基于Mel频率倒谱系数的光缆声音信号特征提取方法研究
2013-04-24李一芳
李一芳
(南京航空航天大学经济与管理学院,南京 210016)
0 引言
随着通信事业的快速发展,对于通信网络的建设与管理提出了更高的要求。光缆是现代大容量通信的重要组成部分,对于光缆的保护也随之提出了更高的要求。
声音作为目标活动时发出的一种固有信号,必然携带着目标本身的结构信息和运行状态信息。利用声音传感器可以实现对通信光缆铺设区域进行全天候不间断的监测,通过光纤传感器拾取目标活动时产生的声振动信号,提取其中的特征,可以对目标进行探测、识别和分类。将获取的信息传输给通信网络控制台或指挥中心,可以使指挥人员及时准确的了解和掌握监测区域的情况,从而及时有效的对通信光缆进行巡查和维护,切实保障通信网络的可靠性和安全性。针对通信光缆的破坏事件诸如铲车,电钻以及施工等,需要采取一种切实可行的方式来进行实时识别,以便采取及时的保护措施,保证光网络的通信质量。
本文旨在研究基于Mel频率倒谱系数提取光缆声音信号特征的提取方法,为通信网络实时监控提供一种有效的手段。
1 Mel频率倒谱系数
1.1 声音识别系统
声音识别系统的基本原理是:通过训练样本的量化,提取特征参数来建立样本文件,保存在声音样本数据库中;通过采集被识别的声音,提取特征参数后通过匹配算法与样本数据库中的样本进行匹配,并输出识别结果。典型的声音识别系统基本模型如图1所示。
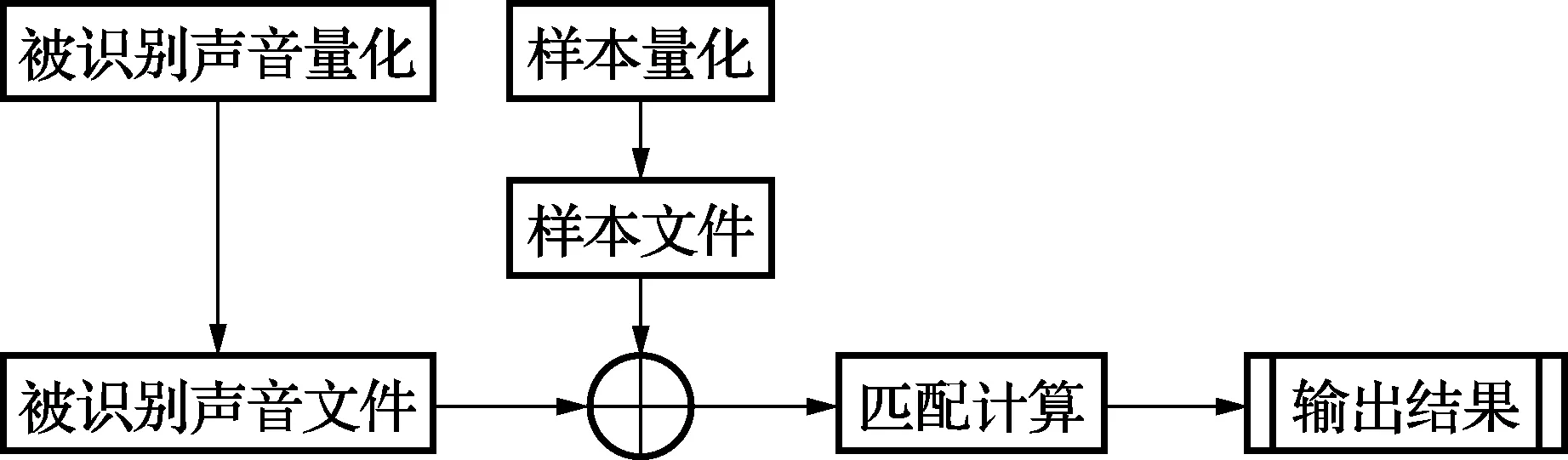
图1 声音识别系统基本模型
由于特征参数能够有效地体现该声音所包含的区别于其他声音的不同特点,它在整个识别过程中起着至关重要的作用。目前,在识别研究领域使用较多的有Mel频率倒谱系数(Mel Frequency Cepstrum Coefficient,MFCC)[1-2]、线性预测倒谱系数(Linear Predictive Cepstrum Coefficients,LPCC)、线性倒谱对(Linear Spectrum Pair,LSP)等。已有的研究表明MFCC在识别系统中具有很高的识别性能以及噪声鲁棒性。
1.2 低频频谱识别
MFCC主要描述信号在频率域上的能量分布,它能够较好地模拟人耳听觉系统的感知能力。MFCC使用一串在低频区域交叉重叠排列的三角型滤波器(如图2所示),捕获声音的频谱信息。由于Hz-Mel频率非线性的对应关系,使得在低频区域使用的滤波器数量较多,分布密集;而在高频区域使用的滤波器数量较少,分布稀疏。由于光缆的破坏事件的频谱大致都位于低频区域,所以采用MFCC能够获得很好的识别效果。本文所呈现的实验结果表明,采用该特征参数对于破坏事件的识别率,获得了比较好的结果。
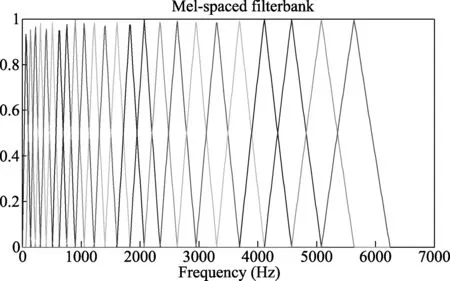
图2 三角滤波器分布
2 声音特征参数的提取
MFCC参数是研究人的听觉系统的基础上而得出的声学特征[3-4]。对于人的听觉机理研究发现,当两个频率相近的音调同时发出时,人只能听到一个声调。临界带宽指的就是这样一种令人主观感觉发生突变的带宽边界。当两个音调的频率小于临界带宽时,人们就把两个音调听成一个,这就是所谓的掩蔽效应。Mel刻度就是对这个临界带宽的度量方法之一。根据已有的研究工作表明,临界频带宽随着频率的变化而变化,并与Mel频率的增长一致。采用Mel频率模拟人耳的听觉,它与声音频率的大概关系近似表示为:在1000Hz以下,大致呈线性分布,带宽为100Hz左右;在1000Hz以上呈对数增长。频率f与Mel频率Mel(f)之间的转换关系为:
Mel(f)=2595lg(1+f/ 700)
