logistic回归参数遗传算法估计的可行性研究
2012-12-04陈金瓯
韩 芳 陈金瓯 柳 青△
医学研究中常涉及用多个指标对两类对象进行预测或判别的问题,logistic回归是两分类判别或疾病风险预测的常用模型之一。通常用极大似然法估计logistic回归的模型参数,随着计算机功能的日益强大和模型求解方法发展,有人提出了其他的参数估计方法。在以前的应用中人们发现当变量较多而样本有限时,极大似然法估计存在过拟合现象,模型外推应用时出现较大的泛化误差。此外当变量较多而样本较小时,极大似然估计的参数会出现异常值,例如极大极小的参数估计值或极大的标准误〔1-2〕。本文拟通过模拟比较参数估计的遗传算法和极大似然法的结果,从理论上考证极大似然法和遗传算法的适用条件。
遗传算法是通过不断的选择、交叉、变异的计算程式来得到最优解的一种方法,适用范围很广,在医学领域里已有应用,如特殊模型遗传程序设计(genetic programming)用于疾病数据的分类〔3-5〕;又如疾病相关基因的遗传算法搜索〔6〕。在医学分类问题中,通常用分类效能指标考察模型的优劣〔7〕,而通常评价模型参数估计方法时只考察了模型系数的统计学意义,没有考察模型的分类效能。本文主要从分类效能和泛化误差着手,考察极大似然法和遗传算法用于估计logistic回归模型参数的价值。
数据模拟和参数估计方法
1.数据模拟
建立8个自变量的logistic回归模型,自变量包括分类变量和数值变量,数值变量包括呈正态分布的变量和偏倚分布变量。模型设置分别为标准设置(模型1)、自变量间有相关(模型2)和自变量间有相关并且随机误差较大(模型3)。模型表达式如下:
模型1 logit(p)=0.5+0.8x1-1.2x2+1.3x3+1.5x4-0.7x5+1.7x6-1.5x7-0.7x8+e1
模型2 logit(p)=1.5-0.9x1+0.8x3+0.8x2x4-1.2x5-0.6x6-0.6x7+0.8x8x1+e2
模型3 logit(p)=1.5-0.3x1+0.2x3+0.2x2x4-0.4x5-0.2x6-0.2x7+0.2x8x1+e3
其中x1,x4为两分类变量,x2,x3为有序3分类变量,x8为有序5分类变量,x5,x6为正态分布数值变量,x7为偏倚分布数值变量。e为随机误差项,e1服从均数为0,方差为3的正态分布;e2和e3服从均数为0,方差为7的正态分布。模型2中,x3与x1、x2有相关:m3=1.2x1+0.6x2+e,x3为分类变量,所以由m3转换产生;x6与 x4、x5有相关,x6=0.4x4+0.6x5+e;并且x2与x4,x1与x8之间存在交互作用项。模型3的自变量设置、变量间相关、交互作用项与模型2相同,但模型中各自变量的系数值减少,与预测变量的关联减弱。
