基于HOG和SVM的人体行为仿生识别方法
2013-04-03张祥合
王 丹,张祥合
(1.吉林大学仿生工程学报编辑部,长春130022;2.吉林大学吉林大学学报(工学版)编辑部,长春130022)
目前,针对人体行为识别的研究按特征采集方式的不同分为非视觉的方法和基于视觉的方法两类,非视觉的方法是指在人身上或者人所在空间安装各类传感器采集人的活动数据。这种采集方式具有侵犯性,对于被测者增加了心理和生理负担[1]。随着机器视觉的发展,基于视觉的人体运动分析和身份鉴别越来越受到人们的关注[2]。在基于视觉的人体行为识别研究中,基于视频的研究比较多,而基于静态图像的研究相对较少[3]。从本质上而言,视频就是静态图像的序列化,基于静态图像的识别结果可以直接应用到视频识别中。相对于视频的识别,基于静态图像的识别更有困难和具有挑战性,因为静态图像缺少了视频中包含涉及时间的动态信息,例如,踢足球的图像中可能包含跑和跳的信息,演奏乐器的图像中包含仅手持乐器的图像等。在研究人类视觉系统处理机制的基础上[4-7],将方向梯度描述符(Histogram of Oriented Gradient,HOG)引入到多尺度空间,建立了图像的多分辨鲁棒表示,并利用SVM提出了一种人体行为仿生识别方法。
1 算法原理
通过对大量人体行为理解研究文献的整理发现:人体行为理解研究一般遵从特征提取与运动表征、行为识别、高层行为与场景理解等几个基本过程,如图1所示。
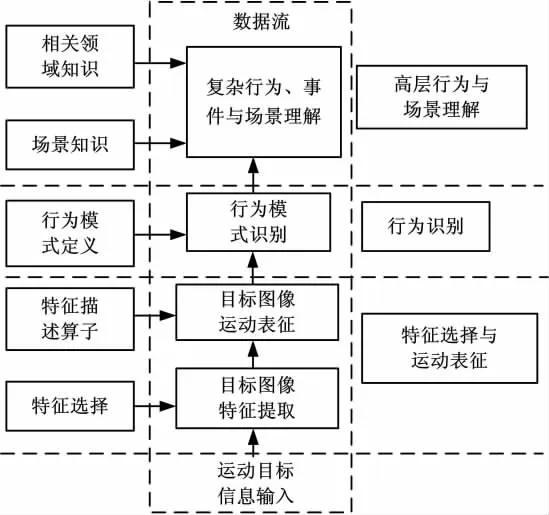
图1 人体行为理解的一般性处理框架Fig.1 General frame of understanding of human behavior
特征提取与运动表征是在对目标检测、分类和跟踪等底层和中层处理的基础上,从目标的运动信息中提取目标图像特征并用来表征目标运动状态;行为识别则是将输入序列中提取的运动特征与参考序列进行匹配,判断当前的动作处于哪种行为模型;高层行为与场景理解是结合行为发生的场景信息和相关领域知识,识别复杂行为,实现对事件和场景的理解。本文在研究人类视觉系统处理机制的基础上[4-7],将方向梯度描述符(Histogram of Oriented Gradient,HOG)引入到多尺度空间,建立了图像的多分辨鲁棒表示,并利用SVM设计了基于仿生模式识别的人体行为仿生识别方法,该方法检测图像中人体的能力较强。
2 实验
通过Google图像搜索引擎人体行为图片,建立了包含读书、打电话、考试、弹吉他、拉小提琴、跑步和步行共7类行为的数据库,数据库共有1400张带有复杂背景的人体行为图像。实验选取4类典型行为作为研究对象,分别是拉小提琴、弹吉他、步行和跑步,如图2所示。将搜索到的图像进行手动选取建立实验数据库。4类行为中,前两个是人与物交互的典型行为,后两者是与人体姿势密切相关并且极其相似的行为。选择以上这4类行为能够较好地反映分类器的分类能力,每类行为分别选取50张图片作训练样本,50张图片作测试样本。共200个训练样本,200个测试样本。每个样本分辨率为240×120,对其进行HOG特征提取得到9396维特征向量,根据高维仿生信息学的基本思想,利用SVM进行机器学习。

