Q 学习在RoboCup 前场进攻动作决策中的应用
2013-02-22章惠龙李龙澍
章惠龙,李龙澍
安徽大学 计算机科学与技术学院,合肥230039
1 引言
RoboCup 仿真组比赛是在不受硬件平台约束的纯仿真软件环境中进行的,Agent 能够通过机器学习等方法,达到类似或者接近人类的那种各种选择的最优决策。反应到比赛场上,就是使11 个分布式的Agent 在仿真的对抗环境中,通过协同工作,能够最优、快速、高效地处理球场上的一切问题,比如说动作选择的决策、视觉选择的决策、个体动作的执行等。Q 学习常被用于RoboCup 环境中的强化学习问题,然而大部分是运用在Agent 的个体动作学习上,比如传球、带球、射门等。本文将Q 学习运用到局部范围的RoboCup 前场进攻动作决策中,通过引入区域划分,基于区域划分的奖惩函数和对真人足球赛中动作决策的模拟,使Agent的进攻能力得到一定程度上的加强。
2 Q 学习算法
强化学习(Reinforcement Learning,RL)是一种非监督的Agent 自学习算法,它的基本思想是从环境中得到反馈而进行学习,就是所谓的trial and error 学习方法。在学习过程中,Agent 不断尝试进行动作选择,并根据环境的反馈信号(即回报)调整动作的评价值,最终使得Agent 能够获得最大回报的策略。
Q 学习算法是一种普遍采用的强化学习算法。Q 学习的特点是不需要知道环境模型,直接利用经历的动作序列学习最优的动作,因此Q 学习常被用于解决不确定环境下的强化学习问题。
在马尔科夫决策过程(Markov Decision Processes,MDP)中,Agent 可以感知周围环境不同周期时候的不同状态,并且可以执行动作库中的任何一个动作。在t 周期,环境状态为St,Agent 选择动作at执行后,环境状态由St变为St+1,同时反馈回报r(st,at)给Agent。在以后的每个周期,Agent 重复迭代,直至达到终止周期。用动作评价函数Q(st,at)表示在st状态Agent 选择动作at后的最大折算累积回报,即由Agent 执行动作后的立即回报加上以后每个周期都遵循最优策略的值,可以用公式表示为:
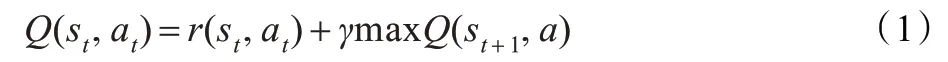
其中,γ(0 ≤γ ≤1)为折算因子,是一常量,a 为动作库中的任一动作。Agent 每周期进行动作选择时,总是选择对应此状态拥有最大Q 值的动作,然后依照此策略进行迭代。经过反复的迭代,Q 值不断的更新,这就是Q 学习算法的学习过程。
为了使Q 学习能够在适当周期内收敛,需要在公式中加入适当大小的学习率。引入学习率α 以后,Q 学习算法的公式可以表示为:
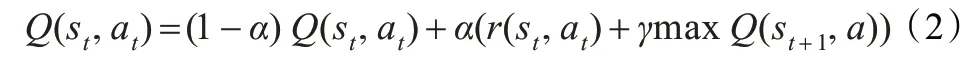
其中,α(0 <α <1)为控制收敛的学习率,γ 为折算因子。
3 Agent动作决策框架
在RoboCup2D 仿真环境中,Server 为Agent 提供了6种基本原子动作,分别是dash(加速)、turn(身体转向)、kick(踢球)、tackle(铲球)、catch(扑球)、move(瞬移),其中catch动作只提供给守门员使用。Agent 在一个仿真周期内可以任选其一发送给Server,但是不能重复发送。而在Client端,球队可以根据自己的需要,将这6 种原子动作组合成为一些高级个体动作,供Agent 调用执行。不同的球队可能拥有自己不同的高级个体动作集。本文依照的是Agent 2D 底层代码,该底层提供了5 种个体高级动作供Agent 持球时候调用。由于本文实验着重研究前场进攻,所以只列出了Agent 持球时候可以执行的一些高级动作,并且守门员专有的catch 动作并没有包括在内。
图1 中,Agent 通过ActionGenerator(动作发生器)选择需要执行的动作,动作执行后WorldModel(世界模型)发生改变,作用于Field Evaluator(球场评估器),Field Evaluator反馈一个reward(回报)给Agent,接着Agent 进行下一轮的动作选择。这个过程就是Agent 的一次动作决策的过程,也就构成了Agent 的动作决策框架。仔细观察该图不难发现,这个过程与Q 学习的学习过程相当类似,将Action-Generator内的动作选择机制用Q 学习算法进行训练,Agent的动作决策过程就变成了一个Q 学习算法的学习过程。

