GPU加速技术在医学三维可视化中的应用
2013-04-12王玉,王宏
王 玉,王 宏
(1.东北大学 中荷生物医学与信息工程学院,沈阳 110819;2.东北大学 机械工程与自动化学院,沈阳110004)
近些年来,随着CT等影像设备的不断发展和升级换代,使得患者影像数据量越来越大,传统的二维显示方式已无法满足实际临床需要。医学三维可视化技术近些年来成为被关注的领域。
临床应用中除了对三维可视化重建图像质量提出较高的要求外,对交互绘制速度也提出了较高的要求。基于光线投射方法可以生成高质量的三维图像,能够满足临床诊断的需要。但它的一个突出缺点就是绘制速度慢,如果没有一种有效的加速方法对其绘制速度进行改善,其很难适应实际应用和医学图像技术发展的要求。
光线投射方法提出后,相应的加速技术的研究就从来没有停止过。目前,针对光线投射的软件加速技术主要有以下几种[1-2]:包围盒技术(bounding box)、空间剖分(space subdivision)技术和光线相关性(ray coherence)技术。
包围盒技术[3-5]的基本原理是在物体外围生成一个与物体外接的最小多面体,当采用光线投射方法进行绘制时,直接跳过多面体以外的数据而只在该多面体内进行采样和图像合成,则可以大大提高图像绘制的速度。
空间剖分技术主要是利用数据空间的相关性,通过对数据空间进行剖分,将连续的空体元划分到一定的子区间,当光线在数据空间穿行时,碰到这些子区间只需进行简单的求交运算,就可以略过整个子区间,从而减少光线投射的步数,达到降低绘制时间的目的。空间网格剖分有两种方式:一种是将空间均匀地分割成大小相同的小立方体网格的方法,具有代表性的是Fujimoto等[6]提出的ARTS(Accelrated Ray Tracing System)方法和Yagel等[7]提出的离散光线投射(Discrete Ray Tracing)方法。另外一种网格剖分方式是采用分层的空间剖分方法。例如二叉剖分(BSP)方法、八叉树(Octree)方法[8]和Kd树方法[9]等。
基于光线相关性的加速方法主要基于以下一种或几种原理[10]:
(1)像空间相关性(pixel-space coherency);
(2)物空间相关性(object-space coherence);
(3)光线间相关性(inter-ray coherency);
(4)空间跳跃(space-leaping);
(5)序列间相关性(sequence coherence)。
以上提到的一些加速方法,主要都是基于忽略无效计算的思想减少时间消耗,应该说都取得了很好的加速效果,但对于数据量越来越大的医学影像三维可视化,还是很难达到实时的显示效果。
本文基于NVIDIA显卡通用计算架构CUDA技术,将GPU加速技术应用于医学三维可视化体显示中,三维可视化重建速度得到了大幅的提高。同时,利用MFC扩展动态库及导出类技术,在架构设计上避免了大量代码移植工作。针对特定的GeForce 9600 GT显卡,对GPU同时执行的线程数与计算时间做了统计,找到了计算时间最少的最优线程数。
1 体显示
早在1984年,Tuy等[11]就提出了光线追踪的基本思想,并实现了对三维物体表面的直接绘制。Levoy[12]和Sabella[13]分别从插值方法、可视化映射、明暗处理、图像合成等方面对该方法进行了完善和扩充,形成目前体绘制中的标准光线投射绘制方法。
光线追踪的基本原理如图1所示。从屏幕的每个像素点出发,沿着视线的方向投射一条光线,以一定的步长在三维数据场中穿行。在它行进的过程中,不断进行重采样及颜色合成,直到阻光度足够大或光线已经穿过整个体数据空间为止。当屏幕上所有像素的光线投射过程都完成后,得到最终的显示图像。由于光线投射的重采样和图像合成是按照屏幕上每个像素上发出的光线逐个进行的,因而属于图像空间扫描的体绘制方法。

