基于信息熵的变异算子设计
2012-10-20王再见董育宁
王再见,董育宁
(1.安徽师范大学物理与电子信息学院,安徽芜湖 241000;2.南京邮电大学通信与信息工程学院,江苏南京 210003)
0 引言
遗传算法(Genetic Algorithms,GAs)模拟的是生物进化过程[1],是一种自适应启发式概率性迭代全局搜索算法,由于简单易行在各个领域得到广泛应用。但是,GAs早熟收敛使其全局收敛性存在一定概率的不稳定,降低了算法性能。导致GAs早熟收敛的主要原因是基因多样性的降低。较大的种群规模(基因多样性较好)可以提供较好的全局搜索性能,但收敛相对较慢;而较小的种群规模(基因多样性较差),其搜索空间的分布范围有限,可以较快地达到局部最优解,容易引起未成熟收敛。在实际问题的求解过程中,种群规模是有限的。因此,如何在有限的种群规模条件下,保持基因多样性,进而快速产生优良后代是GAs必须解决的问题。该文针对该问题,从变异算子的设计入手,提出了基于信息熵的变异算子。改进后的变异算子考虑了变异行为与环境的关系,增加了种群信息量,有效地保持种群的多样性,保证了种群进化的质量。
1 变异分析
变异是众所周知的影响GAs收敛性能和搜索效果的重要因素之一,文献[2]对变异的搜索能力进行了详细的分析,指出变异是唯一具有全局搜索能力的遗传算子。文献[3-6]表明变异与求解的问题有关。但在GAs研究中变异都是基于概率、固定的且与问题无关的,其发生都是随机的[7],变异率也是数值实验得到的经验值[3,4],虽然有文献采用自适应变异率来改善算法性能,但仅考虑适应度等部分因素,忽略了各因素产生的关联影响,在一些应用中算法的效果并不好[8]。正如Trewavas在文献[9]中指出:对于变异,简单数学工具的使用不仅使所涉及的机理远比实际的简单,甚至发生直接的误导作用。GAs基于适应度的进化模式没有考虑进化的外部环境和进化成分之间的关系,变异率的使用掩饰了生物学变异,忽略了个体的重要性,导致或频繁破坏已获得的优良模式,或使种群收敛到早熟集,降低了算法搜索能力。
生物进化的实质在于种群基因频率的改变,每个种群都有它独特的基因库,基因库代代相传,并在传递过程中得到保持和发展,种群越大,基因库也越大;反之,种群越小基因库也越小。当种群变得很小时,就有可能失去遗传的多样性,从而失去了进化上的优势而逐渐被淘汰[10,11]。由此可见,变异与具体的环境有关,其目的是增加种群的信息量,这在算子设计时需要充分考虑。
2 基于信息熵的变异算子
由信息论可知,信息熵在随机事件发生之前,它是结果不确定性的量度;在随机事件发生之后,它是从该事件中所得到信息的量度(信息量)[15]。引入信息熵作为基因信息的度量,目的为变异提供判断依据。
2.1 几个概念
定义2.1 基因库:解空间所含的全部基因。
定义2.2 当前种群基因库:当前种群所含的全部基因。
定义2.3 基因类型:完全一样的基因属于同一类型。
定义2.4 基因类型信息熵:对于当前种群,如果基因库S内基因类型入选当前种群基因库的概率分布P={p1,…,pn},则每种基因类型本身的信息为Ii=-log2pi,基因类型的平均信息量为 H=,这个平均信息量就是基因类型信息熵。
基因类型信息量假设:当前种群基因库不存在的基因类型,各类型的信息量相等,且相互独立。
2.2 基于信息熵的变异算子设计及性能分析
基于信息熵的变异算子是对生物变异过程的逼近,应体现以下特点:① 变异既有随机性也有普遍性,与当前种群(具体的环境)有关,体现在变异概率受当前种群影响,动态调整;② 变异目的是增加种群的信息量,体现在变异算子倾向于引进新的基因类型,以增加种群的信息量,避免基因多样性降低而导致早熟收敛。基于以上分析,该文提出的基于信息熵的变异算子实现步骤如下:
步骤1 设定变异概率:
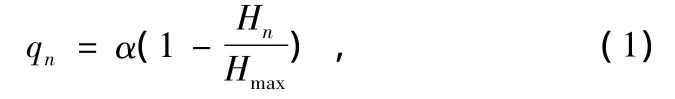
式中,qn为第n代变异概率;α为修正因子,用于调整基因概率估计不准所带来的误差(实验取值1);Hn为第n代基因类型信息熵。