根据模型1、2和3分别模拟一份例数为1 000的数据作为总体,从中抽取200份样本(包括训练集100份和验证集100份),训练集的样本量分别为800、200、80和40;验证集的样本量不变,均为200。分别根据训练集数据用极大似然法和遗传算法两种参数估计方法估计模型参数,用样本数据估计的模型参数分别做训练集和验证集数据的判别,考察这两种参数估计方法建立模型的分类效能,分类效能的指标为灵敏度、特异度和正确度。
2.遗传算法的参数设置
本研究中遗传算法的目的就是要搜索出一组模型参数,使模型的分类效能达到最大。选入logistic回归和遗传算法的初始变量均是x1~x8,logistic回归通过P值是否小于0.05来筛选最终模型的变量,而遗传算法通过设定系数来筛选变量,例如a1b1x1项,系数a采用二进制编码,取值为1或0,系数b采用实数编码,取值范围为(-∞,+∞)或者根据实际意义加以限定[-2,2],当a1=1时表示模型选入x1变量,b1就是x1的系数值,相反当a1=0时表示模型不选入x1变量,b1无意义。
另外遗传算法本身运算过程需要设定一些参数,为了得到遗传算法的最好结果,通常以不同的参数试验,经过多次试验,选择针对问题的最佳参数〔8〕。本次分析中设置初始参数:种群大小为20,交叉概率为0.6,变异概率为0.005,最大进化代数为100,自变量系数的范围为[-2,2]。通过程序运行的情况以及结果的合理性情况调整程序的参数。
本程序采用的最终参数如下:种群大小为100,交叉概率为0.6,变异概率为0.01,自变量系数的范围为[-2,2],最大进化代数为300,目标函数值超过50代没有改善则程序停止,表示当前代中的最优个体为最终结果。使用的统计软件为SAS 8.1、SPSS 13.0和MATLAB 7.0。
结 果
1.标准参数设置的模拟结果
标准参数设置指自变量独立性较好,自变量之间不存在相关,并且无交互作用的数据结构。在800、200、80和40四种样本量下,极大似然法估计的模型分类效能在训练集和验证集均高于遗传算法估计的模型,如表1所示。但在样本量为40的情况下,两份样本的模型参数极大似然法估计不收敛。观察四种样本量情况下的两种参数估计方法的效能,发现随着样本量的减小,极大似然法在验证集中的分类效能逐渐下降,说明极大似然法的泛化误差随着样本量的减小而增大。而随着样本量的减小,遗传算法在验证集中的分类效能下降不如极大似然法明显,但遗传算法在训练集中的分类效能有一个逐渐增长的趋势,提示随着样本量的减小遗传算法的过拟合现象越来越明显。在样本量为40时,两种方法在训练集中的分类效能差异已无统计学意义。
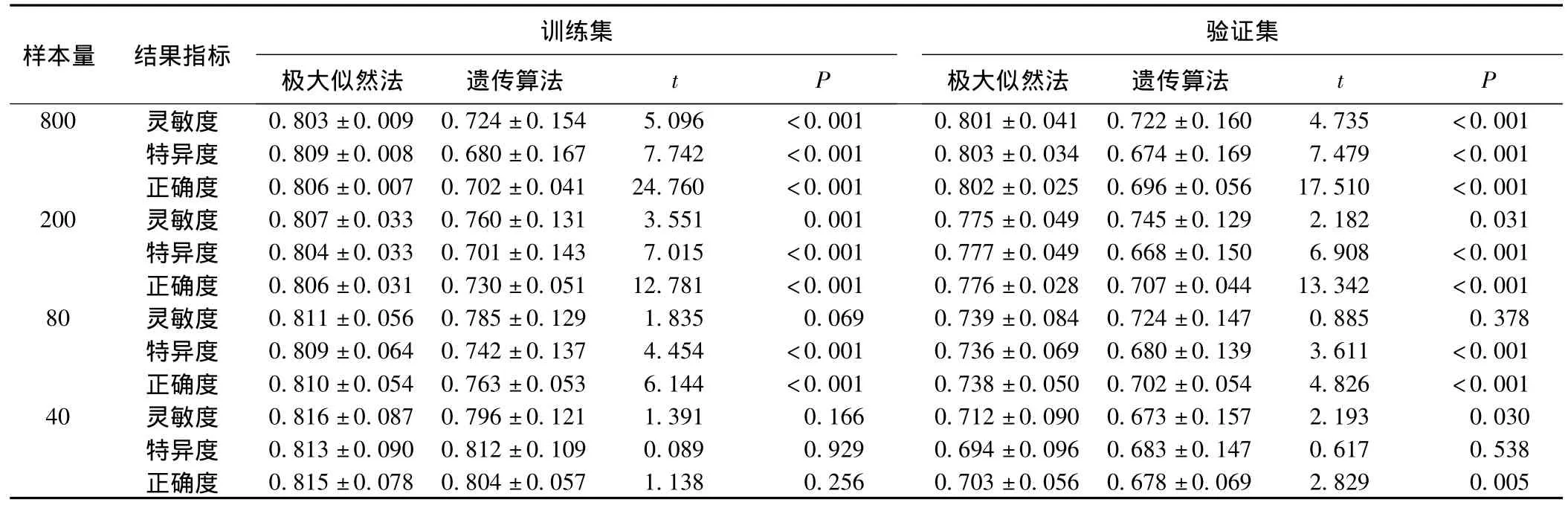
表1 两种方法不同样本量下(模型1)在训练集和验证集中的分类效能(ˉX±S)
