多格式文档搜索引擎索引系统设计与实现
2012-11-21方跃胜姚宏亮
方跃胜 董 辉 姚宏亮
(安徽水利水电职业技术学院电子系,安徽 合肥 231603) (亳州职业技术学院信息工程系,安徽 亳州 236800) (合肥工业大学计算机与信息学院,安徽 合肥 230009)
多格式文档搜索引擎索引系统设计与实现
方跃胜 董 辉 姚宏亮
(安徽水利水电职业技术学院电子系,安徽 合肥 231603) (亳州职业技术学院信息工程系,安徽 亳州 236800) (合肥工业大学计算机与信息学院,安徽 合肥 230009)
随着Internet和计算机的迅猛发展,搜索引擎应需而生,越来越多的企业利用计算机处理运营过程中产生的大量电子文档。如何从这些网络和多格式文档资源中迅速、方便而准确地检索出企业用户所需的信息已成为越来越重要的问题。索引系统是搜索引擎的核心,为提高系统的查全率和查准率,设计了一种适用于文档检索的数据库存储的索引结构并建立索引库来降低索引组织的复杂度,通过布尔逻辑和向量空间的组合模型实现对检索结果排序,以返回最优文档列表。该系统在Windows环境下采用PHP开发组件实现,能够提高检索文档的查全率和查准率。
文档搜索引擎;索引同步;检索模型
随着Internet和计算机的日益发展,搜索引擎已成为人们获取海量网络信息的主要工具。按照“快、全、准、稳”的评测标准,目前的许多搜索引擎已经不能满足人们的需求[1]。此外,越来越多的企业开始利用计算机处理企业的运营过程中产生的大量电子文档。如何从网络和多格式的文档资源中迅速准确地检索出企业用户所需的信息已成为越来越重要的问题。因此,开发快速准确和智能化的搜索引擎是目前的研究热点,而搜索引擎设计中的重要工作是建立索引系统,其目的是能够快速地响应用户的查询。为此,笔者对多格式文档搜索引擎的索引系统进行了研究。
1 索引构建
1.1索引数据库设计
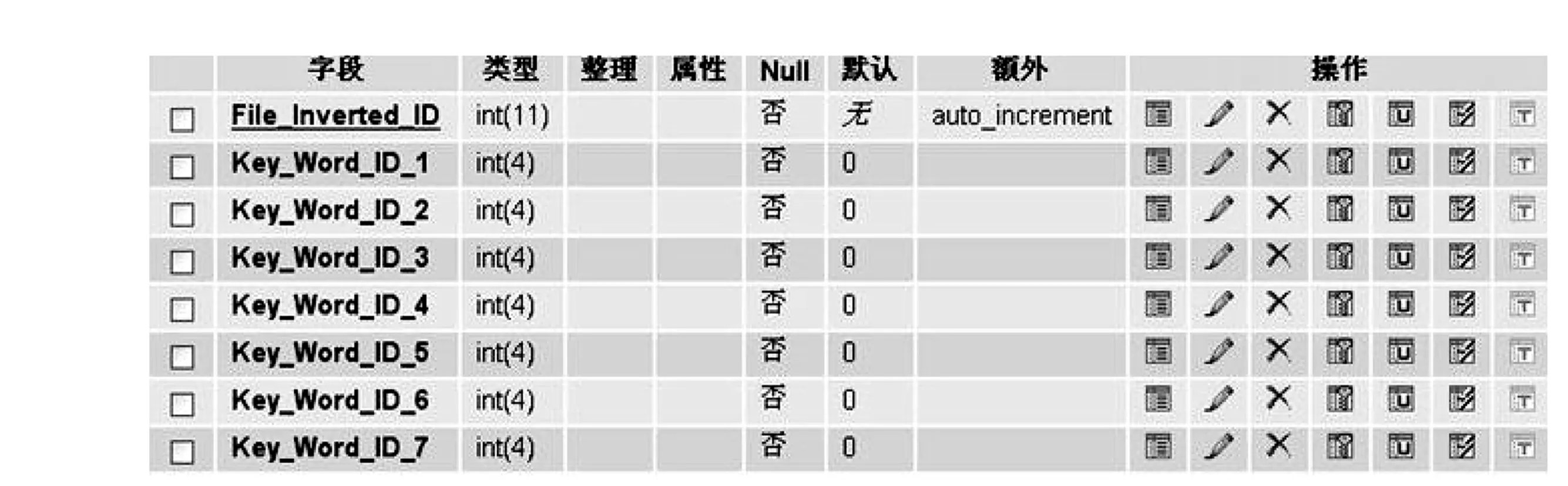
图1 倒排表结构
1)文档表 文档表包含文档编号(File_ID)和文档名称(File_Val)2个字段。
2)关键词表 关键词表包含关键词编号(KeyWord_ID)和关键词(KeyWord_Val)2个字段。
3)倒排表 倒排表是索引数据库的核心部分,其结构如图1所示。
1.2索引组织设计