式(1)说明,变异概率的大小取决于当代基因类型信息熵:①Hn变大则qn变小,说明随着种群基因类型信息熵变大,变异的作用变小,这样避免变异操作频繁破坏已获得的优良模式,使GAs陷入随机搜索。②Hn变小则qn变大,说明随着种群信息量变小,基因多样性降低,有导致早熟收敛的可能,此时需要提高变异概率,补充新的基因,丰富种群的基因类型,为进化提供更多的原材料,提高全局搜索的能力,这对于那些积木块在整个解空间中分散分布的问题很重要。目前公认为GAs操作中,演化初期变异的作用小,起主要作用的是交叉算子,演化后期起主要作用的是变异算子。这在式(1)中得到较好的体现,因为初期种群基因类型信息熵大,基因类型丰富,而通常变异概率很小,所以交叉算子作用明显,演化后期基因多样性降低,交叉算子无法引入新的基因,易陷入局部最优解,此时变异概率很大,变异算子起主要作用。
步骤2 选择变异点:依据基因类型信息量,采用轮盘赌的方式选取欲引入的基因,基因类型信息量较高的该类型基因以较大的概率被选中,欲替换的对应位置就是变异点。
3 实验测试
鉴于P={p1,…,pn}很难确定,而GAs的基因就是二进制的位,基因的概率决定了其所属的基因类型概率。但是在实际运算中获得基因的概率分布几乎不可能实现,此外,信息熵的计算非常复杂,而具有多重前置条件的信息,更是几乎不能计算。因此,对基因类型信息量的计算作如下简化:
①属于当前种群基因库的基因类型,令基因类型i的概率估计为:

则其信息量为:
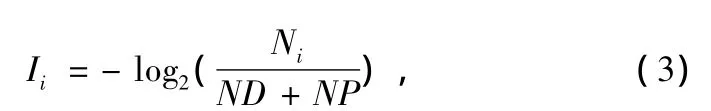
式中,Ni为基因类型为i的基因在当前种群基因库中的总数(当Ni变大,意味着Nj(j≠i)变小,导致基因类型分布失衡,当前种群的信息熵Hn偏离Hmax越远),NP为当前种群基因库缺失的基因类型总数,ND为当前种群基因库的规模。对于设计过程中将ND、NP拆分,是由于在种群更新时,因为针对个体的适应度评估,会使得总体质量较差的个体(但是该个体本身具有个别的优良基因)遭到淘汰,会造成当前种群缺失部分优良基因。
②当前种群基因库缺失的基因类型,各基因类型信息量相等,设基因类型概率的估计皆为:

则信息量为:
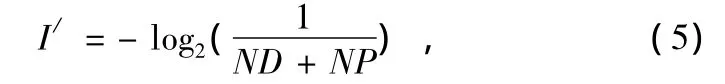
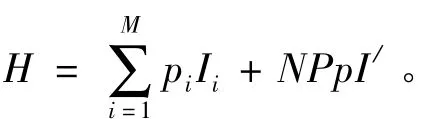
由以上分析可以看出,用各类型基因在种群中所占的大致比例来近似基因类型的概率,反映基因类型入选的概率较大则该类型基因出现在当前种群中的频率较高。
该文采用式(6)、式(7)2个典型的函数(阈值皆设为 ±0.005),将采用新变异算子的 GAs与SGA[12]、FLAGA[13]、HMGA[14]进行实验比较。
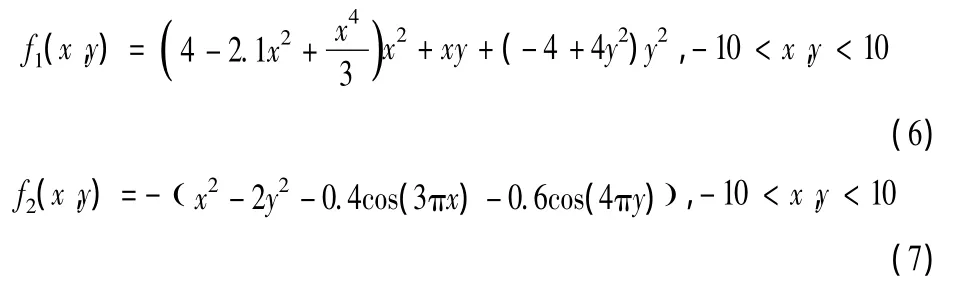
函数 f1(x,y)有6个局部极小点,有2个点(-0.0898,0.7126)和(0.0898,-0.7126)为全局最小点,最小值为-1.031628;函数f2(x,y)是个多峰函数,只有1个全局最大点(0,0),最大值为1。
与SGA相比,采用新变异算子的GAs在平均收敛代数、早熟次数及平均收敛时间3个指标方面优势明显;与FLAGA和HMGA相比也有较好的改善。其原因在于,SGA没有考虑环境对种群质量的影响,其变异算子的设计是固定的,与问题无关。而FLAGA和HMGA的变异尽管也是基于概率的,但是通过微调或记忆等措施保证种群基因信息量,这些保证措施可看作是变异算子的组成部分,事实上此时的变异与环境有关,间接实现了该文的思想,因此实验效果接近。
图1给出种群“变异概率”和“基因类型总数”之间的关系图(迭代100次的统计平均),该图表明变异概率与当前基因分布有关,总体趋势是:随着种群中基因类型增多,种群变异概率变小,避免陷入随机搜索;随着种群中基因类型减少,种群变异概率变大,目的是增加新基因。
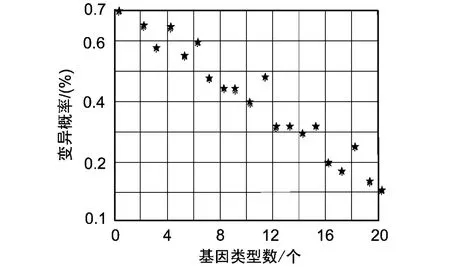
图1 种群“变异概率”和“基因类型总数”的关系图
4 结束语
该文从设计思想入手,分析了GAs中传统变异算子存在的不足,在此基础上,引入信息熵,利用基于信息熵的变异算子改进传统的变异方式,有效地克服了早熟收敛,增强了GAs对复杂问题的求解能力。并根据此机理提出一个稍加改进的GAs,最后对2个典型的函数优化问题进行了模拟比较,结果表明基于信息熵的变异算子大大增强了算法的寻优能力,改进了搜索性能。
