“自己”的语用解释的约束条件系统
2012-12-04杨春雷
杨春雷
(上海外国语大学,上海,200083)
1.介绍
1.1 “自己”的语用解释
篇章中,听话者对指示语的所指有不同的认知状态。说话者对这种认知状态的假设被称为“可辨性”(identifiability)(Chen 2004)。如果说话者认为听话者能通过语境中涉及的其他事物辨认出所指的特定事物,这个所指是可辨的;反之,则不可辨。例如,“自己”在例1中不可辨,而在例2中可辨。
(1) 事实上很少有人会对自己所不知道的事大加议论……
(2) 我知道能让蒙田深感愉快的证词远远不止这些。这些证人的错误并不是信口开河,并不是不负责任地说一些自己不太了解的事物。
(余华《什么是一个作家的看法》)
我们认为,无论说话者认为所指的指代内容对听话者而言是特定的事物(particular entity)还是泛指一类事物,对说话者而言都是可辨的。只有无法辨认所指内容,或者有歧义的时候,才不可辨。是否可辨,其实就是分辨出确切的语用解释。“自己”的语用解释包括“特指”(specific)和“泛指”(generic)。如果“自己”是可辨的,即它指向一个语境中特定的事物,它的语用解释的值标记为“特指”;相反如果它指向一类事物而非任何个体,则标记为“泛指”。本文的主要目的是要发现不同层次上有哪些因素影响语篇中“自己”的语用解释。
1.2 约束条件系统
约束条件系统(expert system,简称ES)在自然语言处理、自动化、人工智能领域更多地译为“专家系统”。这种研究方法最早始于20世纪六十年代,指用户通过回答系统给出的提问,准确描述某个待解决问题的特征,然后系统参考专家经验给出结论。
约束条件系统是通过建立在数据库基础上的规则系统描写语言规律,理解语义并生成新的语句。它由作为经验基础的数据库和在此基础上的规则系统两个主要部分组成。数据库的作用像一个专家,可以在此基础上得出专家经验以解决问题。
约束条件系统的工作原理如图1所示,假设用一个较大的椭圆来表示一个未知的语言形式的解释,用一个较小的椭圆表示能决定该解释的约束条件,如果这个约束条件具有一定的普遍性,那么这个较小的椭圆的大部分或全部面积应该与大椭圆重合。当然,单单一个约束条件很难做出准确预测,但是随着有效约束条件的增加,已知范围也就越来越大。换言之,发现的有效约束条件越多,对解释的预测越为科学和精确。

