搜索引擎日志短语标注规范
2013-04-14舒燕吕学强
舒燕,吕学强
(北京信息科技大学中文信息处理中心,北京100101)
1 引言
语言知识库的构建为计算机自然语言智能化处理提供了资源基础,语料标注是语言知识库构建的重要内容。所谓标注就是对语料库中的原始语料进行加工,把各种标识语言特征的附码标注在相应的语言成分上,以便于计算机识读[1]。北京大学计算语言所在开发了《现代汉语语法信息词典》[2]等语言资源的基础上,又对1998年、2000年《人民日报》语料库进行了标注加工处理[3-4],形成机器可学习的熟语料。语料库的句法标注是语料库语言学研究的前沿课题[5],近年来国内外已开发完成了许多大规模树库。英语方面,有英国的Lancaster-Leeds树库[6]和美国的Penn树库[7];德语方面,有NEGRA树库[8]和TIGER树库[9];捷克语方面,有布拉格依存树库(PDT)[10];汉语方面,有美国宾州大学的Penn中文树库[11]和中国台北“中科院”的Sinica中文树库[12]。
目前基于词的搜索引擎已逐渐不堪时代发展的重负,以短语作为索引项能够提高信息检索的准确率[13],因而成为研究者们探索改善搜索引擎的方向之一。搜索日志记录了人们检索信息的习惯爱好及使用特点,对搜索日志中检索词串进行加工标注处理,抽取出有效短语构建索引项,能够为改善搜索引擎提供一定的帮助。为保证人工加工、标注短语时的统一、规范,语料加工及标注规范的制定是必不可少的。本文吸收国内外树库加工处理技术和经验,基于搜索引擎查询日志特点,以短语描述为基础,制定一套搜索引擎日志短语划分和标注处理规范,为短语的人工加工、校对提供了一定的约束及规则,使机器能够有效地识读短语,为搜索引擎用短语词典构建提供了基础支撑。
2 语料库加工的目标
原始语料为搜狗实验室提供的2006年8月份的用户查询日志的查询词串,用户查询词串存在较大的随机性,因而错误或多样字符也是难以避免的。为了对其中的汉语短语进行标注研究需要做相关处理,其处理内容见下文详述。短语标注的目标是在查询词串形成结构化的XML文件的基础之上进行的,由于时间关系,加工规范小组选定了出现频次较高的“N+N”\“B+N”\“A+N”\“V+N”\“V+V”\“N+V”\“V+N+N”\“N+V+N”\“N+N+V”几种结构类型的短语进行短语边界、短语内部结构类型、短语外部功能类型、三词短语切分和二词短语信息焦点等的加工标注。其标注后的目标语料如图1所示,其中s表示一条经处理后的查询词串。

图1 标注后的语料
图中b表示短语边界值,sg表示三词短语的切分点位置,fc表示二词短语的信息焦点位置,st表示短语内部结构类型,ft表示短语外部功能类型。其各自取值范围及标注规范将在标注集介绍中详述。在图1中可提取出标注出的短语有:“华为/培训/中心”为定中结构的名词短语,“培训/中心”亦为定中结构的名词短语。“培训/中心”的信息焦点落在“培训”上。
3 标注预处理
根据对树库构建体系的总结,发现树库的构建与语法理论研究紧密结合,短语语料加工属于句法树库构建的一部分内容,但又不局限于此。按常理,短语边界值的确定受到句法语法理论的限制,但是在以构建搜索引擎索引项为目的的短语研究中,期望从一句话中抽取出来的索引项一方面要求更全面地定位查询词串所表达的信息,以期用户选择;另一方面更准确地定位查询词串所表达的信息,以为用户节省时间。在这个独特背景下,所提取的短语就要求准而多。因此在语法理论的基础上,本文有异于其他语块标注的最大特点是,允许短语存在嵌套。
