基于谱熵的耳语音增强研究*
2012-10-22杜志然景新幸
杜志然,周 萍,景新幸,李 杰
(1.桂林电子科技大学计算机科学与工程学院,广西桂林 541004;2.桂林电子科技大学电子工程与自动化学院,广西桂林 541004;3.桂林电子科技大学信息与通信学院,广西桂林 541004)
0 引言
耳语音作为一种特殊的语音,因其特殊性,给后续处理带来了不便。尤其是被噪声污染过的语音信号,在提取特征参数过程,往往会受到干扰。因此,对其进行增强处理是一个值得关注的问题。目前对耳语音的增强研究多使用基于神经元的方法[1]和自适应滤波的方法[2]。这些方法往往计算量比较大,需要参考信号的输入,而参考信号在现实中有时是不可知的。谱减法是一种比较传统的增强方法,计算比较简单,效果良好,而且不需要参考信号的输入,在现实生活中有着广泛的应用。由于耳语音的特性,传统谱减法对耳语音的增强效果较差,本文采用基于子带功率谱熵的改进谱减法,对耳语音进行增强处理。
1 耳语音的发音特点
发音系统主要由肺部、声带、声道、双唇构成。耳语音发音时,声门处于半开状态,肺部气流从声门的后半部分即气门摩擦而出,表现为气声发音,声带不振动,能量较低。同时,由于声门半开,声道因为增加了气管和肺部,传输函数与正常发音相比,也发生了改变。这些包含不同频率的气声声波经声道产生不同程度的加强和抑制[3]。
由于独特的发音方式,耳语音有以下特点:1)声带不振动,没有基频;2)气声发音,激励源类似于噪声,能量低,信噪比低;3)耳语音的声道传输函数与正常音不同,耳语音的共振峰相对于正常音向高频偏移,带宽变大;4)为了使耳语音尽可能听清楚,一般情况下耳语音语速较慢,音长较长。图1是正常音与耳语音“san”的基本特征对比图。

图1 正常音与耳语音基本特征对比图Fig 1 Comparison diagram of basis feature of normal and whispered speech
2 耳语音库的建立
目前在耳语音方面进行研究所使用的语音库大多是实验者自己所建的。为了研究方便,本实验建立了一个小型耳语音库:
1)录音环境:耳语音信噪比较低,不易辨识,所以,在比较安静的情况下进行。本实验在普通实验室进行的,时间为晚上9点到10点,连续多天。关闭门窗、空调、饮水机等以保证室内安静。录音时,只有录音人在内,其他人在门外等候。
2)录音设备:考虑到耳语音的发音特点,经过对比试验,选择使用SONY ICD-UX91F立体声数码录音棒、外置麦克风为录音设备。录音棒设置为ST(高质量立体声录音)模式,存储为MP3格式。之后为了实验的方便使用Cool Edit 2.1软件将其转换为频率为8kHz,单声道,量化精度为16 bit的wav文件。
3)发音人:录制的语音库分为2个部分,第一部分有31个发音人,其中15个男生,16个女生,普通话发音。考虑到地域因素,所选的发音人涉及多个省份;第二部分为单人女声发音。
4)录音内容
a.数字0~9;桂林电子科技大学;杂志中随机一段文字。31个发音人,每人大概读1 min,均为耳语音发音。之后同样的内容用正常音重复一遍。
b.单人女声发音,其中100个常用字,50个常用词,数字0~9,26个英文字母,4个声调的发音10组,常用句5个,均用耳语音发音5遍,正常音1遍。
5)注意事项:录音前,每位录音者需要熟悉录音内容,并且掌握耳语音的发音技巧。录音时,每位发音人需要吐字清晰,语调平稳,并且尽量保持不动。
3 耳语音的增强处理
3.1 加噪耳语音信号的子带功率谱熵
信源熵是信源的平均不确定度的度量,不确定度越大,熵值越大[4]。在语音信号中,功率谱熵与信号的功率谱大小无关,仅与变化程度有关。耳语音与正常音相比,能量比较小。使用短时能量、短时平均幅度等方法不易检测出耳语音的噪声段和语音段,而采用功率谱熵可以弥补这些缺点。
首先对信号分帧,加窗,FFT。帧内各频点的功率谱概率密度函数为