图1 决定语用解释的多个约束条件
将约束条件系统应用到语言研究中的代表是Weiss和Kulikowski(1991)、Kuno等(1999,2001)。已有学者采用约束条件系统研究汉语语言现象,如杨春雷(2004,2011)建立了汉语量化词辖域的约束条件系统,证明能够有效预测量化句的语用解释。
2.关于约束条件的说明
根据前期研究和相关文献,我们暂时提出两类约束条件进行考察,一类是比较成熟的合格约束条件,另外一类是潜在约束条件。分别说明如下:
2.1 合格约束条件
1) “自己”和先行词的形式类别:在数据库中,标记了两类“自己”的形式类别,即“复合”(compound)“自己”(如我们自己,他自己等)和“光秆”(bare)“自己”。“自己”的先行词的形式类别包括专有名词、人称代词、有/无生命代词、复合反身代词、反身代词、指示词、其他和未知先行词。
2) “自己”和先行词的性别。
3) “自己”和先行词的句法位置:数据库中标记了5个主要句法位置,包括主语、宾语、旁语、属格形式和具有潜在影响的其他位置(如副词状语位置)。
4) 文体类别:文体也影响语篇中“自己”的语用解释。Bruner(1986:11-12)区分了两种思维方式,一种是“逻辑—科学式”(logico-scientific),另外一种是“叙述式”(narrative)。两种方式的特点不同,前者是“理论驱动的、分类的、概括的、脱离语境的”;后者是“以意义为中心的、试验性的、特殊性的、具体的和对语境敏感的”。人工智能领域中已经有通过计算机研究文体的自动识别。如Karlgren(2004)进行了一项基于数据的分析实验,通过对人称代词、指示词、言谈动词(verbs of utterance)、“私”动词(“private” verbs)和每个单词的词长等特征的考察,研究不同文本文体的自动识别,如广告、特写、悼词、评论和书籍等。本研究的数据库暂只包括议论和叙述文体。
2.2 潜在约束条件
一些约束条件虽然现阶段由于不同的原因,暂时不能成为有效约束条件,但在未来的研究中可以深入考察并取得突破,如:
