基于分布式系统的海量数据存储技术
2013-04-30秦东霞
秦东霞,周 航
(周口师范学院 计算机科学与技术学院,河南 周口466001)
当今是一个信息大爆炸的时代,而计算机技术和网络技术的发展加剧了信息爆炸的速度.大量数据不断产生,而且呈几何性增长,信息资源的爆炸性增长对存储系统在存储容量、数据可用性以及I/O性能等方面提出了越来越高的要求.
面对如此庞大的数据,越来越多的企业开始将数据存储作为一项独立的项目进行管理.分布式存储作为近年来新兴的数据存储方式,以其高可靠性、高通用性、扩展能力强和超大容量等优势引起了国内外学者和专家的关注,并通过将一些研究成果应用于实践,不断成为企业提高效率和降低成本的重要选择.
1 海量数据存储
海量数据是指数据量极大,内容记录多的数据,往往是TB级和EB级的数据集合.存储这些信息不但要求有大量存储容量的存储设备,且还需要大规模数据库来存储和处理这些数据.在满足通用关系数据库技术要求的同时,更需要对海量存储的模式、数据库策略及应用体系架构有更高的设计考虑[1].
1.1 海量数据存储的一般原则
1)海量数据存储应在分析和区别数据性质的基础上,采用分级存储的理论对这些数据采取不同的存储方式.________
2)海量数据存储应实现数据的自动分级存储管理,采用相关软件在提高设备容量和性能的基础上,使用能存储海量数据的自动化磁带库可实现海量数据的自动分级存储.
3)海量数据存储时应充分考虑到不同类型数据的存储问题,设计方案应保障数据安全性、完整性和有效性[2].
1.2 面临的问题
传统的数据存储与管理模式已经很难满足日益增长的数据在容量、性能、存储效率和安全性等方面的要求,而且大部分的数据采集系统和数据分析系统都要求对数据进行实时高效的传输和存储.目前,海量数据存储技术正在向商业应用领域推广,相关应用需要处理的数据量都比较大,对于企业自身的计算能力、存储能力以及基础设施要求较高.因此,研究如何高效存储海量数据成为一个热门的研究课题.
2 分布式环境下的海量数据存储相关技术
分布式计算是一门计算机科学,它研究如何把一个需要非常巨大的计算能力才能解决的问题分成许多小的部分,然后把这些部分分配给许多计算机进行处理,最后把这些计算结果综合起来得到最终的结果[3].分布式计算能够充分利用硬件资源,调度可用资源为用户服务,减少成本,方便使用.
分布式系统将具有大规模复杂计算量的任务分割成若干相对较小的任务,来提高处理任务的速度,因此分布式系统主要用来进行大规模的数据存储和管理.
下面着重介绍分布式环境下的海量数据存储的相关算法.
2.1 BigTable
BigTable是Google设计的高性能的、可扩展的分布式数据存储系统,是用来存储大规模结构化数据的一种非关系型的数据库,它主要用来处理海量数据[4].

图1 BigTable的基本框架图
BigTable的数据模型是一个稀疏的、分布式的、持久化存储的多维度 Map(映射,Map由key和value组成).Map的索引是行关键字、列关键字以及时间戳;Map中的每个value都是一个未经解析的byte数组.
Google目前仍在不断地对BigTable进行改进,通过技术创新和服务创新来提高运行效率和稳定性,图1为BigTable的基本框架.
客户若要访问BigTable,需先通过Open()操作打开一个锁获取文件目录,使得客户端与子表服务器进行通信.这种操作方式与大多数单一主节点的分布式系统相同,客户端与子表服务器通信而不是与主服务器通信.而Master(主服务器)主要管理新字表的分配、子表服务器的状态监控和子服务器之间的负载均衡.
BigTable的设计目的是可靠地处理PB级别的数据,并且能够部署到上千台机器上.用它来进行海量数据的存储,不仅可以快速、准确地查询并存储,还能对服务器之间的负载均衡做出有效调节,使BigTable成为一个架构简洁、模型清晰、易于实现和使用的技术,并且可伸缩性和稳定性都很优秀的系统[5].
然而,BigTable随机读取小型记录的性能比较差.由于无论要读取的数据是大还是小,这些数据都需要从GFS中传输一个至少8k的块,并且要在客户端做一定的缓存.如果数据访问热点不够明显,那么做缓存就没有多大意义,这样就出现了大量存储空间的浪费[6].
