基于页面写相关的闪存转换层策略
2013-01-07陈金忠姚念民蔡绍滨战福瑞孙美玲
陈金忠,姚念民,蔡绍滨,战福瑞,孙美玲
(哈尔滨工程大学 计算机科学与技术学院,黑龙江 哈尔滨 150001)
1 引言
过去几十年,机械硬盘的机械特性带来了随机读写的低性能和高功耗[1~3]。近年来,闪存的体积小、低功耗和抗震性等特点,使得闪存技术被广泛应用于MP3、PDA和移动电话[4]。随着固态硬盘价格逐年降低,不久的将来,固态硬盘将成为企业级存储系统的重要组成部分[5]。与机械硬盘不同,固态硬盘是基于半导体芯片,主要包括2种类型的闪存芯片、NOR和NAND[6]。NOR类似于内存,容量小,它允许通过地址访问任何的一个闪存单元,数据的写入和擦除速度慢。NAND容量大,数据的写入和擦除的速度较快,但需要经过I/O地址转换才能访问。因此,NAND更适用于固态硬盘。大多数的硬盘厂商都支持和传统硬盘相同的接口,例如SATA和SCSI接口。虽然固态硬盘的读写速度比传统的机械硬盘快,但无论是基于NOR或NAND类型的固态硬盘都不支持“就地更新”,在更新某一块上的数据页之前,必须先把整个数据块擦除,称为“写前擦除”。相对读写操作,块擦除的代价非常高。为了避免这种昂贵的擦除开销,固态硬盘引入闪存转换层(FTL)。FTL通过预留一些空闲的日志块,把需要更新的数据写入空闲日志块,从而避免了“写前擦除”。
经典的FTL策略有2种,分别是基于块相联的BAST[7]策略和基于全相联日志缓存的 FAST[8]策略。BAST为每个数据块指定唯一的日志块,更新的数据只能写入对应的日志块。BAST适合顺序存取。对于随机存取,BAST会造成存储空间的浪费。FAST采用全相联的映像方式,更新的数据可以写入到任何的日志块,不会造成存储空间的浪费。FAST还将日志块划分为顺序缓存日志块与随机缓存日志块,分别用于优化顺序存取与随机存取。然而,在 FAST策略中,一个日志块可能关联多个数据块,增加了垃圾回收的成本。为了克服BAST、FAST等策略的缺点,本文提出了一种基于页面“写相关”的FTL策略PWRST。PWRST统计 I/O请求的历史信息,将“写相关”的页面存储在同一数据块。PWRST减少了页面复制开销与块的擦除成本,降低了垃圾回收的成本,提高了固态硬盘的性能。
2 相关工作
2.1 NAND内部结构
NAND闪存芯片由若干个逻辑单元组成,每个逻辑单元包括多个存储平面,每个存储平面由多个存储块构成。假设每个闪存芯片由2个逻辑单元组成,每个逻辑单元由2个存储平面构成,每个存储平面由4个存储块构成。如图1所示,按照存储块在每个存储平面上的分布方式,将固态硬盘分为 3种不同的架构,分别是无条带化架构、部分条带化架构和全条带化架构。图1(a)显示无条带化架构的NAND闪存,将存储块按顺序存放在每个存储平面上,这种结构不支持并行读写。图1(b)显示了部分条带化架构的NAND闪存。这种结构的特点是将存储块分散存放在成对存储平面上,同一个逻辑单元内部的2个存储平面可以并行读写。全条带化架构的NAND闪存如图1(c)所示。存储块分散存放在每一个存储平面上,2个逻辑单元可以并行读写。
2.2 NAND闪存转换层