1) 语义计算在决定“自己”的语用解释的作用。使用Liu和Li(2002)设计的基于知识词典HowNet的词汇语义相似度计算软件,计算“自己”和潜在的先行词间的词汇和语义相似度,确定它的先行词,如例3是一个语篇中通过词汇相似度计算帮助确定“自己”的先行词的例子:
(3) 他并且探出来做这种买卖的同行很多,例如东方大学、东美合众国大学、联合大学(Intercollegiate University)、真理大学等等,便宜的可以十块美金出买硕士文凭,神玄大学(College of Divine Metaphysics)廉价一起奉送三种博士文凭;这都是堂堂立案注册的学校,自己万万比不上。(钱钟书《围城》)

表1 “自己”和潜在先行词间的词汇相似度①
表1显示“他”与“自己”的相似度相对最高,最有可能是“自己”的先行词,这也符合我们的语感。此外,相似度计算在寻找连锁(chained)“自己”的先行词的时候特别有效。如:
(4) 自己没有文凭,好像精神上赤条条的,没有包裹。可是现在要弄个学位。无论自己去读或雇枪手代做论文,时间经济都不够。(钱钟书《围城》)
(5) 人们需要一个虚构的世界来扩展自己的现实,虽然这样的世界是建立在别人的经历和情感之上,然而对照和共鸣会使自己感同身受。(余华《网络和文学》)
很明显,两个相邻“自己”的相似度为1,因此第一个“自己”是第二个“自己”的具有同指内容的第一选择。数据表明,在我们的数据库中,所有的连锁“自己”的例子都属于此类。但是考虑到现有的知识词典对“自己”的描述仍旧需要完善②,还不能过重倚赖语义计算决定先行词,并进一步搜集所需信息。
2) “自己”和先行词距离。“自己”和先行词距离可以根据标点、字的数量、词的数量、句法结构(如:动词+宾语)、功能词(如:连接词)、间隔小句数和段落数标记计算。这个约束条件的影响力还要通过进一步的数据分析并结合其他条件才能确定其有效性。
3) Xu(1994)提出了论旨角色的可及性层阶,如下所示:
施动>体验者>主题>受动
他认为,一个名词词组只有满足了下列两个条件中的至少一个才可能成为“自己”的先行词:(1)在层阶上更靠左;(2)除了其他的语义和语用条件,它应当是句法结构中的主语。他并未指出如果指代路径被阻,如何确定“自己”的先行词。他建议采用综合的研究方法,纳入语义、篇章和句法因素解决“自己”的指示问题。由于现阶段还未发现较为有效的能够自动识别这些论旨角色的方法,该层阶还不能列为合格的约束条件。