2.2 网络文件系统NFS
网络文件系统(Network File System,NFS)是一种FreeBSD支持的文件系统,它允许一个系统在网络上与他人共享目录和文件.通过使用NFS,用户和程序可以像访问本地文件一样访问远程云端上的文件,也可以让计算机通过网络将远程共享的档案一直到自己的文件系统中[7].NFS的组成至少要有两个部分:一台服务器,一台或多台客户机.NFS服务器是中心,客户机是端点,如图2所示.

图2 NFS的拓扑结构图
NFS的基本原则是允许不同的客户端及服务器端通过一组RPCs分享相同的文件系统.它独立于作业系统,允许不同硬件及作业系统共同分享文件,还可以让计算机通过网络将远程的NFS服务器共享的档案拷贝到本地文件系统中.这样本地工作站会节约出更多的磁盘空间,也可以减少诸如硬盘、软驱等的可移动介质设备的数量.
NFS非常适用于I/O需求处于中低水平的工作负载,实际上NFS是一种基于IP的协议,不是基于IP的存储协议.因此它可以大幅简化工作,降低成本.NFS还有一个显而易见的好处是用户不必在每个网络的机器里头都有一个home目录,home目录可以放在NFS服务器上并且在网络上处处可用[8].但是NFS最大的问题是它不太适合于大型的分散式系统.
2.3 MapReduce算法
MapReduce是Google开发的一种分布式计算模型,是用于简化分布式编程模式的方法.它可以分布式处理一系列查询.它的主要思想是自动分割要执行的问题,将问题拆解为Map(映射)和Reduce(化简)的模式.Map是一个分解的过程,它将输入的数据片段拆分为大量的数据片段,将每一个片段分给一个计算机处理;而Reduce却将已经计算完成的分散的数据整合在一起,最后汇总后输出计算结果[9].
MapReduce的执行有两种不同的节点,分别由master和worker负责,其中worker负责处理数据,master负责调度不同的结点之间的数据共享.主要的流程如图3所示.
用户为每一个 Map函数分配key/value对,并将key/value对产生的中间结果传递给Reduce函数进行处理.Reduce函数将对所有key值相同的key/value对进行整合输出.
MapReduce更适用于复杂分析应用和半结构化的数据中.复杂分析类应用属于挖掘类型的应用,需要对数据进行多步骤的计算和处理.通常一个程序的输出会是另外一个程序的输入,因此很难用单个SQL语句来表示,在这种场合,MapReduce是很好的解决方案.而半结构化数据不需要对数据的存储进行格式定义,这些数据通常是键值对,用MapReduce比较方便.
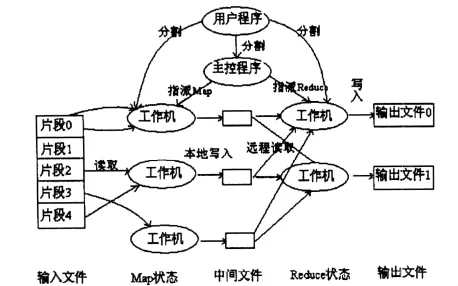
图3 Map Reduce模型主要流程图
MapReduce有两个突出的优点:第一,MapReduce不仅能用于处理大规模数据,而且能将很多繁琐的细节隐藏起来,这样将极大地简化程序员的开发工作;第二,MapReduce的伸缩性非常好,每增加一台服务器,它就能将差不多的计算能力接入到集群中去,而过去的大多数分布式处理框架都难以做到.然而MapReduce最大的不足就是它不适应实时应用的需求,所以在今后的发展中,MapReduce的主导地位也许将会被可用于实时处理的Percolator系统所代替[10].
3 相关应用和发展趋势
研究分布式系统更看重的是它的相关应用.应用存储技术的发展一方面降低了建设分布式系统的成本,减少了服务器的数量,另外还提高了系统的性能,降低了系统性能瓶颈的发生,减少了单点故障问题,提高了系统处理数据的效率,使得系统的性能和效率得到保障.应用存储的实现是将应用软件集成到存储设备中,这样存储设备在存储数据的同时又具有应用软件的功能,这也在很大程度上保障了整个系统的稳定高效运转.
3.1 分布式环境下海量数据存储的应用领域
3.1.1 医药医疗领域
随着分布式技术的思想在存储行业中落地,在非对等网络结构的基础上构建分布式平台成为新型存储的重要前沿方向之一.基于分布式系统的海量数据的存储能够解决目前医院信息化过程中存储资源和管理方面的问题,为日益庞大的医疗数据提供按需扩展的存储空间[11].随着分布式技术的不断完善,海量数据的存储在医院信息化建设中将起到更加实际的作用.
