海量IIS日志自动分析方法的研究
2013-04-24徐国天
徐国天
(中国刑警学院 辽宁 沈阳 110035)
海量IIS日志自动分析方法的研究
徐国天
(中国刑警学院 辽宁 沈阳 110035)
在IIS日志文件中记录了黑客攻击网站的相关线索和违法网站的犯罪证据,研究海量IIS日志信息的自动分析方法对公安机关的侦查、办案工作有重要意义。结合具体实例研究了海量日志自动分析过程中面临的三个关键问题:不规则数据的去除方法;特定数据的定位和提取方法;UTF-8和Base64编码的解析方法,最后介绍了IIS日志自动分析软件的总体设计流程以及软件的测试情况,得出应用这款日志分析软件可以有效地完成海量日志自动分析工作的结论。
IIS 日志 分析 UTF-8 Base64
随着网络技术的快速发展,IIS服务器被广泛使用,在这些服务器上运行了政府机关、企事业单位、高校、银行等机构的各种网站。这些网站在给人们生活带来便利的同时也面临着黑客入侵的安全威胁。在网站遭到攻击之后调查出攻击者的线索是公安机关需要解决的一个关键问题。同时某些不法分子在租用的IIS 服务器上搭建站点,从事网络赌博、色情表演、毒品销售等违法活动。在IIS服务器上收集犯罪证据、调查相关犯罪线索也是公安机关面临的一个重要课题。
在IIS日志中记录了所有客户对服务器的访问行为,包括客户端IP地址、访问时间、访问链接、参数等相关信息。同样黑客的攻击行为、违法站点的犯罪证据也包含在IIS日志中。因此IIS日志分析对公安机关的调查、取证工作有重要意义。
IIS日志包含的数据量非常大(例如一个中等规模的站点,其一天的日志量可能达到400MB)。为了有效地分析日志,目前通常采用的办法是将日志文件导入到数据库中(例如SQL server),再利用数据库的SQL语句对日志数据进行分析、处理。这种方法提高了日志分析的效率,但面临以下问题:①日志文件中的不规则数据会造成导入数据库失败。②混杂在日志记录参数字段中的重要信息无法有效提取,例如聊天记录。③在日志记录中保存的大量非ASCII码数据无法解析,例如UTF-8、Base64编码数据,这些数据中通常包含了重要信息。本文将对海量IIS日志自动分析方法进行研究。
1 IIS日志记录的构成
IIS日志通常保存在“系统分区winntsystem32 logfilesw3svc编号”文件夹下,通常情况下每天生成一个独立的日志文件,其文件名为exyymmdd.log,其中yymmdd代表年、月、日。例如ex061122.log代表2006年11月22日的日志文件。
在IIS日志中记录了所有客户对网站的访问行为,包括客户端IP地址、访问时间、访问链接、参数等相关信息。下面给出的是一条典型的web日志记录:2012-02-28 08∶02∶42 W3SVC1 210.47.128. 134GET/lookpro.aspid=50 80 210.47.128.20 Mozilla/4. 0+(compatible; +MSIE+6.0; +Windows+NT+5.1;+SV1;+.NET4.0C;+.NET4.0E)200 0 0,它代表的含义如下,访问时间:2012-02-28 08:02:42、客户机IP地址:210.47.128.20、服务器IP地址:210.47.128. 134、服务器端口:80、访问链接:lookpro.asp、提交参数:id=50、客户机浏览器类型:IE6.0、客户机操作系统:Windows+NT+5.1内核。
2 去除日志文件中的不规则数据
