基于雨林框架的朴素贝叶斯分类算法
2012-11-08包小兵翟素兰程兰兰
包小兵 ,翟素兰 ,程兰兰
(1.池州学院 数学与计算机科学系,安徽 池州 247000;2.安徽大学 数学科学学院,安徽 合肥 230039)
基于雨林框架的朴素贝叶斯分类算法
包小兵1,2,翟素兰2,程兰兰2
(1.池州学院 数学与计算机科学系,安徽 池州 247000;2.安徽大学 数学科学学院,安徽 合肥 230039)
提出了一种可伸缩的朴素贝叶斯分类算法。算法针对大数据集的训练数据,通过构建雨林框架,能在有限主存里存储训练数据,训练生成概率矩阵,进而对测试样本进行分类。算法仅对整库一次扫描。实验表明,该算法能够获得与整库读入主存相同的分类准确率,并且有较高的处理效率。
雨林;可伸缩算法;朴素贝叶斯分类
1 引言
分类问题是一种重要的数据挖掘问题,分类算法在各个领域已得到广泛的应用,为了增加分类算法的准确性,除了改进算法本身,更重要的是能够使用大数据集进行训练,而这样会受到两个方面的因素制约:一是增加处理时间,二是没有足够的主存来存储大数据集,主辅存数据的转出转入将耗用更多的处理时间。迫切需要解决该问题。
算法的可伸缩性是指当算法运行需要大数据集时算法的有效性问题,即是说一个分类算法的可伸缩性好意味着它可以处理大训练集且有较高的分类精确度。而有些分类算法的可伸缩性差则成了阻碍它们广泛应用的原因之一。在处理算法的可伸缩性问题上通常用下面的方法:(1)在大训练集中进行数据采样;(2)将数据分成若干小块,分别构建分类器,然后综合成一个最终的分类器。但这些方法最大的问题是降低了分类算法的准确性,所以它们并不是好的处理方法。本文提出了基于Rainforest[2]框架的朴素贝叶斯分类算法[1],在能够训练大数据集的同时也具有较高的分类精确度。
2 预备知识
2.1 基本理论
贝叶斯分类法是统计学的方法,可以预测类成员关系的可能性。实践表明表现出高准确率和高速度。贝叶斯分类基于贝叶斯定理,下面介绍贝叶斯定理。
定理1[1](贝叶斯定理)设样本空间S被分成一个含有n个互斥事件的集合,每个事件成为S的一个划分:
S={A1,A2, …,An},AiAj=0,i≠j,X 是 S中任意一个事件,则有下面的结论:

朴素贝叶斯分类法[2](Nalve Bayesian Classifier,NBC)是基于条件独立性假设,即假设一个属性对给定类的影响独立于其它属性。这一假定称为类条件独立性。
设D是包含类标号的训练元组集合,每个元组用n维向量X={x1,x2,…,xn}表示,属性集合可记为DA={A1,A2,…,An}。假设有 J个类 C1,C2,…,CJ,给定的元组X,分类法将预测X属于具有最高后验概率(条件X下)的类。根据贝叶斯定理有:

其中,P(X)为常数,先验概率P(Ci)可以根据训练元组计算得到。为最大化后验概率P(Ci|X),需要最大化条件概率 P(Xi|Ci)。 而事实上计算 P(X|Ci)往往是复杂并且开销较大的,因此做了类条件独立的朴素假设,于是有:

其中xk表示元组 X属性 Ak的值,P (Xk|Ci)的值由训练元组计算。
2.2 朴素贝叶斯分类算法
为了计算条件概率P(Xk|Ci)以计算后验概率,在本文提出的算法中给出如下的定义。
定义1设A为元组的一个属性,xk为属性A的取值,其中k=1,2,…,nA,类标号取值为Ci,i∈{1,2,…,J},称由所有条件概率P(Xk|Ci)生成的矩阵为概率矩阵,定义如下:

那么对于DA中的所有属性,得到如下的概率矩阵簇,记为:

在对预测元组X进行分类时,只需要将元组值和上面定义的概率矩阵簇进行对照,找出相应的条件概率值,根据公式(3)算出各个类的后验概率,比较后得出预测分类,分类完成。
2.3 雨林框架
从朴素贝叶斯分类算法中可以看出,为了计算条件概率P(X|Ci),仅需要对各个属性取值和类取值分别统计,面对大数据集,使用如下的Rainforest框架处理。
设D为训练数据集的元组集合,属性列表集为X,对于属性x∈X,将D往属性列x和类标号列C作投影,得到新数据集 Dx={t(x,i)|x∈X,i∈C},其中,设类标号取值为dom(C)={1,2,…,J}。对属性x的不同值在每个类别i上作计数,令aX,x,i为满足属性值t.X=x且类标号t.C=i的元组t的个数,形式地定义如下:

定义 2[3]令 S=dom(x)×NJ,其中 NJ={(a1,a2,…,aJ)|ai=aX,x,i,i∈dom(C)},如下定义 AVC-set(Attribute-Value Classlabel set):