由于 NAND闪存在更新存储页时必须擦除整个存储块,这大大地降低了 NAND的性能。FTL通过预留一些日志块,将更新的数据写入空闲日志块,从而避免擦除整个数据块。闪存转换层主要功能如下。
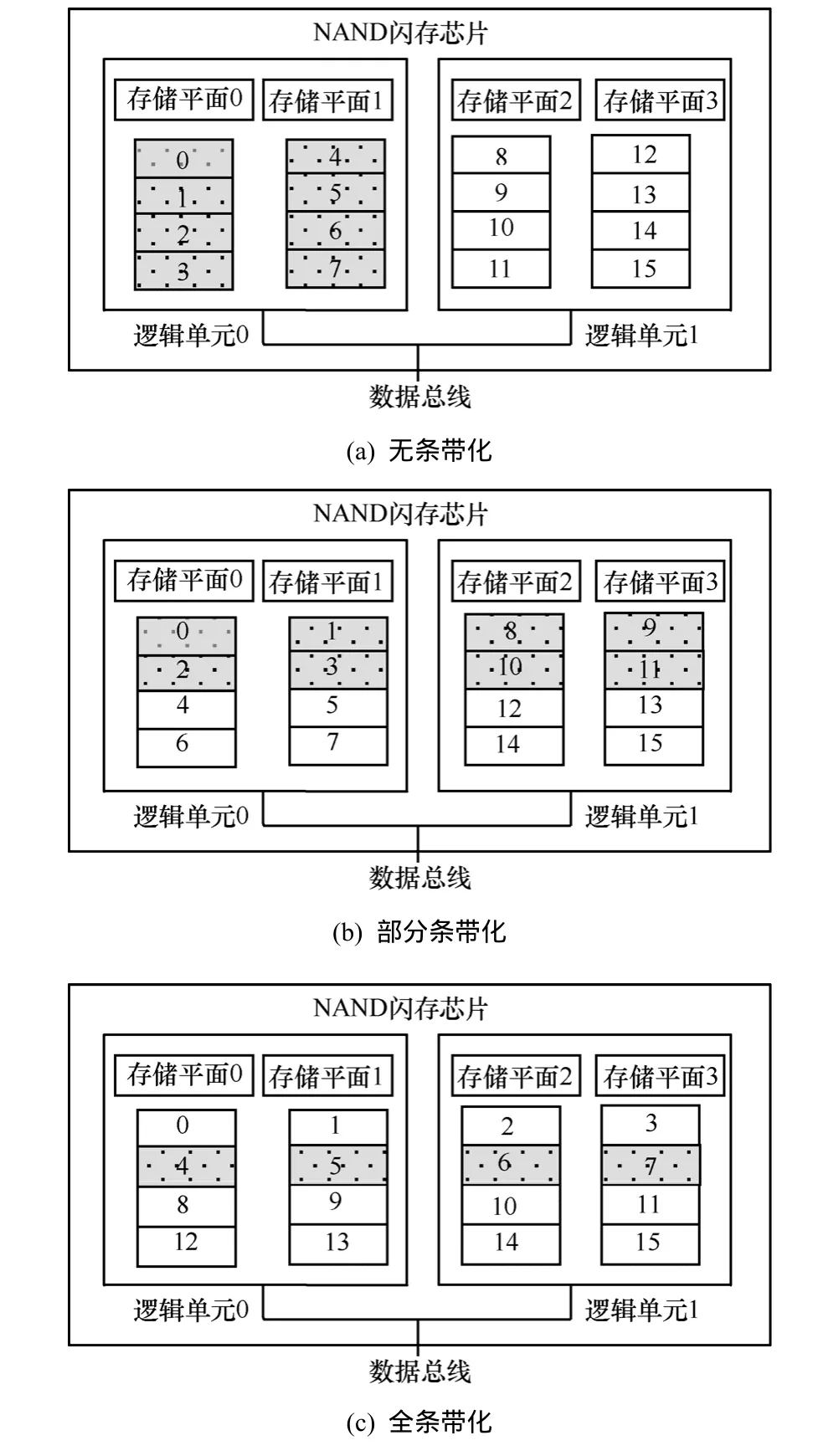
图1 SSD的3种不同的内部架构
1) 映射机制(mapping mechanism):按照映射的粒度,分为页面级别映射与块级别映射。页面级别映射的优点是容易实现且高效,缺点是需要大量的空间存储页面映射表。块级别映射节省了存储映射表的空间,但在垃圾回收时需要大量的页面复制操作,增加了垃圾回收的开销。许多FTL策略采用混合映射机制,大量的数据块采用块级别映射,少量的日志块采用页面级别映射[9,10]。这种混合映射机制提高了固态硬盘的性能。
2) 垃圾回收(garbage collection):当固态硬盘的空闲块数量少于某个下限值时(通常小于总块数的15%),垃圾回收算法扫描整个固态硬盘以回收存储块。文献[11,12]通过减少垃圾回收过程中擦除块数来延长固态硬盘的使用寿命。
3) 损耗均衡(wear-leveling):由于程序的局部性原理,固态硬盘的某些存储块会被频繁的更新和擦除,导致这些块的损耗加快。闪层转换层通常采用“冷块”与“热块”的交换的方法来达到所有存储块损耗均衡的目的。文献[13]提出了FeGC机制,优先回收失效页数量多和失效时间长的数据块,达到了减少垃圾回收开销和损耗均衡的目的。针对闪存阵列,文献[14]提出了FAP策略,通过交换擦除次数多和擦除次数少的块,达到NAND闪存芯片之间的损耗均衡的目标。
2.3 块相联(BAST)策略
BAST的基本思想是每一个数据块关联唯一的日志块,更新时,页面写入相应的日志块。如果日志块没有空闲的页面,即使其他的日志块有空闲页面,也不能写入。假设LPN表示I/O请求的逻辑页号,data表示写入的数据,每个块的大小为S。写操作定义为 write(LPN, data)。在写操作之前,需要将逻辑页号转换成逻辑块号(LBN),计算公式为LBN=LPNmodS。然后,根据LBN查找逻辑块的物理块号(PBN),最后,将数据data写入数据块PBN。假设每个存储块包括4个页面,日志块数为2。I/O请求的逻辑页面向量为V={0,1,2,3,4,5,6,7,2,3,2,3,7,1,1,2}。逻辑块0对应数据块0,为数据块0分配日志块0。逻辑块1对应数据块1,为数据块1分配日志块1。BAST的操作流程如图2所示。由于页 0、1、2、3的逻辑块号为 0,写入对应的数据块0。页4、5、6、7的逻辑块号为1,写入对应的数据块1。当更新逻辑页2、3、2、3时,写入对应的日志块 0。当更新逻辑页 7、1、1、2,逻辑页7写入到日志块1。此时数据块0对应的日志块已经写满,逻辑页1、1、2不能写入日志块 0,需要执行擦除操作。从图 2可以看出,日志块1还有空闲的页面,但不能将数据块0的页面写入日志块 1。BAST造成了日志块空间的浪费,其主要原因是在BAST策略中,一个数据块只关联唯一的日志块,更新的页面只能写入对应的日志块。