3.1 语料库准备
语料库的准备阶段包括:语料库的预处理和加工软件的开发。
语料库的预处理包括:
1)提取查询词串,用户查询日志包含多种信息,提取所研究的有效信息;
2)去除查询词串的无意义词串,包括数字词串、外语词串、网址词串、特殊字符词串、乱码词串等,例如,“%$@@$%^”、“000898+site:business.sohu.com”、“きチ壁”等;
3)将查询词串以词串和词为单位存入XML文件中。
为提高语料标注与校对效率,专门开发了一套辅助标注软件,该软件带有XML节点属性值自动校对功能,提高了人工校对的效率和准确率。
3.2 短语定义
短语标注的首要问题是对短语的定义,本次研究对短语作如下定义:由两个或两个以上的词构成,能够充当某棵语法树中的一个节点。在这个定义中需要明确两点:第一,至少有两个词构成;第二,语法树中任意中间节点均可成为一个短语。例如,将图1中示例描绘成语法树的形式,如图2所示,其中Q(query)表示搜索引擎日志中经过预处理后的一条查询词串,中间节点表示短语功能类型,如NP表示名词短语,叶子节点为每一个词本身,叶子节点的父节点是词在当前词串中所对应的词性。
在图2中可以定义为短语的是,“华为培训中心”和“培训中心”两个名词短语,按照本文对短语的定义,“深圳华为培训中心”也可称为一个短语,但这超出了所研究的几种短语的范围,故此处不作处理。
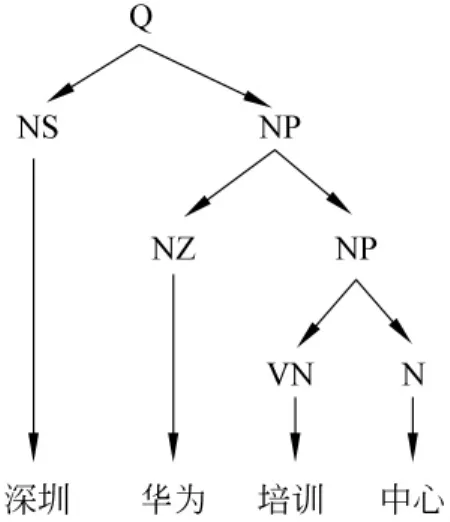
图2 语法树结构
4 标注集及标注规范
上文已述加工短语的有限性,因此在标记集及标注规范的制定上也是针对这有限的短语而制定的。
4.1 标注集
标注集的确定是汉语短语划分和标注的一项基础性工作。参照英文树库的处理实践和经验[6-7],结合汉语短语分析及搜索引擎用户查询日志语料的特点,并借鉴目前的研究成果[14],初步确定了除词和词性标注外的6个标注特征23个标记组成的短语标注集,详见表1。
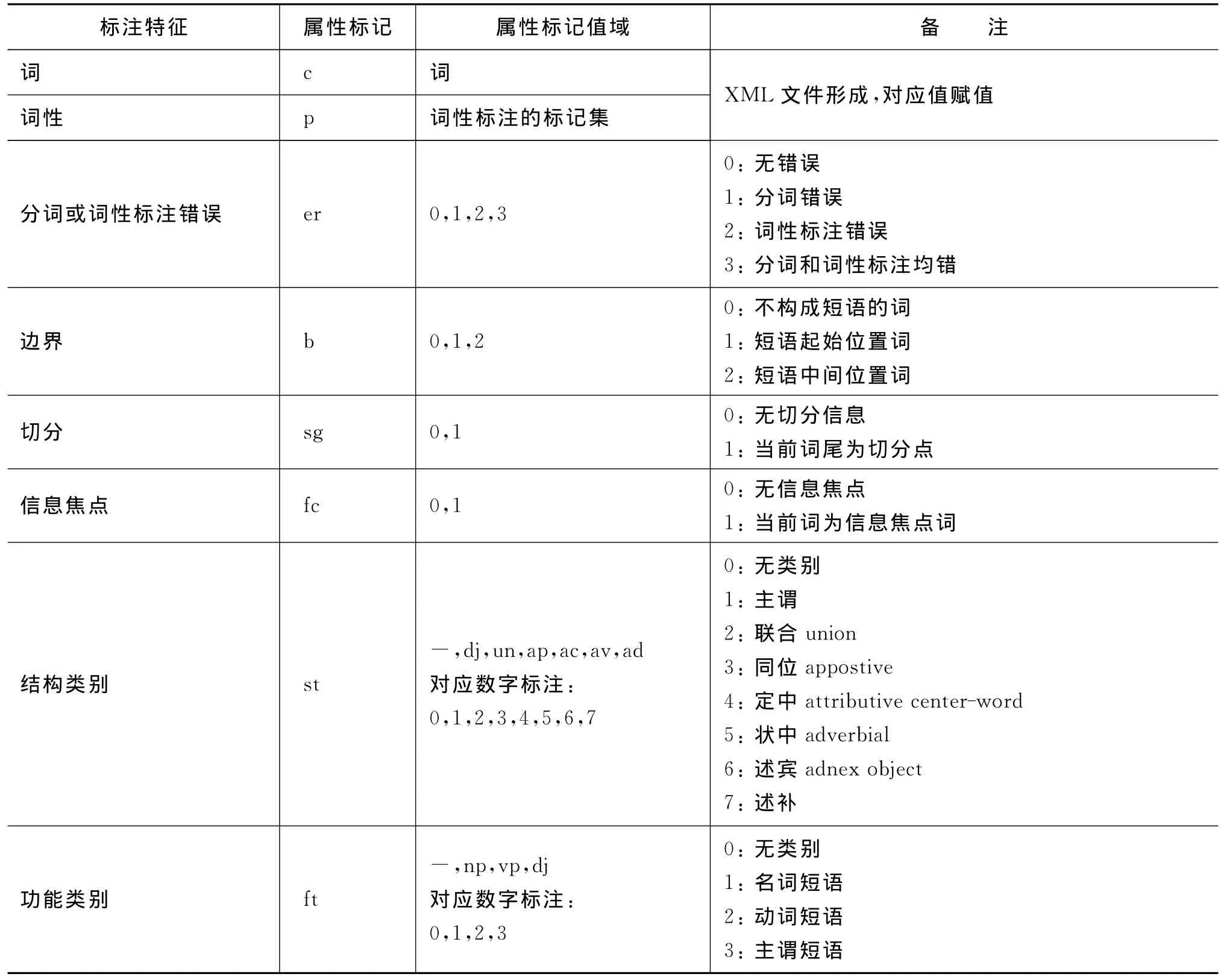
表1 短语标注集描述
表中的“信息焦点”是指人们传递信息过程中,常常有意无意加以强调用来提示交际的重点信息的一种方式,这里将语法重音定义为信息焦点,例如,“教育/信息网”,要传递的信息是关于教育方面的信息网,焦点落在“教育”上,“教育”重读,信息焦点在“教育”上。又如“教育/孩子”,强调“教育”所支配的对象是“孩子”,焦点在“孩子”上,“孩子”重读,信息焦点在“孩子”上。“结构类别”和“功能类别”的取值分别选取了几种待标注短语在预料中出现较多的类型。
本次研究采用了中国科学院计算技术研究所分词工具ICTCLAS2011①http://ictclas.org/进行分词和词性标注,为语料处理的下一步研究考虑,词性标注集选用了中科院计算所二级词性标注集。因此表1中的标注特征“词”和“词性”存储到XML文件是自动获取的。“属性标记”列主要是XML文件中识别各标注特征的值,表中的结构类别和功能类别均有限,主要是因为所研究短语暂时局限在“N+N”\“B+N”\“A+N”\“V+N”\“V+V”\“N+V”\“V+N+N”\“N+V+N”\“N+N+V”几种短语中,并从搜狗日志语料出发制定表1。为了XML文件处理及标注时的方便,将所有标注集映射成数字。