定义3[3]称由每个属性x∈X对应的AVC-sets构成的集合为AVC-group,形式表示为:AVCgroup={AVC(x)|x∈X}。
用以上定义构建的结构被称为是雨林框架(Rainforest Framework),如果训练集存储在数据库,AVC-set可以通过简单的SQL查询得到:select D.x,D.C,count(*)from D where fn group by D.x,D.C。因此,对于雨林框架,一方面算法实现简单,另一方面是对于大训练数据集,生成的AVC-group的存储开销仅与属性个数、各属性取值个数及类标号取值有关,容易被有限的主存接受。
3 可伸缩的朴素贝叶斯分类算法
3.1 算法步骤
本文提出的可伸缩的朴素贝叶斯分类算法是将雨林算法应用到朴素贝叶斯分类算法上,算法流程如下图1。
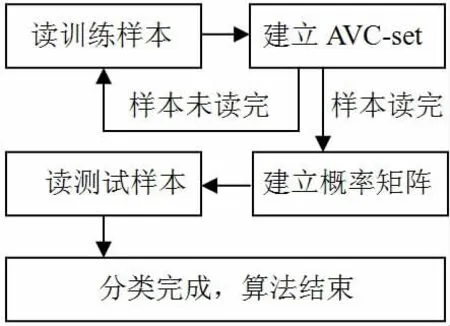
图1 算法流程
具体的算法过程描述如下:
(1)预扫描训练样本的前n条记录,以获取属性个数、属性名、类标号名、各个属性的取值和类标号取值;
(2)建立雨林结构 AVC-set;
(3)扫描整个训练样本,计算上面定义的aX,x,i,写入雨林结构AVC-set的valueClass,进而生成AVC-group,样本扫描完毕,整个雨林结构建立完成;
(4)建立定义1的概率矩阵结构,将从AVC-group读取的数据计算出结果写入概率矩阵。概率矩阵建立完成,则训练过程完成;
(5)读取测试样本,从概率矩阵中获取各属性相对各类的条件概率,计算各个类的后验概率,比较得出所属类,分类完成。算法结束。
3.2 算法改进及一些说明
3.2.1 算法的时间和空间复杂度 该算法的时间复杂度主要在于对训练样本的训练过程中AVC-group的建立,训练样本元组数目为n,时间复杂度为O(n)。算法中除了扫描训练集所需的内存开销外,常驻内存的是AVC-group和概率矩阵,而属性名个数与属性取值均为常数,故空间复杂度为O(1)。
3.2.2 算法说明与改进 该算法的主要优点是让贝叶斯分类算法具有可伸缩性,对于无法一次性读入主存的大数据集,采取分批读入,一次读入的行数可视具体硬件配置设定。
在一些专业领域训练数据不是一次给出的,该算法还可以做一点简单改进,将第一次训练生成的AVC-group写入辅存,第二次读取新的训练集时把生成的AVC-group与前次生成的AVC-group合并,而不需要重新读取前次的训练集,也不需要花费额外的存储空间,仅需要多出读取前次生成的AVC-group的算法做了具体的实验,其中硬件平台:Pentium E2160 1.8GHz处理器,1G内存;软件平台:Windows XP sp3, 开发环境:Visual Studio 2005,C#实现。实验结果分析如下:
对UCI数据库里的Nursery样本数据129600条记录用本算法分批读入内存处理,所得的结果能与样本全部读入内存得到相同的分类准确率,并且耗用时间相当。这表明,该算法是有效的,可以用于大数据集的训练分类。
5 结束语
针对为提高分类准确率而增大训练样本带来的算法可伸缩问题,本文提出一种基于雨林框架的朴素贝叶斯分类算法,实验表明在解决伸缩性问题的同时,保证了算法的高效和高准确率。但是本算法是基于“朴素”前提的,对于实际数据集并不满足属性独立,针对这种情况,本算法还需进一步改进;另一方面还需考虑当训练数据存在数据缺失的情况的处理方法。下步将进行这方面的研究。
[1]李贤平.概率论基础[M].北京:高等教育出版社,1997.
[2]Jiawei Han,Micheline Kamber.数据挖掘概念与技术[M].范明,孟小峰,译.北京:机械工业出版社,2007:201-206.
[3]GehrkeJ,Ramakrishnan R,Gantiy V.RainForest-A Framework for Fast Decision Tree Construction of Large Datasets[C]//Data Mining and Knowledge Discovery.NetheHands:Kluwer Academic Pcblisher,2000:135-149.
Bao Xiaobing,Zhai Sulan,Cheng Lanlan
(Institute of Mathematical Sciences,Anhui university,Heifei Anhui 230039)
A scalable Nave bayesian classifier algorithm is proposed which is aimed at training data of large dataset.Through constructing rainforest framework,training data can be stored in the limited memory and generates probability matrix,Then the testing samples are classified.Algorithm only scans whole dataset for one time.Experiments shows that Algorithm can obtain the same classification accuracy as reading-in of the whole database and have a higher processing efficiency.
Rainforest;Scalable Algorithm;Na ve Bayesian Classifier
TP 391
A
1674-1103(2012)03-0001-03
2011-11-23
安徽省高校优秀青年人才基金项目(0510118)。
包小兵(1981-),男,安徽庐江人,安徽大学数学科学学院硕士研究生,研究方向为数据挖掘;翟素兰(1977-),女,安徽涡阳人,安徽大学数学科学学院副教授,博士,硕士生导师,研究方向为模式识别与数据挖掘。
[责任编辑:曹怀火]