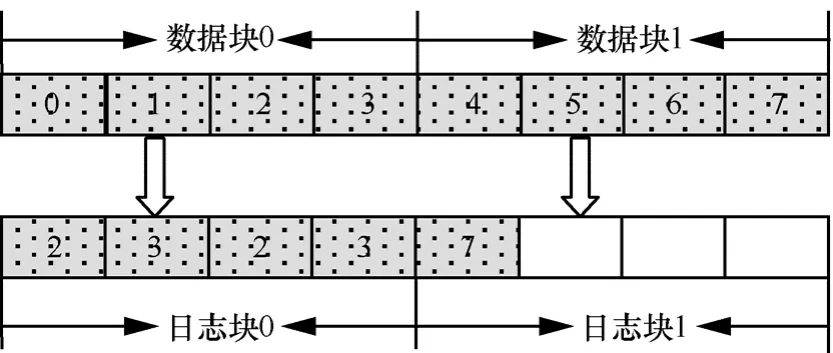
图2 BAST策略写操作流程
2.4 全相联(FAST)策略
FAST策略的基本思想是数据块可以共享日志块。更新的数据可以写入任何日志块的空闲页面。FAST策略的操作流程如图3所示。FAST策略更新逻辑页1、1、2时,由于日志块1还有空闲页,把逻辑页1、1、2写入日志块1。FAST策略充分利用存储空间,减少不必要的擦除开销和提高日志块的空间利用率。如图3所示,日志块1的逻辑页7对应数据块 1,逻辑页 1、1、2对应数据块 0。如果回收日志1,需要将日志块1与数据块0,数据块1合并,进行多次页面复制和块擦除。这是FAST的主要缺点。其原因是在FAST策略中,一个日志块关联了多个数据块。因此,FAST策略虽然克服了BAST策略的缺点,但也带来了昂贵的页面复制与块擦除开销,从而降低了固态硬盘的性能和缩短了固态硬盘的使用寿命。在2.5节将具体分析3种垃圾回收的开销。

图3 FAST策略写操作流程
2.5 垃圾回收开销的分析
垃圾回收分为3种形式,全合并(full-merge)回收、部分合并(partial-merge)回收和交换合并(switch-merge)回收。如图4(a)所示,全合并回收需要复制大量的有效页(valid)和多次块擦除(erase)。如图 4(b)所示,部分合并回收需要复制少量的有效页和2次块擦除。如图 4(c)所示,交换合并回收不需要复制页面,仅需2次块擦除。因此,应该尽可能地增加部分合并回收与交换回收的次数,减少全合并回收的次数。假设Cc表示复制一页的开销,Ce表示擦除数据块的开销,N表示数据块包含页的数量,Nv表示数据块包含有效页的数量,Na表示日志块所关联的数据块的数量,Wf、Wp和Ws分别表示全合并回收,部分合并回收和交换合并回收的开销,则有
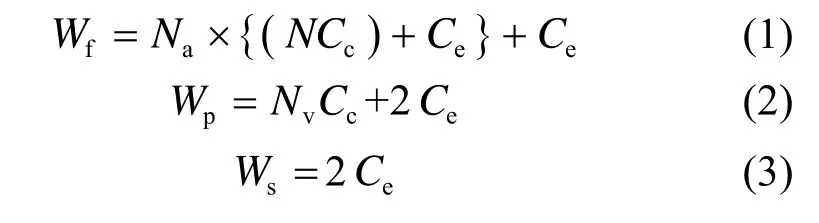
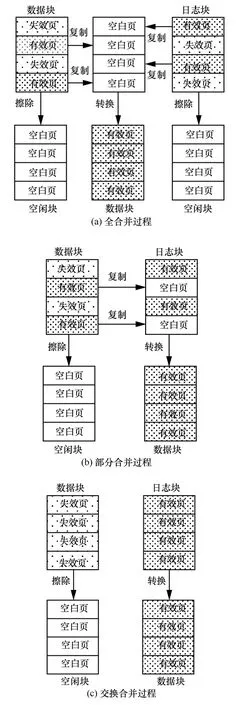
图4 3种全合并回收过程
由式(1)~式(3)可知,在全合并回收时,日志块所关联的数据块数量Na>1,在部分合并和交换合并时,日志块关联的数据块数量Na=1。因此,减少垃圾回收开销的关键是减小Na。由2.4节可知,FAST的一个日志块可能关联多个数据块,即Na> 1 。在垃圾回收时,需要复制大量的页面和多次擦除块,使得固态硬盘性能的下降。
3 PWRST策略
针对BAST和FAST的缺点,PWRST根据I/O请求的历史特性,将“写相关”的页面存储到同一数据块。所谓“写相关”是指I/O请求访问页面A之后,在最近一段时间内将会访问页面B,称页面A与页面B是“写相关”。例如,文件系统在更新文件时,对应的元数据也会被更新,这2次操作的页面是“写相关”。如果数据块的页面都是“写相关”,这些页面可能都是失效的,在垃圾回收时,只需要进行交换合并回收。
3.1 系统架构
SSD的系统架构如图5所示。PWRST分为3个模块,分别是 I/O请求历史收集模块(RHC)、页面写相关分析模块(WRA)和页面聚类模块(PC)。首先,I/O请求历史收集模块负责记录负载最近一段时间内访问的逻辑页号。其次,页面写相关分析模块根据I/O请求历史找出“写相关”的页面。最后,页面聚类模块将具有“写相关”的页面存储到同一数据块。