MFCC特征参数提取过程是:首先将声音信号进行FFT变换到频域,通过Mel尺度的滤波器阵列后进行离散余弦变换,得到特征参数,如图3。

图3 MFCC提取流程
MFCC参数具体提取过程如下:
1)预加重,对每一帧信号减少尖锐噪声影响,提升高频信号[5]。预加重的定义式如下所示:
Sn=Sn-aSn-10.9≤a≤1.0
Sn为原始信号(系统中采用25k采样率,32bits采样精度,参数a通常取0.9725)。
2)窗长40ms,窗移20ms,因此,每帧有1000个采样点。对信号加窗以避免短时声音信号段边缘的影响。加窗的定义如下:
Sw(n)=Sn×w(n) (Sw(n)是加窗后的信号)
其中w(n)为窗函数:
3)对Sw(n)进行快速傅里叶变换[6-7]:由于声音信号在时域上的变化快速而且不稳定,所以通常都将它转换到频域上来观察[8],此时它的频谱会随着时间作缓慢的变化。所以通常将加窗后的帧经过FFT变换,求出每帧的频谱参数。
4)把上一步变换得到的频谱系数用序列三角滤波器进行滤波处理,得到一组系数c1,c2,…。滤波器组中每个三角滤波器的跨度在Mel刻度上是相等的。所有的滤波器总体上覆盖从0Hz到奈奎斯特频率,即采样频率的二分之一。
计算ci的公式如下:
ci=ln[X(k)×Hi(k)]
其中:
f[i]是三角滤波器的中心频率,满足:
Mel(f[i+1])-Mel(f[i])=Mel(f[i])-
Mel(f[i-1])
5)利用离散余弦变换求得倒谱系数。其中P是三角滤波器的个数。倒谱系数的个数为24,由下式得出:
通过上述步骤,即可以得到24维MFCC特征参数。但是,这并不意味着系统最后选取的特征参数就是24维的,因为其中可能存在对于识别系统没有贡献的分量。MFCC特征系数的低阶及高阶部分对于识别系统的贡献仍然未知。已有的研究表明,高阶与低阶的MFCC特征参数在不同的识别环境下会体现出不同的识别性能和噪声鲁棒性。所以,在下一步的实验仿真过程中,通过不同维度特征参数的对比来选择最适合的特征分量组合。
3 实验仿真
仿真过程中对样本声音信号采用了25k采样率,32bits量化长度,每一帧信号长度为40ms,帧移20ms,并利用汉明窗进行短时分析。对采集的铲车、电钻以及施工事件的声音信号,采用基于时域短时能量和短时过零率的双门限端点检测法,去掉其中部分冗余信息,确保所提取的声音信号的有效性。实验过程中选取预处理后声音样本的100帧作为声音训练样本,100帧作为测试样本。
利用支持向量机(Support Vector Machine,SVM)对三种声音信号两两之间进行训练、预测以及分析结果。SVM[9-10]方法是在统计学习理论的VC维理论和结构风险最小原理基础上发展起来的一种新的机器学习方法,根据有限的样本信息在模型的复杂性(即对特定训练样本的学习精度)和学习能力(即无错误地识别任意样本的能力)之间寻求最佳折衷。它能够克服基于规则的层次分类方法的缺点,并且不需要选定阈值。
实验仿真中采用5倍交叉验证方法进行评判[11],即将5次实验的平均识别率作为最终的实验结果。另外,为了选取最佳的特征组合,同时也是为了满足识别系统的实时性要求,需要将特征数据降维,提高系统的处理效率。仿真选择其中最能代表声音信号的维度作为最终系统选用的特征。因此,同时还选择了8维声音特征向量来仿真识别的效果。识别结果如表1所示。
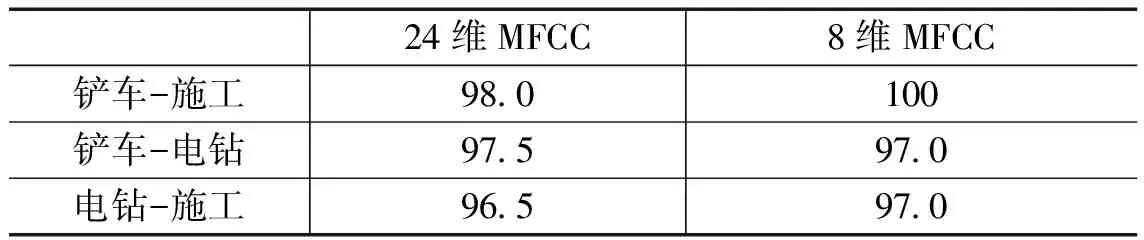
表1 不同维数特征向量实验识别率(%)