图1 Agent的动作决策框架图
4 使用Q学习算法进行Agent前场局部进攻训练
4.1 状态描述
在Agent 的前场进攻中,需要考虑的因素非常多。大多数情况下,前场进攻中都会出现这样一个情况:持球的Agent 面对一个紧逼的防守队员,旁边还有一个己方队员,这时候他该怎么办。此时就可以选取球的位置(SA),离自己最近的己方球员的位置(SB),离自己最近的对方球员的位置(SC)来描述一个特定的环境状态。持球球员的位置与球的位置大致相同,所以这里就不予考虑了,于是<SA,SB,SC>就可以用来描述球场上局部范围内的一个环境状态。
在球场上是用X 和Y 坐标来描述一个单位的位置的,此时Agent 的位置信息SA、SB、SC都是连续的,这不利于状态描述,需要人工离散它们。本文将前场区域划分为30×10个小的区域,其中X 轴方向分为30 等份,Y 轴方向分为10等份,此时就可以用一对离散化的(i,j)来描述任何一个Agent的位置信息(0 ≤i ≤29,0 ≤j ≤9)。
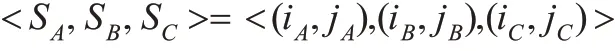
4.2 动作集的确定
直接使用Agent 动作决策框架中给出的5 种高级个体动作作为Agent 执行的动作集,Agent 的动作集可以表示为:{shoot,pass,cross,dribble,selfpass}。
4.3 奖惩回报的确定
本文实验中奖惩回报的确定相对复杂,可以表示如下:
(1)己方进球,r=1;
(2)球到达射门点,r=0.9;
(3)球出界,r=0;
(4)以上情况都不是,r=区域基础回报+区域内部回报。
所谓的射门点是综合前场特别是禁区内的各个因素,经过数学运算得到的射门位置,可以通过给出的球的位置信息直接判断此时能否进行射门,这里暂不研究。下面着重介绍情况(4)时奖惩回报是如何给出的。
前面讨论状态描述的时候,为了离散Agent 的位置信息,将前场区域划分为了30×10 个小区域。这里为了确定奖惩回报,将前场区域划分为4 个大区域,关于X 轴对称的上下区块为同一区域,划分之后不同的区域拥有不同的奖惩基础回报,球落在哪个区域,就选择那个区域的基础回报作为整体回报的一部分。
图2 中相同的号码代表相同的区域。4 号区域基础回报最大,因为此区域非常有利于进球,其次为3 号区域,再其次为1、2 号区域。如果球队进攻侧重于中路突破,则2号区域基础回报大于1 号区域;如果侧重于边路突破,则2号区域基础回报小于1 小区域。
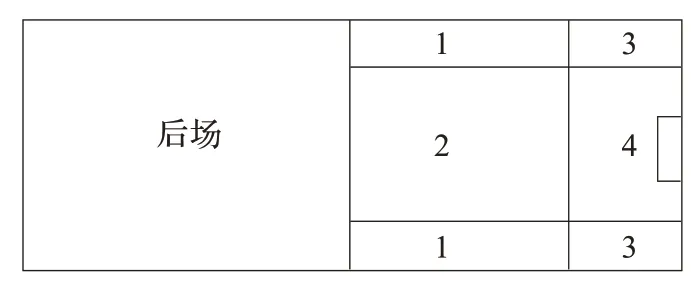
图2 前场区域划分
除了区域基础回报外,还需要加上区域内部回报来更加细化整体回报。区域内部回报主要是由球的位置信息和离球最近的对方、己方球员与球之间的距离确定的。
在情况(4)下,r=区域基础回报+区域内部回报,需要保证此时的r<0.9,而且区域基础回报至少应该大于10 倍的区域内部回报。至于具体如何确定这两种回报,可以有多种方法。在本文的实验中,1、2、3、4 号区域的基础回报分别被设定为0.5、0.5、0.6、0,7。
通过仔细观察现实生活中的真人足球赛可以发现这样一个现象:一个球员拿到球的时候,当防守队员距离自己很远的情况下,他会快速带球推向对方球门;当防守队员距离自己稍近但是又不至于能够抢断球的情况下,他会慢速带球试图摆脱对手,同时观察场上队友的位置准备传球;当防守队员继续逼近以至于可以抢断球的情况下,他就会将球传给队友,或是进行射门。将这种真人足球赛中的动作决策模式引入到区域内部回报中,通过修改区域内部回报,使得Agent 能够做出接近或者是类似的这种动作决策。本文的实验中,区域内部回报给定如下:
Ifd1>5.0
区域内部回报=(XA+(d1-5.0)×2.0×XA-d3)/100
If 3.0 <d1≤5.0
区域内部回报=(XA+(d1-d2)×2)/100