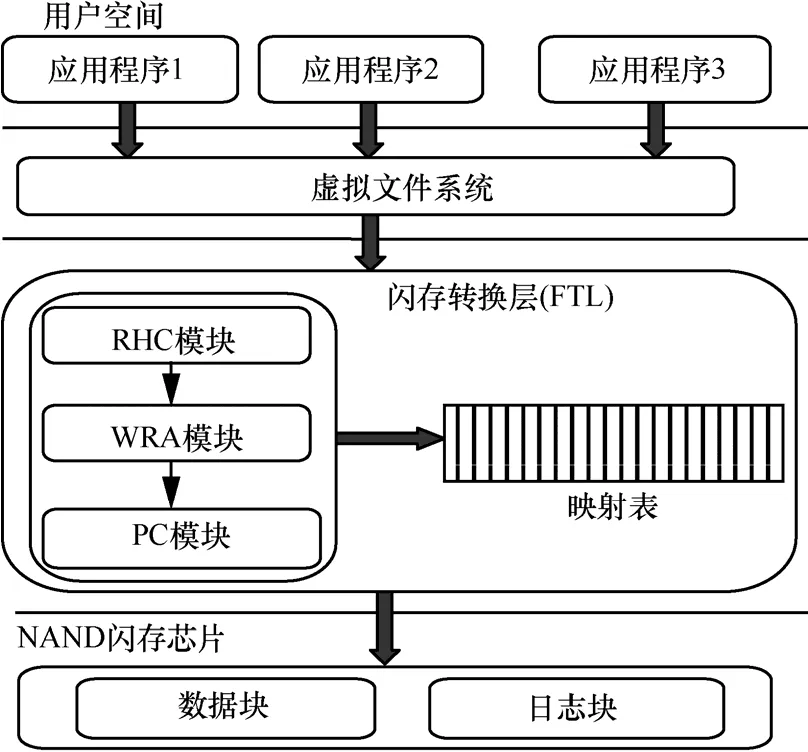
图5 SSD的系统架构
3.2 I/O请求历史收集模块(RHC)
首先,文件系统发出的 I/O请求将逻辑扇区(LBA)号映射为逻辑页号(LPN),FTL根据逻辑页号得到逻辑块号(LBN)和块内偏移(offset),然后通过查询块映射表得到物理块号(PBN)。RHC模块使用散列表对I/O请求的时刻T和访问的逻辑页号进行记录。其中,T和LPN分别表示了I/O请求的时间和空间特性。散列表可以实现对I/O请求的快速查找,更新以及删除操作,其维护非常方便。因此,散列表可以有效地维护I/O请求的历史信息。
3.3 页面写相关分析模块(WRA)



图6 I/O请求访问的页面序列
3.4 页面聚类模块
从3.3节可知,“写相关”的页面具有访问时间的关联性,如果将这些页面存储到SSD的同一数据块,那么在垃圾回收时,数据块包含的页面可能都是失效的页面,只需要一次擦除操作。从而避免了昂贵的页面复制开销,提高了垃圾回收的效率。页面聚类的模块功能是将“写相关”的页面存储到同一个数据块,其基本原理是利用了数据挖掘中的层次聚类的方法。即初始时将每个页面划分为一个单独的组,在接下来的迭代中,把那些“写相关”的页面合并成一个组,直到这个组的大小等于数据块的大小,然后将这些页面写入空闲块。图7给出了具体的操作流程。首先,从I/O请求的历史集合RHC找出访问频率最高的页面pi,放入组iA。然后,根据页面写相关分析模块,找出与页面pi“写相关”的页面pj,并将页面pj放入iA,组中的页面数ci加1。如果iA中页面的数量等于块的大小,聚类完成。否则,继续聚类。对于某些系统公共页面来说,可能有许多与其写相关系数较大的页面。这些公共页面可以使用页面映射的方式,那么在垃圾回收时,就不会引起全合并操作。
4 性能分析
实验分别测试了 BAST、FAST和 PWRST在Postmark[15]、IOzone[16]和 TPC-C[17]负载下的垃圾回收开销和I/O请求的响应时间。
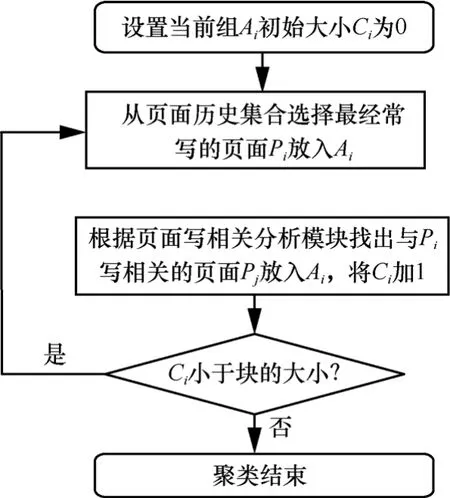
图7 页面聚类算法
4.1 测试环境
本实验所使用的模拟器是建立DiskSim之上的SSD模拟器[18]。该模拟器提供了对垃圾回收机制与交叉读写机制的模拟。表1给出了SSD模拟器的配置参数,包括SSD基本组成部分、页面的读写时延、擦除块的时延、擦除模式等。

表1 SSD模拟器配置参数
4.2 测试负载和参数设置
测试的负载包括 Postmark、IOzone和TPC-C。其中,Postmark和IOzone是I/O密集型的文件系统测试集,包括大量的随机读写操作。IOzone负载是对大文件的测试。Postmark负载则是频繁、大量地存取小文件。TPC-C负载是数据库测试集。模拟实验中的2个重要的参数:THs和θth。其中,THs表示系统空闲块数占总存储块的比例。θth表示“写相关”的门限值,分别设置为0.5、0.7和0.9,对应的PWRST策略表示为 PWRST(0.5)、PWRST(0.7)和 PWRST(0.9)。