图2 行为识别的样本Fig.2 Samp les of behavior recognition
实验中,4类人体行为的混淆矩阵如表1所示。其中,spread值为径向基神经网络的散布常数,该值越大表示类间的距离阈值就越小。多次实验结果表明,当spread为3时,分类效果较好。由表1可知,拉小提琴与其他行为的混淆度最低,跑步和步行混淆度最高,两者之间有约30%的误判。表1中所示混淆矩阵的查全率如表2所示。
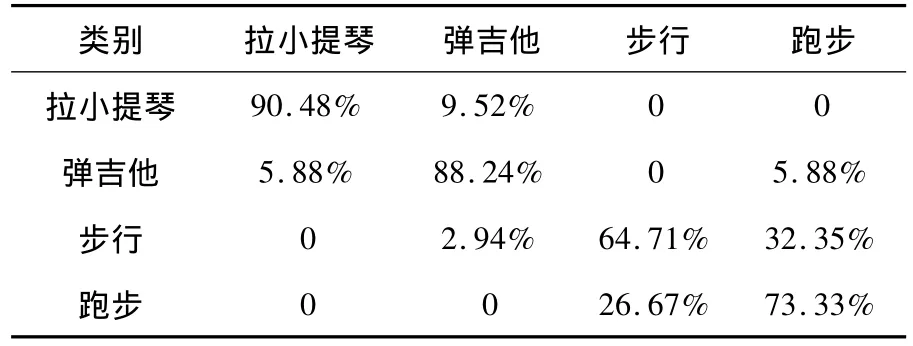
表1 4类人体行为的混淆矩阵(spread=3)Table 1 Confusion matrix of four kinds of human behavior(spread=3)
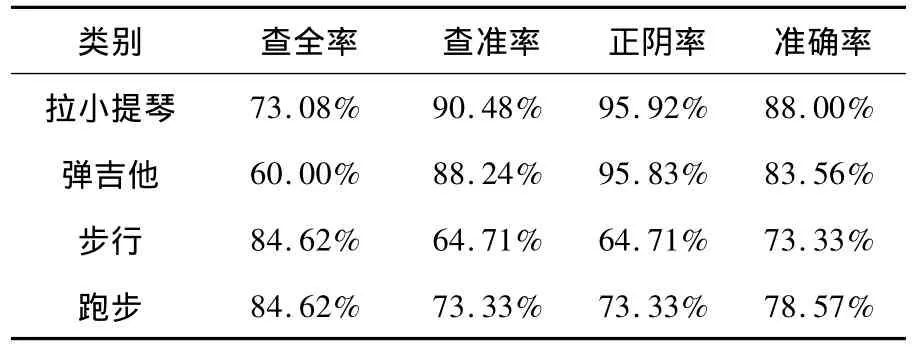
表2 表1混淆矩阵的查全率Table 2 Recall rate of confusion matrix
由表2可知,在查全率为73.08%的情况下,拉小提琴的查准率达90.48%,拉小提琴的分类效果是最好的,弹吉他的查全率较低,但查准率和准确率仍然非常理想。
图3为4类行为的PR曲线,由图3可知,跑步的PRC较为特殊,当查全率很低,即阈值设为较高的情况下,查准率却不像其他3类行为那样高,而当查全率在30%附近时查准率才达最高值。出现这一现象的原因是在步行测试样本中存在某些图像,它们的得分高于跑步测试样本,但这些样本出现的比例较小,由表1可知,这样的样本不会超过26.67%,所以随着查全率升高,大部分跑步样本被检测出来,查准率也升高了。
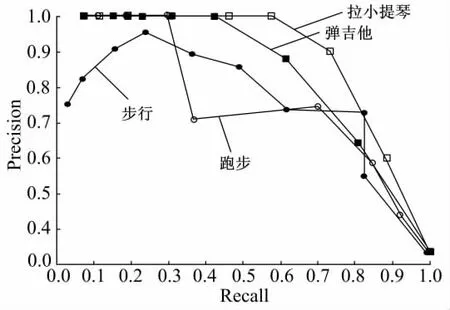
图3 4类行为的分类PR曲线Fig.3 PR curve of four kinds of behavior
3 与其他分类方法的比较
由于算法所用图像数据库的不同,以及所用行为类型的差异,无法直接进行分类性能的比较。本文主要通过以下两种方式将本文算法与其他分类方法进行比较。
(1)混淆矩阵
混淆矩阵反映了分类器的分类精确度,从侧面反映了分类器的分类性能。土耳其Bilkent大学的Nazli Ikizler[8]在2008年利用LDA(概率主题模型)提取行为特征,建立了SVM分类器;采用通过Google搜索行为图像自建的图像库和BBC的运动数据库进行实验,实验结果的混淆矩阵如表3所示。
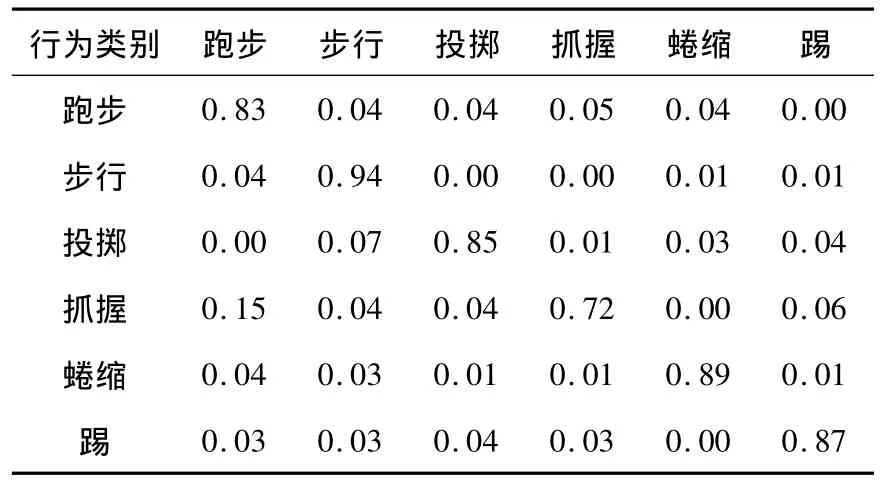