[1]YANG Wen-zhu,LI Dao-liang,ZHU Liang.An Improved Genetic Algorithm for Optimal Feature Subset Selection from Multi-character Feature Set[J].Expert Systems with Applications,2011,38(3):2733-2740.
[2]KAYA I.A Genetic Algorithm Approach to Determine the Sample SizeforControlChartswith Variablesand Attributes [J].Expert Systems with Applications,2009,36(5):8719-8734.
[3]王洪峰,汪定伟,杨圣祥.动态环境中的进化计算[J].控制与决策,2007,22(2):127-131.
[4]YANG Sheng-xiang, YAO Xin. Population-based IncrementalLearning with Associative Memory for Dynamic environments [J].IEEE Transactions on Evolutionary Computation,2008,12(5):542-561.
[5]JIN Yao-chun,BRANKE J.Evolutionary optimization in uncertain environments-a survey [J].IEEE Transactions on Evolutionary Computation,2005,7(3):303-317.
[6]SPEARS W M.Evolutionary algorithms:The role of mutation and recombination(Natural Computing Series)[M].Berlin:Springer Verlag,2000:28-34.
[7]SUZUKI J.A further result on the Markov chain model of genetic algorithms and its application to A simulated annealing-like strategy[J].IEEE Trans Systems,Man &Cybernetics,1998,28(1):95-102.
[8]刘敏,严隽薇.基于自适应退火遗传算法的车间日作业计划调度方法[J].计算机学报,2007,30(7):1164-1172.
[9]TREWAVAS A J.The importance of individuality.Lerner H R.Plant Responses to Environmental Stresses:FromPhytohormones to Genome Reorganization [M].New York:Marcel Dekker Inc,1999:27-42.
[10]RAVEN PETER H,JOHNSON GEORGE B.Biology[M].New York:The McGraw-Hill Companies,2005.
[11]KARIN Klontke,ANTOINE Barrière,IRINA Kolotuev,et al.Trends,Stasis,and Drift in the Evolution of Nematode Vulva Development [J].Current Biology,2007,20(17):1925-1937.
[12]SRINVAS M,PATNAIK L M.A daptive probabilities of crossover and mutation in genetic algo rithms[J].IEEE Transactions on SMC,1994,24(4):656-666.
[13]刘习春,喻寿益.局部快速微调遗传算法[J].计算机学报,2006,29(1):100-105.
[14]陈昊,黎明,陈曦.动态环境下基于混合记忆策略的遗传算法[J].应用科学学报,2010,28(5):540-545.