4.3 垃圾回收开销
SSD垃圾回收主要包括两方面:页面迁移数和擦除块数;其中页面迁移数是指在全合并回收和部分合并回收过程中复制的页面数量。而擦除块数是指在全合并、部分合并和交换合并回收过程擦除的块数总和。SSD模拟器分别对 Postmark、IOzone和TPC-C 3种负载,生成106个读写请求进行测试。
4.3.1 页面迁移数
表2~表4分别给出了THs的值为0.15、0.10和0.05时,3种算法垃圾回收时的页面迁移数。PWRST(0.7)在Postmark和IOzone负载下的页面迁移数比BAST减少了30%,比FAST减少了20%。在TPC-C负载下,PWRST(0.7)页面迁移数比BAST减少15%,比FAST减少了12%。主要原因是BAST数据块对应唯一的日志块,当关联的日志块没有空间时,即使其他的日志块有空闲页时,也会触发垃圾回收机制。FAST的日志块可能关联多个数据块,增加了全合并的次数,从而增加了页面迁移数。另外,3种策略的页面迁移数都随着THs值的减小而增加,这是由于随着空闲块数目的减少,执行垃圾回收的概率增大。另外,PWRST(0.7)的页面迁移数量少于 PWRST(0.5)和 PWRST(0.9)。PWRST(0.9)只将归一化概率大于0.9的页面写入同一数据块,因而会遗漏一些页面。而PWRST(0.5)可能将一些不相关的页面写入同一数据块,因此会增加页面迁移数。
4.3.2 块擦除次数
表5~表7给出了BAST、FAST和PWRST在3种负载下的块擦除次数。BAST、FAST和PWRST这3种策略块擦除次数随着THs的减小而增加。在Postmark和IOzone负载下,PWRST(0.7)的块擦除次数比BAST减少10%,比FAST减少8%。相比于BAST和FAST,PWRST利用页面“写相关”减少了全合并回收的次数和块的擦除次数。对于固态硬盘,擦除次数不仅与性能相关,而且影响固态硬盘的使用寿命。因此,PWRST策略能够有效地提高固态硬盘的性能和延长固态硬盘的使用寿命。
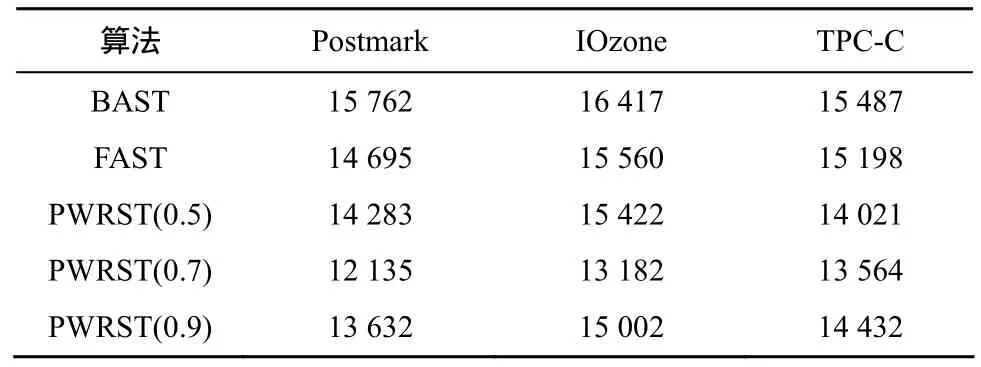
表2 当THs=0.15时,BAST、FAST和PWRST的页面迁移数
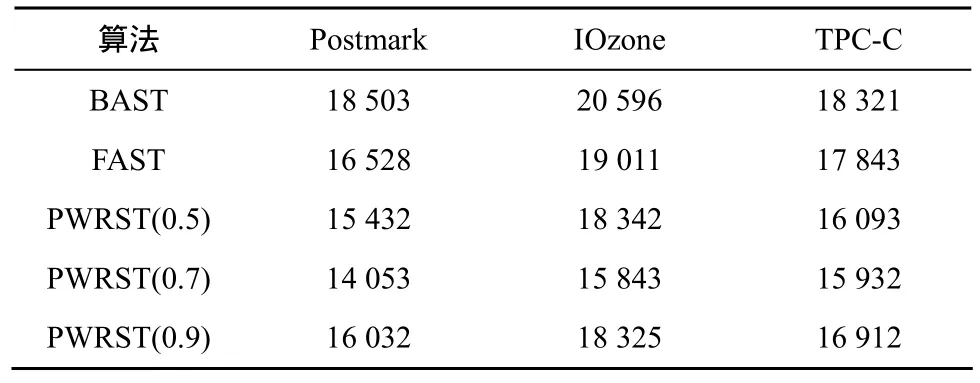
表3 当THs=0.10时,BAST、FAST和PWRST的页面迁移数

表4 当THs=0.05时,BAST、FAST和PWRST的页面迁移数
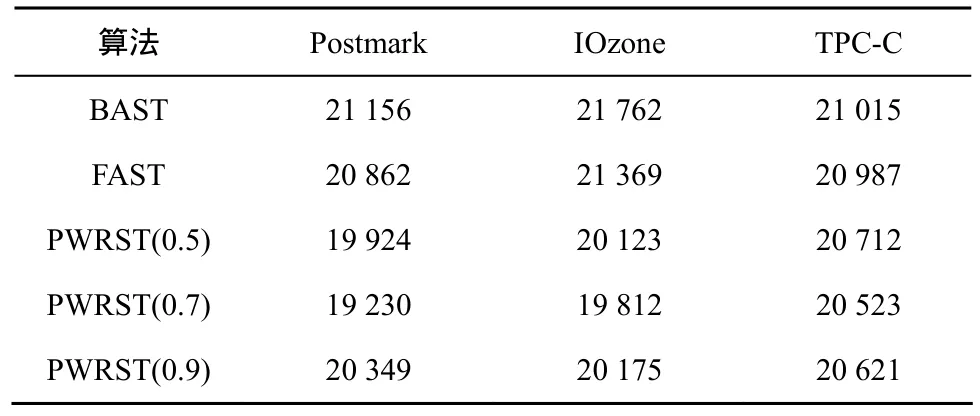
表5 THs=0.15时,3种策略的块擦除数
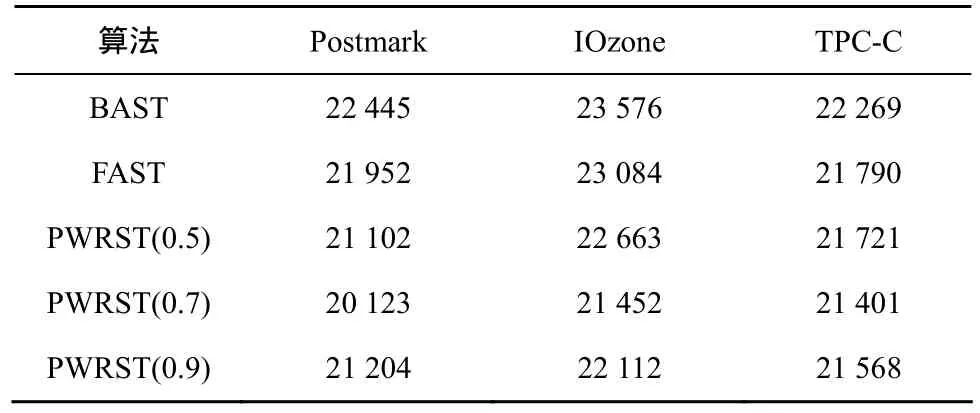
表6 THs=0.10时,3种策略的块擦除数
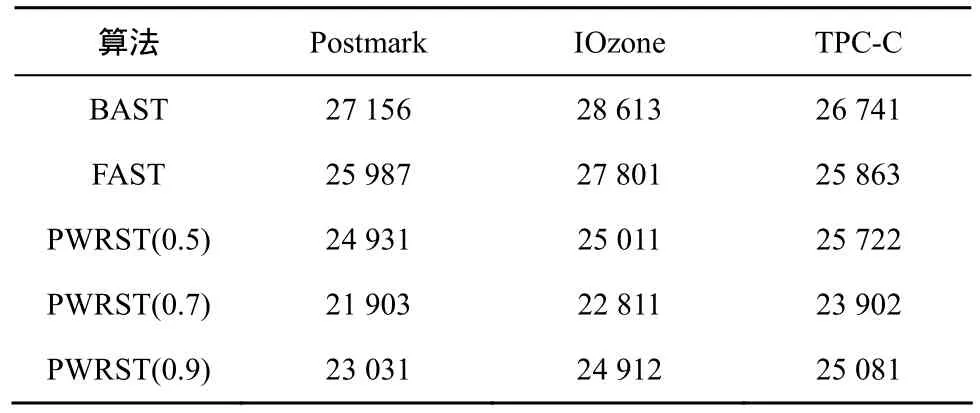
表7 THs=0.05时,3种策略块的擦除数
4.4 3种合并回收的开销