Ifd1≤3.0
区域内部回报=(XA-d3)/100-本区域基础回报
式中,XA为球的X坐标,d1为离球最近的防守球员与球之间的距离,d2为离球最近的己方球员与球之间的距离,d3为球到对方球门之间的距离。公式中通过控制XA的倍数来控制带球速度;通过控制d3的大小来控制是否将球推向对方球门;通过控制d1的大小来在一定程度上控制是否摆脱最近的防守队员;通过在区域内部回报中减去本区域基础回报,使得此时Agent 的总体奖惩回报急剧减小,Agent为了快速摆脱这种状态,就会进行传球,或是射门。
从此公式可以看出,当防守队员距离持球队员很远时(d1>5.0),快速带球推向对方球门;当防守队员距离持球队员稍近时(3.0 <d1≤5.0) ,慢速带球,摆脱防守,寻找传球点;当防守队员距离持球队员很近时(d1≤3.0),将球传给队友,或是射门。
4.4 Q 值的更新
本文实验依照的Q值更新公式为:

其中,规定α=0.15,γ=0.85。当环境处于终止状态时就可以根据此公式更新一次Q值。终止状态包括己方进球,球出界外,球被对方球员拦截这几种状态,一些由于犯规造成的情况没有考虑在内。
4.5 实验结果
通过大量周期的仿真学习后,各个状态下Q值逐渐趋近于收敛到一个稳定的值。将经过学习训练后的Agent 投入到实际比赛中,以进球为最终统计数据,让Agent 完全按照学习到的Q表进行自主动作决策,取得了良好的效果。特别是训练场景设置在禁区边缘的时候,Agent 经过学习训练后能够在小范围内灵活带球躲避守门员和防守队员,将球带到或者传到射门点,大大增加了射门的次数。
表1 给出了底层代码、手工代码和Q学习代码分别与UVA 优秀代码、底层代码进行100 场比赛后,平均每场比赛的进球数。其中底层代码是手工代码和Q学习代码的基础,手工代码和Q学习代码都是在其上经过修改而成的,UVA 优秀代码是国内一支以UVA 为底层的RoboCup2010全国赛8 强之一的球队代码。从表1 中可以看出,Q学习代码相对于底层代码和手工代码,无论对手是UVA 优秀代码还是底层代码,进攻实力都大大增强,符合实验的初始设计目标。

表1 实验统计结果
5 结束语
本文将Q学习算法应用到RoboCup 前场进攻动作决策中,通过大量周期的训练学习,使得Agent 能够进行自主动作决策,进而加强Agent 的进攻能力。通过观察实验之后的统计结果,表明将Q学习应用于Agent 的动作决策之中取得了一定的效果。然而不足之处也是很明显的,如环境状态描述过于简单粗糙,并没有细致地描述出球场上的实时状态。将此方法应用于安徽大学最新版本的DreamWing仿真2D 球队代码中,通过进行多场实际的对抗性比赛,发现球队进攻能力取得了明显的提高,符合本文的设计目标。
[1] Akiyama H,Shimora H.HELIOS2010 team description[C]//Proceedings of the Robocup 2010 Conference,2010.
[2] 马勇,李龙澍,李学俊.基于Q学习的Agent 智能防守策略研究与应用[J].计算机技算与发展,2008,18(12).
[3] 周勇,刘峰.基于改进的Q学习的RoboCup 传球策略研究[J].计算机技术与发展,2008(4):63-66.
[4] Kostas K,Hu Huosheng.Reinforcement learning and co-operation in a simulated multi-agent system[C]//Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems,17-21 Oct,1999,2:990-995.
[5] de Boer R,Kok J.The incremental development of a synthetic multi-agent system:the UVA Trilearn 2001 robotic soccer simulation team[D].The Netherlands:University of Amsterdam,2002.