实验过程中采用径向基函数(Radial Basis Function,RBF)作为核函数。从实验结果可以看出,不论是24维特征向量还是8维特征向量,都具有令人比较满意的识别率。这说明,采用MFCC作为该识别系统的特征参数,能够获得比较好的识别效果。同时,系统采用8维特征向量与采用24维特征向量的识别效果相当,这也从一定程度上表明特征向量的降维对于实际识别系统的可行性。
4 结论
作为主流识别领域的MFCC在识别中能较好地模拟人耳听觉系统的感知能力,在识别系统中具有很高的识别性能以及噪声鲁棒性,对低频声音信号有着很好的计算精度[12]。MFCC特征参数的高低维部分对于不同识别环境表现出不同的识别性能和噪声鲁棒性。
通信光缆周边环境中的各种破坏事件所产生的声音的频率主要位于500Hz以下低频部分,根据MFCC的良好特性,采用MFCC作为该声音识别系统的特征参数,且主要是选择MFCC的低维部分作为该系统的特征参数。实验仿真结果表明,采用低维MFCC特征参数能够得到比较满意的识别效果。这就为下一步系统的建立奠定了坚实的基础。下一步,通过采集更多的不同的事件声音样本信号,通过两类或者三类样本之间的组合来进行识别,仿真寻找更加优化的特征维度组合,提高识别的速度和精度。
[1] 江星华,李应.一种基于MFCC 的音频数据检索方法[J].计算机与数字工程,2008(9)
[2] 叶庆云,蒋佳.基于语音MFCC 特征的改进算法[J].武汉理工大学学报,2007(5)
[3] 张震,化清.语音信号特征提取中Mel倒谱系MFCC 的改进算法[J].计算机工程与应用,2008,44(22)
[4] 韩一,王国胤,杨勇.基于MFCC 的语音情感识别[J].重庆邮电大学学报,2008(5)
[5] 白静,张雪英.基于支持向量机的抗噪语音识别[J].太原理工大学学报,2009(1)
[6] 杨行峻,迟惠生,等.语音信号数字处理.北京:电子工业出版社,1995
[7] Rabiner L,Juang B H.Fundamental of Speech Recognition.New York:Prentice Hall,1993
[8] Furui S.Speaker Independent Isolated Word Recognition Using Dynamic Feature of Speech Spectrum.IEEE Trans on Acoustics,Speech,Signal Processing,1986,34(1):52-59
[9] Seneff S.A Joint Synchrony/mean-rate Model of Auditory Speech Processing.Journal of Phonetics,1998, 16:55-76
[10] Atal B S.Automatic Recognition of Speakers from Their Voices.Proceeding of IEEE,1976,64(4):460-475
[11] Reynolds D A.Experimental Evaluation of Features for Robust Speaker Identification.IEEE Trans on Speech and Audio Processing.1994,2(4):639-643
[12] Kanedera N,Arai T,Hermansky H,et al.0n the Importance of Various Modulation Frequencies for Speech Recognition.In:Proceedings of EUR0SPEECH,1997,Rodos,Greece