表3 文献[8]方法的混淆矩阵[8]Table 3 Confusion matrix by themethod in Ref.[8]

表4 多分类SVM分类器的混淆矩阵[9]Table 4 Confusion matrix ofmulti-class SVM classifier
将表3~4与本文方法的混淆矩阵(表1)进行比较可知,本文方法在对拉小提琴和弹吉他的识别率较高,利用SVM方法的分类器容易将步行划分到跑步中,本文在建立SVM分类器中利用高维空间仿生信息学处理高维矩阵的方法的分类性能要高于多分类SVM分类器。由于分类器的分类性能与所用图像库有较大的关系。而且,是否对训练集和测试集图像进行预处理也会影响分类效果。所以对于不同分类器使用不同数据库的识别效果的比较只能作为参考,无法准确评定某个分类器的性能的高低。从混淆矩阵表现的结果来看,本文提出的分类器性能与上述两种分类器的性能相当。
(2)平均准确率
为了进一步评价不同分类器的分类性能,法国里昂高等师范学校的Vincent Delaitre利用bagof-features模型建立了4种分类器,另外还基于SVM建立了两种分类器,6种分类器的分类性能如表5所示[10]。
由表5可知,LSVM+C2的分类器的分类准确率最高,为68.75%。该分类器不仅可以提升C2的分类性能,而且对于比较相似的人体行为,该方法也能提升LSVM的性能。但从平均准确率(Average Accuracy)来看,仍然低于本文方法80. 865%和83.98%的平均准确率。
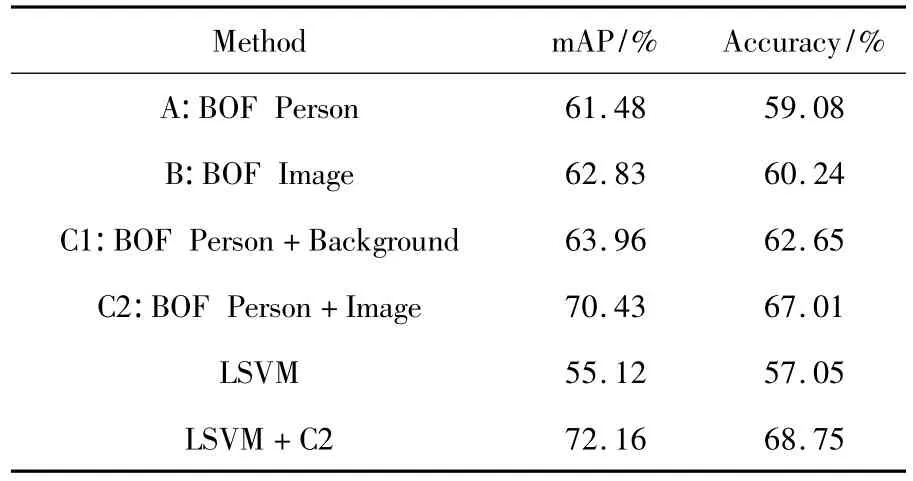
表5 6种分类器的分类性能[10]Table 5 Classification performance of six kinds of classifier
4 结束语
本文首先分析了目前国内外对人体行为理解的研究现状,在对HOG和SVM深入分析的基础上,利用高维空间仿生信息学中有关高维空间数据处理的知识,提出了基于HOG+SVM的人体行为仿生识别与分类方法。并利用目前常用于评价分类器分类性能的指标对本文方法进行了评价,最后与目前常用方法的结果进行了比较,结果表明,在针对静态图像中人体行为的分类与识别效果方面,本文方法对差别较大的行为识别效果较好,对相似行为的识别效果还有待于进一步提高。
[1]Smal I,Draegestein K,Galjart N,et al.Particle filtering formultiple object tracking in dynamic fluorescence microscopy images:application to microtubule growth analysis[J].IEEE TransMed Imaging,2008,27(6): 789-804.