图8~图10给出了在THs= 0 .05时,全合并回收,部分合并回收与交换合并回收在3种负载下的开销。BAST在Postmark负载下的全合并次数占80%左右,FAST的全合并回收次数占50%左右,而PWRST全合并次数只占了10%左右。FAST充分利用了存储空间,避免了不必要的擦除开销。因此,FAST的全合并开销比BAST低。PWRST将“写相关”的页面写入同一数据块,减少了日志块关联的数据块数量,增加了部分合并回收与交换合并回收的比例。因此,PWRST垃圾回收的开销比BAST和FAST都小。
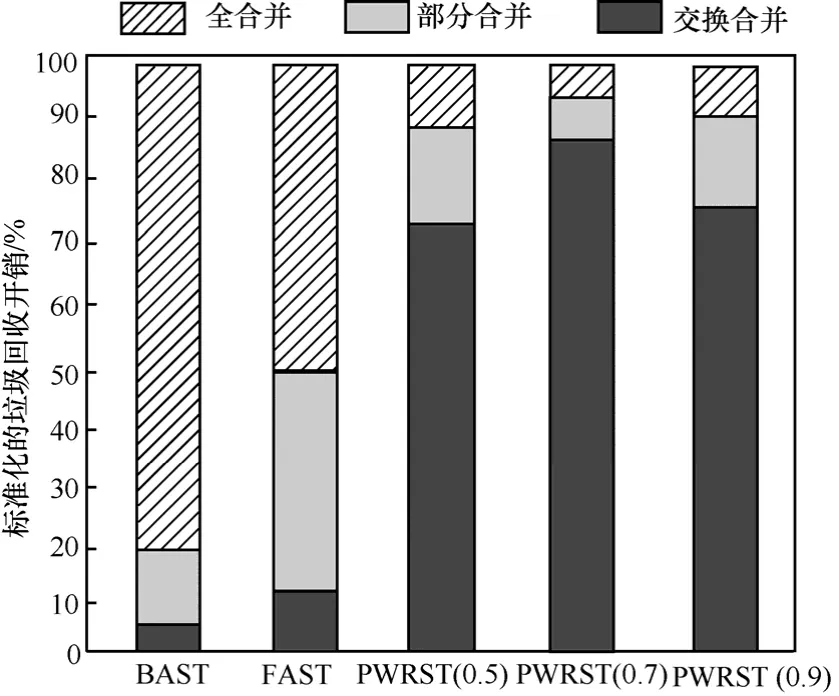
图8 在Postmark负载下合并开销的比例
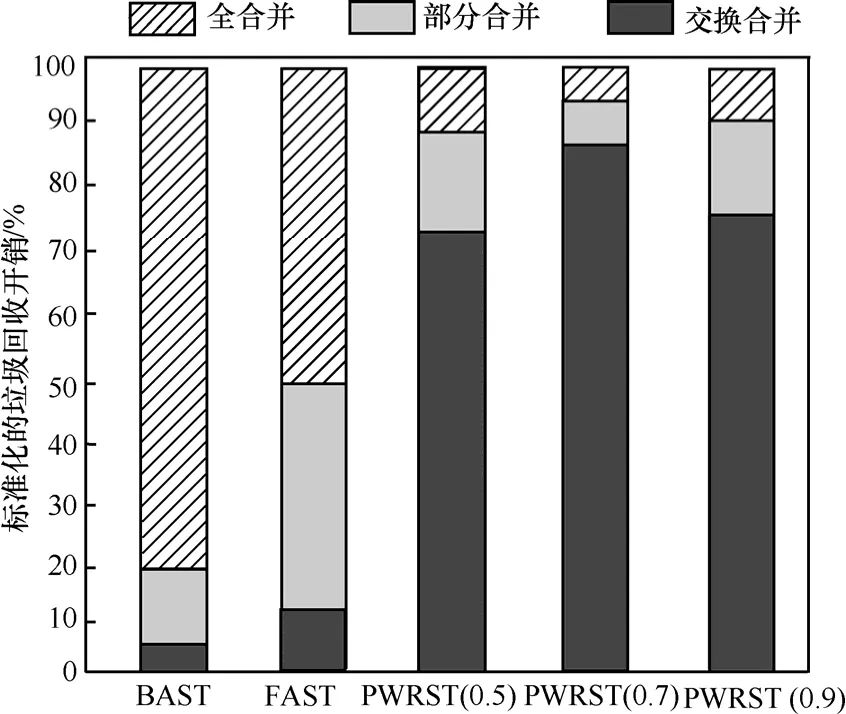
图9 在IOzone负载下合并开销的比例
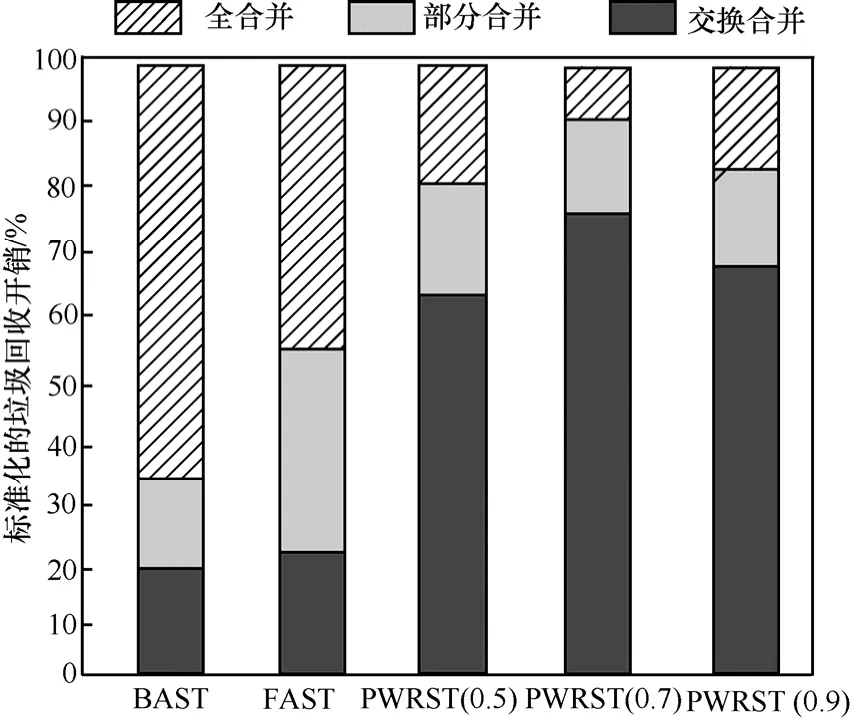
图10 在TPC-C负载下合并开销的比例
4.5 不同FTL策略的I/O平均响应时间
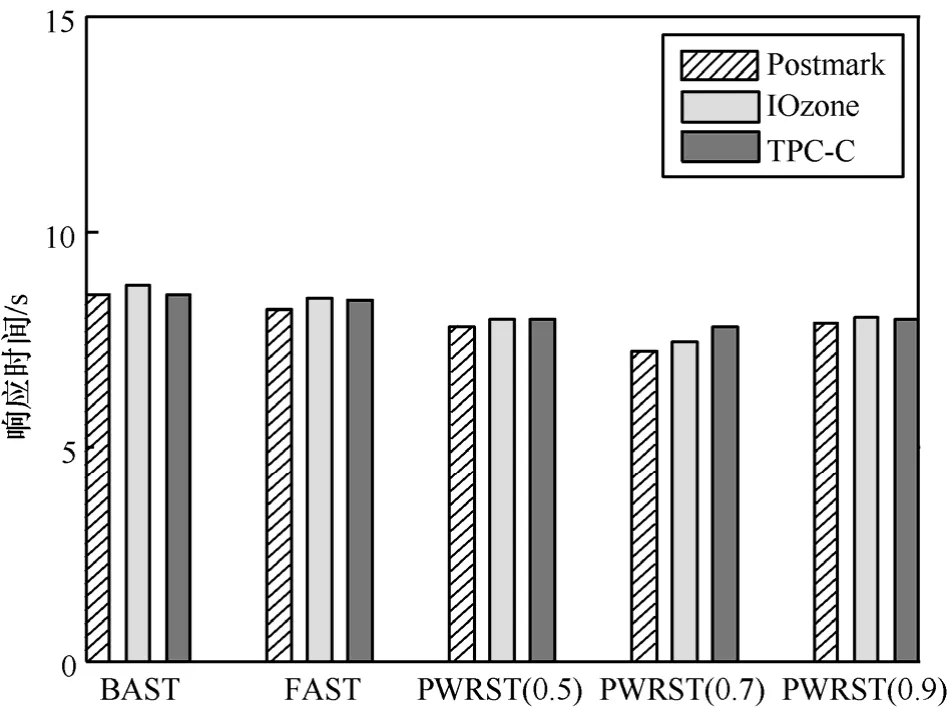
图11 当 T Hs = 0 .15时,BAST、FAST和PWRST的平均响应时间
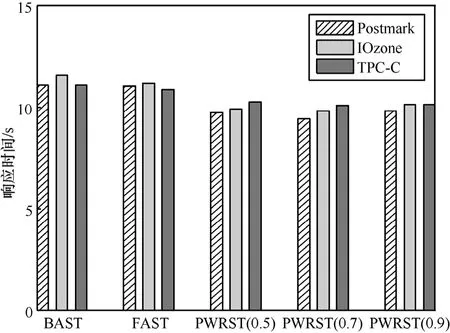
图12 当 T Hs = 0 .10时,BAST、FAST和PWRST的平均响应时间
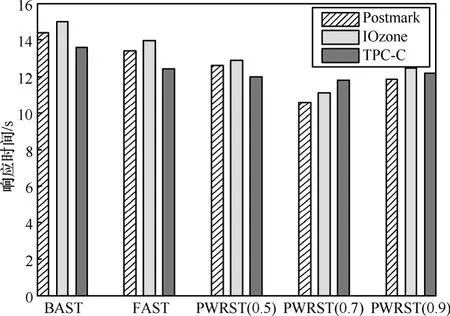
图13 当 T Hs = 0 .05时,BAST、FAST和PWRST的平均响应时间
图11~图13给出了3种FTL策略在Postmark、IOzone和TPC-C 3种负载下的平均响应时间。当THs= 0 .15时,PWRST(0.7)在Postmark下的平均响应时间比BAST减少了18%,比FAST减少了14%。PWRST(0.7)在TPC-C下的平均响应时间比BAST策略减少了10%,比FAST减少了8%。当THs=0.05时,PWRST(0.7)在 Postmark下的平均响应时间比BAST减少35%,比FAST减少26%。在TPC-C负载下,PWRST(0.7)的平均响应时间比BAST减少了12%,比FAST减少了10%。因此,本文提出的PWRST策略在响应时间等方面优越于BAST和FAST。
5 结束语
经典的闪存转换层策略(如BAST、FAST)都有其自身的缺点,BAST会造成存储空间的浪费和不必要的擦除开销。FAST策略中的日志块可能关联多个数据块,垃圾回收的开销非常大。本文提出了一种基于页面写相关的FTL策略PWRST。PWRST将“写相关”的页面存储到同一数据块,减少了全合并回收的次数。实验表明,PWRST减少了块的擦除次数,降低了垃圾回收的开销和I/O的平均响应时间。进一步验证了PWRST的可行性和优越性。
[1] CHUNG T S, PARK S W, LEE D H,et al.Systems software for flash memory: a survey[A].Proceedings of the 2006 IFIP International Conference on Embedded and Ubiquitous Computing[C].Korea, 2006.394-404.
