={di},所有的簇构成一个聚类C={c1,c2,…,ci}。
(2)计算聚类C中两两簇之间的相似度。
(3)选取最大相似度的簇对max sim(ci,cj),将ci和cj合并为一个新簇ck=ciUcj。
(4)重复上述步骤,最后剩下的簇数达到预先设定的聚类数为止。
可见,层次聚类算法相当于将每篇文档作为一篇文档节点生成m_nMaxClasses棵聚类树的过程,每次合并相似度最大的两棵树,并相应调整权重、相似度等信息,继续合并直至聚类树的棵数等于预先设定的聚类数为止。
值得注意的是,层次聚类算法的具体步骤中,关键在于如何合并相似度最大的树,聚类后如何输出结果,这需要在程序中做好以下几项工作:一是将布尔型成员m_bClusted改为整型数据成员m_nParent。整型数据成员的意义是将一篇未被聚类的文档设为0,否则设为它的父节点文档号。二是每次要比较文档的两两相似度,因此相似度数组要由一维变为二维。三是每次合并两棵相似度最大的树时,将权重大的树的根作为根,权重小的作为子树。四是每次合并两棵树后要动态调整相似度数组的值。对于将要合并的两棵树的根节点的文档号,选权值大的作为根节点,设节点号为r,调整相似度数组中行号和列号为r的元素。五是聚类完成后,每棵树的根节点对应的文档即为该类的质心。结果输出时,需要对聚类树进行遍历。
层次聚类算法的形式化过程描述为:
void CCluster::Run()
{
将每篇文档初始化为一棵树,父节点号为0;
while(当前聚类树的棵数>设定的聚类数)
{
计算文档两两相似度存入相似度数组;
选取相似度最大的两篇文档对应节点;
将权值较小节点的m_nParent置成权
值较大的节点号;
调整新生成树的权值和相似度数组;
当前聚类树棵数减1;
}
输出聚类结果;
}
3 实 验
根据预设的聚类体系,从各大门户网站上收集300篇文本,首先选取其中20篇作为测试样本,然后对基于向量空间模型的层次聚类算法进行分析调试,再随机抽取剩余中的100篇和200篇作为实验样本进行测试,最后采用准确率评价聚类效果。这里的准确率是指所有判断的文本中与人工聚类结果吻合的文本所占的比率。测试结果表明,采用基于向量空间模型的层次聚类算法对文本进行聚类,在20篇测试样本的情况下准确率可以达到81%,在其余两种样本容量的环境下,整体准确率也都有不同程度的改善,如图2所示。
4 结束语
通过基于向量空间模型的层次聚类算法从网上采集的样本在特征空间中的分布情况与待分样本非常相近,说明采用该算法从网上获取相似样本的方法是可行的,且从挖掘的准确率上更具有性能优势。但随着样本容量的增加,准确率会有所降低,其中主要的原因是实验数据类别本身比较相似,属于一个大类别,或者由于同一个子类别下的文本文件关联不是很紧密。这可以通过去除无特征词和合并同义词来提高准确率。
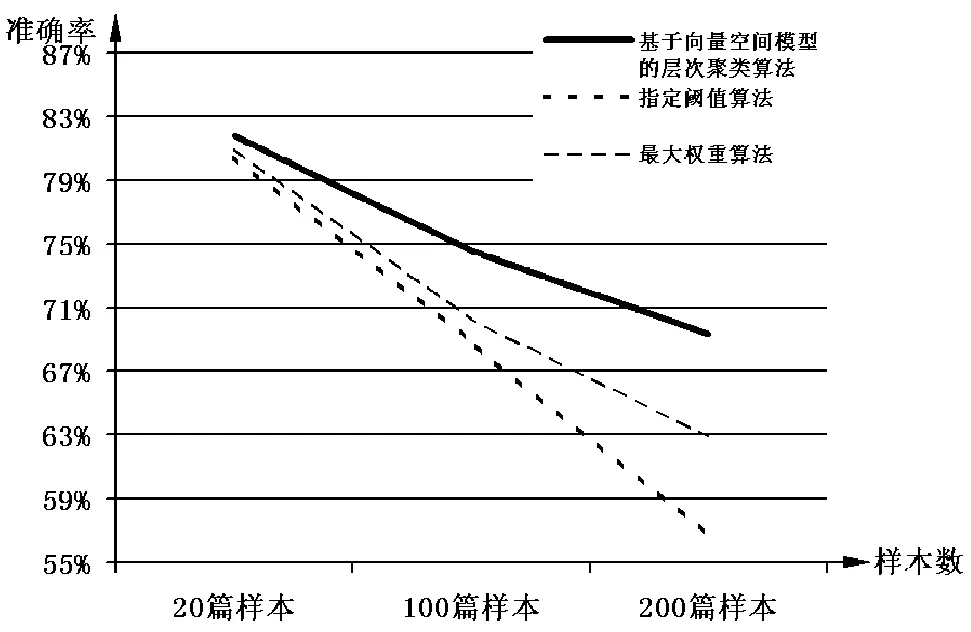
图2 基于向量空间模型的层次聚类算法与指定阙值算法、最大权重算法的比较
[1]常青.文本挖掘 挖掘知识[J].中国计算机用户,2004(24):49-50.
[2]胡可.基于人工免疫系统的信息过滤技术研究[D].成都:西南交通大学信息科学与技术学院,2006.
[3]林鸿飞,马雅彬.基于聚类的文本过滤模型[J].大连理工大学学报,2002(2):249-252.
[4]马军红.文本聚类算法初探[J].电子世界,2012(6):71-72.
[5]刘泉凤,陆蓓,王小华.文本挖掘中聚类算法的比较研究[J].计算机时代,2005(6):7-8,22.
