流量管理中队列调度算法研究
2013-01-31乔俊超王爱国
乔俊超,王爱国
(1.武汉邮电科学研究院,湖北 武汉430074;2.烽火通信股份有限公司,湖北 武汉430074)
随着IPTV对网络带宽需求的快速增长,针对流量的管理需求也日益强烈。流量管理主要涉及网络带宽控制和分配、通信延迟的降低和拥塞控制的最小化。流量管理提出的目标是用于高效管理网络资源,并且为用户提供需要的带宽和服务等级[1]。在通信设备的内部,流量管理能够在流量发生拥塞时,对数据进行合理的处理,使得用户端能够得到一个很好的QoS体验。由于流量在设备内部发生拥塞时会导致端口数据吞吐量下降,增加端到端延迟,引起传输抖动和数据丢包等问题,因此如何合理地进行流量管理来减少拥塞至关重要。在设备内部的包交换芯片中流量管理部分可以分为以下几个主要方面:流量分类(Traffic Classification)、流量监控(Traffic Policing)、缓存管理(Buffer Management)、流量调度与整形(Traffic Scheduling & Shaping)、流量标记(Traffic Marking)[2]。本文将主要研究流量调度部分的队列调度算法。队列调度的功能是确定输出端口在下一个时刻,从哪个队列中输出数据包。高效和公平性是队列调度算法两个很重要的指标,如何高效和公平地调度是一个很复杂的问题,在进行队列调度时,由于需要平衡调度算法的复杂度、控制的简易程度和对不同服务等级流量的公平性,所以队列调度算法目前是研究的热点。
目前队列调度有多种算法,例如FIFO、PQ、FQ、WFQ、WRR(CBQ)、DRR、DWRR等。每种队列调度算法都有其优缺点和适用场景,如何在不同的场景下合理高效地运用调度算法值得研究。本文将针对目前运用较多的DWRR调度算法做研究,分析其优缺点,并在其不足的基础上提出改进方法。
1 DWRR调度算法
赤字加权轮询(Deficit Weighted Round Robin,DWRR)是基于Round Robin的算法,由M.Shreedhar和G.Varghese在1995年提出。DWRR是队列调度算法中的一个基本算法[3]。根据数据包业务类型的不同,汇聚到不同的服务队列,每个队列称为CLS(Class of Services),DWRR算法按照一定的轮询机制来输出每个服务队列的数据包,同时每个服务队列基于分配的权重值,享受不同级别的服务。
WRR是基于每个队列的帧数来计算的,而DWRR是基于每个队列的字节数来计算的,对数据流的控制更精准。DWRR算法主要有以下几个参数:
1)DC[i](Deficit Counter)变量。用以记录第i个队列可用的信用度,即每次轮询该队列时允许调度器访问的字节总数。
2)Quantum[i]参数。根据每个队列的权重值来配置。用于在每次轮询到第i个队列时,向DC里面补充一定的信用度,即DC[i]=DC[i]+Quantum[i]。
DWRR算法具体的执行步骤如下:
1)初始化时,根据每个队列的权重分配相应的Quantum值,并把每个队列的DC值设为初始值0。