1)倒排表存储 针对倒排表存储的问题,提出了以下3种设计方案:①直接将倒排表放入内存;②将倒排表存入硬盘上的文件;③将倒排表及必要的文件存入数据库(此处使用MySQL)。由于数据量很大,综合考虑各个方面的算法,决定采用方案③,同时在具体实现过程中,对二维数组采用分组的方法来实现对索引文件的存储。使用数据库来代替文件流,可使插入、删除、查询等操作更加方便、高效。
在具体实现倒排表存储时基于以下思想[2]:建立多个数据表,其中每个表有2001个字段,每篇文档作为一个数据插入,其中第一个字段作为文档编号,后面所有的数据以0作为标志,为0则该文档不含有对应的词,否则含有。数据库中的倒排表有多个数据表组成,具体设计时应注重以下几个方面:①表与表之间的联系。将所有的文档都作为数据量插入表中,各个表唯一的不同是关键词编号,因而可将2000作为一个单位标志分别将表命名为Inverted_0、Inverted_1、…,使得各个表互相联系。②处理文档与关键词在数据库中的存储方式。对于文档,在存储的时候直接存储其在服务器中的位置信息,以数据库自动为其添加的ID作为主键;对于关键词,使用ID和关键词本身来存储关键词。③对文档和关键词的插入和删除的处理。对关键词的插入和删除就是对字段的插入和删除处理,而对文档的插入和删除即为对数据的插入和删除处理。
2)建立关键词表 建立关键词表的流程如图2所示。
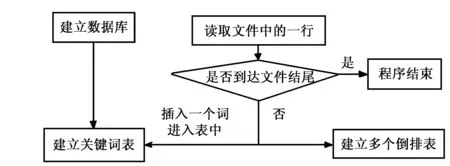
图2 建立关键词表流程图
3)插入关键词 插入关键词的步骤如下:①将所有的关键词读入数据库;②将文档插入文档表,同时运用已经写好的倒排算法将文档插入上一步形成的空的倒排表;③在查找过程中首先读取关键词,查到其在关键词表中的ID,然后在倒排表中读取该词的ID遍历这一行,最终得到该词所在文档的编号。具体实现算法[3]:对于给定的关键词,如果不为空,首先将关键词插入关键词表;判断关键词标志量flag_word 是否为“1”,若是则建立新的倒排表,否则进入下一步;将当前的关键词插入当前的倒排表中的列属性中,同时使关键词标志量flag_word 加“1”;如果关键词标志量flag_word越界,将关键词标志量flag_word量置“1”,同时使倒排表标志量flag_table加“1”。
4)建立多个倒排表 建立多个倒排表的具体流程如图3所示。
5)建立文档表 建立一个文档表,向其中添加文档,同时在数据库中形成了一些类似二维数组的多个倒排表。在向表中插入文档的同时,对每一个文档进行遍历。
6)向倒排表插入数据 向倒排表中插入数据的流程如图4所示。
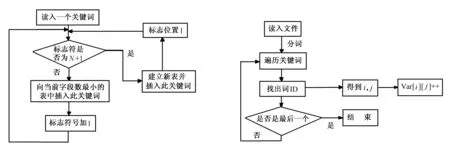