搜狗日志中用户查询串较为精简,缺乏一定的上下文语境,导致当前分词工具,对用户查询词串进行分词及词性标注时,其准确率有所降低。因此在标注集的确定时将分词及词性标注错误也考虑进来了,在人工标注时对其进行相应的人工加工处理,以便于在后期的深入研究中对分词或词性错误进行纠正处理。
4.2 标注规范
短语划分和标注的另一项基础性工作是建立完善的短语划分和加工处理标注规范。根据周强[15]在其博士论文中总结提到的,短语标注加工处理,需要兼顾到机器自动标注和人工校对的不同特点,一方面要在最大程度上保持处理结果的一致性,另一方面又要使划分出来的短语符合语言学上的规定。从所研究语料特点考虑,确立短语划分和标注的规范如下。
1)标注限制。本次标注仅限于标注“N+N”\“B+N”\“A+N”\“V+N”\“V+V”\“N+V”\“V+N+N”\“N+V+N”\“N+N+V”几种短语,其他结构短语不作标注要求;
2)原始标注特征,除“词”和“词性”外其余标注特征的标注值均为0;
3)对于边界特征b标记,如果b=0也即当前词为不构成短语的词,其后的标注特征值均不需修改,保持原始值。
4)当短语边界标记b=1时,查找最近一个b=2的词,构成短语,判断短语的结构类别和功能类别,并将其结构类别st和功能类别ft的值分别标记在b=1的词上。
5)两个以上词构成的短语才会存在切分特征,两个词构成的短语存在信息焦点特征。当短语边界标记b=1时,与最近一个b=2的词构成短语时,如果短语的词数大于等于3,则判断当前词是否为切分点,是则sg=1,否则判断当前词的下一个词是否为切分点,是则sg=1,否则当前短语不存在切分点;如果短语的词数等于2,则判断当前词是否为信息焦点,如果是则将fc改为1,如果否则将下一个词的fc改为1。
6)在信息焦点标记中,由于容易产生歧义,根据语料的特点,总结如下标注规律:“V+N”结构,动词短语焦点在N上,名词短语焦点在V上;“N+V”结构,主谓短语焦点在V上,名词短语焦点在N上;状中、定中结构焦点在修饰语上,分别为状语、定语;述补短语,焦点标注在补语上;同位结构标在具体指称的名词上,例如,“视频/n剪发/v”,焦点标在剪发上。
7)er属性的标注,先看是否存在分词错误,是则er=1;再看是否存在词性错误(当前分词情况下),是则er=2,如果这两者同时满足则er=3。
8)语料标注中只识别:人名、地名、机构名这三个名称的分词错误,像电影名、小说名、公司名、产品名、书名等这类名称性的词不把它们当作整体来标注,就按常规词串切分来标注。例如,“刘/nr1心/n画家/n”里面的“刘/nr1心/a”是个人名,应该作为一个整体,所以这两个词的er均需有所标注;而“不/d夜/tg城/n电影/n”中的“不/d夜/tg城/n”虽然是个电影名称,但是不识别它,按照分词工具对词串的正常切分法,在这里认为它不存在分词错误。
9)在分词错误情况下,存在严格意义的错分,例如,小/a考查/v分/v,这样的情况,将所有错分的词的er值均标为1;但如果存在误分的情况,例如,天天/d在/p线/n免费/v电影/n,那么只需将“在”和“线”上的er值标为1,其后的“免费电影”依然按正常短语标注。对于分词和词性标注均存在错误的情况,参照此规范。