3.1.2 教育教学领域
现代远程教育的开展,让远程教学平台逐渐进入人们的生活中,大量的数字化教学资源极大地丰富了人们的生活,提高了教学质量.开展现代远程教育离不开教学平台,若用户集中使用一个平台,则大量的数据资源的存储,大量用户的并发访问将对服务器的负载提出很大的挑战.把分布式系统应用到教学平台的开发上,研究可以容纳大量用户同时访问的分布式现代远程教学平台,可以充分满足远程教育对大量数据的需要,克服远程教学平台中存在的诸多不足.
3.2 海量数据存储的发展趋势
随着存储技术相关研究和应用的不断深入,海量数据存储也在为能提高更加高效的技术和服务探索更广阔的发展方向.
3.2.1 网格存储
网格存储是基于网格网络的一种新的存储模型.网格类似于一个网状网络,所以它的各方面性能和大小都是可扩展的.网格存储将部署和存储在多个系统和网络中的信息进行管理,这些分系统没有控制路由的集线器或集中控制的交换机,因此不受中央交换机的约束,这在提高结构可靠性和可伸缩性的同时也节约了组件的成本[12].
3.2.2 P2P存储
以往存储方式存储的数据都放在处于“中心”的几个大型服务器上,而采用P2P存储则将存储信息放在处在相对“边缘”的个人电脑上,这样可以将网络中剩余的空间进行合理地利用,另外,还为提高网络存储的高性能提供了可能.在提高网络存储能力方面,可以采取以下两种措施,一方面扩大网络存储器的存储能力,另一方面采用并行存储的策略,也就是将多个存储器按照某种方式进行连接.
3.2.3 存储容灾
存储容灾采用数据备份和恢复技术,将本地关键业务数据进行远程备份,一旦本地数据和应用系统出现问题,将启动容灾机制,最大限度地保障数据的可用性,从而使得计算机系统能够正常提供服务.存储容灾创建的远程数据系统主要用来保存本地备份的关键业务数据.在数据备份过程中,进行备份的数据可以是完全复制的也可以只复制部分重要数据,可以是实时的,也可以有一定时差,但一定要保障数据的可用性.
4 小结
海量数据存储相关技术主要研究对象是大数据在存储过程中出现的问题及解决方法,其研究目的在于提高大容量数据的数据存储能力、数据处理效率以及在处理过程中如何保障数据的可用性和完整性.笔者首先介绍了海量数据相关概念,海量数据存储过程中应遵循的基本原则和方法,然后对基于分布式系统的海量数据存储技术进行了深入的研究和探讨,对相关经典算法和应用做了详细的介绍,并对这些算法的优缺点和相关应用方向进行了分析,最后对海量数据存储未来的发展趋势做出展望.相信随着人们对海量数据的研究和应用的深入,海量数据存储的性能、速度和可靠性也会得到很大的提高,将其应用到日常生活中也是指日可待.
[1]绍林.高速海量数据存储技术研究[D].湖南:国防科学技术大学,2007:1-3.
[2]蒋然.海量数据存储关键技术浅析[J].电脑知识与技术,2010,20(6):5103-5105.
[3]苏勇,周敬利.基于iSCSI OSD存储系统的设计与分析[J].计算机工程与应用,2007,43(23):103-105
[4]李怀阳.进化存储系统数据组织模式研究[D].武汉:华中科技大学,2012:2-3.
[5]石云辉.高扩展负载均衡服务器集群技术及应用探讨[J].中国电化教育,2009(7):123-125.
[6]董玉管.群云计算的数据计算与存储[J].电脑知识与技术,2012,8(16):3803-3805
[7]陈璐.基于云计算的海量数据存储技术的研究及应用[D].武汉:武汉科技大学,2011:7-8.
[8]刘阳成,周俭谢,玉波海.量数据存储管理技术研究[J].微计算机应用,2011,32(10):33-36
[9]Dean J,Ghemawat S.MapReduce:Simplified Data Processing on Large Clusters[J].Communications of the ACM,2008,51(1):107-113
[10]方少卿,周剑,张明新.基于 MapReduce的改进选择算法在云计算的Web数据挖掘中的研究[J].计算机应用,2013,30(2):377-379.
[11]杨洋.网格计算与云计算综述及发展趋势的探讨[J].南京广播电视大学学报,2012(2):76-79
[12]张艳玲,徐海峰.浅谈云存储在医院信息化中的应用[J].医疗卫生装备,2012,33(8):40-41.