2)开始轮询,查看当前队列是否为空,若为空队列,则跳过本队列,访问下一队列,并把DC[i]设为0;若为非空队列,则DC[i]=DC[i]+Quantum[i],若此时DC[i]大于等于队列头部数据包帧长,则DC[i]=DC[i]-Queue[i]_head_packetsize,发送该数据包之后,再对此队列进行判断,直到队列为空或者DC[i]小于队列头部数据包帧长,则访问下一队列,剩余的DC[i]累加到下次轮询。DC[i]不能小于0。
3)结束一轮轮询之后,重新从步骤2)开始,如此循环。
DWRR算法优点:解决了WFQ计算复杂度高和WRR无法应对数据包长度变化的问题,提供了一种更精确的带宽分配算法;但是也存在一些不足,例如若一个队列一直传送数据包直到DC[i]小于队列头部数据包帧长时,可能引入抖动,使得DWRR难以支持实时业务,同时DWRR算法里面不支持DC[i]为负数,使得当DC[i]小于当前队列数据包帧长时,可能需要经过若干次轮询积累足够信用度之后,才能传送队列里的数据包,可能会使队列出现“带宽饥饿”现象[4]。因此有必要针对算法中的不足进行改进,使得算法既能够保证低加权值的延迟性能,同时又能保证对各个队列带宽分配的相对公平性,尽量避免出现“带宽饥饿”。
2 改进的DWRR算法
通过认真分析DWRR算法存在的不足,本文提出了一种改进型DWRR算法——IDWRR(Improved DWRR),能够在一定程度上解决DWRR算法的缺点。
为全面提升养殖场的经济效益,部分养殖户会独自饲养生猪,自己屠宰并销售,通常为家庭分工协作饲养、共同负责产销,这种自产自销模式在一定程度上有利于稳定生猪市场,但受到经济利益的限制,部分养殖户在生猪养殖中,存在供不应求的现象。为解决这一问题,养殖户从外地引入肉质,屠宰并兼顾销售,使疫情因素转变,一旦消毒不彻底,将会导致外来疫病的传入,不利于生猪自产自销事业的发展。另外,不能定期消毒、接种疫苗,也增加了各类疾病发生的几率,且呈大面积扩散趋势,不利于生猪养殖事业的发展。
IDWRR算法有以下3个状态变量:
1)Weight[i],为 每个队列的权重值,正整数,可以取0,取0时该队列变为SP(Strict Priority)模式,这里不讨论。指定该队列相对于其他队列所占的带宽比例,需要配置。
2)弹性因子K,为正整数,用于计算队列的信用额度补给。当每轮轮询结束后,所有的DC[i]计数器值为负数时,K的值会被重新计算。每个队列的Quantum[i]=Weight[i]×2K,K的值是下一轮轮询时,能使所有DC[i]经过补给后大于0的最小值。
3)DC[i]变量,用以追踪第i个队列相对于其指定的权重值所占带宽的情况。DC[i]允许小于0。
相比于之前的DWRR算法,IDWRR算法改进之处主要在于:1)弹性因子K来决定每个队列每次获得补充的信用度;2)DC[i]小于0。K值重新计算的条件:当每轮轮询结束后每个队列的DC[i]都小于0。
改进后DWRR的算法执行步骤如下:
2)轮询开始,若当前队列为空,则保持当前的DC[i]值不变,轮询下一队列。若当前队列非空,则对DC[i]进行信用度补给,即DC[i]=DC[i]+Quantum[i],补给之后,若DC[i]大于当前队列头部数据包帧长时,则发送该数据包,DC[i]=DC[i]-Queue[i]_head_packetsize;发送之后再次进行判断,若DC[i]≥0且DC[i]的值小于 当 前 队 列 头 部 数 据 包 帧 长 时,则DC[i]=DC[i]-Queue[i]_head_packetsize,之后DC[i]变为负数,结束当前队列,轮询下一队列。
3)结束一轮轮询后,若所有队列DC[i]都为负数,则重新计算K值,Quantum[i]也随之改变,接着从第二步开始;否则直接从第二步开始,如此循环。
当所有DC[i]为负时,表明网络突入大量数据包,可能出现拥塞情况,原有的K值可能不能有效缓解网络拥塞,所以K值需要重新计算;当只有部分DC[i]为负值时,这时K值不进行更新,因为只要相应数据流的队列不为空,DC[i]在每轮轮询时都会获得补充,这时和DWRR的功能相同。利用弹性因子K的好处在于可以实时统计网络中的实际数据包帧长,相比于之前的DWRR算法能够减少延时、减少传输抖动;允许DC[i]为负数则使得相应数据流在信用额度不足时,能够先发送一个数据包,然后再在下一轮补充,这样在一定程度上增加了公平性。
IDWRR算法的流程图如图1所示。
3 仿真结果
3.1 仿真网络的拓扑结构和主要参数
本文中采用网络仿真器NS-2来仿真IDWRR算法的性能[5],并且与未改进的DWRR算法进行比较。仿真网络的拓扑结构如图2所示。
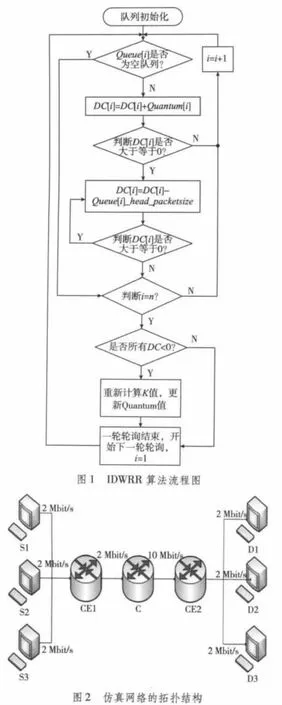
图2中S1,S2和S3分别用户发送端,D1,D2和D3分别为对应的用户接收端,CE1和CE2分别为网络用户边缘路由器,C为网络的核心路由器,CE1与C是瓶颈链路,带宽为2 Mbit/s,核心链路带宽为10 Mbit/s。主要验证在发送相同数据包的情况下,DWRR和IDWRR在延迟和公平性方面的性能比较。S1,S2和S3分别发送BE,AF和EF数据流,使其进入不同的队列[6]。S1,S2和S3到CE1的链路延时固定为10 ms,BE,AF和EF数据流在NS-2中的配置如表1所示。
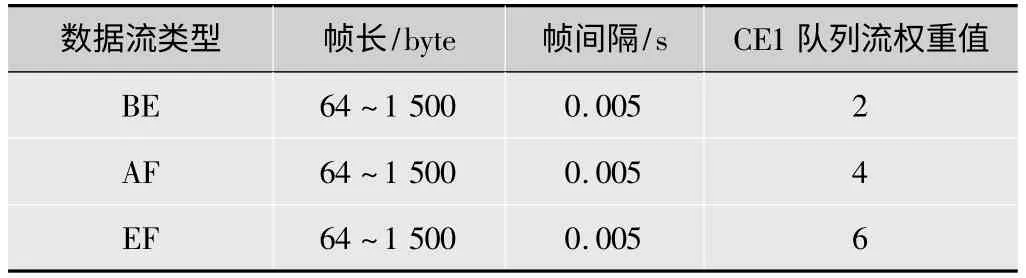
表1 NS-2中数据流配置
3.2 仿真结果分析
由于篇幅的限制,在CE1的输出端口侧只针对BE和EF两个数据流在延时和公平性方面做对比。图3和图4的仿真结果分别为BE、EF数据流在两种算法下延时的比较;图5的仿真结果是在两种算法下,BE和EF数据流分别配置相同权重值、公平性的比较。
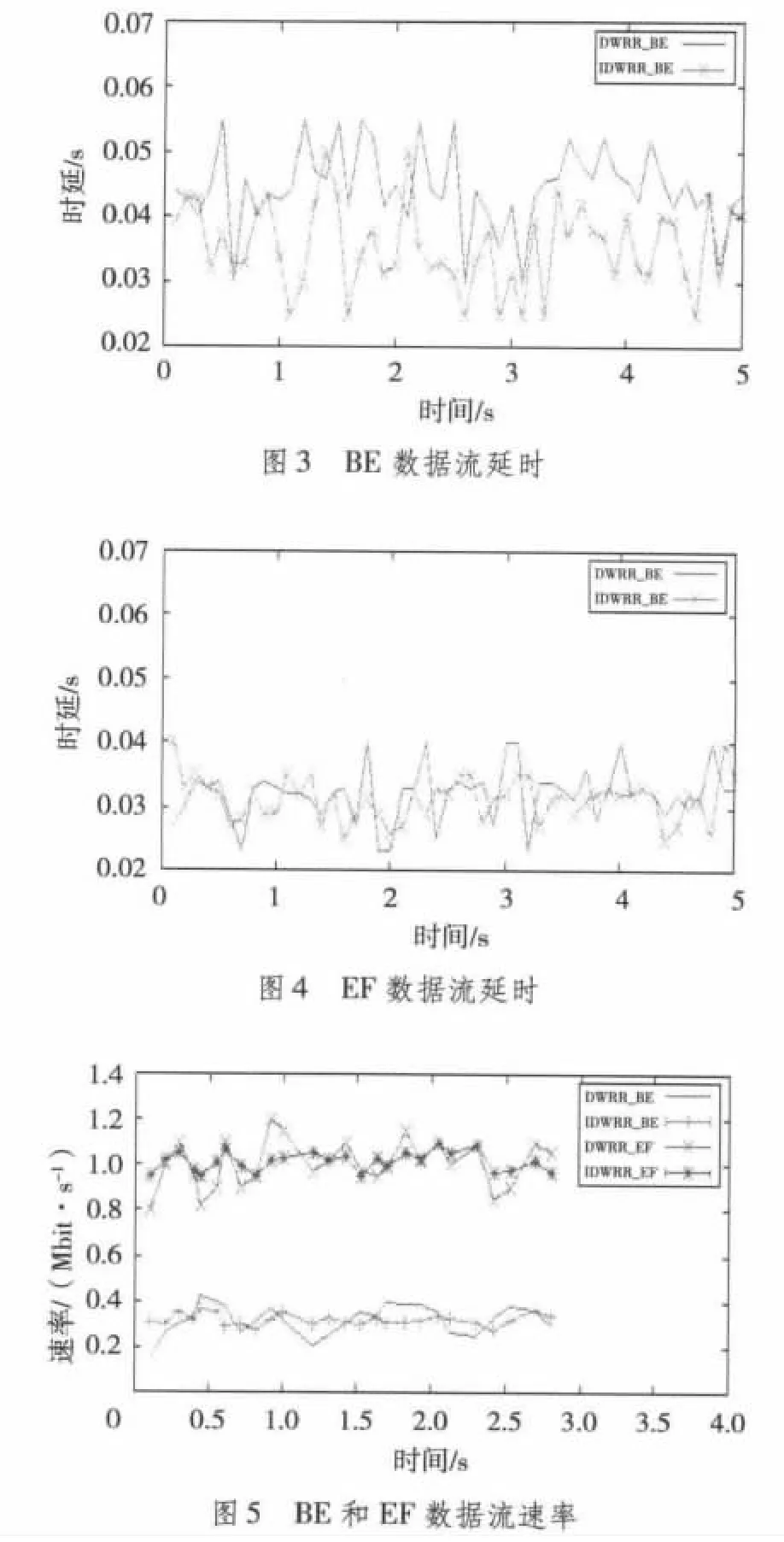
在数据流的配置中,虽然数据流的帧长是变化的,但是两种算法采用帧长随机的随机种子是一样的,所以在同一时刻,两种算法对应的数据流帧长是相同的,这样能更方便地对比两种算法的性能。