3.数据库建设
数据库建设参考了许余龙(2005)中提出的语篇中前指解释数据库建设的一些基本原则、方法、程序和部分特征,也包括了一些新的特征,如语义计算、标点符号标志距离等③。
数据库中的语料来源和“自己”的分布如表2所示,其中篇章代码栏中N代表叙述文本,A则代表议论文本。
目前学者对市场间联动性的研究成果丰富,但多以静态相依性描述为主,本文基于GJR-GARCHDCC模型对“深港通”前后深港股市之间的联动性进行动态互动分析,文章可能的贡献有:第一,以“深港通”为切入点,首次系统性分析了“深港通”机制的运行对深圳股市与香港股市的联动效应影响;第二,为了刻画两地股市的时变特征,本文运用DCC模型来描述市场联动效应的动态变化,测算了深市与港市的动态风险溢出效应。研究发现“深港通”开通之后,两地联动效应经过一定的过渡期才得到显著加强,风险溢出方向主要还是由深市向港市溢出,为金融市场跨地区的协作提供动态监管方向,也为中国股市的健康发展提供可靠的实证依据。
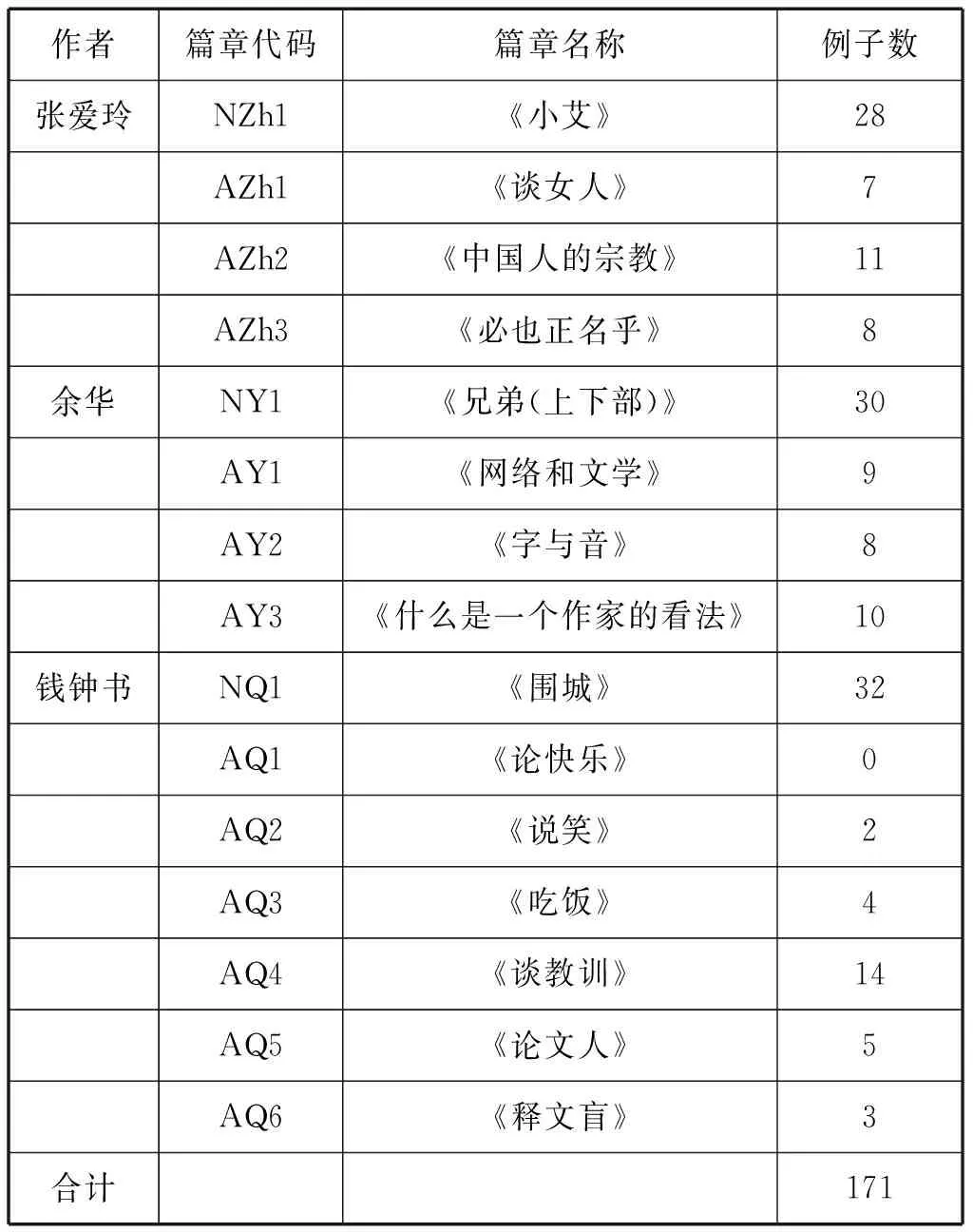
表2 数据库中“自己”的来源与分布
4.讨论和发现
4.1 相互关联的约束条件
分析数据表明在一些约束条件之间存在明显的相互影响的关系。
1) 距离和文体的相互关系:以“自己”和先行词之间的小句和句子数目为例,见表3:
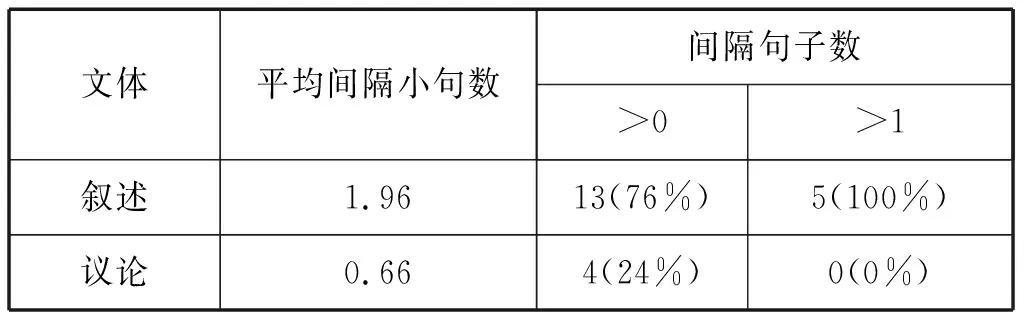
表3 距离和文体的相互关系
“自己”和先行词的距离在两种不同文体中存在一致的明显差异。在叙述文中,“自己”可在更大的范围内自由选择先行词,而议论文中的“自己”则相对受限。
2) “自己”和先行词的句法位置间的关系:Keenan和Comrie (1977)提出了名词短语的可及性层阶(The Noun Phrase Accessibility Hierarchy,简称NPA),后来又在Keenan和Comrie(1979)中通过大量的多语种的例证研究了这些语言中关系从句的构成策略。该层阶如图2所示:
主语>直接宾语>间接宾语>
旁语>属格形式>比较结构宾语④
图2名词短语可及性层阶