10)分词标注存在错误的词,不参与构成短语,其后的特征标记均不需修改;词性标记错误的词,不需修改词性标记,但按照正常标注短语,例如,正常词性标注“改变/v点/n样式/n”,若语料中标注为“改变/v点/qt样式/n”,因为v+q+n不在标注范围内,则不作标注,若语料中标注为“改变/v点/vn样式/n”,v+n是标注的范围,而v+v+n不在研究的范围,所以只需要标注“点/vn样式/n”构成的短语,但词“点”的er值需要改为2。
为了使规范能完整有效的执行,特制定以下原则。
(1)语境优先原则,即基本语法理论优先。在语境优先下还会产生歧义,则采用下述原则解决;
(2)在短语界定时,采用从右往左滑动窗口的方法,将所有能形成的短语标注出来;当滑动到某一位置,若与其紧邻的下一位置的词语无法形成短语时,将从这个位置进行拆分,前后分成两部分;
(3)在短语切分歧义中,遵循音节和谐规律;
(4)存在分词错误情况下,存在严格意义的错分,例如,小/a考查/v分/v,这样的情况,则不予以处理;但如果存在误分的情况,例如,天天/d在/p线/n免费/v电影/n,则只标注其中的短语“免费电影”;
(5)总体遵循的原则:方便和可扩展性。由于目前标注语料的有限性,对标注规范的制定也是有限的,总体规范的制定和执行必须有利于后期研究的可读性和可扩展性。
5 结语
本规范制定立足于前人研究的基础,通过挖掘搜狗用户查询日志语料的特点和规律,运用语言学知识,经过长时间的讨论和试标注而制定,整个规范的制定及实施花费了14个月的时间。实验选用2006年8月1日搜狗实验室公布的用户查询日志中的查询词串为语料,随机选用其中1/2的语料采用本标注规范进行标注,然后对标注后的语料分别用最大熵、CRF、SVM_HMM模型进行短语边界识别和短语类别识别,识别效果在每一类模型中都取得了较好的结果。截至2011年6月底,已完成145 645条查询词串的标注及校对工作。
[1] 崔刚,盛永梅.语料库中语料的标注[J].清华大学学报,2000,(1).
[2] 俞士汶,朱学峰,王惠,等.现代汉语语法信息词典详解.北京:清华大学出版社,1998.
[3] 俞士汶,段慧明,朱学峰,等.北京大学现代汉语语料库基本加工规范[J].中文信息学报,2002,16(5):49-64.
[4] 俞士汶,段慧明,朱学峰,等.北京大学现代汉语语料库基本加工规范(续)[J].中文信息学报,2002,16(6):58-65.
[5] 周强.汉语句法树库标注体系[J].中文信息学报,2004,18(4):1-8.
[6] Leech G,Garside R.Running agrammar factory:the production of syntactically analysed corpora or‘treebanks’[C]//Proceedings of Stig Johansson and Anna-Brita Stenstrom(eds.)English Computer Corpora:Selected papers and Research Guide.1991:15-32.
