利用编码层特征组合进行场景分类
2013-04-03章毓晋
崔 崟,段 菲,章毓晋
(1.北京航空航天大学电子信息工程学院,北京100191;2.清华大学电子工程系,北京100084)
对图像的理解实际上是要实现对场景的理解。对场景进行分类是实现场景理解的重要手段。具体说来,场景分类要根据视觉感知组织原理,确定出图像中存在的各种特定区域及其特性,并在此基础上给出场景的概念性解释[1]。实际中,场景分类常看作是利用计算机自动地将图像标记为不同语义场景类别的过程。场景分类在基于内容的图像检索等领域得到广泛重视和应用。
场景中感兴趣的部分常称为前景或目标,对场景的分类与对目标的识别有密切的联系。对目标的充分认识肯定对场景的分类有帮助,但场景分类与目标识别又不同,通常需要在尚未获得对目标的完全认识前对其进行分类。另一方面,分类的场景对目标的识别具有一定的指导作用。
从场景分类的方法看,最初的思路常将其建立在对目标识别的基础上。但一方面,由于目标识别本身就是一个困难的问题,另一方面,参照人类的视觉认知过程,仅初步的目标识别已可满足对场景的分类要求(场景分类并不一定完全基于对目标的完全认识),所以近年许多研究绕过目标识别直接进行场景分类。
基于图像的场景分类要借助从图像中提取的低层特征实现对高层语义(场景信息)的区分。为克服低层特征和高层语义之间的“语义鸿沟”,近年来有不少方法致力于构建中间语义层以在低层特征和高层语义间搭桥。如文献[2]就定义了图像的开放性、粗糙性等5个视觉属性作为中间语义层特性。
近年许多场景分类工作利用了词袋模型。词袋模型源自对自然语言的处理,引入图像领域后也常称为特征包模型。特征包模型由类别特征归属于同类目标集中形成包而得名[3]。基于生成式的“词袋模型”,文献[4,5]分别利用LDA概率模型[6]和pLSA模型[7],试图寻找图像的“主题”作为中层语义特征。为克服“词袋模型”仅考虑了组成图像的基元部件的自身特性而丢失了这些基元部件的空间位置信息的缺点,文献[8]提出了空间金字塔匹配与汇总的方法。最近取得较好结果的一种场景分类方法[9]就是基于“词袋模型”和空间金字塔汇总的框架。
考虑到场景内容的多样性和复杂性,对场景的分类常需要提取多种不同类型的低层特征,并将它们组合用于场景分类。现有的特征组合方法均将所提取的特征直接结合形成单个综合特征,然后以此进行分类工作。考虑到如上所述构建中间层对联系低层和高层的作用,本文试图将所提取的特征并不在开始就直接结合,而是对各类提取的特征先分别进行加工,而在较后的(对应较高层次)步骤中再结合。
本文概括介绍了典型的场景分类框架,讨论了场景分类中所用的特征,在回顾一般的特征层直接组合方法的基础上,详细介绍所提的编码层特征组合的方法,最后给出在实际数据上对特征层直接组合方法和编码层特征组合方法的对比实验结果和对结果的讨论分析。
1 图像场景分类框架
基于词袋模型的图像场景分类框架如图1所示。四个具体步骤是:①对输入图像进行特征提取以得到特征描述向量;②结合特征向量形成视觉词汇的词典;③对每幅图像的特征向量进行编码得到编码向量;④利用空间金字塔进行匹配汇总,并对汇总结果进行分类以得到类别标签。

图1 场景分类框架Fig.1 Framework of scene classification
2 特征选取
选取恰当的特征在场景分类中起着重要作用。尺度不变特征变换(SIFT)可看作一种检测图像中显著特征的方法[10-11],它不仅能在图像中确定具有显著特征点的位置,还能给出该点的一个描述矢量,也称为SIFT算子或描述符。
考虑到实际场景多是彩色的,在提取特征时,利用彩色信息可增加对场景的描述能力,从而更准确地进行场景分类。对彩色特征描述符的要求主要是能有效地描述彩色分布并且对光照强度的线性变化和偏移有较强的鲁棒性。一种利用彩色信息的方法将SIFT特征推广到彩色空间,提出了RGB-SIFT特征[12]。RGB-SIFT特征是对图像中的红、绿、蓝三色通道分别求出SIFT特征后将结果合并得到的,具有对光照线性变化及偏移的鲁棒性。
本文探讨在不同层次进行特征组合的问题,所以除选择SIFT特征外,还增加了归一化彩色直方图(Normalized color histogram,NCH)特征[12]。与传统的彩色直方图不同,为了服从标准正态分布N(0,1),红(R)、绿(G)、蓝(B)三个彩色通道的像素值分布被分别归一化:

式中:R',G',B'分别为归一化后的红、绿、蓝三通道像素值。本文采用的归一化颜色直方图对每个颜色通道取16个bins(直方条),共计48维。
3 特征层直接组合
对低层特征的直接组合是在特征层进行的。具体就是分别提取输入图像的 SIFT特征和NCH特征,将两种特征合并作为一个新的特征参与接下来的视觉词典建立,编码成向量,并进行匹配汇总等步骤(见图2)。设SIFT特征和NCH特征的维数分别为DS和DN,则组合后特征的维数D为D=DS+DN。组合后的特征在前DS维和后DN维分别使用SIFT和NCH两种特征描述图像,其描述性能与两种异质信息的加权和相关。

图2 特征层特征组合Fig.2 Feature combination in feature layer
4 编码层特征组合
在特征层直接组合方法形成的视觉词典中每个“词”包含了所有参与组合的特征的信息,编码过程中待编码特征与码本的距离测度将同时由所有特征参与衡量。这样得到的特征编码显然是所有特征综合的结果,无法保证单一特征的鉴别性不变。
为在不同特征组合的同时保留单一特征的鉴别性,本文考虑在编码层(相比特征层更高,也可看作中层)进行特征组合。具体做法是在分别提取SIFT和NCH特征后,对两种特征分别生成视觉词典并编码,然后将两种特征的编码结果合并后进行空间汇总并送入分类器(见图3)。设SIFT特征和NCH特征的词典长度分别为LS和LN,则组合后的特征编码维数为L=LS+LN。
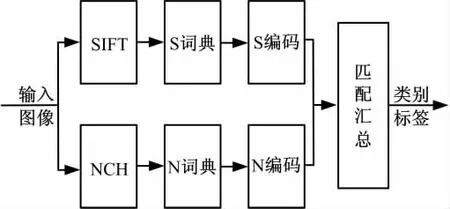
图3 编码层特征组合Fig.3 Feature combination in coding layer
如上组合得到的编码具有一定的结构性,编码向量中前LS维和后LN维分别对应于SIFT特征和NCH特征。由于编码结果将直接参与分类,所以在编码层的特征组合不仅利用了编码的结构性而且在组合的同时保留了参与组合的单一特征的鉴别性。在场景分类中,多特征组合要取得比单一特征更好结果的关键是在特征组合时没有丧失其中每个单一特征的鉴别性,从而在某些特征无法对场景进行区分时可利用其它特征进行分类。所以,可期望在编码层的特征组合将比在特征层的特征组合获得更高的分类准确率。
5 实验结果与分析
为验证所提出的特征层组合方法的有效性和编码层特征组合方法相对于传统特征层组合方法的优越性,本文选用384维的RGB-SIFT特征[12]作为基准,分别对SIFT和NCH在特征层的组合以及SIFT和NCH在编码层的组合进行了对比。
5.1 实验设置
实验在三个场景图像数据集上进行:Corel-10、Sports-8和MIT Scene-8。其中,Corel-10含有10类自然场景的共1000张图片,实验中随机选取每类50张图片用于训练,剩余50张图片测试; Sports-8含有8类运动场景的共1579张图片,实验中随机选取每类70张图片用于训练,剩余图片中随机选取60张用于测试;MIT Scene-8含有8类户外场景共2696张图片,实验中随机选取每类100张图片用于训练,剩余图片用于测试。为了得到更可靠的结果,在每个数据集上的实验结果都是10次独立随机选择训练集与测试集后运行结果的平均值,并给出标准差。
为归一化数据,在所有实验中都将输入图像统一按比例缩小至最大边长为300像素。通过用采样步长为8像素的密集采样将每幅图片划分为16×16像素大小的图像块,以图像块为单位提取特征,并对特征进行L2范数归一化。为生成视觉词典,利用了K-means聚类算法,其后再用5-近邻矢量量化方法[13]对特征进行编码。在汇总方法中,采用了最大值汇总[14]。具体采用3层空间金字塔[9]结构(1×1+2×2+1×3)进行最大值空间汇总。最后,本文选择直方图相交核[15]的支持向量机作为分类器,在多类分类中采用一对多的分类策略。
5.2 特征层组合实验
在特征层组合实验中,比较了RGB-SIFT特征与SIFT和NCH在特征层组合的特征。所采用的词典长度均为1024。实验结果如表1所示。