图1 光线追踪步长Fig.1 Ray tracing steps
基于光线追踪的体显示图像合成公式由下式给出[14-15]:

式中:cout,λ(u,v)为光线离开体元时的颜色值; cin,λ(uv)为光线进入体元前的颜色值;α(xi,yj,zk)为当前体元的阻光度;cλ(xi,yj,zk)为当前体元的颜色值。
从屏幕像素cλ(um,vn)出发,沿光线方向对阻光度及颜色分量采样合成,最终得到屏幕像素的颜色值,由下式给出:

式中:cλ(xi,yj,z0)=cbkg,λ;α(xi,yj,z0)=1。
2 程序实现
由式(2)可知,合成屏幕像素的光线追踪过程对于每个象素都是独立的,每个像素的光线追踪过程都可以由GPU中的一个thread完成,具有非常好的并行计算特性,非常适用GPU加速。
2.1 GPU加速技术介绍
由于现代的显示芯片具有高度的可程序化能力及相当高的内存带宽和大量的执行单元,可以利用显示芯片帮助进行一些计算工作,即GPGPU。CUDA是NVIDIA的GPGPU模型,它以C语言为基础,可以直接使用C语言编写可在显示芯片上执行的程序。
在CUDA的架构下,一个程序分为两个部分:host端和device端。host端是指在CPU上执行的部分,而device端则是在显示芯片上执行的部分。CUDA架构下,显示芯片执行时的最小单位是 thread。数个 thread可以组成一个 block。执行相同程序的block,可以组成grid。
2.2 程序架构设计
VS6没有集成CUDA程序编译,为此我们创建了一个接口导出类CGPUSpeedUI,在VS2008下,将其编译成相应的lib文件。原产品VS6工程通过该lib文件进行编译。这样 device端的kernel程序可以在VS2008下的动态库执行,不需要对原有工程做大量的代码移植工作,GPU加速架构设计如图2所示。
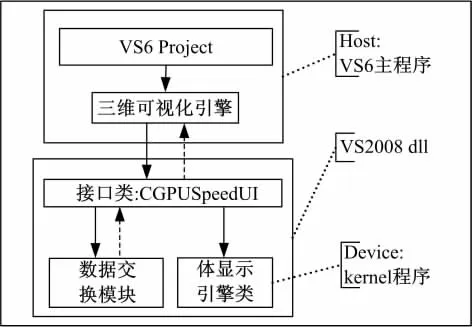
图2 GPU加速架构设计Fig.2 GPU speedup architecture
2.3 数据交换
CUDA中,GPU不能直接存取主内存,只能存取显卡上的显示内存。因此,需要将数据从主内存先复制到显卡内存中,进行运算后,再将结果从显卡内存中复制到主内存中。为此,需要在 host端CPU程序中将剂量计算需要的数据准备好,然后通过调用接口类CGPUSpeedUI成员函数将数据复制到显卡内存中。device端kernel程序执行结束后再通过调用接口类 CGPUSpeedUI成员函数将计算好的数据复制到同一主内存中。
这些被复制到显卡内存中的数据包括在device端 kernel程序需要定义的一些数组及变量。在CUDA内存管理中,纹理内存具有只读属性,全局内存可以进行读写操作。但纹理内存空间具有高速缓存,纹理拾取仅在高速缓存未命中时,才会从设备内存中读取数据,所以纹理内存与全局内存相比,具有更高的读取效率。针对以上特性,我们对只读数组采用纹理内存方式管理,对于可读写数组声明为全局变量
2.4 程序设计
图1中屏幕像素经过离散处理后,由式(2)可知,对于屏幕任意离散点对应像素颜色值Cλ(μm,vn)的计算可以在显示芯片执行最小单位thread中独立进行。体显示流程图如图3所示。