从图3和图4的NS-2仿真结果可以看出,IDWRR相比DWRR减少了数据流传输的延时,对于BE数据流的延时,采用DWRR调度算法平均延时45 ms,而采用IDWRR调度算法平均延时32 ms,改进后的算法延时降低约29%;对于EF数据流的延时,采用DWRR调度算法平均延时33 ms,而采用IDWRR调度算法平均延时29 ms,改进后的算法延时降低约12%。通过对BE和EF数据流延时的比较,可以看出IDWRR在延时性上有很大提高。
图5在公平性方面对两种算法做出了比较,根据之前的权重配置,从总体上BE数据流的带宽为0.33 Mbit/s,EF数据流的带宽为1 Mbit/s。在比较公平性时,本实验比较数据输出速率的波动性。从图5中可以看出对于BE数据流,两种算法的总体平均速率都是0.33 Mbit/s,但是IDWRR数据流的输出速率比DWRR要平缓,速率波动比较小;对于EF数据流,两种算法的总体平均速率虽然都是1 Mbit/s,然而DWRR的数据流输出比IDWRR速率波动要大。经过仿真分析可以得出改进的IDWRR算法在公平性上比DWRR有提高。
通过对BE和EF数据流在延时和公平性上的仿真分析可以得出,IDWRR算法相比于DWRR算法性能上有很大的提高,符合算法改进的预期效果。
4 结束语
本文主要研究DWRR算法,分析其不足之处,并在其基础上提出了一种改进算法,改进算法能够根据弹性因子K来计算当前网络中的最大数据包帧长,以此来调节每个队列的信用额度补给Quantum,能够在一定程度上降低传输延迟,提高队列接入的公平性,从而提高了网络的服务质量。虽然对传输延时有一定的改进,但是队列调度只依靠这一种算法还不能保证QoS,所以应该和其他算法一起协同工作,来满足用户对不同业务QoS的要求。
[1]杜晓萍.时隙可变长分组缓存调度算法[J].电视技术,2012,36(21):37-41.
[2]XIAO Xipeng.Technical,commercial and regulatory challenges of QoS[M].American:Morgan Kaufmann Publishers,2008.
[3]Juniper Network.Supporting differentiated service classes:queue scheduling disciplines[EB/OL].[2012-06-06].http://folk.ntnu.no/einersen/arkiv/4.klasse/01h/TTM4150-Nettverksarkitektur/Readings/Congestion%20control%20-%20Queue%20scheduling%20disciplines.pdf.
[4]闵捷,周红琼,王晓东.一种基于优先级的加权公平队列调度算法[J].宁波大学学报:理工版,2012,4(2):42-46.
[5]肖权权,段迅.基于NS2的网络仿真与性能测试[J].计算机技术与发展,2012,4(22):25-28.
[6]潘迟龙,张基宏.基于WRR的改进型队列调度算法[J].电信快报,2012(1):34-37.