[7] Mitchell P Marcus,Mary Ann Marcinkiewicz,Beatrice Santorini.Building a Large Annotated Corpus of English:The Penn Treebank[J],Computational Linguistics,1993,19(2):313-330.
[8] Skut W,Brants T,Krenn B,et al.A linguistically interpreted corpus of German newspaper text[C]//Proceeding of the Conference on Language Resources and Evaluation LREC-98.Granade,Spain.1998:705-711.
[9] Brants S,Hansen S.Developments in the TIGER annotation scheme and their realization in the corpus[C]//Proceedings of the 3rd Conference on Language Resources and Evaluation(LREC-02).Las Palmas de Gran Canaria,Spain.2002:1643-1649.
[10] Hajic J.Building a syntactically annotated corpus:The Prague Dependency Treebank[C]//E.Hajicova(Ed.),Issues of valency and meaning.Studies in Honour of Jarmila Panevova.Prague,Czech Repubilc:Charles University Press.1999.
[11] Xia Fei,Martha Palmer,et al.Developing Guidelines and Ensuring Consistency for Chinese Text Annotation[C]//Proceedings of the 2nd International Conference on Language Resources and Evaluation(LREC-2000),Athens,Greece.
[12] Chu-Ren Huang,Feng-Yi Chen,Keh-Jiann Chen.Sinica Treebank:Design Criteria,Annotation Guidelines,and On-line Interface[C]//Proceedings of the 2nd Chinese Language Processing Workshop,HongKong:29-37.
[13] 许静芳,李星,李奥.信息检索中主题式词典的构建方法[J].计算机工程,2005,31(21):143-145.
[14] 俞士汶.词语切分与词性标注—规范与加工手册[EB/OL].http://icl.pku.edu.cn/icl_groups/corpus/coprus-annotation.htm,1999.
[15] 周强.汉语语料库的短语自动划分和标注研究[D].北京:北京大学,2002.