2.存在变量相关和交互作用参数设置的模拟结果
当自变量间存在相关,并且有交互作用项时,考察两种参数估计方法在不同样本量下的效能。在样本量为800和200时,极大似然法估计的模型分类效能在训练集和验证集仍然高于遗传算法估计的模型,如表2所示,但在样本量为80和40时,极大似然法和遗传算法估计的模型分类效能差异无统计学意义,说明数据结构比较复杂时极大似然法估计模型参数的分类效能降低。同样的,在样本量为40的情况下,五份样本的模型参数极大似然法估计不收敛,说明复杂的自变量间关系影响了极大似然法的参数估计效能。
另外观察四种样本量情况下的两种参数估计方法的模型分类效能,发现和标准设置同样的趋势,极大似然法的泛化误差随着样本量的减小而增大;遗传算法的过拟合随着样本量的减小而增大。
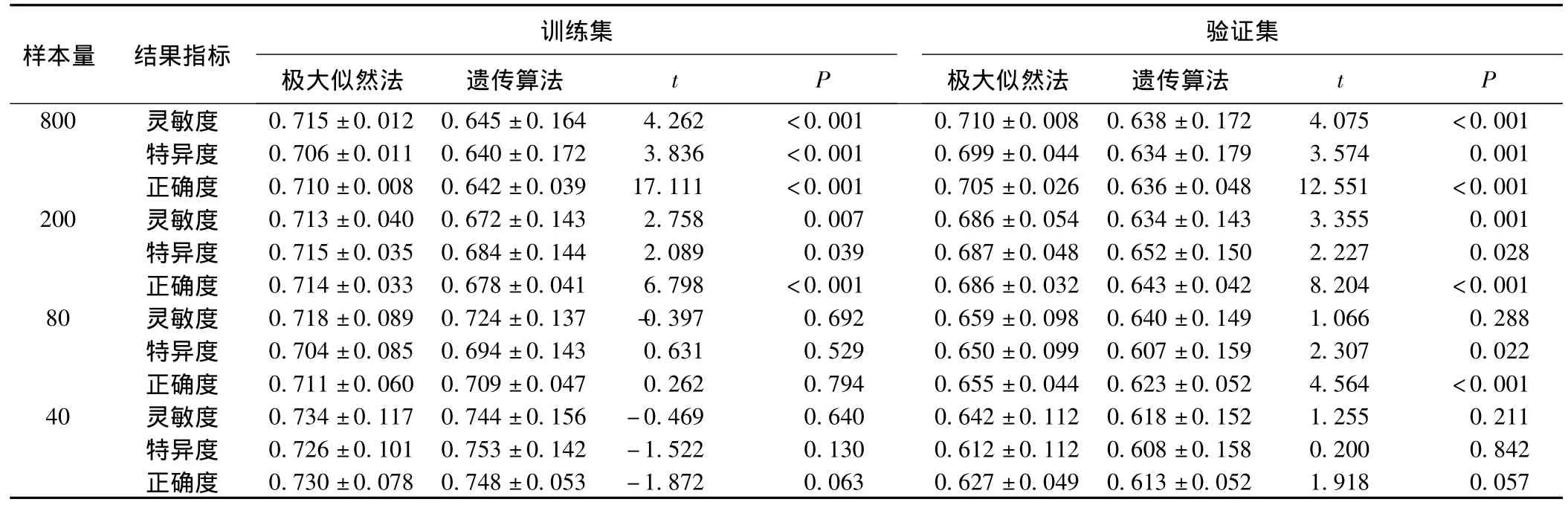
表2 两种方法不同样本量下(模型2)在训练集和验证集中的分类效能(ˉX±S)
3.随机误差增大模型模拟结果
当自变量间关系复杂而随机误差增大时,数据变异程度增加。在这种数据结构下,自变量对因变量的影响受到干扰比较大,在这种情况评价两种参数估计方法的分类效能。在训练集样本量为80的情况下,100份训练集样本中有64份样本极大似然法不收敛,训练集样本量200时,仍有39份样本极大似然法不收敛(表3)。提示当数据不理想时,极大似然法受样本量限制比较大,而遗传算法不受影响。撇开极大似然法不收敛的那些样本,模型3的两种方法估计模型参数的分类效能与模型2相似,故不重复。
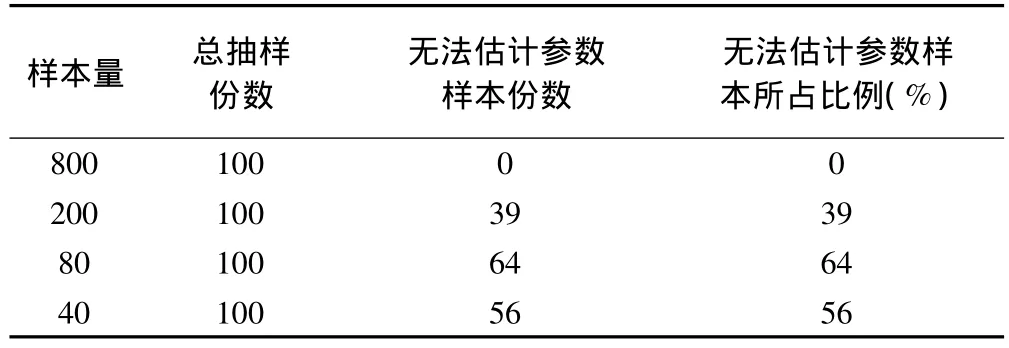
表3 极大似然法无法估计参数的样本数
讨 论
本文通过模拟研究发现:遗传算法在数据内部结构不复杂的情况下能达到较高的分类效能,如模型1里面遗传算法的分类效能在0.7~0.8之间,但其分类效能并没有超越logistic回归方法。而logistic回归参数的极大似然法估计是常规的方法,已经有相当长时间的应用。因此,一般情况下极大似然法仍属首选参数估计方法。但是模拟结果也提示:当样本量较小,自变量关系复杂,自变量与因变量关系较弱时,模型参数的极大似然法估计可能不收敛,这时遗传算法可能成为理想的替代方法。
有文献报道遗传算法做logistic回归模型的参数估计〔9〕,效果更好,但该文献为单个自变量的logistic曲线模型。本文模拟结果显示遗传算法还不能替代极大似然法用于logistic回归参数估计,仅在小样本复杂数据结构情况,有一定的价值。
样本量小或自变量与因变量关联较弱的情况在基因突变与疾病关联分析中比较常见,这时极大似然法可能无法完成logistic回归模型的参数估计,而遗传算法可能发挥其优势。此外遗传算法在模型搜索方面更具有优势,遗传算法搜索出的模型相对简单,能从大量的自变量中搜索出对应变量有影响的自变量,简化模型,因此模拟遗传算法搜索不同结构logistic回归模型及估计参数的效果,值得进一步探索。