在IIS日志文件的日志记录中可能搀杂了一些不规则数据,如图1所示,在ex120229.log日志文件中搀杂了四行非日志记录(第4~7行)。其中第一行表示服务器使用的是IIS6.0、第二行表示版本1.0、第三行表示下面日志记录的形成时间是2012-02-29 06:27:33、第四行是日志记录的各个字段名称。在每个日志文件中都可能搀杂了大量这种类型的数据。由于它们属于不规则数据,在将日志文件导入到数据库时会发生转换错误。本文设计的日志分析软件可有效去除这类不规则数据。
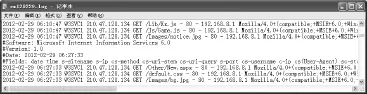
图1 IIS日志文件中包含了不规则数据
使用winhex打开日志文件之后,我们发现日志文件中每行记录的结尾都存在两个不可见的特殊字符,即0x0d和0x0a,其中0x0d代表“回车”、0x0a代表“换行”。根据这一特点本文设计了一款日志分析软件,其状态转换图如图2所示。它的基本思想是依次读取日志文件中的每条记录,再从中查找、提取、处理相应的数据信息。日志文件由若干个字节组成,其中特殊字节包括0x0d、0x0a和EOF(代表文件结束符)、其他字节视为普通字节(common byte)。状态转换机依次处理日志文件中的每个字节,在initial状态下处理了第一个字节之后,状态转换到1-status。在1-status状态下将这一行记录的每个字节依次写入到数组buffer中,当读取字符为0x0d时状态转换到2-status,如果下一个字节为 0x0a,则转换到3-status,如果下一个字节为EOF,则转换回initial,程序异常结束。3-status代表在buffer数组中保存了一条完整记录,可按照设定好的关键词在buffer数组中搜索、提取、处理特定数据。这种方法可以高效、灵活地进行大容量日志文件处理。
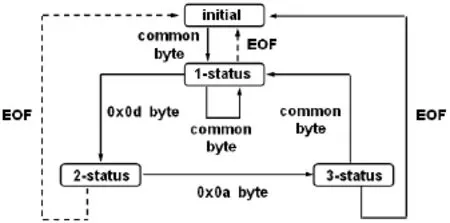
图2 软件的状态转换图
当软件处于3-status时,说明在buffer数组中保存了一条记录。这可能是一条有效的日志记录,也可能是一条不规则数据,该如何进行区分呢?通过分析我们发现,有效的日志记录都是以当前日期作为开头,例如2012-02-29,利用这一特点可以筛选出不规则数据。如果这条日志记录不是以当前日期开头,那么这就是一条不规则数据,软件不进行处理,反之这就是一条有效的日志记录,可以对该记录进行相应的处理。
对有效日志记录的加工、处理主要包括:按照关键字查找特定信息和按照关键字提取、处理特定信息。下面对这两种重要的处理函数进行介绍。
3 特定数据定位、提取函数
只要IIS服务器配置得当,日志文件会记录下客户访问服务器的详细信息,其中在URL参数部分会记录下重要的线索。例如下面这条日志:2012-02-29 01:16:42 W3SVC1 210.47.128.134 GET/login.aspxname= jack&pwd=8e163b6986e0e7250228040 2c89ab 66c 80 192.168.8.10 Mozilla/4.0+(compatible;+MSIE+6.0;+ Windows+NT+5.1;+SV1;+.NET4.0C;+.NET4.0E)200 0 0。在这条日志的参数部分记录了登录用户名为jack、密码为MD5加密值:8e163b6986e0e72502280402c89 ab66c。在IIS日志中包含了大量这类信息,我们需要从这类日志中提取出日期、时间、用户名、密码、客户IP地址,这涉及到数据定位和数据提取函数。
3.1 特定数据定位函数
在进行日志记录分析时最常用的操作就是字符串的定位,本文设计了下面所示的字符串定位函数。它包含四个参数,其中数组S保存主串、数组T保存子串、整数pos保存查找的起始位置、s_length保存主串长度、t_length保存子串长度。函数的功能是在主串S中查找子串T从pos位置之后第一次出现的位置,如查找成功,则返回子串位置,否则返回-1。

3.2 特定数据提取函数