图3 体显示GPU计算流程图Fig.3 Volume rendering GPU computing process flowchart
3 结果与比较
在试验过程中,我们选择了五例临床患者CT序列影像数据进行试验。程序运行软件环境为Windows XP操作系统。硬件配置为台式机,CPU配置为Intel(R)Core(TM)2 Duo E8400@ 3.00 Hz,内存2 GB。GPU配置为GeForce 9600 GT。
3.1 GPU线程优化
在试验过程中,对GPU同时执行的线程数与计算时间做了统计,找到了计算时间最少的最优线程数。具体如图4所示数据曲线,从图4中可以看出,针对GeForce 9600 GT.显卡,同时并行执行200个左右的threads时,计算时间最短。且当threads个数大于220后,计算时间会有明显增加,主要原因是同时进行的 thread数目过多,导致一部分的数据储存在显卡内存中,降低了执行效率。

图4 并行执行threads个数与计算时间关系Fig.4 Threads number and computing time relationship
3.2 CPU与GPU计算时间比较
在试验过程中,对CPU计算时间和GPU计算时间也做了对比。对比结果如表1所示。

表1 CPU与GPU计算时间比较Table 1 CPU and GPU Com putation Time Comparison
从表1数据可以得出,GeForce 9600 GT显卡计算速度可提高6倍左右,使三维可视化重建时间在1 s以内。
4 结束语
本文提出的基于GPU加速技术也可以用于其他科学计算领域。而且考虑到VS6没有集成CUDA的编译环境,本文采用2.2节的程序架构设计,可以最大限度地减少代码重构的工作量,只需要将GPU device端运行的代码移植到更高版本的VS版本即可,这对在VS6环境开发的软件改造非常重要。同时,对于相对配置较低GeForce 9600 GT显卡即可达到6倍左右的加速效果,如果在更高配置的显卡上运行,将会得到更好的加速效果,具有非常高的应用价值。
[1]Hu Ying,Hou Yue,Xu Xin-he.Fast volume rendering formedical image[C]//Proceedings of XI International Congress for Stereology,Beijin,2003.
[2]Szirmay-Kalos L,Havran V,Balazs B,et al.On the efficiency of ray-shooting acceleration schemes[C]//Proceedings of SCCG'02 conference,2002:89-98.
[3]Chang A Y.A survey ofgeometric data structures for ray tracing[D].Brooklyn USA:Polytechnic University,2001:12-75.
[4]Clark JH.Hierarchical geometricmodels for visible surface algorithm[J].Communication of the ACM,1976,19(10):547-554.
[5]彭群生,鲍虎军,金小刚.计算机真实感图形的算法基础[M].北京:科学出版社,1999.
[6]Fujimoto A,Tanata T,Iwata K.ARTS:Accelerated raytracing system[J].IEEEComputer Graphics and Applications,1986,6(4):16-26.
[7]Yagel R,Cohen D,Kaufman A.Discrete ray tracing[J].IEEE Computer Graphics and Applications,1992,12(5):19-28.
[8]Fuchs H,Kedem Z M,Naylor B F.On visible surface generation by a priori tree structures[J].Computer Graphics,1980,14(3):124-133.
[9]Glassner A S.Space subdivision for fast ray tracing[J]. IEEE Computer Graphics and applications,1984,4 (10):15-22.
[10]Bentley J L.Multidimensional binary search trees used for associative searching[C]//Communications of the ACM,1975,18(9):509-517.
[11]Tuy H K,Tuy L T.Direct 2-D display of 3-D objects[J].IEEE Computer Graphics and Applications,1984,4(10):29-33.
[12]Levoy M.Display of surfaces from volume data[J].IEEE Computer Graphics and Applications,1988,8(5):29-37.
[13]Sabella P.A Rendering algorithm for visualizing 3D scalar field[J].Computer Graphics,1988,22(4):51-58.
[14]Westover L.Footprint evaluation for volume rendering[J].Computer Graphics,1990,24(4):367-376.
[15]Frieder G,Gordon D,Reynolds R A.Back-to-front display of voxel-based objects[J].IEEE Computer Graphics and Applications,1985,5(1):52-60.