1.冯国双,陈景武,周春莲.logistic回归应用中容易忽视的几个问题.中华流行病学杂志,2004,25:544-545.
2.陈彬,李从珠.基于选择抽样下的Logistic回归.北方工业大学学报,2006,18:86-90.
3.Cornelis J,Biesheuvel,Ivar S.Genetic programming outperformed multivariable logistic regression in diagnosing pulmonary embolism.Journal of Clinical Epidemiology,2004,57:551-560.
4.Ivar S,Maarten K.Genetic programming as a method to develop powerful predictive models for clinical diagnosis.GECCO'05 2005,June,164-166.
5.Milo E,Jeffrey AK.Use of genetic programming to diagnose venous thromboembolism in the emergency department.GenetProgram Evolvable,2008,9:39-51.
6.Li L,Jiang W,Li X.A robust hybrid between genetic algorithm and support vector machine for extracting an optimal feature gene subset.Genomics,2005,85:16-23.
7.Regeniter A,Freidank H,Dickenmann M.Evaluation of proteinuria and GFR to diagnose and classify kidney disease:Systematic review and proof of concept.European Journal of Internal Medicine,2009,20:556-561.
8.Michalewicz Z,Genetic Algorithms+Data Structures=Evolution Programs.Berlin:Germany Springer,1989.
9.蔡煜东.运用遗传算法拟合 Logistic曲线的研究.生物数学学报,1995,10:59-63.