研究表明名词短语的句法位置在决定指代性(referentiality)方面作用显著,可及性在指称研究和约束体系中具有同样重要的作用,“自己”和潜在的先行词的句法位置影响先行词选择,因此在我们的约束条件系统中也将包括这方面的特征。表4包含“自己”和先行词的句法位置对应关系的相关数据。
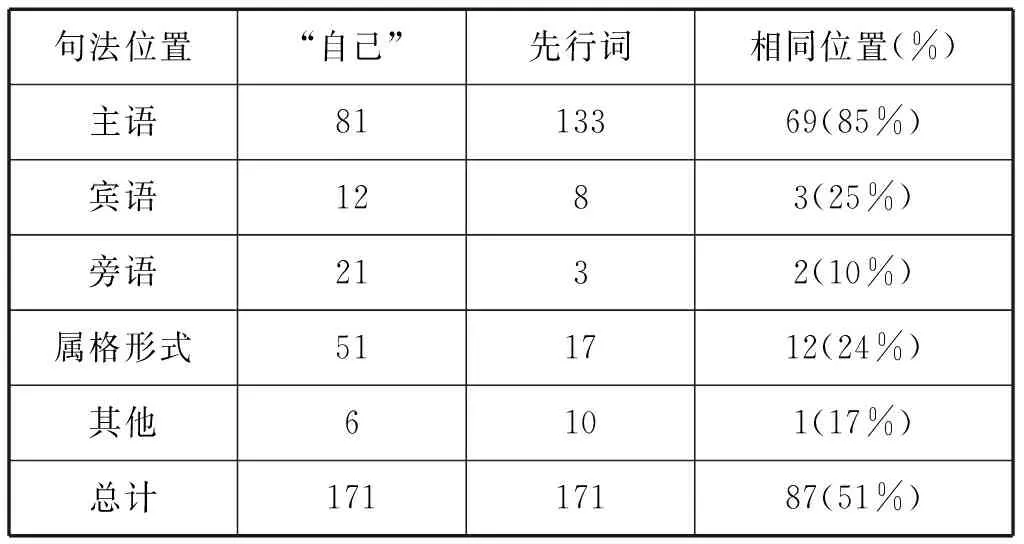
表4 “自己”和它的先行词的句法位置间的关系
表4表明主语位置的“自己”和主语位置的先行词具有最高的吻合度(85%);旁语位置的吻合度最低(10%)。
这些明显相互影响的约束条件虽然不能直接用来预测“自己”的语用解释,但可以帮助我们把较抽象、宽泛的约束条件(如文体、先行词等)分解成操作性更强,更精确的约束条件,从而更加准确的预测语用解释。
4.2 点数配置与点数和的计算
4.2.1 点数配置
只有当一个约束条件的某个值对“自己”的语用解释产生显著的直接影响时,才会根据该值对特定的语用解释的预测效率赋予其点数。现阶段,我们规定如果含有值A的70%以上的例子属于某一特定的语用解释,那么该值即成为能够预测这种语用解释的合格的约束条件。如果值A对于“自己”的特指解释有显著影响,它将被赋予一个正值点数,赋值的计算公式为:

相反,如果值A对泛指解释具有显著影响,它的点数要被转为负值。计算公式如下:

但是,即使70%以上的含有值A的例子与某种语用解释重叠,如果缺乏足够的语料支持,暂时也不会被赋予点数。
下面我们将根据表5的数据分别考察发现的约束条件并为其赋值。

表5 约束条件及其值概览
1) 复合“自己”倾向于具有特指解释,它对特指解释的影响点数为:点数特指=91/134=0.70。
2) 两种文体对“自己”的语用解释的影响很大。所有的泛指解释都出现在议论文中,而80%的特指解释的例子出现在叙述文中。“自己”的语用解释在两种文体的比例也符合Bruner(1986)总结的两种文体的特征。分别给两种文体赋值,该约束条件的绝对值将达到1.8,出于对单一约束条件量权过重的顾虑,现阶段我们暂只给议论文中“自己”对泛指解释的影响加-1。
3) “自己”和先行词的主语位置的特指解释的比例相当高,大约是该位置的泛指解释的3倍。而其他位置上的语用解释并无太大区别。主语位置的“自己”对特指解释影响的点数为:点数特指=60/81=0.74。主语位置的先行词对特指解释影响的点数为:点数特指=100/138=0.72。
