样本量估计及其在nQuery和SAS软件上的实现——均数比较(一)
2012-12-04段重阳陈平雁
吕 朵 段重阳 陈平雁
样本量估计是研究设计中的一个极为重要环节,如何正确估计样本量即使对于统计专业人员都是较难把握的技能。目前,无论是统计专业人员还是非专业人员在实施样本量估计时大多面临以下三个问题:其一,目前国内尚缺乏系统地介绍样本量估计方法的文献,从而导致在实验设计阶段进行样本量估计时手段受限,尤其涉及到临床试验中应用较多的非劣性检验和等效性检验,以及一般研究中非参数检验、多元回归和相关分析的样本量估计方法。其二,由于国内的教科书、专著和一些相关的期刊论著在介绍样本量估计方法时缺乏源头文献的引用,加之某些设计的样本量估计方法不止一种,我们采用的方法是否准确和权威?我们应用的究竟是谁提出的方法?其三,样本量估计的应用软件并不普及,如果依靠研究人员自己编程会有相当难度。
鉴于上述原因,我们以样本量估计专业软件nQuery Advisor 7.0〔1〕为依据(因为该软件目前被国际上公认为样本量估计的权威软件之一,同时得到美国FDA的认可),系统介绍样本量估计方法,给出计算公式及其权威出处,通过实例加以说明,并附有nQuery Advisor 7.0的操作主界面和样本量估计中参数设置的界面,以及SAS 9.2软件实现的程序,便于广大读者应用。为了验证nQuery Advisor 7.0计算结果的准确性,同时用SAS 9.2软件及R语言由双人乃至三人独立编程进行验证,以确保无误。由于篇幅所限,本系列文章将侧重基于差异性检验与等效性检验的样本量估计方法,基本不涉及基于可信区间的样本量估计方法。有关R语言实现的程序将有另文介绍。
全部内容按统计分析方法分为五个部分,分别为均数比较、率的比较、生存分析、相关分析、回归分析的样本量估计,详细目录见表1。所涉及的参考文献均列在每个部分的结尾处。
因本文涉及的样本量计算公式较多,凡公式中出现的相同符号统一定义如下:
α:检验水准;
1-β:检验效能;
s:取1代表单侧检验,取2代表双侧检验;
MSE:均方差;
CV:变异系数;
各类参数:如μ(总体均数)、σ(总体标准差)等,这些参数一般未知,通常根据优先顺序 — 预试验结果、他人研究结果、假设等三种方式进行估计。
若个别公式中的符号与上述定义不符,或另有含义,将以个别公式的定义为准。
1 均数比较
1.1 单样本均数的比较
1.1.1 差异性检验
1.1.1.1 单样本t检验
方法:O'Brien和Muller(1993)〔2〕给出的单样本t检验的样本量估计是建立在自由度为n-1,非中心参数为的非中心t分布基础上。其检验效能的计算公式为:


表1 样本量估计方法目录
式中,μ1为预期总体均数;μ0为已知总体均数;σ为预期的总体标准差。
在计算样本量时,一般先设定样本量初始值,然后迭代样本量直到所得的检验效能满足条件为止。此时的样本量,即研究所需的样本量。
【例1-1】某研究欲验证从事铅作业男性工人的血红蛋白含量是否与正常成年男性平均值(140 μg/L)有差异。预试验测得从事铅作业男性工人的血红蛋白含量均值130.83 μg/L,标准差 25.74 μg/L。如果设定α为5%水平,检验效能为85%,双侧检验,统计分析采用单样本t检验,试估计样本量。
nQuery Advisor 7.0实现:设定检验水准 α=0.05;双侧检验,即s=2;检验效能取1-β=85%。依据上述基础数据可知,μ1=130.83,μ0=140,σ =25.74。在nQuery Advisor 7.0主菜单选择:
Goal:Make Conclusion Using:⊙Means
Number of Groups:⊙One
Analysis Method:⊙Test
方法框中选择:One group t-test for difference in means
在弹出的样本量计算窗口将各参数键入,如图1-1所示,结果为n=73。即本试验的最少样本量为73例。