表1 特征层组合结果Table 1 Results of feature layer combination
从实验结果可以看出,特征层组合后用176维的特征取得了与384维RGB-SIFT特征相近的分类准确率。RGB-SIFT特征从某种意义上来说也是一种在特征层组合的特征(可看作在提取特征前先进行了组合),通过计算三色通道的SIFT特征间接利用了彩色信息。但是,由于SIFT特征主要是对图像中梯度信息的描述,而灰度图像与彩色图像相比并没有明显的梯度信息的缺失。所以,RGB-SIFT特征在综合利用梯度和颜色信息时有一定的冗余性。特征层组合的方法(可看作在分别提取特征后再进行组合)更高效地综合利用了梯度与颜色信息。SIFT和NCH组合特征与RGB-SIFT特征相比,特征维数大大减少,所以在词典生成与编码效率上应有明显的优势。
5.3 编码层组合实验
在编码层组合实验中,比较了RGB-SIFT特征与SIFT和NCH在编码层组合的特征。所采用的词典长度均为2048,其中两个待组合特征分别采用长度为1024的词典。实验结果如表2所示。

表2 编码层特征组合结果Table 2 Results of coding layer feature combination
从实验结果可看出,利用编码层特征组合得到的分类准确率在使用相同长度的词典时明显高于使用RGB-SIFT特征得到的结果。这在图4给出的对Corel-10数据集分别利用SIFT特征和编码层特征组合得到的分类混淆矩阵中也得到了验证。图4右图中主对角线上的数值明显大于图4左图中主对角线上的数值,即分类正确率都有所提高。

图4 SIFT特征与编码层特征组合方法在Corel-10上的混淆矩阵比较Fig.4 Com parison of confusion matrixes between SIFT and coding layer feature combination on Corel 10
6 结论与展望
本文比较了编码层特征组合与特征层特征组合的效果,分析和实验均表明编码层特征组合在图像分类中有更好的效果。本文也比较了利用(在特征提取前的)组合特征与分别提取特征再将结果组合的效果,分析和实验均表明后者优于前者。因此,从语义角度看,在组合特征以提高图像分类的准确性时,对特征的组合应尽量在较高的语义层上进行。
上述结论也为进一步的工作指明了方向,即一方面要研究更多种类的异质特征以更全面描述图像的特性,另一方面还要研究较高语义层次的特征组合或融合方法,以期更有效地利用特征信息。
[1]章毓晋.图像工程(下册):图像理解[M].(第3版).北京:清华大学出版社,2012.
[2]Oliva A,Torralba A.Modeling the shape of the scene:a holistic representation of the spatial envelope[J]. IJCV,2001,42(3):145-175.
[3]Sivic J,Zisserman A.Video Google:A text retrieval approach to objectmatching in videos[C]∥Proc ICCV II,Nice,France,2003:1470-1477.
[4]Li F F,Perona P.A bayesian hierarchical model for learning natural scene categories[C]∥Proc CVPR,San Diego,USA,2005:524-531.
[5]Bosch A,Zisserman A,Munoz X.Scene classi cation via pLSA[C]∥Proc ECCV,Graz,Austria,2006:517-530.
[6]BleiD,Ng A,Jordan M.Latent dirichletallocation[J]. Journal of Machine Learning Research,2003(3):993-1022.
[7]Sivic J,Russell B C,Efros A A,et al.Discovering objects and their location in images[C]∥Proc ICCV,Beijing,China,2005:370-377.
[8]Lazebnik S,Schmid C,Ponce J.Beyond bags of features:Spatial pyramid matching for recognizing natural scene categories[C]∥Proc CVPR,New York,2006: 2169-2178.
[9]Yang J,Yu K,Gong Y,et al.Linear spatial pyramid matching using sparse coding for image classification[C]∥Proc CVPR,2009:1794-1801.
[10]Lowe D.Distinctive image features from scale-invariant key points[J].IJCV,2004,60(2):91-110.
[11]Nixon M S,Aguado A S.Feature extraction and image processing[M].(2ed).Academic Press,2008.
[12]Van de Sande K E A,Gevers T,Snoek C G M.Evaluation of color descriptors for objects and scene recognition[C]∥Proc CVPR,Anchorage,USA,2008:1-8.
[13]Van Gemert JC,Veenman C J,Smeulders A W M,et al.Visualword ambiguity[J].TPAMI,2010,32(7): 1271-1283.
[14]Boureau Y,Bach F,Le Cun Y,et al.Learningmid-level features for recognition[C]∥Proc CVPR,2010:2559-2566.
[15]Maji S,Berg A C,Malik J.Classification using intersection kernel support vector machine is efficient[C]∥Proc CVPR,Anchorage,USA,2008:1-8.