[2] DING X N, JIANG S, CHEN F,et al.DULO: an effective buffer cache management scheme to exploit both temporal and spatial localities[J].ACM Trans Storage, 2007, 3(2):1242522.
[3] LI Z M, CHEN Z F, SUDARSHAN M S,et al.C-miner: mining block correlations in storage systems[A].Proc of FAST’02[C].San Francisco, USA, 2004.173-186.
[4] GAL E, TOLEDO S.Algorithms and data structures for flash memories[J].ACM Computing Surveys, 2005, 37(2):138-163.
[5] LEVENTHAL A.Flash storage memory communications[J].Communications of the ACM, 2008, 51(7):47-51.
[6] SANTARINI M.NAND versus NOR[J].EDN, 2005, 50(21):41-48.
[7] KIM J S, KIM J M, NOH S H,et al.A space-efficient flash translation layer for compactflash systems[J].IEEE transactions on Consumer Electronics, 2002, 48(2):366-375.
[8] LEE S W, PARK D J, CHUNG T S,et al.A log buffer based flash translation layer using fully associative sector translation[J].IEEE Transactions on Embedded Computing Systems, 2007, 6(3):18-45.
[9] KANG J U, JO H, KIM J S,et al.A superblock based flash translation layer for NAND flash memory[A].Proc of ICES’06[C].Seoul, Korea,2006.161-170.
[10] CHAO H, SHIN D , EOM Y I.Kast: k-associative sector translation for NAND flash memory in real-time systems[A].Design, Automation Test in Europe Conference Exhibition[C].Nice, France, 2009.507-512.