图3 建立多个倒排表流程图 图4 向倒排表中插入数据流程图
1.3索引同步设计
1)关键词同步 对所有的关键词用ELFHash()函数[4]运算,计算出每个关键词的散列码。将相同散列码的关键词存在散列表的同一个位置,并记录其所在文档信息。在关键词同步的存储结构中建立了2个数组,其中1个用来存储关键词,另1个用来存储与关键词索引值相同的文档编号,使其一一对应。在程序运行的过程可以直接通过array_search()函数[5]来查找到相应的关键词及其对应的文档信息。在程序运行的过程中,首先初始化关键词数组并建立文档类的数组并使其一一对应,然后遍历所有的文档并将关键词所在文档添加进入文档类数组。在遍历文档时,得到该文档分词后的某一个关键词,判断关键词所在文档是否在文档数组中的对应位置。若在其对应的位置则证明该文档已经添加进入其对应位置,不再作任何处理;若不在其对应位置,则将其信息添加进文档数组。同步流程图如图5所示。
2)文档同步 对于文档同步,应建立一个关键词类的数组,用数组的下标作为文档的编号,存储关键词在该文档中出现的次数、位置等信息。在程序运行的过程中,对分词后的关键词数组进行遍历得到某一个关键词,然后判断该关键词是否在该篇文档的关键词数组中,如果在数组中就添加其位置信息,如果不在数组中则添加本关键词及其位置信息进入关键词数组中。
2 索引检索
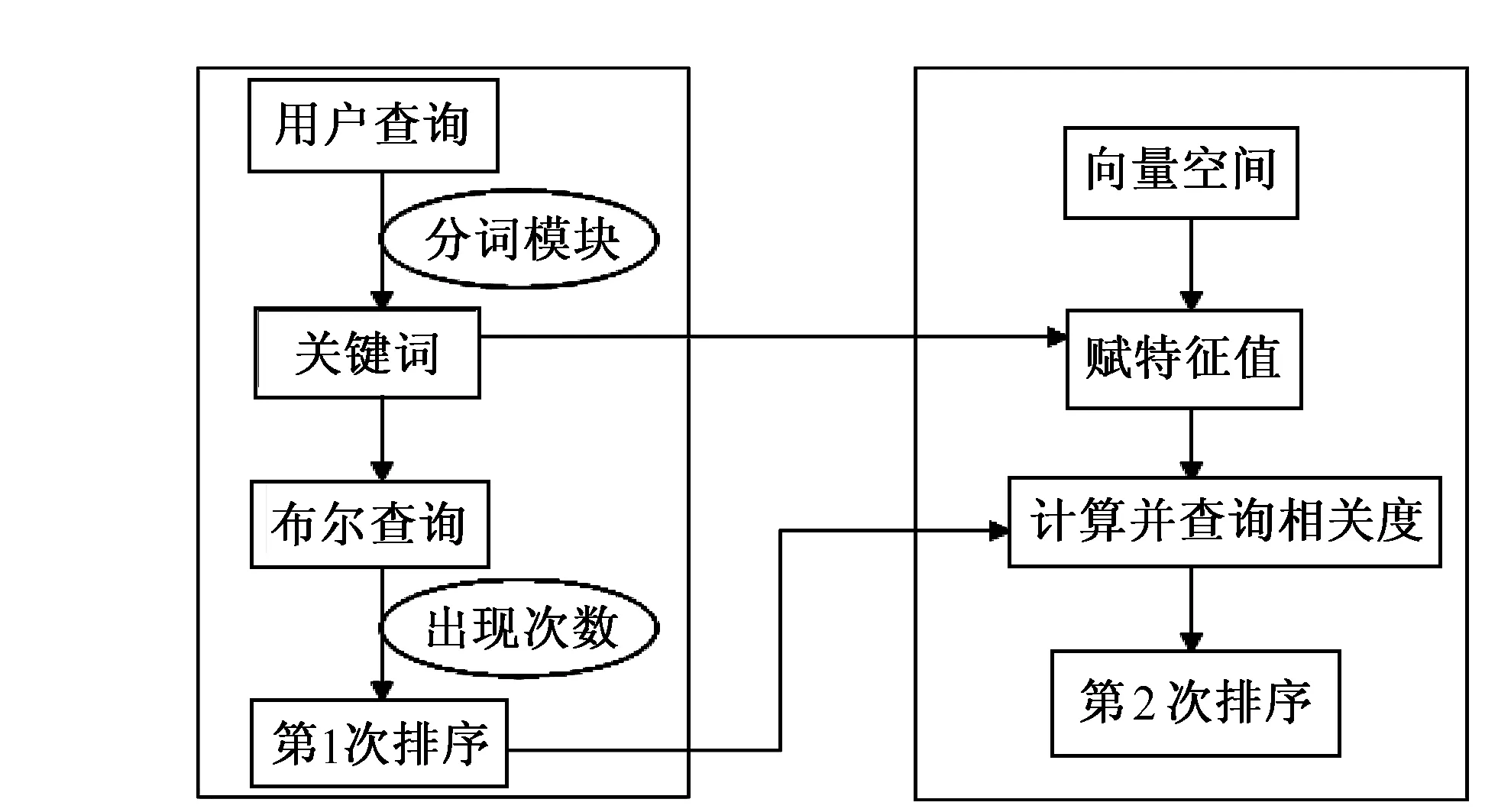
图5 信息检索组合模型
该系统采用基于词索引的中文全文检索,信息检索模型采用布尔逻辑和向量空间的组合模型,设计思想如下(以法律文档查询为例):①首先用布尔逻辑检索模型将用户查询通过基于Memcached的动态四字双向词典机制的分词系统切分成关键词序列;②将这些关键词组成布尔查询语句;③利用数据库查询,到索引库中取出包含这些关键词的所有案例,并按照关键词在每一个案例中出现的次数对所有的案例进行第1次排序,取出关键词出现次数最高的前50个案例作为第2次排序的依据;④建立一个向量空间;⑤对上一步分出来的关键词作为向量空间的特征表示集,形成1个N维向量,其中每1维作为1个特征;⑥对第1次排序中的前50个案例利用TFIDF公式[6]分别计算其与查询的相关度;⑦根据相关度高低对这50个案例进行第2次排序,并与其它案例一起返回给用户。组合信息检索模型如图5所示。该模型不仅能解决布尔逻辑检索模型对查询结果排序不准确的问题,而且能提供比向量空间模型更快的查找速度,满足用户对系统响应速度的要求,同时还可以降低系统运行成本。