图1 -1 nQuery Advisor7.0关于例1-1样本量估计的参数设置与计算结果



图1 -2 SAS 9.2关于例1样本量估计的参数设置与计算结果
1.1.1.2 基于差值均数的配对t检验
方法:与单样本t检验相同,见式(1-1),只需将μ1定义为预期差值的总体均数μd=μ1-μ2;已知总体均数μ0定义为0;σ为预期差值的总体标准差。
【例1-2】在一项将要开展的减肥新药临床试验中,采用自身前后对照的配对设计。由预试验得到的初步结果显示,未服药前的体重指数(BMI)均数为28.5,服药治疗后的BMI均数为26.0,服药前后差值的标准差为4.5。如果设定α为5%水平,检验效能为85%,双侧检验,统计分析采用配对t检验,试估计样本量。
nQuery Advisor 7.0实现:设定检验水准 α=0.05;双侧检验,即s=2;检验效能取1-β=85%。依据上述基础数据可知,μ1=28.5,μ2=26.0,σ =4.5。在nQuery Advisor7.0主菜单选择:
Goal:Make Conclusion Using:⊙Means
Number of Groups:⊙One
Analysis Method:⊙Test
方法框中选择:Paired t-test for difference in means
在弹出的样本量计算窗口将各参数键入,如图1-3所示,结果为n=32。即本试验的最少样本量为32例。
SAS 9.2软件实现:

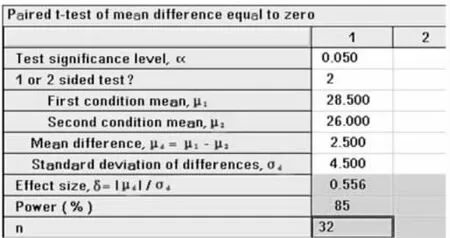
图1 -3 nQuery Advisor7.0关于例1-2样本量估计的参数设置与计算结果



图1 -4 SAS 9.2关于例2样本量估计的参数设置与计算结果
1.1.1.3 单个重复测量因素方差分析
方法:Dixon和 Massey(1983)〔3〕给出的单个重复测量因素方差分析的样本量估计是建立在自由度为M-1和(M-1)(n-1),非中心参数为 nM(V/σ2·(1-ρ))的非中心F分布上。其检验效能的计算公式为:
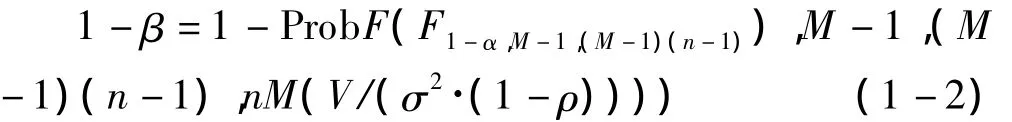
式中,M为重复水平数;V为各个水平均数的方差;ρ为水平间的相关系数;σ为每一水平的总体标准差。
在计算样本量时,一般先设定样本量初始值,然后迭代样本量直到所得的检验效能满足条件为止。此时的样本量,即研究所需的样本量。
【例1-3】一项旨在提高儿童自尊心的心理干预试验中,用一个满分为100的儿童自尊心量表分别在干预前、干预后1个月、2个月,3个月对受试儿童进行测量,以评估干预效果。通过预试验获得干预前得分为55,第一次测量和一月后第二次测量之间的相关系数为0.7,两次测量的合并标准差为10。研究者预期经过三个月的干预后得分上升到59.5。试估计本研究在检验效能为90%的情况下所需样本量。
nQuery Advisor7.0实现:设定检验水准α=0.05;检验效能取1-β=90% 。依据上述基础数据可知,ρ=0.7,σ =10,M=4。在nQuery Advisor7.0 主菜单选择:
Goal:Make Conclusion Using:⊙Means
Number of Groups:⊙One
Analysis Method:⊙Test
方法框中选择:Univariate one-way repeated measures analysis of variance。
注意,这里首先应根据不同时间观察结果对V进行估计,假设测量得分逐步均匀升高。在菜单栏中选择:
Assistants:⊙Compute Effect Size
在弹出的计算窗口将各参数键入,如图1-5所示,结果为V=2.813。

图1 -5 nQuery Advisor7.0关于例1-3样本量估计的参数计算结果

图1 -6 nQuery Advisor7.0关于例1-3样本量估计的参数设置与计算结果
在图5界面点击Transfer按钮,计算结果V值显示于主对话框(图1-6),在主对话框再键入其他参数,结果为n=40。



图1 -7 SAS 9.2关于例1-3样本量估计的参数设置与计算结果