4) 虽然先行词的性别的值之间不存在显著差别,但泛指解释中的未知性别的比例特别高。总的来说,数据表明先行词的确定的性别不影响“自己”的语用解释,但如果先行词的性别未知,“自己”倾向于具有泛指解释。先行词的未知性别对泛指解释影响的点数为:点数泛指=52/67=-0.78。
5) 先行词为复数形式的“自己”倾向于泛指解释,而单数形式则倾向于特指解释。先行词的单数形式影响特指解释的点数为:点数特指=103/113=0.91;复数形式影响泛指解释的点数为:点数泛指=-41/51=-0.80。
6) 先行词如果是专有名词短语,“自己”则必然是特指解释。尽管在其他的类别中,如先行词是名词短语、有生命短语和反身代词时,也发现了一些显著影响,但是综合考虑语料支持强度和影响的大小,在现阶段,只有当先行词是专有名词时,“自己”的特指解释才会被加上1个点数。
综上所述,我们所讨论过的合格的约束条件被赋予的点数如表6所示:
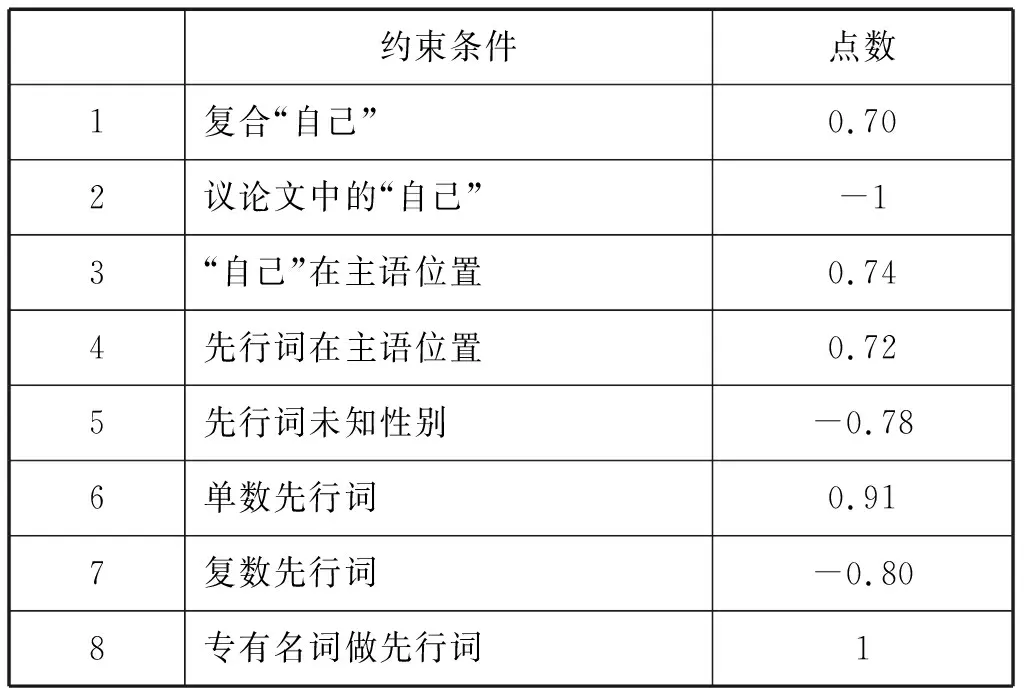
表6 “自己”的约束条件的点数
4.2.2 点数和计算
赋予每个约束条件点数后,将每个“自己”符合条件的约束条件对应的点数相加得到点数和。每个“自己”的点数和决定了它在篇章中的语用解释。表(7-8)表明了具有特指和泛指解释的“自己”的点数和分布情况。

表7 “自己”的泛指解释的点数和分布图
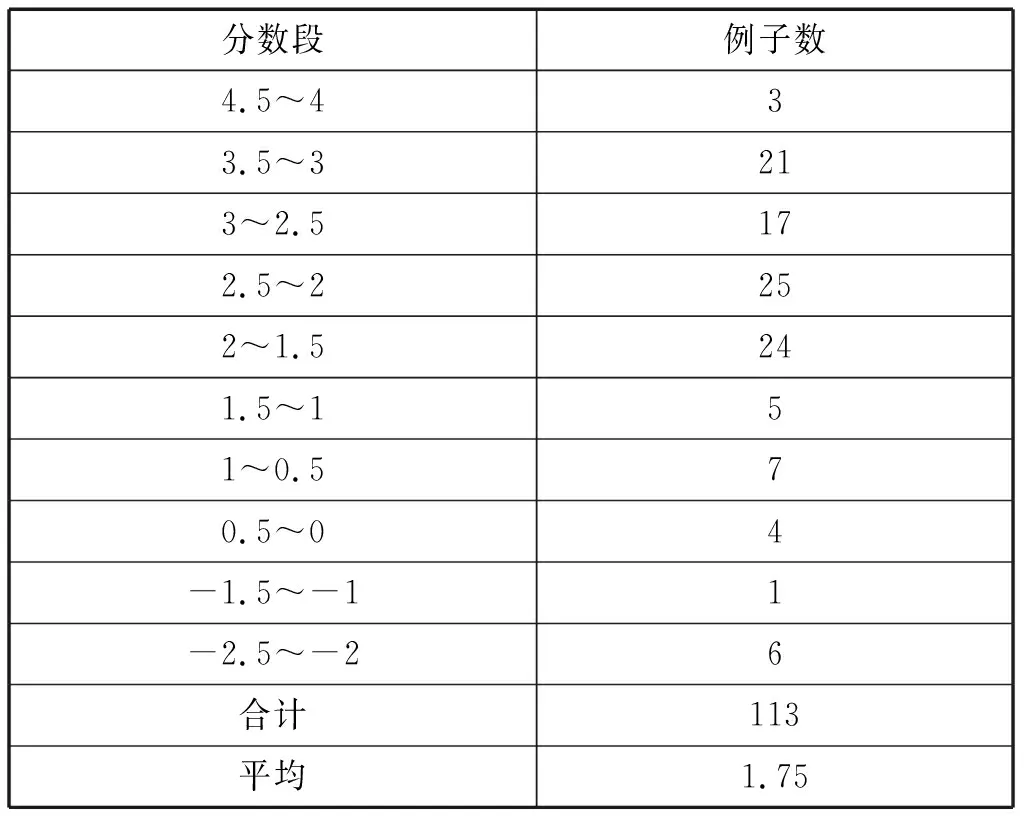
表8 “自己”的特指解释的点数和分布图
为了确定能够准确预测“自己”的语用解释的标准,表9包括了应用不同的待选标准后得到的预测效率。
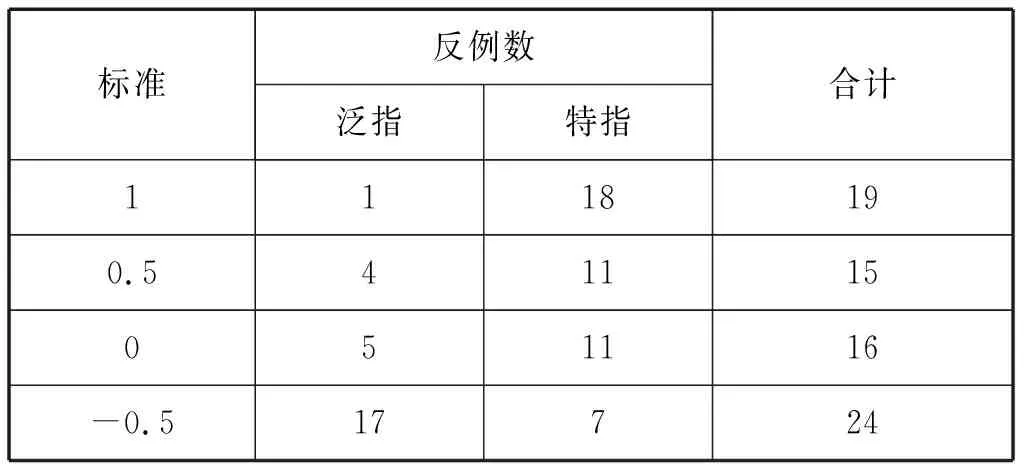
表9 应用不同标准对“自己”的语用解释的预测效率
表9显示如果以点数和0.5作为预测标准,会得到最佳的预测效率91%。点数和高于0.5的“自己”具有特指解释,低于这个标准的具有泛指解释。
5.反例分析及深入研究的方向
通过对反例分析,我们发现“自己”的先行词的人称也对它的语用解释有重要影响。例如,相对其他人称,汉语中的第一人称单数“我”一般不用于泛指解释。例6是具有特指解释的反例,两句中的“自己”都有-0.15的点数和(计算公式为:点数和=(0.91+0.72)-1-0.78=-0.15)。