[2]皮文凯,刘宏,查红彬.基于自适应背景模型的全方位视觉人体运动检测[J].北京大学学报:自然科学版,2004,40(3):458-464.
[3]侯志强,韩崇昭.视觉跟踪技术综述[J].自动化学报,2006,32(4):603-617.
[4]Wang S J,Chen X,Qin H,et al.Double synaptic weight neuron theory and its application[C]∥International Conference on Advances in Natural Computation,Changsha,China,2005,264-272.
[5]Weber M,Welling M,Perona P.Towards automatic discovery of object categories[C]∥IEEE Conference on Computer Vision and Pattern Recognition,2000.
[6]Zhang J,Marszalek M,Lazebnik S,et al.Local features and kernels for classification of texture and object categories:A comprehensive study[J].International Journal of Computer Vision,2007,73(2):213-238.
[7]谭菊.基于视觉感知的目标特性分析[D].重庆:重庆大学自动化学院,2010.
[8]Ikizler N,Cinbis R G,Pehlivan S,et al.Recognizing Actions from Still Images[C]∥19th International Conference on Pattern Recognition(ICPR),2008:1-4.
[9]Yang Wei-long,Wang Yang,MoriGreg,et al.Recognizing Human Actions from Still Imageswith Latent Poses[C]∥2010 IEEE Conference on Computer Vision and Pattern Recognition(CVPR),2010:2030-2037.
[10]Delaitre V,Laptev I,Sivic J.Recognizing human actions in still images:a study of bag-of-features and partbased representations[C]∥Proceedings of the British Machine Vision Conference,2010:1-11.