[11] CHEN F, LUO T, ZHANG X D.CAFTL: A content-aware flash translation layer enhancing the lifespan of flash memory based solid state drivers[A].Proceedings of FAST’2011[C].San Jose, CA, USA, 2011.77-90.
[12] WU G Y, HE X B.ΔFTL: improving SSD lifetime via exploiting content locality[A].7th ACM European Conference on Computer Systems, Euro-Sys’12[C].Bern, Switzerland, 2012.253-265.
[13] KWON O, KOH K, LEE J,et al.FEGC: an efficient garbage collection scheme for flash memory based storage systems[J].Journal of Systems and Software, 2011, 84(9):1507-1523.
[14] ANAM Z, SUMAYYA S, SABA Z,et al.A Flash aging prevention technique (FAP) for flash based solid state disks[A].International Conference on Computer Science & Education- ICCSE[C].Singapore,2011.531-536.
[15] KATCHER J.Postmark: A New File System Benchmark[R].Technical Report TR 3022, Network Appliance, 1997.
[16] NORCOTT W, CAPPS D.IOzone file system benchmark[EB/OL].http://www.iozone.org.
[17] Transaction processing performance council TPC-C benchmark[EB/OL].http://www.tpc.org/tpcc/spec/tpcc_current.pdf, 2004.
[18] KIM Y, TAURAS B, GUPTA A,et al.Flashsim: a simulator for NAND flash-based solid-state drives[A].1st International Conference on Advances in System Simulation, SIMUL 2009[C].Porto, Portugal,2009.125-131.