以上面提到的日志为例,每处理一条记录时,首先利用定位函数查找这条记录中是否包含关键词“name=”和“pwd=”,如包含、则提取出用户名,即“name=”之后,“&”之前的内容。再提取出密码,即“pwd=”之后32字节数据(MD5密码的长度固定32字节)。每条日志记录的开始19字节保存的就是固定格式的日期和时间信息,格式为yyyy-mm-dd hh:mm: ss,这样可以提取出这条日志形成的日期和时间。在关键词“-”之后、“ ”之前的内容为客户端IP。至此这条记录需要的关键信息提取完成,通过分析可以发现,关键词例如“name=”、“pwd=”在数据提取中起到重要作用。
4 常见编码解析函数
4.1 UTF-8编码解析函数
UTF-8(8-bit Unicode Transformation Format) 是一种针对Unicode的可变长度字符编码(定长码),也是一种前缀码。它可以用来表示Unicode标准中的任何字符,且其编码中的第一个字节仍与ASCII相容,这使得原来处理ASCII字符的软件无须或只须做少部份修改,即可继续使用。因此,它逐渐成为在电子邮件、网页及其他储存或传送文字的应用中,优先采用的编码。UTF-8使用一至四个字节为每个字符编码。
在IIS日志中可能存在大量UTF-8编码的数据信息,提取、分析这些数据对公安机关的调查、取证有重要意义。例如下面这条日志:2012-03-23 08:43:51 W3SVC1 210.47.128.134 GET/Server.aspx t=%E6%98% 8E%E5%A4%A99%E7%82%B9%E8%A7%81 80 192. 168.8.2 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+ NT+5.1;+SV1)200 0 0。其中%E6%98%8E%E5% A4%A99%E7%82%B9%E8%A7%81即为UTF-8编码的聊天数据,其对应的十六进制数据为E6988EE5A4 A939E782B9E8A781,将这组数据通过winhex写入UTF-8编码的文本文件中,见图3。打开文本文件查看到的结果如图4所示。这组聊天数据的内容为“明天9点见”。编码对应关系为:E6988E—“明”、E5A4A9—“ 天 ”、 39—“ 9”、 E782B9—“ 点 ”、E8A781—“见”,可见一个汉字占3个字节编码、一个字符占1个字节。
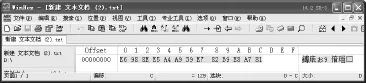
图3 通过winhex写入十六进制数据

图4 采用UTF-8编码保存文本文件
根据UTF-8编码的特点,本文设计了如下转换函数。函数的功能是将ACSII码表示的十六进制UTF-8数据转换为可读的汉字。buffer数组中存放从日志中提取的UTF-8编码数据。程序采用循环结构处理UTF-8字符串,遇到“%”直接跳过,遇到十六进制数据时,则将前后两个字符转换为一个字节数据。

例如buffer数组中保存待处理数据为“%E6% 98%8E%E5%A4%A99%E7%82%B9%E8%A7%81”,经过函数处理之后,在buffer_to数组中保存结果为0xE6988EE5A4A99E782B9E8A781。将buffer_to数组内容使用fwirte函数写入到一个TXT文件中,双击打开该文件即可看到文字“明天9点见”。
4.2 Base64编码解析函数
ASCII数据的取值范围是0~127,其中0~31区间是“不可打印”ASCII数据,这段区间主要是一些控制符,例如“回车”、“换行”等。32~127区间保存的是“可打印”ASCII数据,这段区间是一些可显示的字符,例如“+-*<a b c d”等。