(6) 至于如何对待音乐明确的特性,我告诉自己应该相信门德尔松的话。(余华《字与音》)
根据前文得出的0.5预测标准,“自己”应当具有泛指解释,然而根据语感,它指作者本人,为特指解释。为了证明第一人称单数是否能够决定“自己”的特指解释,还需要在未来更大规模的语料库中,在不同的人称代词的影响力区分中寻求证明。
基于本研究,今后可以在以下方面做深入研究:首先,进一步扩大语料库规模。真实语料的增加和丰富将增加系统的准确性和说服力。第二,主要因为现有的计算条件还无法有效的甄别并计算一些潜在的约束条件,如语义角色和语义距离,它们未被作为合格的约束条件计算点数,但相信经过进一步的语料的检验和技术的进步,这些条件在今后的研究中将会发挥更重要的作用。第三,如果点数配置能够根据真实语料的统计数据,经过条件间的相对调整,通过计算机程序找到最佳预测力的点数分配方案,预测的结果会更加精确。最后,此类研究方法可以应用于其他指示语的语用解释研究。语料库中指示语和其他短语亦可实现衔接,这有利于提高语篇的计算处理的准确性。
附注:
① “自己”在HowNet中只有两个概念(concept):
ADJ {aValue|属性值,kind|类型}
PRON {self|己}
因此,词汇相似度计算器的参数被重新调整为β1 =0.60,β2=0.40,β3 & β4=0。根据验证,这也产生了更佳的解释力。
② 参见黄居仁(2003:6-21)的相关评论。
③ 数据库结构信息,如有需要请与作者联系。
④ >表示前者比后者的可及性更高。
Bruner, J.1986.ActualMinds,PossibleWorlds[M].Cambridge, MA: Harvard University Press.
Chen, P.2004.Identifiability and definiteness in Chinese [J].Linguistics42: 1129-84.
Karlgren, J.2004.The wheres and whyfores for studying text genre computationally[OL].http://www.aaai.org/library/symposia/fall/fs04-07.php