其中,m为帧号,s(f(i,m))为信号经FFT后第m帧第i个点的频谱分量,|s(f(i,m)|2为其功率谱能量,N为快速傅里叶变换的点数,则第m帧信号的功率谱熵为
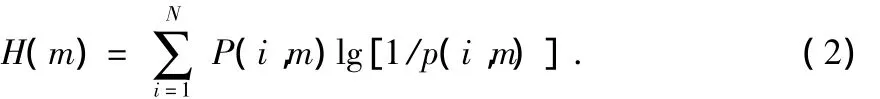
为了消除突发性噪音对某一频点的影响,采用子带功率谱熵的方法[5]把几个频点组成一个子带,这样一帧信号就分为Nb个子带,本实验把4个频点组成一个子带,则一帧信号中有N/4个子带。
根据子带的功率密度函数求每帧信号的功率谱熵,这样得到的功率谱熵相对要平缓一点,子带的功率密度函数为
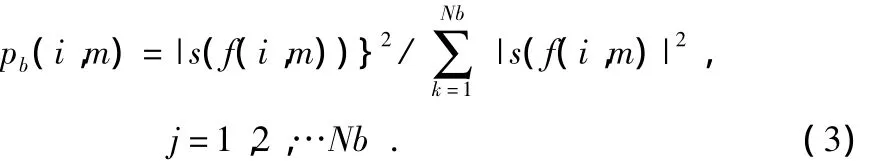
其中,|s(f(i,m)|2是第m帧第i子带内频点功率谱能量之和,则第m帧信号的功率谱熵为

根据最大熵定理,当构成信源的各个符号出现的概率相等时,这时出现任何符号的可能性相等,也就是不确定最大,这时熵值最大[4]。噪音信号频谱分布比较均匀,而语音信号的频谱分布变换范围比较大,根据最大熵定理,噪音的功率谱熵要大于语音的功率谱熵。因此,可以利用语音信号的子带功率谱熵有效的检测出一段语音信号的语音段和噪音段。图2是一段加噪耳语音信号的波形图及其子带功率谱熵图。

图2 加噪耳语音信号的波形及其子带功率谱熵图Fig 2 Waveform and band-partitioning power spectral entropy of noisy whispered speech
从图2可以看出:加噪耳语音信号虽然幅值、能量比较小,但利用子带功率谱熵还是可以有效地分辨出噪音段和语音段。上图中熵值大的部分为噪音段,熵值较小的部分为语音段。
图3分别是耳语音“san”的在信噪比为10和5情况下的子带功率谱熵图,从图中可以看出两者的噪音段虽然信噪比不同,但谱熵值没有明显的改变,仍介于值3.6~3.8之间。但语音段在低信噪比为5情况下的谱熵值明显增大,谱熵值由原来的 3.3~3.4 上升到 3.4~3.6。由此可以推测出在一段混杂不稳定噪音的语音段中,若某帧的谱熵较大,说明这帧语音被污染得比较严重。

图3 不同信噪比下的子带功率谱熵图Fig 3 Band-partitioning power spectral entropy under the condition of different SNR
3.2 改进谱减法
设带噪语音信号为y(t),纯净语音信号为x(t),噪声信号为n(t)。因为非线性噪声可以转换为线性噪声来处理,为了研究方便,一般假定噪声信号和纯净语音信号是线性相加的[6],则有

设Y(ω),X(ω),N(ω)分别为y(t),x(t),n(t)对应的频谱,则等式两边经傅里叶变换后有

因为假设Xi,Ni是相互独立的,则对应的功率谱有以下关系

为了防止负值现象的出现,当|Y(ω)|2-|N(ω)|2<0时置0。将原始语音的相位作为增强后语音的相位,通过逆傅里叶变换,就可以得到增强后的语音信号。
基本谱减法比较简单,但存在很大的缺点,就是音乐噪声的出现。因为在现实中噪声并非一直稳定的,而且噪声与纯净语音并非都是线性相加的,某些点谱减后可能会形成一个个的峰值,造成音乐噪声,听觉上难以接受。目前关于如何消除音乐噪声有很多种方法,大多数方法采用下式

