MooseFS中chunkserver负载均衡算法研究*
2013-02-21艾云霄谭跃生王静宇
艾云霄,谭跃生,王静宇
(内蒙古科技大学 信息工程学院,内蒙古 包头 014010)
随着云计算迅速发展,IT界将进入“云”时代。然而,云计算[1]中会产生海量的数据存储,传统的文件系统已不能满足其性能要求。作为云存储的核心基础平台,分布式文件系统的重要性日益凸显。目前,互联网上应用最多的分布式文件系统有 GFS[2]、HDFS[3]、MooseFS等。MooseFS分布式文件系统,其设计思想来源于google文件系统,采用的是主从式服务器架构,通过将文件数据分成64 MB的chunk块分散存储在多台通过网络连接起来的计算机节点上,这种模式不可避免地存在一些节点分配的chunk块过多,而另外一些节点却是空闲的,导致系统的chunkserver数据块分配负载不均衡问题。
数据的负载均衡是分布式文件系统的核心之一,是否有好的负载均衡算法直接影响系统的性能,如果算法没有选择好,会导致负载严重失衡,使系统的性能不能得到充分的发挥。因此有必要研究chunkserver的数据块负载均衡选择算法,以解决chunkserver数据块分配的负载均衡问题。
1 相关工作
负载均衡[4-5]的实现方法主要有静态模式和动态模式。静态模式是指在系统执行前,提前采取相应措施,把数据存储到各个节点上,尽可能地保证系统运行过程中不出现负载不均衡现象。动态模式是指在系统执行过程中,实时根据节点的存储状况来实现负载均衡。很显然,静态模式仍然还会有较高的概率出现系统负载不均衡现象,动态模式虽然实现起来比静态模式复杂,但是执行后效果好。MooseFS分布式文件系统就是采用动态模式来实现chunkserver的负载均衡的。
负载的量化有多种标准,如CPU利用率、内存利用率等。目前,最常见的负载均衡算法有轮转法、随机法、散列法、最快响应法[3]等。轮转法,均衡器将新的请求轮流发给节点表中的下一个节点,是一种绝对平等。随机法,把伪随机算法产生的值赋给各节点,具有最大或最小随机数的节点最有优先权,各个节点的机会也是均等的。散列法也叫哈希法,利用单射不可逆的HASH函数,按照某种规则将新的请求发送到某个节点。最快响应法,平衡器记录自身到每个节点的网络响应时间,并将下一个到达的连接请求分配给响应时间最短的节点。
本文以chunkserver上chunk块的多少作为负载均衡的指标。这里负载均衡是指各个chunkserver上chunk块数的多少大致相同,不会出现一些chunkserver上块数很多,而另外一些chunkserver上块数很少或是没有块数,造成一些chunkserver运行繁忙,而一些chunkserver处于空闲状态的不均衡现象。
2 MooseFS的chunkserver负载均衡算法
Moose File System[6]是一个具备容错功能的网络分布式文件系统,它将数据分布在网络中的不同服务器上,MooseFS通过FUSE使之看起来就是一个Unix的文件系统。即分布在各个范围的计算机将它们未使用的分区统一进行管理使用的一种文件系统。
2.1 MooseFS文件系统架构
MooseFS分布式文件系统主要由四部分组成[7]:
(1)管理服务器 managing server(master):负责各个数据存储服务器的管理,文件读写调度,文件空间回收以及恢复,多节点拷贝。
(2)元数据日志服务器 Metalogger server(Metalogger):负责备份master服务器的变化日志文件,文件类型为changelog_ml.*.mfs,以便于在 master server出问题的时候接替其进行工作。
(3)数据存储服务器 data servers(chunkservers):负责连接管理服务器,听从管理服务器调度,提供存储空间,并为客户提供数据传输。
(4)客户机挂载使用 client computers:通过 fuse内核接口挂接远程管理服务器上所管理的数据存储服务器,使共享的文件系统和本地unix文件系统的使用效果类似。
2.2 chunkserver负载均衡算法
在MFS系统中,当客户端向数据存储服务器上传文件时,这些被上传的文件被划分成64 MB大小的chunk块,然后再根据chunkserver选择算法被存储在数据存储服务器上。如果chunk块被均衡分配,则系统不会出现一些chunkserver运行繁忙,而一些chunkserver处于空闲状态的现象,提高了用户访问系统的速度。
MFS源代码中定义了matoceeerventry结构体,用来描述chunkserver的信息。在这个结构体中有一个carry变量,它是MFS中数据存储时分布算法的核心。MFS中每台chunkserver会有自己的carry值,在选择chunkserver时会将每台chunkserver按照carry值从大到小做快速排序,优先选择carry值大的chunkserver来使用。算法流程图如图1所示。其中,allcnt表示mfs中可用的chunkserver的个数,availcnt表示mfs中当前可以直接存储数据的chunkserver的个数,demand表示当前文件的副本数目。
MFS系统启动时,通过rndu32()函数为每一个chunkserver随机产生一个大于0且小于1的carry值。系统运行时,每台chunkserver的carry值的变化满足以下规律[8]:
(1)仅当 carry值大于 1时,才可以向此 chunkserver中存储数据,并将此chunkserver的carry值减1。
(2)当 demand〉availcnt时,循环增加每台 chunkserver对应的carry变量的值,直到满足demand〈availcnt时为止。
(3)变量carry每次增加的增量为本台chunkserver的总空间与系统中总空间最大chunkserver的总空间的比值。
根据以上算法的分析可知,在MFS系统中,数据并不是均匀地分配到各台chunkserver上的,而是chunkserver总空间大的,分配到的数据就多,即分配到chunkserver上的数据与此chunkserver的总空间大小成正比。如果chunkserver的总空间大小相同,则数据被均匀分配到chunkserver上,表1为随机生成500个、1 000个、1 500个、2 000个文件时,chunk块在各个chunkserver上的分布,测试结果显示,数据被均匀分配到各个chunkserver上。