Keenan, E.L.& B.Comrie.1977.Noun phrase accessibility and universal grammar [J].LinguisticInquiry8: 63-99.
Keenan, E.L.& B.Comrie.1979.Data on the noun phrase accessibility hierarchy [J].Language55: 331-51.
Kuno, S., K.Takami & Y.Wu.1999.Quantifier scope in English, Chinese and Japanese [J].Language75: 63-111.
Kuno, S., K.Takami & Y.Wu.2001.Response to Aoun and Li [J].Language77: 134-43.
Liu, Q.& S.Li.2002.Word similarity computing based on HowNet [J].ComputationalLinguisticsandChineseLanguageProcessing2: 59-76.
Weiss, S.M.& C.A.Kulikowski.1991.ComputerSystemsThatLearn:ClassificationandPredictionMethodsfromStatistics,NeuralNets,MachineLearningandExpertSystems[M].San Mateo: Morgan Kaufmann Publishers.
Xu, L.1994.The antecedent of ziji [J].JournalofChineseLinguistics22: 115-36.
黄居仁.2003.语意网,词网与知识本体:浅谈未来网路上的知识运筹[J].佛教图书馆馆讯33:6-21.
许余龙.2005.语篇回指实证研究中的数据库建设[J].外国语(2):23-29.
杨春雷.2004.汉语量化词辖域的约束条件系统[J].现代外语(3):255-63.
杨春雷.2011.面向语用解释消歧的量化名词短语约束条件系统[J].语言文字应用(1):122-28.