当α=2,β=1时为基本谱减法;通过实验设定α,β为某一确定的值;自适应改变α,β的值都可以提高去噪的灵活性[7~9]。当α一定,增大β可以减少残余噪声,但是语音可能会有较大的失真;当β一定时,增大α,残余噪声增大,但失真较小。
本文利用改进谱减公式|X(ω)|=[|Y(ω)|αβ|N(ω)|α]-α进行去噪。首先利用信号的子带谱熵设定阈值,有效判断出噪声段和语音段,然后分开处理噪声段和语音段。噪音信号并非一直稳定的,因此,为了更好地去噪,需要实时更新噪声|N(ω)|,同时在噪音段和语音段自适应调节α,β值,以达到良好的增强效果。
3.3 算法实现
首先选取无音部分的前10帧计算初始噪声,然后利用信号的子带功率谱熵值判断出信号的噪音段和语音段。如果是噪音段则更新噪声,选取当前帧权重为0.8,上一帧更新后的噪声权重为0.2。如果是语音段,则根据被污染的程度实时调节谱减系数β,为了避免语音失真,适当增大α。
具体步骤如下:
1)加噪、分帧、加窗、预加重、快速傅里叶变换。
2)选取无音部分前10帧,计算其平均幅度作为初始噪音幅度Noise。
3)计算每一帧的子带功率谱熵Hi,并记最大熵值为Hmax,最小熵值为Hmin。
4)当Hi/Hmax>0.93(0.93 经过反复试验确定)时,可以判断其为噪音段,更新噪音Noise=0.2×Noise+0.8×Noise(i)。
其中,Noise为前一帧更新的噪声,Noise(i)为当前帧噪音。设定谱减系数β=2.5,α=2,β经过反复实验确定,转步骤(6)。
5)当Hi/Hmax<0.93可判断其为语音段,设谱减系数β,当H(i)比较大时,说明此帧污染较严重,β也相应增大,为了避免语音失真,设定α=3,转步骤(6)。
6)谱减,若谱减后小于0,则置0。
7)合成语音,去加重,实验结束。
4 实验结果
为了验证本文方法的有效性,从录制的语音库中截取一段耳语音“0,1,2,3”以不同信噪比加入高斯白噪声,采样频率8kHz,量化精度16bit,帧长512,帧移256,采用上述方法利用Matlab进行仿真实验。
图4是以信噪比5加入高斯白噪声,用本文方法处理后的原始波形图和增强波形图。从图中可以看出:本文方法对耳语音的去噪效果良好,计算后得知增强后的信噪比得到了提高。并且经过试听,发现音乐噪声得到了有效的消除。表1是以不同信噪比加入高斯白噪声,利用基本谱减法和本文方法增强后的信噪比对比。

表1 输出信噪比的对比Tab 1 Comparison of output SNR
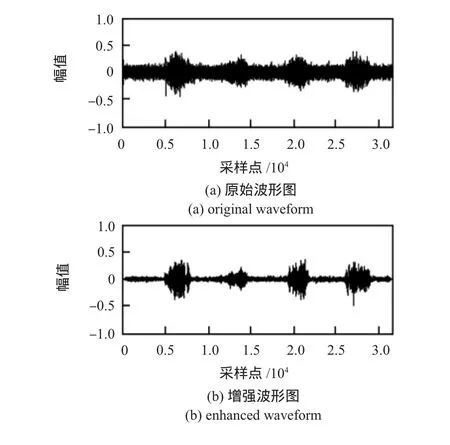
图4 原始波形图与增强后波形图对比Fig 4 Comparison of original and enhanced waveform
5 结论
本文建立了一个小型耳语音库,分析了耳语音的发音特点和功率谱熵特性,并利用基于子带功率谱熵的改进谱减法对耳语音进行增强处理。实验证明:此方法比较简单,且与传统谱减法相比,信噪比有了较大的提高,削减了噪声的干扰,为耳语音说话人识别、耳语音到正常音的转换等后续研究打下良好的基础。
[1] 孙 静,陶 智,顾济华.基于AD神经网络的耳语音增强研究[J].计算机工程与应用,2007,43(29):242 -244.
[2] 孙 静,陶 智,顾济华.基于LMS自适应滤波的耳语音增强的研究[J].通信技术,2007(12):394-396.
[3] 沈 炯,王理嘉.耳语音的性质[J].汉语学习,1984(4):35-40.
[4] 曹雪虹,张宗橙.信息论与编码[M].北京:北京邮电大学出版社,2002.
[5] Li Xin,Liu Huaping,Zheng Yu,et al.Robust speech endpoint detection based on improved adaptive band-partitioning spectral entropy[C]∥Lecture Notes in Computer Science,2007:36 -45.
[6] 张雪英.数字语音处理[M].北京:电子工业出版社,2010.
[7] Gao Liuyang,Guo Yunfei,Li Shaomei.Speech enhancement alogrithm based on improved spectral subtraction[C]∥IEEE International Conference on Intelligent Computing and Intelligent Systems,ICIS2009,2009:140 -143.
[8] 刘志坤,唐小明,朱洪伟.基于改进谱减法的语音增强研究[J].计算机仿真,2009,26(6):363 -366.
[9] 陶 智,赵鹤鸣,龚呈卉.基于谱减法的听觉模拟的语音增强[J].计算机工程与应用,2005(4):57-60.