3 系统实现
该系统在Windows环境下采用Apache+PHP+MySQL黄金搭档来实现:类Inverted函数Create_DB()实现数据库功能,Create_KeyWord_Table()函数实现初始的关键词表功能,Create_File_Table()实现初始的文档表功能,Create_InvertedTable($var)实现倒排表的功能,从而实现数据库的初始化。当更新数据库时,调用Insert_Dir()函数,将文件夹中所有文档都输入数据库,文档为经过分词后的txt文件。函数Insert_Dir()首先将文件名插入file表,然后读取文件将其中的词插入关键词表,同时更新倒排表内容,记录关键词在文档中的出现次数与位置。检索时,对输入内容首先进行分词和去停用词处理,然后对数据库中文档运用综合模型分析、计算以确定输出。
4 结 语
随着Internet和计算机的迅猛发展,许多企业利用计算机处理运营过程中产生的大量电子文档。为了从网络和多格式文档资源中迅速准确地检索出所需信息,设计了一种适用于文档检索的数据库存储的索引结构,通过建立索引库来降低索引组织的复杂度,利用布尔逻辑和向量空间的组合模型对检索结果排序并返回最优文档列表,系统在Windows环境下采用PHP开发组件实现。实际运行表明,该系统能够提高检索文档的查全率和查准率。
[1]郑榕增,林世平. 基于Lucene的中文倒排索引技术的研究[J].计算机技术与发展,2010(3):55-56.
[2]杨安生.基于倒排表的中文全文检索研究[J].情报探索,2009(7):77-80.
[3]陈海波.基于自动分词的企业文档搜索引擎设计与实现[D].西安:西北工业大学,2007.
[4]肖丽.哈希查找中散列函数的运用[J].技术与市场,2009,16(8):18-19.
[5]曹衍龙,赵斯思.PHP网络编程技术与实例[M].北京:人民邮电出版社,2006.
[6]熊回香,夏立新.基于词索引的中文全文检索关键技术及其发展方向[J].中国图书馆学报,2007,33(4):47-51.
10.3969/j.issn.1673-1409(N).2012.07.038
TP391
A
1673-1409(2012)07-N111-03
2012-04-24
国家自然科学基金资助项目(60705015)。
方跃胜(1975-),男,1999年大学毕业,讲师,硕士生,现主要从事中文分词与索引关键技术方面的教学与研究工作。
[编辑] 李启栋