为了便于用户查看,IIS日志只能记录“可打印”的ASCII数据。目前在windows主机中汉字默认采用ANSI编码(即简体中文GB2312编码),在这种编码方案中一个汉字占两个字节,每个字节的取值范围是0~255,这一范围超出了“可打印”ASCII数据的区间(32~127),这导致某些中文数据无法以原始编码格式保存在日志文件中,在这种情况下,Base64编码方案被大量采用。
Base64编码的基本思想是将“不可打印”的数据(例如中文)转换为“可打印”的ASCII数据,下面结合具体实例分析Base64算法。图5给出了汉字“你好”的Base64编码过程,汉字的原始编码方案是ANSI编码,“你”的值为0xC4E3、“好”对应0xBAC3。图中给出了每个十六进制字节对应的二进制值,例如0xC4对应的二进制值为11000100。第一步:将4个字节、共32位二进制数据从左至右按照6位一组进行划分。最后余出2位1,在其后补充4位0、凑齐6位。共得到6组数据。第二步:计算出每组二进制数据对应的十进制数值,例如110001对应49。第三步:根据每组的十进制数值查找Base64编码表,得出每组对应的“可打印”ASCII字符。例如在Base64转换表中,49对应“x”、14对应“O”。最终得出汉字“你好”的Base64编码为“xOO6ww”。
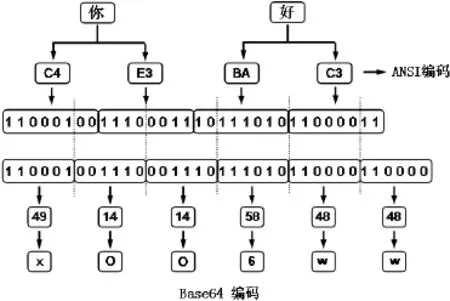
图5 Base64编码算法
打开日志文件,查看到的“可打印”字符串“xOO6ww”对应的就是汉字“你好”。在进行日志分析时需要将“可打印”的字符串重新还原为对应的汉字内容。采用的算法就是Base64编码算法的逆向过程,算法描述如下:第一步:查找Base64转换表,找出每个字符对应的十进制数值,例如“O”对应值为14。第二步:将每个十进制数转换为6位二进制数据。例如14对应二进制001110。第三步:将得到的二进制数据从左至右按照8位一组进行划分。最后舍弃多余的4个二进制0。将计算出的数据以ANSI编码方案保存到一个TXT文件中,再双击打开该文件即可查看到对应的汉字内容。
5 软件的总体流程
IIS日志分析软件的总体执行流程如图6所示。Initial函数负责进行初始化操作,包括指定提取信息的保存路径、指定日志文件夹的保存位置、输入起始日志文件的名称(软件会从起始日志文件开始,自动依次处理日志文件夹内的每个日志文件)。
之后软件会采用一个循环结构依次处理每个日志文件。从日志文件中读出一条记录后,如果这是一条有效的日志记录,则进行处理,再依次读取、处理之后的每一条记录。这个过程一直进行下去,直到当前日志文件处理完成,再打开下一个日志文件进行处理。
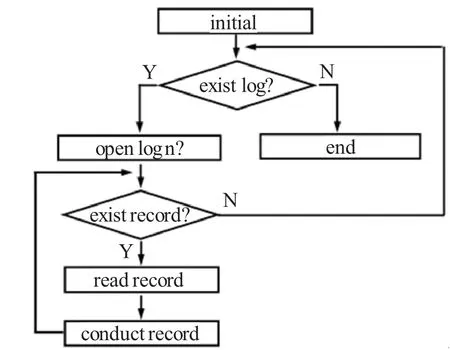
图6 软件的总体执行流程
6 软件的测试运行情况
应用该软件对某网络赌博网站的IIS日志文件进行了检验。该网站的日志文件记录了2012-02-28~2012-04-08共42天的玩家访问记录,总容量达到6.08GB。分析发现,日志文件中保存了大量玩家的用户名和密码信息,以及玩家在进行网络赌博过程中进行聊天的数据信息(数据采用UTF-8编码格式保存)。

图7 提取出的聊天数据截图
该软件从文件夹检出1342406条包含账户信息的日志记录。从这1342406条日志记录中共提取出14316个账户信息。软件共提取到2918条聊天日志记录(见图7)。在实际应用中该软件的日志分析效果良好。
1.谭浩强.C程序设计[M].北京:清华大学出版社,1998
2.严蔚敏.数据结构[M].北京:清华大学出版社,2002
3.裴有柱.计算机网络技术[M].北京:电子工业出版社,2009
4.Behrouz A.Forouzan.TCP/IP协议族[M].北京:清华大学出版社,2003