表1 chunk块的分布情况测试
2.3 改进的chunkserver负载均衡算法
在MFS系统中,如果chunkserver的总空间大小差别很大,就会造成总空间大的chunkserver被多次选择,chunk块数多,而总空间小的chunkserver很少或几乎不被选择,chunk块数少,造成chunk块分布不均衡。在图1整个算法流程图中循环增加可直接存储数据的chunkserver的个数,即增加carry的值直至demand=availcnt是负载均衡算法的核心部分,而其中carry的增加量servtab[allcnt].w如何计算是算法的关键问题。增加可直接存储数据的chunkserver的流程图如图2所示,算法实现代码如下:


图2 chunkserver增加算法流程图
在原算法中carry的增加量servtab[allcnt].w=(double)eptr-〉totalspace/(double)maxtotalspace,就是把本台chunkserver的总空间与系统中总空间最大chunkserver的总空间的比值作为carry变量的增加量。而改进后carry的增加量 servtab[allcnt].w=((double)maxtotalspace-(double)eptr-〉usedspace)/(double)maxtotalspace, 就是把系统中总空间最大chunkserver的总空间减去本台chunkserver已用去的空间大小后与系统中总空间最大chunkserver的总空间的比值作为carry变量的增加量。
2.4 对改进负载均衡算法的测试
本测试的实验环境是在VMware里虚拟出5台虚拟机 ,1 台 master,3 台 chunkserver,1 台 client。 其 中 ,3 台chunkserver的硬盘大小分别为 5 GB,8 GB,11 GB,其他配置均相同。测试的主要目的是检测改进的算法是否能将数据均匀地存储到各台chunkserver上,此时系统的冗余备份设置为1。

利用测试脚本随机生成1 000个随机文件,然后上传到MFS系统中。算法改进前后chunk块的分布情况如表2和表3所示。
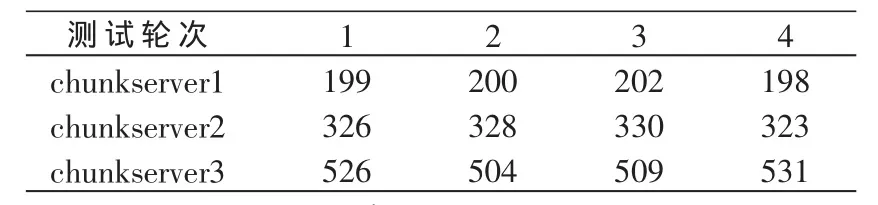
表2 算法改进前chunk的分布情况

表3 算法改进后chunk的分布情况
实验分别对改进前和改进后做了4次测试。从测试结果可以看出,算法改进前chunkserver硬盘容量越大,其上数据的分布就越多,这种情况容易导致各台chunkserver上的访问压力不一样,使系统性能不能达到最优。算法改进后,数据在chunkserver上基本是平均分配,各台chunkserver访问压力也基本一致,避免了总空间大的chunkerver总被不停地访问,而总空间小的chunkserver被闲置,使系统性能得到了优化。
本文对MooseFS分布式文件系统进行了分析,针对chunkserver选择算法存在负载不均衡的不足进行了改进,避免出现系统中总空间大的chunkserver上存储chunk块数多、访问量大,而总空间小的chunkserver上存储的chunk块数少或没有chunk块存数而处于闲置状态。通过实验测试,改进后达到了预期的效果,chunk块在各个chunkserver上分布均衡,系统性能得到优化。
[1]王德政,申山宏,周宁宁.云计算环境下的数据存储[J].计算机技术与发展,2011,21(4):81-82.
[2]GHEMAWAT S, GOBIOFF H, LEUNG S T.The Google file system[C].Proceedings of the 19th ACM Symposium on Operating Systems Principles.Lake George,New York:2003:29-43.
[3]APACHE HADOOP.Hadoop[EB/OL].[2009-03-06].(2012-03-19)http://hadoop.apache.org/.
[4]谭支鹏.对象存储系统副本管理研究[D].武汉:华中科技大学,2008.
[5]张聪萍,尹建伟.分布式文件系统的动态负载均衡算法[J].小型微型计算机系统,2011,32(7):1424-1426.
[6]百度文库.MFS文档[DB/OL].2010.http://wenku.baidu.com/view/320b56260722192e4536f61b.html.
[7]51CT0 博 客.MooseFS 介 绍[DB/OL].2011.http://haiquan517.blog.51cto.com/165507/526252.
[8]mfs (mooseFS) 深入分析 (chunkserver选择算法)[DB/OL].2011.http://www.oratea.net/? p=285#comment-481.
